







 本文详细介绍了Python中字符串的编码格式,如UTF-8、GBK等,以及字符串的格式化方法,如`format()`函数,包括对齐、填充等。此外,还讲解了字符串的查找、分割、连接、大小写转换、是否由特定字符组成等功能,以及`replace()`和`maketrans()`的用法。最后提到了`strip()`家族方法和`eval()`函数的两种主要用途。
本文详细介绍了Python中字符串的编码格式,如UTF-8、GBK等,以及字符串的格式化方法,如`format()`函数,包括对齐、填充等。此外,还讲解了字符串的查找、分割、连接、大小写转换、是否由特定字符组成等功能,以及`replace()`和`maketrans()`的用法。最后提到了`strip()`家族方法和`eval()`函数的两种主要用途。
编码:UTF-8
- ASCII码:一个字符1B
- GB2312、GBK、CP939:1个中文字符2B
- python3默认使用UTF-8:UTF-8:英语字符1B;常见汉字字符3B
格式化字符串

1、format方法
- 序号0,1,2…指定格式化哪个元素
- 对齐:默认右对齐
- 10.3f:该数据一共占10个字符位置,保留3位小数
- 20s:字符串一共占20个字符
- 10.3%:数据一共占10个字符,百分数保留2位小数
- 06b:二进制数字一共占6位,高位补0
单个输出:
format(数据,'格式')
>>> format(532.26, '10.3f')
' 532.260'
>>> format('你好呀笨蛋', '>20s')
' 你好呀笨蛋'
>>> format(0.001234, '10.3%')
' 0.123%'
二进制数字高位补零输出
>>> format(2, '06b')
'000010'
多个输出:
'{0: 格式}, {1: 格式},....'.format(数据, 数据2,....)
>>> '输出小数:{0: >10.3f}\n输出字符串:{1: <20s}\n输出百分数{2: >10.3%}'.format(532.26, '你好呀笨蛋', 0.0011234)
'输出小数: 532.260\n输出字符串:你好呀笨蛋 \n输出百分数 0.112%'
2、center,rjust,ljust对齐填充
new_string = string.center(长度, 填充单字符)
>>> # 字符串对齐并补全
>>> 'hello cc'.center(20, '*')
'******hello cc******'
>>> 'hello cc'.rjust(20, '*')
'************hello cc'
>>> 'hello cc'.ljust(20, '*')
'hello cc************'
填充字符你只能写单字符

>>> 'ccc'.center(20, '=')
'========ccc========='
子母串
1、[r]find,[r] index:子串首次出现下标
查找一个字符串在另一个字符串指定范围(默认是整个字符串)中首次或最后一次出现的位置:
- 如果不存在则返回-1:find, rfind
- 如果不存在抛出异常:index, rindex
string.find(substring[, start[, end]]) -> int
返回文本中每个字符的首次出现:
>>> text = '''
东边来个小朋友叫小松,手里拿着一捆葱。
西边来个小朋友叫小丛,手里拿着小闹钟。
小松手里葱捆得松,掉在地上一些葱。
小丛忙放闹钟去拾葱,帮助小松捆紧葱.
小松夸小丛像雷锋,小丛说小松爱劳动。
'''
>>> for i, ch in enumerate(text):
if i == text.find(ch): # 当前ch是首次出现的ch,才记录
print('字符{0}首次出现下标为{1}'.format(ch, i))
2、count:返回子串出现次数
查找一个字符串在另一个字符串中出现的次数:string.count(substring)
3、startswith, endswith:是否以子串开头/结尾
S.endswith(suffix[, start[, end]]) -> bool
>>> import os
# 文稿下文件
>>> [filename for filename in os.listdir()]
['.DS_Store', 'Nuts', '.localized', '二阶段锁.xlsx', 'GTA Vice City User Files', 'totalLength.plist', 'Python3萌新入门笔记.pdf', 'TencentMeeting', '.UTSystemConfig', '1400115281_report_pb.dump', 'src']
# 找到以pdf结尾的文件
>>> [filename for filename in os.listdir() if filename.endswith('.pdf')]
['Python3萌新入门笔记.pdf']
分割
1、[r]split
string.split(分隔符默认为所有空白符, maxsplit = n):- re.split:分割符可以多个
- 使用正则对象:分割符可以多个
1.1、不用正则
- 不指定分隔符,则字符串中的任何空白符号(空格、换行符、制表符等)都将被认为是分隔符,并删除切分结果中的空字符串。
>>> string = ' apple,peach, peach,pear,orange'
>>> string.split()
['apple,peach,', 'peach,pear,orange']
- 指定分隔符:会保留空白字符串
>>> string = ' apple,peach, peach,pear,orange'
>>> string.split(',')
[' apple', 'peach', ' peach', 'pear', 'orange']
>>> string.split('peach')
[' apple,', ', ', ',pear,orange']
- 指定最大分割次数
>>> string = ' apple,peach, peach,pear,orange'
>>> string.split(maxsplit = 2)
['apple,peach,', 'peach,pear,orange']
1.2、用正则
直接re
>>> text = 'alpha. beta....gamma delta'
>>> re.split(r'[. ]+', text)
['alpha', 'beta', 'gamma', 'delta']
用正则对象
>>> text = 'alpha. beta....gamma delta'
>>> pattern = re.compile(r'[. ]+')
>>> pattern.split(text, maxsplit = 2)
['alpha', 'beta', 'gamma delta']
2、[r]partition一分为三
永远结果是三份:左中右 string.[r]partition(中间字符串)
>>> string = ' apple,peach, peach,pear,orange'
>>> string.partition('peach')
(' apple,', 'peach', ', peach,pear,orange')
连接字符串join
string = '连接符'.join(字符串列表)
>>> '::'.join(['aa', 'bb', 'cc'])
'aa::bb::cc'
>>> '::'.join(['aa'] * 5)
'aa::aa::aa::aa::aa'
>>> ''.join(['aa', 'bb', 'cc'])
'aabbcc'
大小写、是否是数字、字母…
1、转换大小写,首字母…
- titile:对每个单词首字母大写,其余字母转化为小写,单词里的其他字符保持不变
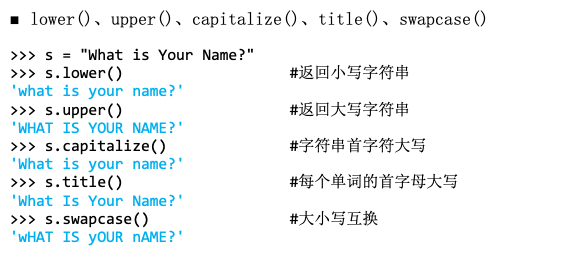
2、字符串是否由xx组成
- isalnum()字母和数字组成
- isalpha()全是字母
- isdigit()全是正整数
- isnumerical():支持汉字数字,罗马数字
>>> '一'.isnumeric()
True
>>> 'ⅣⅢⅩ'.isnumeric()
True
- isdecimal():十进制
- isspace():是空白字符
- isupper():全是大写
- islower()全是小写
替换、映射:replace,maketrans
1、replace:指定子串不重叠全部替换
new_string = string.replace('word', 'replacestring', 替换次数)
如下替换cc和dad都是不重叠的
>>> 'cccdadad'.replace('cc', '*')
'*cdadad'
>>> 'cccdadad'.replace('dad', '*')
'ccc*ad'
应用1:判断s2在s1中不重叠出现的次数。
'''1. 遍历'''
res, i = 0, 0
while i < len(s1) - len(s2) + 1:
if s1[i:i + len(s2)] == s2:
res += 1
i += len(s2)
else:
i += 1
return res
''' 2. split分割'''
return len(s1.split(s2)) - 1
'''3. replace替换的特性:不重叠替换,个人觉得最好理解'''
s = s1.replace(s2, '*')
return s.count('*')
应用2:关键词屏蔽
>>> words = ['asshole', 'stupid', 'kill']
>>> for word in words:
if word in 'i will kill you':
'i will kill you'.replace(word, '*****')
'i will ***** you'
2、maketrans/translate:多字符一一映射
1、映射表:table = ''.maketrans(string1, string2)
2、开始映射:new_string = string.translate(table)
>>> table = ''.maketrans('12345', '一二三四五')
>>> string = '42352346'
>>> new_string = string.translate(table)
>>> new_string
'四二三五二三四6'
>>> table
{49: 19968, 50: 20108, 51: 19977, 52: 22235, 53: 20116}
凯撒加密解密
from string import ascii_letters, ascii_lowercase, ascii_uppercase
def kaisaEncrypt(string, k):
# 每个字母替换为后面k个
new_lower = ascii_lowercase[k:] + ascii_lowercase[:k]
new_upper = ascii_uppercase[k:] + ascii_uppercase[:k]
table = ''.maketrans(ascii_letters, new_lower + new_upper)
new_string = string.translate(table)
return new_string
# 是否解密成功
def check(temp_string) -> bool:
# 不唯一:我们对每次尝试解密的结果测试是否含有至少两个常见单词,若有,则认为解密成功
mostCommonWords = ('the', 'is', 'to', 'not', 'have', 'than', 'for', 'like')
# 如果word在temp_string中,则元祖放一个1
return sum(1 for word in mostCommonWords if word in temp_string) >= 2
def kaisaDecrypt(new_string):
# 加密是后移字母,一共有26种情况,一一测试
for i in range(1, 26):
temp_string = kaisaEncrypt(new_string, -i)
if check(temp_string)== True:
return temp_string
if __name__ == '__main__':
string = "Python is a greate programming language. I like it!"
new_string = kaisaEncrypt(string, 3)
print(kaisaDecrypt(new_string))
从外向里删除指定若干字符:[r]strip
- 一般用于提取每行文本取出空格
new_string = string.strip(字符/字符串)
规则:看外侧有啥,再看参数有没有该字符,有则删除,没有则删不掉
无参数:相当于参数为空白字符
- 外侧有空白字符,参数也是空白字符,删除成功,剩下hello world,外侧为h、w,参数没有。剩下hello world
>>> ' hello world '.strip()
'hello world'
单个字符参数
- 外侧有d、f,参数没有,删除失败
>>> 'dffdfaaafff'.strip('a')
'dffdfaaafff'
- 外侧有a,参数有a,删除成功
>>> 'afffaffaa'.strip('a')
'fffaff'
字符串参数
- 先看外侧有a和c,参数 含有a,即只需要含有,不看顺序 ,则删除,得到:ddfffccc;
- 然后外侧有d和c,参数没有,仍然是ddfffccc
>>> 'aaaddfffccc'.strip('af')
'ddfffccc'
- 例:结果是全部删掉了
>>> 'aabbccddeeeffg'.strip('gbaefcd')
''
rstrip, lstrip:只看右/左外侧
- 左边外侧有a,参数有a。
>>> 'aadfaaffffaaddaa'.lstrip('a')
'dfaaffffaaddaa'
>>> 'aadfaaffffaaddaa'.rstrip('a')
'aadfaaffffaadd'
文本规范化输出
规范化每行输出:姓名:张三…
>>> text = '''姓名:张三
年龄:39
性别男
职业 学生
籍贯: 地球'''
>>> lst_lines = [line.strip() for line in text.split('\n')]
>>> lst_lines
['姓名:张三', '年龄:39', '性别男', '职业 学生', '籍贯: 地球']
>>> for item in lst_lines:
print(item[:2], item[2:].strip(': '), sep = ':')
姓名:张三
年龄:39
性别:男
职业:学生
籍贯:地球
eval(string)的两大功能
参数必须是字符串!
1、计算字符串表达式的值:eval(string)
tip: 经leetcode解题过程发现:
eval链接字符串运算比直接int(string)再做运算,或者ord(‘string’)-ord(‘0’)慢的多
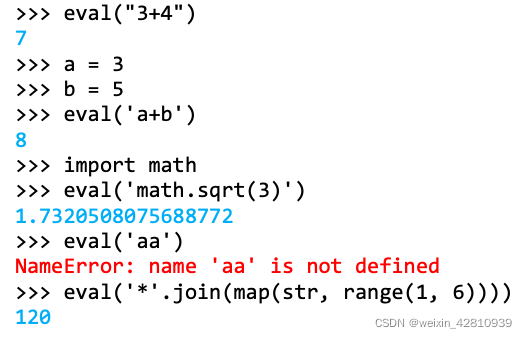
2、得到字符串内元素的原本格式
判断eval内的string是否是合法输入
- 元祖的特殊形式
>>> 1,2,3
(1, 2, 3)
>>> 1,2,
(1, 2)
- 字符串元祖—>元祖
>>> eval('1,2,')
(1, 2)
>>> eval('1 2')
Traceback (most recent call last):
File "<pyshell#98>", line 1, in <module>
eval('1 2')
File "<string>", line 1
1 2
^
SyntaxError: unexpected EOF while parsing
- 易错点:'string’传入的string只是一个变量,“‘string’”
>>> eval('string')
Traceback (most recent call last):
File "<pyshell#96>", line 1, in <module>
eval('string')
File "<string>", line 1, in <module>
NameError: name 'string' is not defined
>>> eval("'string'")
'string'
转义符号:\,r
一般\n, \t算一个字符,如果加上转义符号r或者 \则变成单纯两个字符:\ 和n
>>> len(r'\ngood')
6
>>> len('\\ngood')
6
>>> len('\ngood')
5
字符串s=‘a\nb\tc’,则len(s)的值是( )。C
A.7 B.6 C.5 D.4
Python语句print(r"\nGood")的运行结果是( \nGood )。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











