







Python基础
- 列表、元组、字典、集合的异同
Pandas
基础
Series/DataFrame创建
- 基础创建、多列计算得到新列
# Series
s1 = pd.Series([1,2,3.0,4],index=list('abcd'),dtype='int32',name='s2')
dict = {'apple':'red','banana':'yellow'} # key==》index,value==》value
s2 = pd.Series(dict)
# Series to DataFrame
s2.to_frame()
# DataFrame
df1 = pd.DataFrame(np.arange(25).reshape(5, 5),
index = ['row1', 'row2','row3','row4','row5'],
columns=['col1', 'col2','col3','col4', 'col5'])
dict = {'id':[1,2,3,5],'comment':['a','b','','d'],'name':list('ABCD')}
df2 = pd.DataFrame(dict,index=['China','England','Japan','Korea']) # dict's key ==> column name
# df1新增col,两者有什么区别?
df1 = df1.assign(new_col=lambda df1: df1.col1*df1.col2)
df1['new'] = df1.col1**2+df.col2
# multiIndex
indexs = pd.MultiIndex.from_tuples(
[('a', 1), ('b', 2),('c', 3),('c', 2),('e', 5)], names=['index1','index2'])
df1.index=indexs
删除行/列
df.drop([col1,col2])
如果要删除列,要添加axis=1
基础切片
data[]——sad
缺点:行列没法组合用
data[['col1','col2']] # 取多列
data[0:2] # 取第1、2行
iloc()基于位置,整数索引
loc是location的意思,i可以当作integer加强记忆,因此iloc只能用整数索引「iloc比loc多了I,所以索引的时候可以少打=用整数来表示行列」
data.iloc[:,1] # 取单列
data.iolc[1,:] # 取单行
data.iloc[0:2,[1,3]] # 取连续行「不用[]」,取多列(非联系列)
loc()基于标签,用行/列名进行索引
data.loc[['row1','row2'],'col1':'col2'] # 取连续列
ix()(不推荐:在iloc、loc之前的产物)iat、at(不推荐:只能取单个元素——at使用行、列名;iat使用行、列索引)
高阶切片
Boolean切片
# 逻辑关系:& | ~
df1[(df1.col3>=12)&(df1['col4']<=18)]
df1.loc[df1.col2>=11,'col2':'col4']
使用query
df1.query('col1 > 7')
df1.query('col1 > 7 or col2 <= 16')
随机抽样
df.sample(n=10) / df.sample(frac=0.5)
filter
df.filter(regex='str')使用正则匹配
索引
df.rename()# 重命名行/列索引名字- 两种修改方式:
- (index=index_mapper, columns=columns_mapper, …)
- (mapper, axis={‘index’, ‘columns’}, …)
df = pd.DataFrame({"A": [1, 2, 3], "B": [4, 5, 6]})
df.rename(columns={"A": "a", "B": "c"})
df.rename(index={0: "x", 1: "y", 2: "z"})
df.set_index('A')# set the index:将A列作为索引df.reset_index()# 重置索引。set_index()的反向操作:分层索引的索引层级被还原回列
@
Drop:bool,default F。是否删掉回列的索引
@inlace:bool,default F。
df.reindex()# 重排索引:行/列索引。重排方式:更改顺序;新增加索引没有对应值,默认为nan;减少索引(等价切片,如果传入的list小于df)
DataFrame.reindex(
labels=None,
index=None, # 重排index
columns=None, # 重排col
method=None, # method{None, ‘backfill’/’bfill’, ‘pad’/’ffill’, ‘nearest’}
axis=None, copy=True, level=None, fill_value=nan, limit=None, tolerance=None)

数据类型
- df.dtypes 查看字段数据类型
- df[‘a’].astype(‘float’) 数据类型转化
排序
df.sort_values()
@
by: 指定列名/索引名(要对应axis)
@axis= 0(default), =1
@ascending=True(default-升序)
@na_position: {first, last}, 设定缺失值的显示位置
df.rank()
@
axis=0,
@method: {average, min, max, first, dense}
average: average rank of the group: 1, 2, 3.5, 3.5, 5
min: lowest rank in the group: 1, 2, 3, 3, 5
max: highest rank in the group: 1, 2, 4, 4, 5
first: ranks assigned in order they appear in the array: 1, 2, 3, 4, 5
dense: like ‘min’, but rank always increases by 1 between groups: 1, 2, 3, 3, 4
@numeric_only: bool,是否只排数字列
@ascending:bool
@pct:bool,default False. 是否显示百分比
@na_option: {‘keep’, ‘top’, ‘bottom’}, default ‘keep’ 空值保留空值、排第一、排底部
df.sort_index()# court by labels along on axis
summarize data
- 常用属性/方法
# basic
df.head(n) / df.tail(n)
df.shape # 查看df的行/列#
len(df) # 查看df的行
df.index
df1.columns.to_list()
df.info() # 查看数据类型、cnt#、非空值
df.describe() # 查看cnt、mean、std、四分位数
df[['col1','col2']].nunique() # 计算每列有几个“不同的值”
df['col1'].value_counts() # 计算每个值有几个“记录”
# summary
df.count() # cnt非空值
df.sum()
df.cumsum() # 累加
df.min()/df.max()
df.mean() # 取平均,如果有空值不会算进平均
# 统计
df.median() # 取中位数,如果有空值会跳过
df.quantile([0.25,0.75]) # 取分位数,比describe灵活可以选择axis
df.var() # 计算方差(Variance)
df.std() # 计算标准差(Standard Deviation)
df.idxmax()/df.idxmin() # 取最小/最大的index value?
透视表功能
df.groupby
(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=NoDefault.no_default, observed=False, dropna=True)
@level: 当df是多维度索引时,可以用level参数进行第i层索引聚合
补充:size(), transform(), agg()
## Aggregation
- 常规用法:
df.groupby(['col1','col2']).mean() # sum(),count()
df.groupby(['col1']).size() # size of each group
- 不同字段实现不通聚合-基础 # 结果是二级索引
f = {'ado':['sum'], 'seller':['count']}
df.groupby('country').agg(f)
- 不同字段实现不通聚合-改名
df.groupby('country').agg(
ado_sum=('ado','sum'),
seller_cnt=('seller','count'),
ado_range=('ado',lambda x: x.max()-x.min()
)
## Transformation,
- 常规
df.transform(lambda x:(x+x%2))
- 高阶:求行/列分布
df1.transform(lambda x: x/x.sum(), axis=0) # 列的分布情况
df1.transform(lambda x: x/x.sum(), axis=1) # 行的分布情况
pd.pivot_table 更像透视表
pandas.pivot_table( data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False, sort=True)
<==>df.pivot_table(values, index...)
# 基础:
table = pd.pivot_table(df, values='D', index=['A', 'B'],
columns=['C'], aggfunc=np.sum, fill_value=0)
# 进阶:
table = pd.pivot_table(df, values=['D', 'E'], index=['A', 'C'],
aggfunc={'D': np.mean,
'E': [min, max, np.mean]})
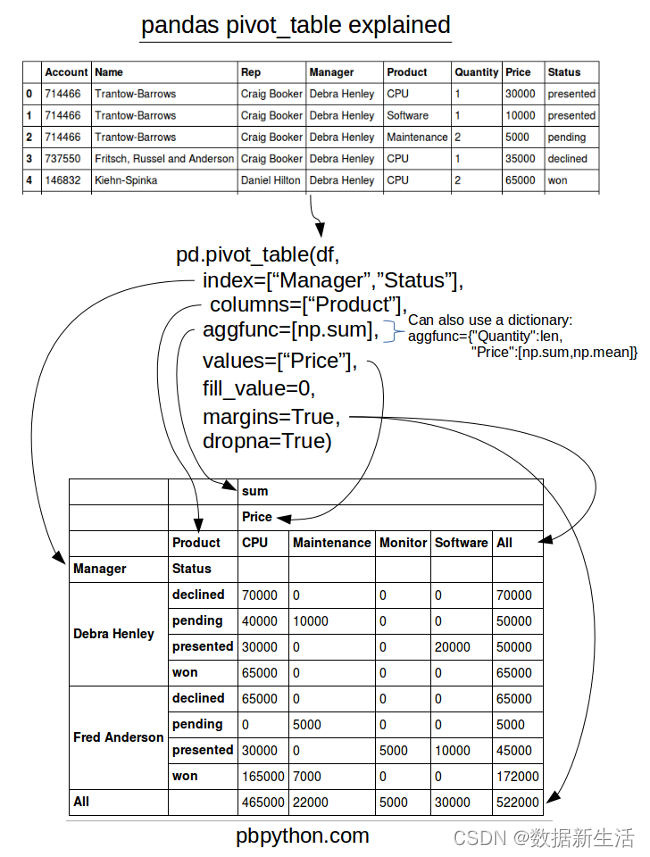
pd.pivot: reshape data
pandas.pivot(data, index=None, columns=None, values=None)
没有聚合函数,仅是row转column,不能有重复的行列。pivot其实可以被pivot_table替代
df.stack() 堆积/ df.unstack()
stack列转行,unstack行转列

df.melt()
作用与df.stack类似。均可以通过pivot的方式还原。
区别
- df.stack()⇒ 列转行,列名会成为index,需要从series转为dataframe
- df.melt()⇒ 列转行,列名成为1列的值,默认忽略index;更灵活可以指定
pandas.melt(frame,
id_vars=None, # identifier variables 标识变量
value_vars=None, # Column(s) to unpivot. 如不指定所有剩余字段展开
var_name=None, # use for the ‘variable’ column
value_name=‘value’, # use for the ‘value’ column.
col_level=None, ignore_index=True)
append:https://www.gairuo.com/p/pandas-melt
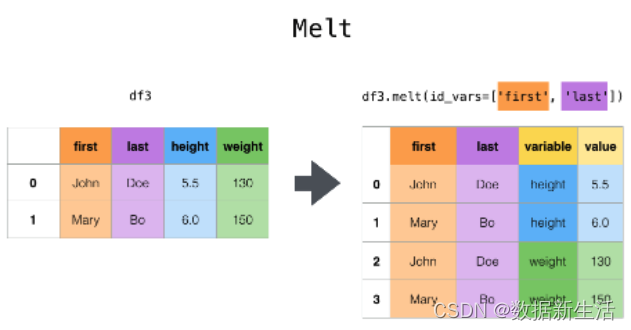
combining data
pd.merge(df1, df2, how, on) <==> df1.merge(df2, how, on)
pd.merge(right, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=(‘_x’, ‘_y’), copy=True, indicator=False, validate=None)
默认重叠列拼接
@how: {‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’}, default ‘inner’
@on/left_on/right_on:join的key
@suffixes: 相同字段的后缀
df1.join(other_df2, on=None, how='left', lsuffix='', rsuffix='', sort=False功能与merge类似
默认行索引拼接,重叠列拼接(没啥区别?)
@how: {‘left’, ‘right’, ‘outer’, ‘inner’}, default ‘left’
@sort: 是否根据连接的键进行排序
pd.concat()
用于多个df行方向/列方向的拼接(Vertical/Horizontal)
pandas.concat(objs, axis=0, join=‘outer’, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=False, copy=True)
@
objs:[df1,df2,…]
@axis:=1时,会根据索引进行拼接
@join: {‘inner’, ‘outer’}, default ‘outer’
@ignore_index:True, 会重新索引
@key:指定用作“层次化索引”各级别上的索引
@name:行索引的名字
特殊应用:pd.concat([pd.DataFrame([i], columns=['A']) for i in range(5)], ignore_index=True)
df.append()数据纵向堆叠的拼接(Vertical)
DataFrame.append(
other, # 待合并的数据。可以是pandas中的DataFrame、series,或者是Python中的字典、列表这样的数据结构
ignore_index=False,
verify_integrity=False, # 默认是False,如果值为True,创建相同的index则会抛出异常的错误
sort=False)
iteration
df.iteritems() # (index-column name, Series)pairs
df.iterrows() # (index-row name, series) pairs
高阶用法
missing data
df.dropna()
@
axis: {0 or ‘index’, 1 or ‘columns’}, default 0
@how: {‘any’, ‘all’}, default ‘any’
@thresh: int, optional(至少几个非空保留)
@subset: ***index / columns (哪几列/行判断是否NA)
@inplace: bool, default False
-
df.fillna() -
df.isnull()
应用:判断某列为空的赋值为0df.loc[df['ado'].isnull(),'ado']=0 # df要是copy版本才行,不知道为什么( chained indexing链式索引?) -
df.notna() -
df.replace("a","b")
(to_replace=None, value=NoDefault.no_default, inplace=False, limit=None, regex=False, method=NoDefault.no_default)
@to_replace: 待替换掉的数据(str, regex, list, dict, Series, int, float, or None都可以;正则也行)
@value: 用value来替换掉to_replace
@method:{‘pad’, ‘ffill’, ‘bfill’, None},当value为空时,ffill靠前面的填充;bfill靠后面的填充;pad等价ffill?
duplicate data
s3.unique()#Return unique values,series去重,df不行df.duplicated(subset=None, keep='first')# check duplicates
@
subset: index / columns (哪几列/行判断是否重复)
@keep: {‘first’, ‘last’, False} (保留前值还是后值)
@return: T/F
first表示第二次出现为重复值(标记为T);last表示前面出现为重复值(标记为T);false表示每个都为重复值
df.drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False)# drop duplicates
@
ignore_index: 重新索引
drop data
df.drop()
时间函数
to_datetime()
df2['Date']= pd.to_datetime(df2['Date'])
strftime strptime的区别
- f 是“format”缩写, p是"parse"缩写, (分别代表“格式化”和“解析”)
- strftime 和strptime 都需要接收一个参数format格式化字符串, 但是作用刚好是相反
- strftime 根据指定的format把一个"python可以识别的时间类型"格式化为"时间字符str"
- strptime根据指定的format把一个"时间字符串str"解析为“python可以识别的时间类型date”
now = datetime.now() # datetime
print(now, type(now))
res_f = datetime.strftime(now, "%Y-%m-%d") # str
res_p = datetime.strptime("2021-03-12", "%Y-%m-%d") # datetime
# 应用:
CustData['Date1']=list(map(lambda x:datetime.strptime(x, '%Y/%m/%d'),CustData['Date']))
# 计算日期差
today = datetime.datetime.today().date()
specific_d = datetime.datetime.strptime('2022-04-19', "%Y-%m-%d").date()
days = specific_d - today
# 明天
print(today+datetime.timedelta(days=1))
# 昨天
print(today+datetime.timedelta(days=-1))
Appendix: time, datetime, strptime和strftime的区别
date_range()
pd.date_range(
start=None, # ‘20200201’
end=None, # ‘20200205’
periods=None, # int, 固定日期范围 start + periods搭配使用
freq=None, # default ‘D’ – 日偏移;‘B’ – 工作日偏移; ‘M’ – 每月最后一日;‘MS’–每月第一天
tz=None, normalize=False, name=None, closed=NoDefault.no_default,
inclusive=None, # {“both”, “neither”, “left”, “right”}, default “both” 开闭
**kwargs)
df1['date'] = pd.date_range('2022-01-01', periods=2,freq='M')
# 输出:2022-01-31, 2022-02-28
df1[‘date’] = pd.date_range(‘2022-01-01’, periods=5,freq=‘M’)
Numpy
文件读写
查看文件夹
路径查看
os.path.abspath()/os.path.abspath(.)读取当前文件路径os.path.abspath('..')查看本脚本上层所处的文件夹os.getcwd()读取当前文件路径
查看当前文件夹下的文件
os.listdir()# 列出所有files or folder in current folder
删除文件、文件夹
import os
import shutil
os.remove(path)#删除文件,path指路径os.removedirs(path)#删除空文件夹os.rmdir(path)#删除空文件夹shutil.rmtree(path)#递归删除文件夹,即:删除非空文件夹,该包有更多文件操作
创建新“文件夹”
import os
folder = os.getcwd() + '/test_data'
#获取此py文件路径,在此路径选创建test_data文件夹
if not os.path.exists(folder):
os.makedirs(folder)
读、写文件
读取文件
df=pd.read_csv(path1,encoding='gbk')df=pd.read_excel(path)
写入文件
to_excel单sheet输出、多sheet输出
root = os.getcwd()
path = root + '/data/test.xlsx'
df1 = pd.DataFrame(np.arange(8).reshape(2,4))
df2 = pd.DataFrame(np.arange(12).reshape(2,6))
# 单sheet
df1.to_excel(path)
# 多sheet输出
writer = pd.ExcelWriter(path)
df1.to_excel(writer,'df1')
df2.to_excel(writer,'df2')
writer.save()
循环、函数、类
1. 循环
循环
if语句
if condition1:
执行条件1
elif condition2:
执行条件2
else:
执行条件3
for/while语句
for i in range(1,10,3):
...
else:
...
#########################################################
j = 0
while j<10&j>5:
...
else: #else也属于循环内部,for/while遍历结束,进入else, 如果break,就跳出循环,也就跳过了else
...
break vs continue
break跳出当前循环,并跳出整个循环continue跳过当前循环,直接开始下一次循环,即没跳出整个循环
2. 函数
- 定义def 函数名(参数)
- 调用函数名(参数值)
Lambda
lambda可以跟任意个参数
:之后的内容相当于return后面的内容
# 1)多参数
`lambda x,y: (x+y)*2`
# 2)与if语句联合使用
lambda x: 1 if x>=2 else 0
# 3)高阶:lambda 与 map结合
f = lambda x: 1 if x>=2 else 0
list(map(f,[1,2,3])) # output: [0, 1, 1]
list(map(lambda x: 1 if x>=2 else 0,[1,2,3])) # 与上面等价
map(f,a)
将函数f依次套用在a(可枚举类型)的每个元素上;并返回map对象;map对象可转化为list或用遍历将其显示
list(map(lambda x:x+1, [i for i in range(3)])) # output:[1,2,3]
reduce(f, iterable) need to study more
对参数序列中的元素进行累计
from functools import reduce
reduce(lambda x,y:x+y, [1,2,3]) # 6=1+2+3
reduce(lambda x,y:x**y, [3,2,1]) # 9=3**2**1
apply()
apply() 使用时,通常放入一个 lambda 函数表达式、或一个函数作为操作运算:
DataFrame.apply(self, func, axis=0, raw=False, result_type=None, args=(), **kwds
@func代表的是传入的函数或 lambda 表达式;
@axis参数可提供的有两个,该参数默认为0/列
- 0 或者 index ,表示函数处理的是每一列;
- 1 或 columns ,表示处理的是每一行;
@raw ;bool 类型,默认为 False;
- False ,表示把每一行或列作为 Series 传入函数中;
- True,表示接受的是 ndarray 数据类型;
参考:https://zhuanlan.zhihu.com/p/340770847
df.apply(np.mean,axis = 1) # dataframe.apply
df.A = df.A.apply(lambda x:x+1) # series.apply
3. 类
描述具有相同的属性和方法的对象的集合。它定义了集合中每个对象所公有的属性和方法,对象是类的实例。
- 比喻:
类——模板(方法)
对象——类——模板(方法) - 实例:
类:车
对象:宝马、奥迪
属性:发动机、底盘、车轮
方法:测速、变速、转变方向
# 创建类
class 类名称(object):
pass
# 实例化
A=sutdent('Tom',24)
B=student('Jack',45,score=91) # 对类student实例化,A,B就是实例化后的对象
# 创建类
class Student(object):
def __init__(self,name,scoreList):
self.name=name # 类的初始化
self.scoreList=scoreList
def total_score(self): # 类的方法
res=sum(self.scoreList)
return '学生姓名:%s,总成绩:%s'%(self.name,res)
# 实例化
A=Student('Emma',[67,89,51])
print(A.total_score()) # output:学生姓名:Emma,总成绩:207
B=Student('FanZhou',[90,95,99])
print(B.total_score()) # output:学生姓名:FanZhou,总成绩:284
str = 'abcd' # str表字符串的实例化
str.index('c') # str的index方法, output: 2
# python的一切都是对象
4. 模块
模块是一个包含所有你定义的函数和变量的文件,其后缀是.py。模块可以被别的程序引入,以使用该模块中的函数等功能
- 模块的引用:
import math - to do:是否可以将现在的工作内容模块化
from ScoreRate import rt# 导入的模块要在同一文件夹
数据格式显示
import pandas as pd
pd.set_option('display.max_columns', None) # 显示完整的列
pd.set_option('display.max_rows', None) # 显示完整的行
pd.set_option('display.expand_frame_repr', False) # 设置不折叠数据
pd.set_option('display.max_colwidth', 100)
pd.set_option('display.float_format',lambda x : '%.1f' % x) # 避免显示科学计数法
# pd.get_option("max_info_columns") # 目前最大info列数
pd.set_option("display.max_info_columns", 200) # 设置info中信息显示数量为200
tool
批量合并图片
import PIL.Image as Image
import os
def get_images_names_list(IMAGES_PATH):
'''
@功能::::::读取路径下所有图片的名称列表,并按照创建时间排序
@IMAGES_PATH 图片集路径
'''
# 准备: 图片格式
IMAGES_FORMAT = ['.jpg', '.JPG', '.png']
# 得到 image name list
image_names = [name for name in os.listdir(IMAGES_PATH) for item in IMAGES_FORMAT if
os.path.splitext(name)[1] == item]
image_names.sort(reverse=False)
return image_names
def image_compose(IMAGE_SAVE_PATH,IMAGES_PATH,image_names,IMAGE_ROW,IMAGE_COLUMN=1,IMAGE_COLUMN_SIZE=3583,IMAGE_ROW_SIZE=2240):
'''
@功能::::::定义图像拼接函数
@IMAGE_ROW 合并图片后的行数
@IMAGE_COLUMN 合并图片后的列数
@IMAGE_COLUMN_SIZE 单个图片的行像素
@IMAGE_ROW_SIZE 单个图片的列像素
@IMAGE_SAVE_PATH 合并后图片的保存路径
'''
# 1. 创建一个新图
to_image = Image.new('RGB', (IMAGE_COLUMN * IMAGE_COLUMN_SIZE, IMAGE_ROW * IMAGE_ROW_SIZE))
# 2. 循环遍历,把每张图片按顺序粘贴到对应位置上
for row in range(1, IMAGE_ROW + 1):
for col in range(1, IMAGE_COLUMN + 1):
# 第几张图片=列数*实际函数+实际列数
n = IMAGE_COLUMN * (row - 1) + col - 1
if n+1>len(image_names):
break
print(image_names[n])
# 读取图片
from_image = Image.open(IMAGES_PATH + image_names[IMAGE_COLUMN * (row - 1) + col - 1]).resize(
(IMAGE_COLUMN_SIZE, IMAGE_ROW_SIZE),Image.ANTIALIAS)
# 拼接
to_image.paste(from_image, ((col - 1) * IMAGE_COLUMN_SIZE, (row - 1) * IMAGE_ROW_SIZE))
# 3. 保存新图
print('save image')
return to_image.save(IMAGE_SAVE_PATH)
root = '/Users/xx/Desktop/'
path = root
image_names = get_images_names_list(path)
# save_path = root
k=14
save_path = root + 'final0.png'
image_compose(IMAGE_ROW=7,IMAGE_COLUMN=2,IMAGE_SAVE_PATH=save_path,IMAGES_PATH=root,image_names=image_names[:k]) #调用函数
# print('0-end')
# k=k+10
# save_path = root + 'final1.png'
# image_compose(IMAGE_ROW=5,IMAGE_COLUMN=2,IMAGE_SAVE_PATH=save_path,image_names=image_names[k-10:k]) #调用函数
# print('1-end')
# k=k+10
# save_path = root + 'final2.png'
# image_compose(IMAGE_ROW=5,IMAGE_COLUMN=2,IMAGE_SAVE_PATH=save_path,image_names=image_names[k-10:k]) #调用函数
# print('2-end')
# k=k+10
# save_path = root + 'final3.png'
# image_compose(IMAGE_ROW=5,IMAGE_COLUMN=2,IMAGE_SAVE_PATH=save_path,image_names=image_names[k-10:k]) #调用函数
# print('3-end')
# save_path = root + 'final4.png'
# image_compose(IMAGE_ROW=2,IMAGE_COLUMN=2,IMAGE_SAVE_PATH=save_path,image_names=image_names[k:k+3]) #调用函数
# print('4-end')
图片合并,四张一页,转PDF
from PIL import Image
import os
def combine2Pdf(folderPath, pdfFilePath):
files = os.listdir(folderPath)
pngFiles = []
sources = []
for file in files:
if 'png' in file:
pngFiles.append(folderPath + file)
pngFiles.sort()
first_index = pngFiles.index('/Users/xxxx/Desktop/截屏2023-12-03 21.09.51.png') # 查找第一张照片位置
pngFiles=pngFiles[first_index:]
num_images = len(pngFiles)
for i in range(0, num_images, 4):
page_sources = []
for j in range(i, min(i+4, num_images)):
pngFile = Image.open(pngFiles[j]).convert("RGB")
page_sources.append(pngFile)
output = Image.new("RGB", (page_sources[0].width * 2, page_sources[0].height * 2)) # 一页大小
for k, source in enumerate(page_sources):
left = source.width * (k % 2) # 图谱左上角起点
upper = source.height * (k // 2) # 图片左上角高起点
output.paste(source, (left, upper))
sources.append(output)
sources[0].save(pdfFilePath, save_all=True, append_images=sources, optimize=True, quality=30)
return pngFiles
if __name__ == "__main__":
folder = "/Users/xxxx/Desktop/"
pdfFile = "/Users/xxxx/Desktop/营养餐D15-D18.pdf"
files = combine2Pdf(folder, pdfFile)
# print(files)















 2793
2793











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









