




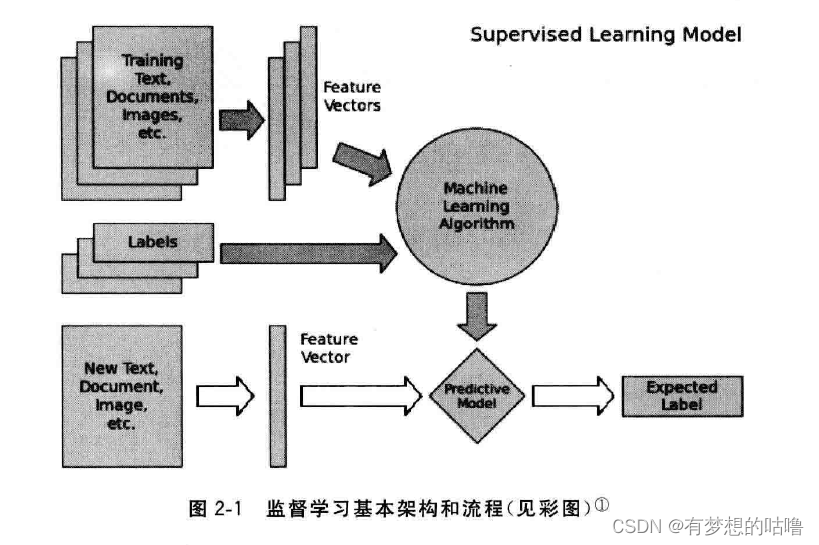
监督学习的流程示意图
1、什么是监督学习
监督学习(Supervised Learning)是机器学习中最常用和最基础的学习方法之一。它通过使用已标记的训练数据集来训练一个模型,使其能够对未知数据进行预测和分类。
在监督学习中,训练数据集由输入和输出组成,每个训练样本都有一个对应的输入值和输出值(标签)。训练样本被输入到模型中,模型通过“学习”观察输入和输出之间的关系,从而可以推广到未见过的新数据。
监督学习的主要目标是寻找一个能够将输入映射到输出的模型,使其能够对未知数据进行准确的预测或分类。常见的监督学习任务包括:
-
分类(Classification):将输入数据分为不同的类别。例如,根据病人的症状预测其是否患有某种疾病,根据电子邮件的内容判断其是否为垃圾邮件。
-
回归(Regression):根据输入数据预测一个数值型的输出。例如,根据房屋的面积、位置等特征预测其价格,根据一辆汽车的特征预测其燃油效率。
监督学习的基本思想是通过大量的训练数据让模型从中学习到输入与输出之间的映射关系,从而能够进行准确的预测。常用的监督学习算法包括决策树、支持向量机(SVM)、神经网络、随机森林、朴素贝叶斯等。
在实际应用中,监督学习需要注意数据的质量和特征的选择,同时需要进行模型选择、参数调优和评估等步骤,以确保模型具有良好的泛化能力。监督学习在许多领域都有广泛的应用,如金融、医疗、自然语言处理、图像识别等。
2、监督学习图像示意



















 1013
1013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











