







阿里云E-MapReduce操作
阿里云E-MapReduce(简称EMR),是运行在阿里云平台上的一种大数据处理的系统解决方案。EMR构建于云服务器ECS上,基于开源的Apache Hadoop和Apache Spark,让您可以方便地使用Hadoop和Spark生态系统中的其他周边系统分析和处理数据。EMR还可以与阿里云其他的云数据存储系统和数据库系统(例如,阿里云OSS和RDS等)进行数据传输。
一、E-MapReduce的用途
以往在使用Hadoop和Spark等分布式处理系统时,通常需要执行如下步骤:

在上述使用流程中,真正跟用户的应用逻辑相关的是步骤810,而步骤17都是前期准备工作,但这些前期准备工作都非常冗长繁琐。E-MapReduce提供了集群管理工具的集成解决方案,例如,主机选型、环境部署、集群搭建、集群配置、集群运行、作业配置、作业运行、集群管理和性能监控等。通过E-MapReduce,您可以从繁琐的集群构建相关的采购、准备和运维等工作中解放出来,只关心自己应用程序的处理逻辑即可。
此外,E-MapReduce还为您提供了灵活的搭配组合方式,您可以根据自己的业务特点选择不同的集群服务。例如,如果您的需求是对数据进行日常统计和简单的批量运算,则可以只选择在E-MapReduce中运行Hadoop服务;如果您有流式计算和实时计算的需求,则可以在Hadoop服务基础上再加入Spark服务。
二、E-MapReduce的组成
E-MapReduce的核心是集群。E-MapReduce集群是由一个或多个阿里云ECS实例组成的Hadoop、Flink、Druid、ZooKeeper集群。以Hadoop为例,每个ECS 实例上通常都运行了一些daemon进程(例如,NameNode、DataNode、ResouceManager和NodeManager),这些daemon进程共同组成了Hadoop集群。例如下图是一个包含Master节点、Core节点、Task节点和Gateway节点的E-MapReduce集群。

1)Master节点,部署了Hadoop的主节点服务,包括HDFS NameNode、HDFS JournalNode、ZooKeeper、YARN ResourceManager和HBase HMaster等服务,可以根据集群的使用场景,选择高可用集群或非高可用集群。测试环境可以选择非高可用集群,生产环境建议选择高可用集群。高可用集群可以选择2个或3个Master节点,当选择2个Master节点时,HDFS JournalNode和ZooKeeper会部署在Core的emr-worker-1节点。生产环境建议创建高可用集群时选择3个Master节点。
2)Core节点,部署了HDFS DataNode和YARN Nodemanager,用于HDFS数据的存储和YARN的计算,不可以弹性伸缩。
3)Task节点,部署了YARN NodeManager,用于YARN计算,可以通过弹性伸缩的方式灵活扩容或缩容。
4)Gateway节点,部署了Hadoop的客户端文件,您可以通过Gateway提交作业,避免直接登录集群产生的安全和客户端环境隔离问题。您需要先创建Hadoop集群,然后创建Gateway集群关联至Hadoop集群。
三、Kafka模块
3.1 Kafka搭建(E-MR)
1)点击“产品与服务”,搜索“E-MapReduce”点击进入

2)点击创建集群

3)选择“Kafka”,选中Kafka版本对应的产品版本

4)选择“按量付费”
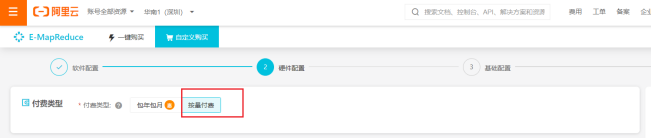
5)选择网络配置
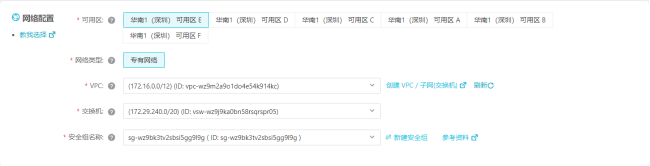
6)选择实例配置

7)配置基础信息

8)确认集群信息

9)Kafka集群创建成功
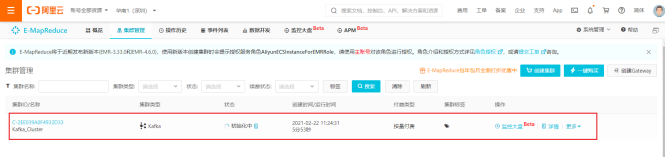
10)查看ECS实例列表
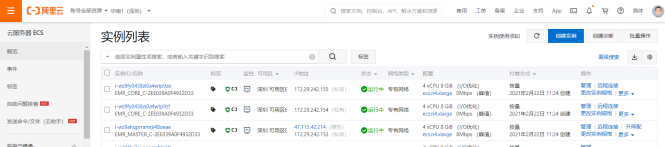
3.2 Kafka节点连接
打开远程连接工具进行配置,这里以CRT为例。
1)新建一个Session
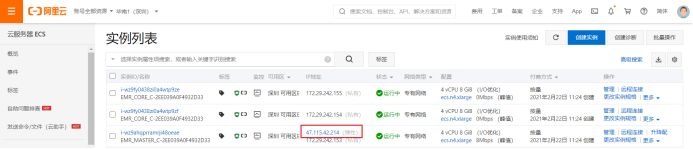

2)浏览框架搭建路径
[root@emr-header-1 service]# cd /opt/apps/ecm/service/
[root@emr-header-1 service]# ls
alertmanager bigboot emr-monitor flow-agent hive kafka-client livy prometheus superset
alluxio clickhouse emrsdk flume hudi kafka-manager metastore ranger tez
analytics-zoo datafactory ess ganglia hue kafka-rest-proxy oozie solr zeppelin
b2jindosdk deltalake esssdk hadoop impala kafka-schema-registry phoenix spark zookeeper
b2monitor druid flink has jupyter knox pig sqoop
b2smartdata emrhook flink-vvp hbase kafka kudu presto storm
2)修改hosts文件
[root@emr-header-1 service]# vim /etc/hosts
# 增加如下一行
172.29.242.153 cluster_master_node
3.3 Kafka命令行操作
1)查看当前服务器中的所有topic
[root@emr-header-1 kafka_2.12-2.4.1-1.0.0]# pwd
/opt/apps/ecm/service/kafka/2.12-2.4.1-1.0.0/package/kafka_2.12-2.4.1-1.0.0
[root@hadoop102 kafka]$ kafka-topics.sh --zookeeper cluster_master_node:2181 --list
2)创建topic
[root@emr-header-1 kafka_2.12-2.4.1-1.0.0]# kafka-topics.sh --zookeeper cluster_master_node:2181
--create --replication-factor 3 --partitions 1 --topic first
选项说明:
–topic 定义topic名
–replication-factor 定义副本数
–partitions 定义分区数
3)删除topic
[root@emr-header-1 kafka_2.12-2.4.1-1.0.0]# kafka-topics.sh --zookeeper cluster_master_node:2181
--delete --topic first
需要server.properties中设置delete.topic.enable=true否则只是标记删除。
4)发送消息
[root@emr-header-1 kafka_2.12-2.4.1-1.0.0]# kafka-console-producer.sh --broker-list
cluster_master_node:9092 --topic first
>hello world
>atguigu atguigu
5)消费消息
[root@emr-header-1 kafka_2.12-2.4.1-1.0.0]# kafka-console-consumer.sh --bootstrap-server
cluster_master_node:9092 --topic first
[root@emr-header-1 kafka_2.12-2.4.1-1.0.0]# kafka-console-consumer.sh --bootstrap-server
cluster_master_node:9092 --from-beginning --topic first
–from-beginning:会把主题中以往所有的数据都读取出来。
6)查看某个Topic的详情
[root@emr-header-1 kafka_2.12-2.4.1-1.0.0]# kafka-topics.sh --zookeeper cluster_master_node:2181
--describe --topic first
7)修改分区数
[root@emr-header-1 kafka_2.12-2.4.1-1.0.0]# kafka-topics.sh --zookeeper cluster_master_node:2181 --alter
--topic first --partitions 6
3.4 Kafka数据监控
1)点击“监控大盘”
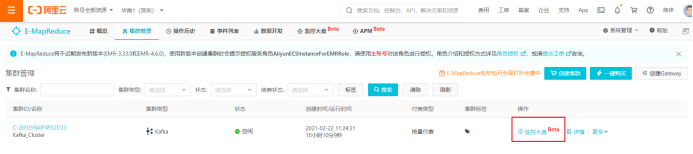
2)集群概览

3)主机监控
















 341
341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









