






谷歌发现LLM是Greedy Agent,提出用RL调教出理性决策
原创 编辑部 深度学习自然语言处理 2025年04月27日 21:32 江苏
大模型的“决策短板”从何而来?
大语言模型(如ChatGPT、Gemma2)在文本生成、代码编写等领域大放异彩,但当它们被用作“智能体”做决策时,却常犯低级错误:比如玩井字棋胜率只有15%(不如随机玩家),或在老虎机任务中反复选择同一个低收益选项。

论文:LLMs are Greedy Agents: Effects of RL Fine-tuning on Decision-Making Abilities
链接:https://arxiv.org/pdf/2504.16078
这篇论文揭开了背后的三大“性格缺陷”:贪婪性、频率偏差和知行差距,并通过强化学习微调(RLFT)结合思维链(CoT),让LLM的决策能力实现质的飞跃。
三大失败模式
贪婪性:LLM的“路径依赖”
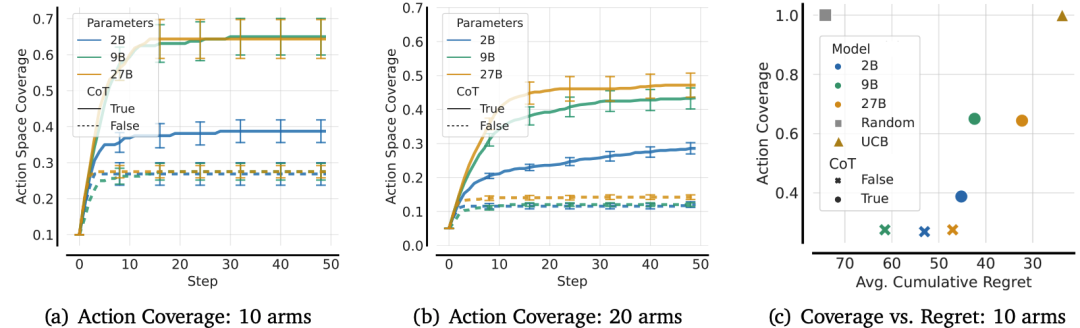
就像人类炒股时过早抛售潜力股,LLM会迅速锁定早期高收益动作(如老虎机的某个拉杆),后续不再探索其他选项。实验显示:
-
在10个选项的任务中,LLM平均只探索65%的动作
-
20个选项时,覆盖率暴跌至45%
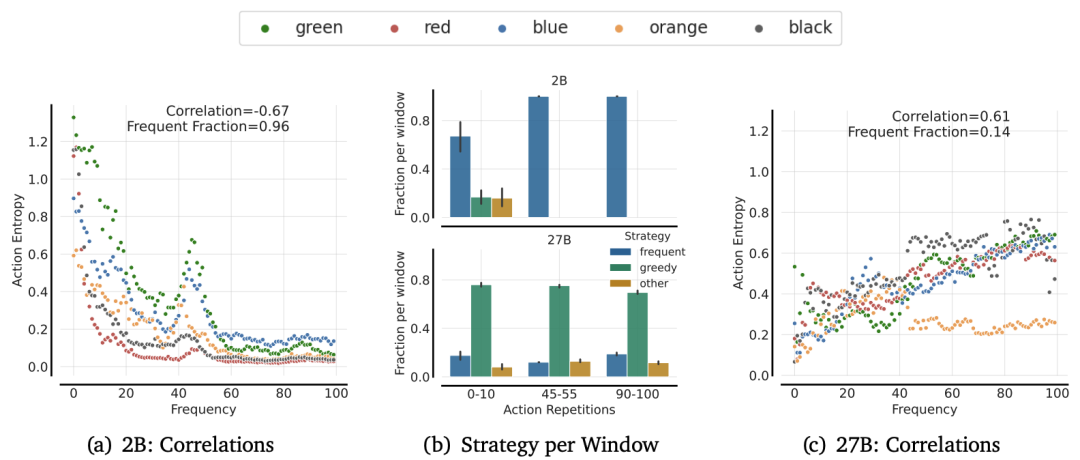
频率偏差:迷信“高频动作”
小规模模型(如2B参数)尤其明显:如果某个动作在历史记录中出现次数多(比如连续按“蓝色按钮”10次),即使它收益低,LLM仍会盲目选择。
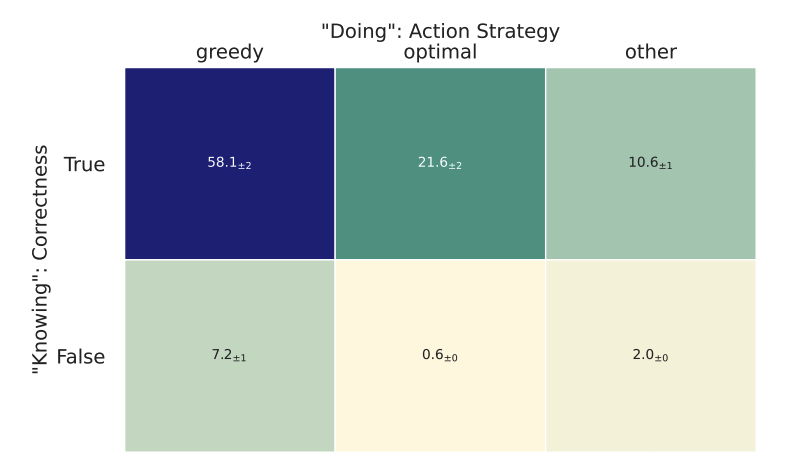
知行差距:懂道理却做不到
LLM能正确推演最优策略(如计算UCB值),但行动时却选择次优选项。例如:
-
87%的思维链推理正确
-
但正确推理中,64%的实际动作与推理结果矛盾
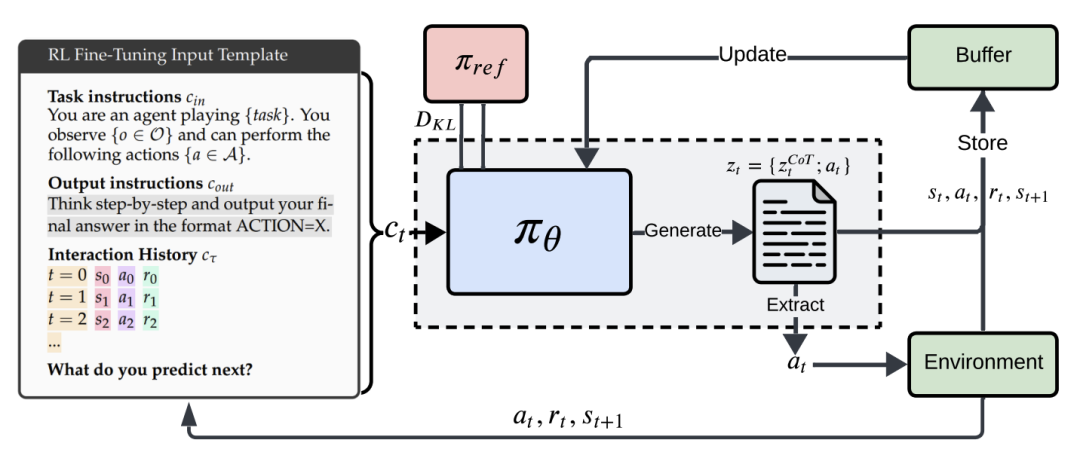
破解之道:强化学习微调+思维链
论文提出“决策日记训练法”:
-
让LLM写思维链:生成包含推理过程的文本(例如:“按钮A的UCB值=收益均值+探索奖励√(ln(t)/使用次数)”)
-
用环境反馈奖励微调:通过强化学习(PPO算法)奖励高收益决策,惩罚无效动作
关键公式(简化版):
优化目标奖励最大化与原始模型的相似度
其中β控制“创新探索”与“保守稳定”的平衡。
实验验证
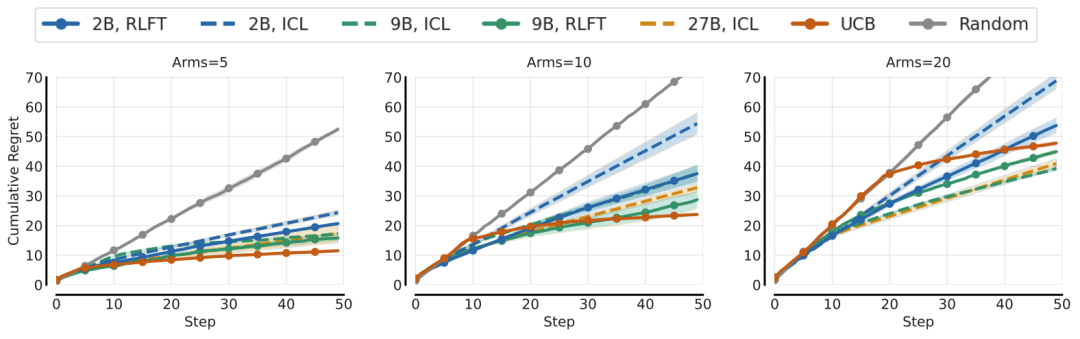
多臂老虎机:从“菜鸟”到“高手”
-
经过RLFT微调的2B小模型,动作覆盖率提升12%
-
累计后悔值(与最优策略的差距)显著降低
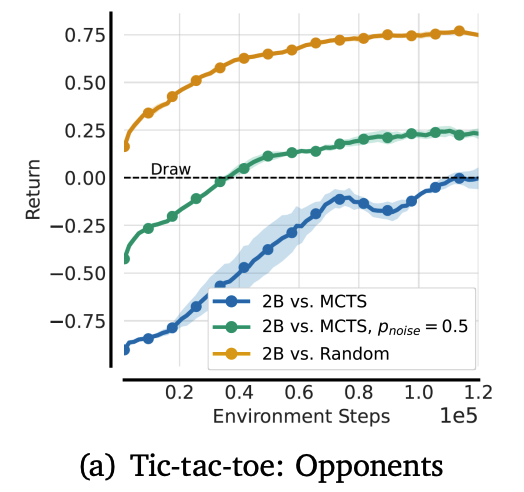
井字棋对战:逆袭之路
-
对抗随机玩家:胜率从15%→75%
-
对抗MCTS算法:从几乎全败到平局
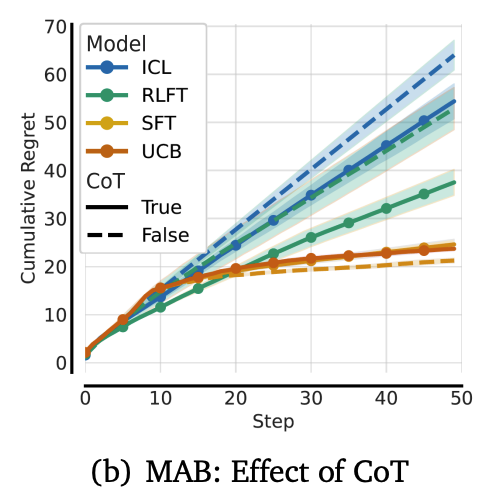
思维链的重要性
去掉思维链后,模型表现倒退至微调前水平,证明CoT是“有效思考”的关键。
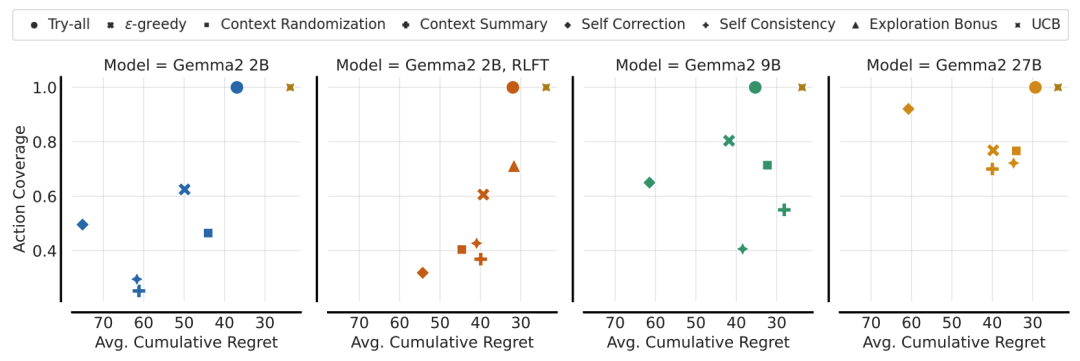
进阶:让LLM学会“主动思考”
论文尝试了多种增强探索的方法:
-
经典RL技巧:ε-贪婪策略(10%概率随机探索)
-
LLM专属优化:
-
自我纠错:生成多轮推理并投票选择最佳动作
-
上下文随机化:打乱动作标签破除语义偏见
-
实验结果:结合探索奖励(+1奖励未尝试动作)效果最佳,覆盖率提升至70%。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











