







1. pandas 介绍
pandas 是 Python 的数据分析核心库。它提供了一系列能够快速、便捷地处理结构化数据的数据结构和函数。pandas 兼具 Numpy 高性能的数组计算功能以及电子表格和关系数据库灵活的数据处理能力。它提供了复杂精细的索引功能,以便便捷地完成重塑、切片和切块、聚合以及选取数据子集等操作。
统计分析是数据分析的重要组成部分,它几乎贯穿了整个数据分析的流程。运用统计方法,将定量与定性结合,进行的研究活动叫作统计分析。统计分析除了包含单一数值型特征的数据集中趋势、离散趋势和峰度与偏度等统计知识外,还包含了多个特征比较计算等知识。
2. 读写不同数据源数据
数据读取是进行数据预处理、建模与分析的前提。不同的数据源,需要使用不同的函数读取。pandas 内置了 10 余种数据源读取函数和对应的数据写入函数。常见的数据源有三种,分别是数据库数据、文本文件(包括一般文本文件和 CSV 文件)和 Excel 文件。掌握这三种数据源读取方法,便能够完成 80% 左右的数据读取工作。
2.1 读写数据库数据
除了 pandas 库外,还需要使用 SQLAlchemy 库建立对应的数据库连接。SQLAlchemy 配合相应数据库的 Python 连接工具(例如,MySQL 数据库需要安装 mysqlclient 或者 pymsql 库,Oracle 数据库需要安装 cx_oracle 库),使用 create_engine 函数,建立一个数据库连接。在 create_engine 中输入的是一个连接字符串。
# SQLAlchemy连接MySQL数据库代码
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/testdb?charset=utf8')
print(engine)
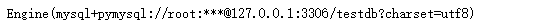
在使用 Python 的 SQLAlchemy 时,MySQL 和 Oracle 数据库连接字符串的格式如下:
数据库产品名+连接工具名://用户名:密码@IP地址:数据库端口号/数据库名称?charset=数据库数据编码
2.1.1 读取
| 函数 | 说明 |
|---|---|
| read_sql | 既能读取数据库中的某一个表,也能实现查询操作 |
| read_sql_table | 只能读取数据库的某一个表,不能实现查询操作 |
| read_sql_query | 只能实现查询操作,不能读取数据库中的某一个表 |
pandas.read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None,
columns=None, chunksize=None)
pandas.read_sql_table(table_name, con, schema=None, index_col=None, coerce_float=True, parse_dates=None,
columns=None, chunksize=None)
pandas.read_sql_query(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None,
chunksize=None)
# 使用read_sql_table、read_sql_qurey、read_sql函数读取数据库数据
import pandas as pd
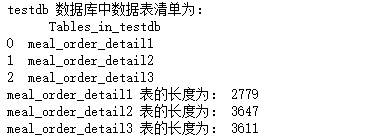
formlist = pd.read_sql_query('show tables',con=engine)
print('testdb 数据库中数据表清单为:\n',formlist)
detail1 = pd.read_sql_table('meal_order_detail1',con=engine)
print('meal_order_detail1 表的长度为:',len(detail1))
detail2 = pd.read_sql('select * from meal_order_detail2',con=engine)
print("meal_order_detail2 表的长度为:",len(detail2))
detail3 = pd.read_sql('meal_order_detail3',con=engine)
print('meal_order_detail3 表的长度为:',len(detail3))
2.1.2 存储
DataFrame.to_sql(self, name, con, schema=None, if_exists='fail', index=True, index_label=None,
chunksize=None, dtype=None, method=None)
| 参数 | 说明 |
|---|---|
| name | 接收 string,代表数据库表名。 |
| if_exists | 接收 fail、replace 和 append。默认 fail。fail 表示如果表名存在,则不执行写入操作;replace 表示如果存在,则将原数据表删除,再重新创建;append 则表示在原数据库表基础上追加数据。 |
| index | 接收 boolean,默认为 True。表示是否将行索引作为数据写入数据库。 |
# 使用to_sql方法写入数据
detail1.to_sql('test1',con=engine,index=False,if_exists='replace')
formlist1 = pd.read_sql('show tables',con=engine)
print('新增一个表格后,testdb 数据库数据表清单为:\n',formlist1)

2.2 读写文本文件
文本文件是一种由若干行字符构成的计算机文件,它是一种典型的顺序文件。CSV 是一种用分隔符分隔的文件格式,因为其分隔符不一定是逗号,因此又被称为字符分隔文件。文件以纯文本的形式存储表格数据(数字和文本)。它是一种通用、相对简单的文件格式。
2.2.1 读取
pandas 提供了 read_table 函数读取文本文件,提供了 read_csv 函数来读取 CSV 文件。因为 CSV 文件也是一种文本文件,所以两个函数都可以读取 CSV 文件。
pandas.read_csv(filepath_or_buffer, sep=',', delimiter=None, header='infer', names=None, index_col=None,
usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None,
converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None,
skipfooter=0,nrows=None, na_values=None,keep_default_na=True, na_filter=True, verbose=False,
skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False,
date_parser=None, dayfirst=False, cache_dates=True, iterator=False, chunksize=None,
compression='infer', thousands=None, decimal: str = '.', lineterminator=None, quotechar='"',
quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, dialect=None,
error_bad_lines=True, warn_bad_lines=True, delim_whitespace=False, low_memory=True,
memory_map=False, float_precision=None)
pandas.read_table(filepath_or_buffer, sep='\t', delimiter=None, header='infer', names=None,
index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True,
dtype=None, engine=None, converters=None, true_values=None, false_values=None,
skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None,
keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True,
parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None,
dayfirst=False, cache_dates=True, iterator=False, chunksize=None, compression='infer',
thousands=None, decimal: str = '.', lineterminator=None, quotechar='"', quoting=0,
doublequote=True, escapechar=None, comment=None, encoding=None, dialect=None,
error_bad_lines=True, warn_bad_lines=True, delim_whitespace=False, low_memory=True,
memory_map=False, float_precision=None)
| 参数名称 | 说明 |
|---|---|
| filepath_or_buffer | 接收 string。代表文件路径。 |
| sep | 接收 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









