







总代码readme.md
先决条件
软硬件要求
您可能需要一台至少配备1 个 GPU (>= 8GB)、20GB 内存和50GB 可用磁盘空间的机器。我们强烈建议使用 SSD 驱动器来保证高速 I/O。
您应该首先安装一些必要的软件包:
- 安装Python >= 3.5
- 安装Cuda >= 9.0 和cuDNN
- 使用 CUDA安装PyTorch >= 0.4.1(也支持 PyTorch 1.x)
- 安装SpaCy并初始化 GloVe 如下:
$ pip install -r requirements.txt
$ wget https://github.com/explosion/spacy-models/releases/download/en_vectors_web_lg-2.1.0/en_vectors_web_lg-2.1.0.tar.gz -O en_vectors_web_lg-2.1.0.tar.gz
$ pip install en_vectors_web_lg-2.1.0.tar.gz
设置
图像特征是使用自下而上的注意力策略提取的,每张图像都表示为一个动态数量(从 10 到 100)的 2048-D 特征。我们将每个图像的特征存储在一个.npz文件中。您可以自行准备视觉特征,也可以从OneDrive或百度云下载提取的特征。下载的文件包含三个文件:train2014.tar.gz、val2014.tar.gz和test2015.tar.gz,分别对应VQA-v2的train/val/test图像的特征。您应该按如下方式放置它们:
|-- datasets
|-- coco_extract
| |-- train2014.tar.gz
| |-- val2014.tar.gz
| |-- test2015.tar.gz
此外,我们使用来自视觉基因组数据集的 VQA 样本来扩展训练样本。与现有策略类似,我们通过两个规则对样本进行了预处理:
- 选择 QA 对,相应的图像出现在 MSCOCO 训练和val分割中。
- 选择答案出现在已处理答案列表中的 QA 对(在整个VQA-v2答案中出现 8 次以上)。
为方便起见,我们提供了我们处理过的vg问题和注释文件,您可以从OneDrive或百度云下载,放置如下:
|-- datasets
|-- vqa
| |-- VG_questions.json
| |-- VG_annotations.json
之后,您可以运行以下脚本来设置实验所需的所有配置
$ sh setup.sh
运行脚本将:
下载VQA-v2的 QA 文件。
解压自下而上的功能
最后,datasets文件夹将具有以下结构:
|-- datasets
|-- coco_extract
| |-- train2014
| | |-- COCO_train2014_...jpg.npz
| | |-- ...
| |-- val2014
| | |-- COCO_val2014_...jpg.npz
| | |-- ...
| |-- test2015
| | |-- COCO_test2015_...jpg.npz
| | |-- ...
|-- vqa
| |-- v2_OpenEnded_mscoco_train2014_questions.json
| |-- v2_OpenEnded_mscoco_val2014_questions.json
| |-- v2_OpenEnded_mscoco_test2015_questions.json
| |-- v2_OpenEnded_mscoco_test-dev2015_questions.json
| |-- v2_mscoco_train2014_annotations.json
| |-- v2_mscoco_val2014_annotations.json
| |-- VG_questions.json
| |-- VG_annotations.json
训练
以下脚本将使用默认超参数开始训练:
$ python3 run.py --RUN= 'train'
所有检查点文件将保存到:
ckpts/ckpt_<VERSION>/epoch<EPOCH_NUMBER>.pkl
训练日志文件将放置在:
results/log/log_run_<VERSION>.txt
加上:
- –VERSION=str,例如–VERSION='small_model’为您的这个模型指定一个名称。
- –GPU=str,例如–GPU='2’在指定的 GPU 设备上训练模型。
- –NW=int,例如–NW=8加快 I/O 速度。
- –MODEL={‘small’, ‘large’} (警告:大模型会消耗更多的 GPU 内存,如果你想用有限的 GPU 内存训练模型,多 GPU 训练和梯度累积可能会有所帮助。)
- –SPLIT={‘train’, ‘train+val’, ‘train+val+vg’}可以根据需要组合训练数据集。默认的训练分割是’train+val+vg’。设置–SPLIT=‘train’ 将触发评估脚本在每个 epoch 后自动运行验证分数。
- –RESUME=True使用保存的检查点参数开始训练。在这个阶段,你应该分配检查点版本–CKPT_V=str和恢复的纪元号CKPT_E=int。
- –MAX_EPOCH=int 在指定的纪元数停止训练。
- –PRELOAD=True 在初始化阶段将所有图像特征预加载到内存中(警告:需要额外的 25~30GB 内存和 30 分钟从硬盘驱动器加载时间)
多GPU训练和梯度积累
我们建议使用至少 8 GB 内存的 GPU,但如果您没有这样的设备,请不要担心,我们提供了两种方法来处理它:
- 多 GPU 训练:
如果您想在 GPU 内存有限的设备上加速训练或训练模型,您可以使用多个 GPU:
添加 --GPU=‘0, 1, 2, 3…’
每个 GPU 上的批量大小将自动调整为BATCH_SIZE/#GPUs。 - 梯度累积:
如果您只有一个小于 8GB 的 GPU,则提供了一种替代策略来在训练期间使用梯度累积:
添加 --ACCU=n
这使得优化器为n小批量累积梯度并立即更新模型权重。值得注意的是, BATCH_SIZE必须除以n才能正确运行此模式。
验证和测试
警告:如果您使用–MODELargs 或多 GPU 训练来训练模型,则也应在评估中进行设置。
离线评估
离线评估仅支持 VQA 2.0 val split。如果您想对 VQA 2.0 test-dev或test-std拆分进行评估,请参阅在线评估。
有两种启动方式:
(推荐)
$ python3 run.py --RUN= ' val ' --CKPT_V=str --CKPT_E=int
或者改用绝对路径:
$ python3 run.py --RUN= ' val ' --CKPT_PATH=str
在线评估
VQA 2.0 test-dev和test-std拆分的评估运行如下:
$ python3 run.py --RUN= 'test' --CKPT_V=str --CKPT_E=int
结果文件存储在 results/result_test/result_run_<'PATH+random number' or 'VERSION+EPOCH'>.json
您可以将获得的结果 json 文件上传到Eval AI,以评估test-dev和test-std拆分的分数
预训练模型
我们提供了两种预训练模型,即small模型和large模型。由于 pytorch 版本不同,小模型对应于我们论文中描述的模型,其性能略高(在我们的论文中,test-dev拆分的总体准确率为 70.63%)。大模型使用HIDDEN_SIZE=1024比小模型大 2 倍的HIDDEN_SIZE=512.
两个模型在test-dev拆分上的性能报告如下:
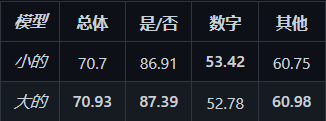
这两个模型可以从OneDrive或百度云下载,解压后放入正确的文件夹如下:
|-- ckpts
|-- ckpt_small
| |-- epoch13.pkl
|-- ckpt_large
| |-- epoch13.pkl
设置–CKPT={‘small’, ‘large’} --CKPT_E=13为测试或恢复培训,详细信息可以在培训和验证和测试中找到。

















 177
177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











