







 本文探讨了深度学习中的数值稳定性问题,涉及矩阵乘法中的学习率调整、权重初始化的重要性(如Xavier初始化)、激活函数选择(如ReLU与sigmoid),以及批标准化等手段来确保模型训练的稳定性。文章还提到如何通过调整学习率、初始权重分布和使用合适的激活函数来防止梯度爆炸和消失现象。
本文探讨了深度学习中的数值稳定性问题,涉及矩阵乘法中的学习率调整、权重初始化的重要性(如Xavier初始化)、激活函数选择(如ReLU与sigmoid),以及批标准化等手段来确保模型训练的稳定性。文章还提到如何通过调整学习率、初始权重分布和使用合适的激活函数来防止梯度爆炸和消失现象。
动手学深度学习14 数值稳定性+模型初始化和激活函数
**视频:**https://www.bilibili.com/video/BV1u64y1i75a/?spm_id_from=autoNext&vd_source=eb04c9a33e87ceba9c9a2e5f09752ef8
**电子书:**https://zh-v2.d2l.ai/chapter_multilayer-perceptrons/numerical-stability-and-init.html
**课件:**https://courses.d2l.ai/zh-v2/assets/pdfs/part-0_18.pdf
这一章不好理解,数学推理较多。
1. 数值稳定性

向量关于向量的导数是矩阵

数值问题:做了太多次的矩阵乘法



学习率比较难调,要在很小的范围内调整,过大过小都会给模型训练带来麻烦

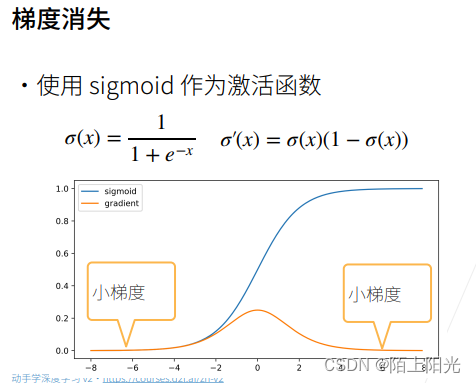



2. 模型初始化和激活函数
如何让训练更稳定

归一化:强行把梯度值到一定范围内的值
不论那一层做多深,均值方差都是固定的,保证数据都在一定范围内。
越陡的地方梯度越大
均值为0,方差为0.01的正太分布随机初始权重,对小网络可以,对很深的网络可能方差过大或过小。



假设权重独立同分布,假设当前层权重和当前层输入是独立事件
所有项独立同分布,所以所有交叉项的和为0

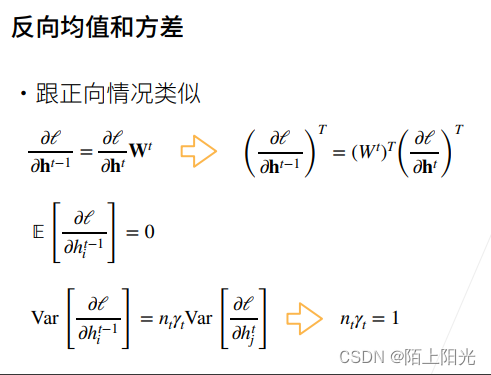
假设均值都是0,方差都是一个常数值,要满足两个条件。
n
t
−
1
n_{t-1}
nt−1 第t层输入的维度
n
t
n_t
nt 第t层的输出的个数,两个条件很难满足,除非输入等于输出才能满足两个条件。
γ
t
γ_t
γt 是第t层权重的方差。
权重初始化的方差,是根据输入输出的维度来确定的。当输入输出维度不一致或者网络变化比较大的情况下,是根据输入输出的维度来适配权重shape,希望梯度和输出的方差在一定范围内。

输入均值为0,要使期望等于0,激活函数一定是过原点的。
泰勒展开式,用一个多项式逼近,做低阶近似。


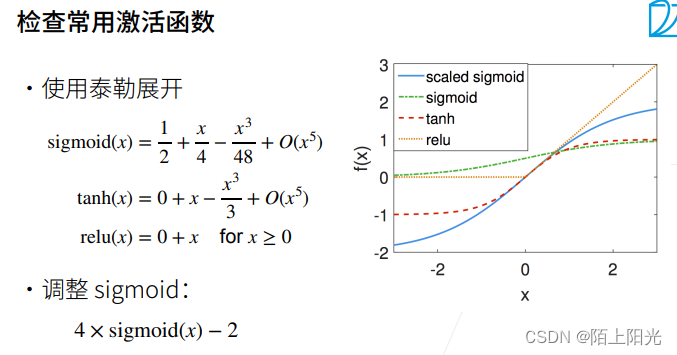

3. QA
- nan inf是怎么产生的以及怎么解决呢?
inf是lr太大导致的,梯度爆炸。nan是一个数除以0了。合理初始化权重+激活函数合理选取+lr不要太大解决问题。可以先把lr往很小调,直到不出现nan或者inf,或者权重初始值,不要让方差很大,等训练有进展再调整。 - 使用ReLU激活函数如何做到拟合x平方或者三次方这种曲线?
ReLU+ 权重去拟合,relu就是取max{0,x},破坏线性。 - 如果训练一开始,在验证集上准确率在提升,训练两个epoch后,突然验证集准确率就变成50%左右并稳定在50%,这是为什么呢?
一般是权重紊乱掉了,数值稳定性出现了问题。可以把学习率调小。如果学习率调小不能解决问题,可能是训练数据本身不稳定。 - 训练过程中,如果网络的输出的中间层特征元素的值突然变成nan,是发生了梯度爆炸吗?还是有什么其他可能的原因?唤醒训练中遇到方差有nan值,是什么原因?
一般是发生了梯度爆炸,如果太小训练曲线是平的没有什么进展。 - 初学者遇到一些复杂的数学公式,看文字描述没有什么感觉,怎么突破知识壁垒呢?
深度学习的好处不懂数学也能用很多东西。数学能力–理解能力。计算机内存和cpu频率,cpu频率决定单位时间能算多少数据–代码能力。内存决定能跑多复杂的任务–数学能力。线性代数、概率论数学课。 - 为什么16位浮点数影响严重?32位和64位就好了嘛?那就是说所有通过fp16加速或者减小模型的方法都存在容易梯度爆炸或者消失的防线?
32位-64位会更好一些,Python默认64位。常用32位。vfloat16 主要是训练时梯度会遇到问题。 - 梯度消失可以说是因为使用了sigmoid激活函数引起的吗?可以用ReLU替换sigmoid解决梯度消失的问题?
sigmoid容易引起梯度消失,但是梯度消失可能有别的原因引起,relu会比较好解决梯度消失,但是不一定能解决。 - 梯度爆炸是由什么激活函数引起的?
梯度爆炸不是由激活函数引起的,激活函数的梯度不是很大。是因为每一层输出的值很大,每一层叠加到很大引起的。 - LSTM这里乘法变加法,乘法说的是梯度更新的时候用的梯度的乘法吗?
lstm通过指数和log将其变成加法。 - 为什么乘法变加法可以让训练更稳定?乘法本质上不就是多个加法吗?如果加法能够起作用,我们需要怎么做?训练用的网络用resNet。
1. 5 100 = 4 ∗ 1 0 17 1.5^{100}=4*10^{17} 1.5100=4∗1017, 乘法让数值变很大。 - 让每层方差是一个常数的方法,指的是batch normalization吗? 为什么bn层要有伽马和贝塔,可以去掉吗?
没关系。batch normalization会让方差趋向一个固定值,后续会讲到。 - 输出或者参数符合正太分布有益于学习,是有理论依据还是经验所得?
有理论依据, 正太分布容易算均值和方差,其他分布也可以,只是需要输出值到一个合理的范围内。 - 随机初始化,有没有一种最好的最推荐的概率分布来找到初始随机值呢?
xavier是常用方案。 - 梯度归一化就是batch normalization吗?
不是。 - 山地图是可视化出来的吗?可以把损失函数、降维度可视化成类似的图指导训练吗?有没有什么好的方法?
对损失函数做可视化。二维比较好画,三维不好画。比较延时。 - 为什么在做这些假设时都需要加入前提独立同分布?非独立同分布的计算会更复杂吗?
为了简单起见。 - 为什么需要假设独立同分布,有什么作用?如果是不独立同分布呢?内部协变量偏移(ics)和独立同分布如何互相影响?
不是独立同分布,没有太大影响。batch normalization做解耦。 - 为什么可以假设每层的权重都遵从同一个分布呢?
假设的是权重初始化时遵从分布的,不是假设的中间处理的结果。 - 正态分布假设有什么缺陷呢?为什么看起来是万能的?
做推导容易。大数定理表示一切的一切都是正太的。 - 有学者用群智能算法来初始化权值阈值,例如粒子群算法等,这种方法怎么样呢?
- 强制使得每一层的输出特征均值为0,方差为1,是不是损失了网络的表达能力,改变了数据的特征?会降低学到的模型的准确率吗?
数值是在一个合适的区间表达,拉到什么区间都可以,0 1是为了数学上,硬件上计算方便。 - 为什么4sigmoid(x)-2可以提高稳定性?4sigmoid-2和ReLU实质是一样的吗?
4*sigmoid-2 在零点附近,曲线近似于y=x这个函数。 - 能否用具体的例子讲解下xavier初始化,例如,针对一个2层线性回归模型,输入层、隐藏层、输出层维度分别是10,16,1,正太分布初始化w的参数怎么结算呢?
后续讲怎么实现。看框架的时间。 - 激活函数的选择有什么建议吗?比如图像分类,或者语音识别?
relu,简单。 - 一般权重都是在每个epoch结束以后更新的吗?
每次迭代一个batch–iterate就会计算更新权重的,在每个epoch-扫完一遍数据之后,权重是更新了很多次的。 - 用的网络是ResNet,还是会出现数值稳定性的问题,咋办?
所有技术是为了缓解出现数值稳定性的问题,并不是解决。整个深度学习的进展,都是为了让数值更加稳定。 - 数值稳定性可能是模型结构引起的,孪生网络两路输入不一样,是不是很可能引起数值不稳定?实际中,降低batchsize或者调小学习率,可以缓解数值稳定性吗?
孪生网络两路输入不一样,会引起数值不稳定。文本进一个网络,图片进入另一个网络,数值区间不一样,会引起数值问题。可以通过权重使两个数值在差不多的范围里面。 - 算法移植这种工程化,怎么在模型设计和模型的精度提升方面有突破呢?
模型背后的设计思路。 - 通过把每一层输出的均值和方差做限制,是否可以理解为限制各层输出值出现极大或者极小的异常值?
也可以这样认为。方差有限制,输出值会在一定范围内,出现极大值的概率就会降低,但仍会有。

















 1169
1169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









