







目录
1.3 -tail、-head : 显示一个文件的末尾、头部 1kb 的数据
3.1 -chgrp、-chmod、-chown : 修改文件所属权限
5.1 -moveFromLocal: 从本地上传到 HDFS(会删除本地源文件)
5.2 -put & copyFromLocal: 将本地文件上传 到 HDFS
5.3 -appendToFile:追加一个文件到已经存在的文件末尾
0. 前言
0.1 查看 hadoop fs 有哪些命令
#查看 hadoop fs 命令文档
hadoop fs
0.2 查看指定命令 的使用说明
#查看指定命令的使用说明
hadoop fs -help [CMD]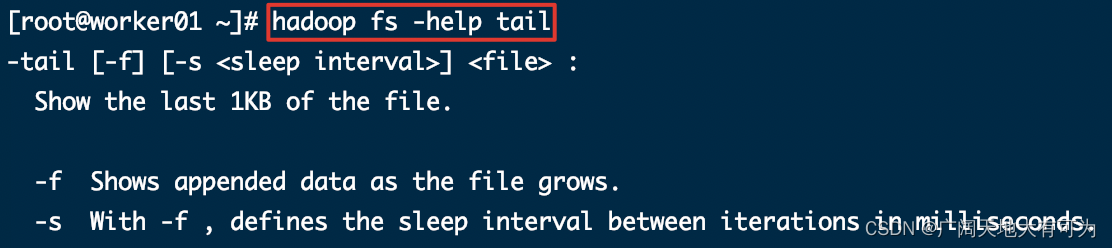
1. 查看
1.1 -ls : 显示目录信息
#显示目录信息
hadoop fs -ls /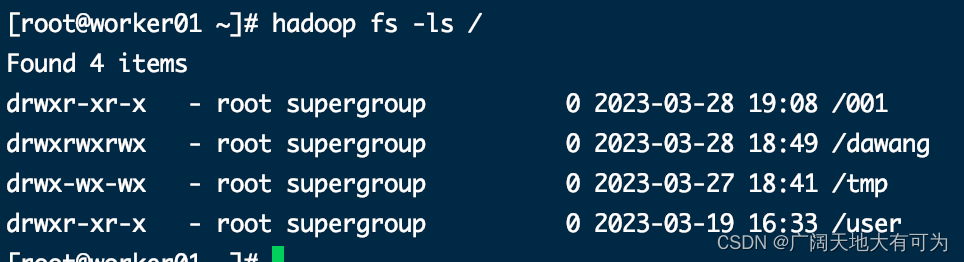
1.2 -cat : 显示文件内容
#显示文件内容
hadoop fs -cat /tmp/1.txt
1.3 -tail、-head : 显示一个文件的末尾、头部 1kb 的数据
#显示一个文件的末尾 1kb 的数据
hadoop fs -tail /tmp/1.txt
#显示一个文件的头部 1kb 的数据
hadoop fs -head /tmp/1.txt1.4 -du : 统计文件夹的大小信息
语法:
-du [-s] [-h] [-v] [-x] path1 path2...
参数:
-s : 对指定的目录求和,否则会遍历指定的目录
-h : 格式化文件大小(默认为字节数),自动单位换算
-v : 显示表头信息(默认不显示)
-x : 不统计快照
结果:
SIZE DISK_SPACE_CONSUMED_WITH_ALL_REPLICAS FULL_PATH_NAME
39 117 /tmp/1.txt
39 117 /tmp/2.txt
SIZE : 文件大小
DISK_SPACE_CONSUMED_WITH_ALL_REPLICAS : 文件所有副本的大小
FULL_PATH_NAME : 完整路径
tips:
DISK_SPACE_CONSUMED_WITH_ALL_REPLICAS 是NameNode的元数据中副本个数*文件大小,副本个数要以实际DataNode个数为准
示例:
#查看 /tmp、/user目录下文件的大小
hadoop fs -du -h /tmp /user
#查看 /tmp、/user目录的大小
hadoop fs -du -s -h /tmp /user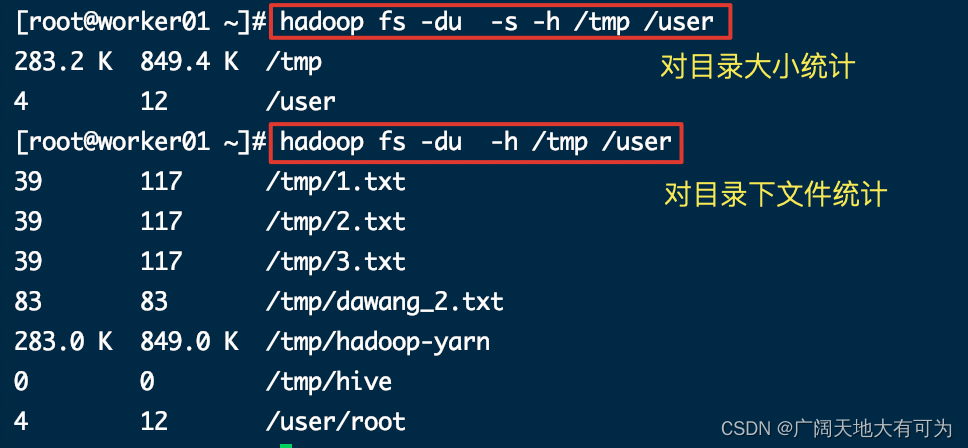
2. 判断
2.1 -test: 对文件的判断
语法:
-test -[defswrz] <path> :
Answer various questions about <path>, with result via exit status.
-d return 0 if <path> is a directory.
-e return 0 if <path> exists.
-f return 0 if <path> is a file.
-s return 0 if file <path> is greater than zero bytes in size.
-w return 0 if file <path> exists and write permission is granted.
-r return 0 if file <path> exists and read permission is granted.
-z return 0 if file <path> is zero bytes in size, else return 1.示例:
#1.判断指定的path是不是目录(是目录返回0,不是目录返回1)
hadoop fs -test -d /tmp/1.txt
echo $?
#2.判断文件或目录是否存在(存在返回0,不存在返回1)
hadoop fs -test -e /tmp/1.txt
echo $?
#3.判断指定的path是不是文件(是文件返回0,不是文件返回1)
hadoop fs -test -f /tmp/1.txt
echo $?
#4.判断指定的path是不是文件且大于0字节(是返回0,不是返回1)
hadoop fs -test -s /tmp/1.txt
echo $?
#5.判断指定的path是不是文件且拥有write权限(是返回0,不是返回1)
hadoop fs -test -w /tmp/1.txt
echo $?
#6.判断指定的path是不是文件且等于0字节(是返回0,不是返回1)
hadoop fs -test -z /tmp/1.txt
echo $?3. 修改
3.1 -chgrp、-chmod、-chown : 修改文件所属权限
语法:
#修改 分组
-chgrp [-R] GROUP PATH...
#修改 权限
-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...
MODE: 用 rwx 字母表示权限 (r=读、w=写、x=执行)
OCTALMODE: 用 421 表示权限 (4=读、2=写、1=执行)
#修改 所有者
-chown [-R] [OWNER][:[GROUP]] PATH... 示例:
#修改权限
hadoop fs -chmod 777 /dawang/1.txt
#修改owner
hadoop fs -chown worker01:worker01 /dawang/1.txt3.2 -setrep:修改 文件副本个数
语法:
-setrep [-R] [-w] <rep> <path> ...
tips: 这里的副本数是 只是NameNode的元数据中记录的副本个数
集群中是否真的会有这么多副本,还需要看 DataNode 的数量
如果目前只有 3个 DataNode节点,最多也就 3 个副本,只有节点数的增加到 10 台时,副本数才能达到 10
示例:
#修改 文件副本个数
hadoop fs -setrep 100 /dawang/1.txt3.3 -mv:更名&移动文件
语法:
-mv <src> ... <dst>
tips: 移动的文件或目录必须存在
示例:
#更名&移动文件
hadoop fs -mv /tmp/1.txt /1.txt4. 创建与删除
4.1 -mkdir: 创建目录
-mkdir [-p] <path> ...
-p 参数的作用:
1. 如果目录已经存在,不会失败
2. 可以创建多级目录
#创建1级目录
hadoop fs -mkdir /2023
#创建多级目录
hadoop fs -mkdir /2023/03
4.2 -rm:删除文件或文件夹
-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...
-f : 如果文件不存在,则不会报错
-[rR] : 递归删除目录(不指定时,只能删除文件)
-safely : 是否开启安全模式,删除大文件时需要确认(大文件通过 hadoop.shell.delete.limit.num.files 设置)
tips: 生产环境中慎用-rm -r - f 😱😱😱
示例:
#删除指定文件
hadoop fs -rm -f /tmp/1.txt
#删除指定文件夹
hadoop fs -rm -f -r /tmp/0014.3 -cp: 拷贝文件
语法:
-cp [-f] [-p | -p[topax]] [-d] [-t <thread count>] [-q <thread pool queue size>] <src> ... <dst> :
-f : 如果目标文件已经存在,则覆盖目标
-d : 跳过创建临时文件
-t <thread count> : 使用线程数(默认为1)
-q <thread pool queue size> : 要使用的线程池队列大小,默认为1024
示例:
#拷贝文件(不覆盖目标文件)
hadoop fs -cp /dawang/1.txt /dawang/3.txt
#拷贝文件(覆盖目标文件)
hadoop fs -cp -f /dawang/1.txt /dawang/3.txt5. 上传
5.1 -moveFromLocal: 从本地上传到 HDFS(会删除本地源文件)
语法:
-moveFromLocal <localsrc> ... <dst>
tips:目录和文件 都可以上传
示例:
# 将本地文件 移动到 hdfs
hadoop fs -moveFromLocal 1.txt /tmp5.2 -put & copyFromLocal: 将本地文件上传 到 HDFS
语法:
-put [-f] [-p] [-l] [-d] [-t <thread count>] [-q <thread pool queue size>] <localsrc> ... <dst>
-p : 保留源文件的时间戳、权限信息
-f : 如果目标已经存在,则覆盖目标
-t : 指定使用线程数(默认为1)
-q : 指定线程池大小(默认为1024)
示例:
# 上传文件(不覆盖目标文件)
hadoop fs -put 1.txt /tmp
# 上传文件(覆盖目标文件)
hadoop fs -put -f 1.txt /tmp5.3 -appendToFile:追加一个文件到已经存在的文件末尾
语法:
-appendToFile <localsrc> ... <dst>
示例:
# 追加文件
hadoop fs -appendToFile 1.txt /tmp/1.txt6. 下载
6.1 -get、-copyToLocal : 下载文件
语法:
-get [-f] [-p] [-crc] [-ignoreCrc] [-t <thread count>] [-q <thread pool queue size>] <src> ... <localdst> :
-p : 保留源文件的时间戳、权限信息
-f : 如果目标已经存在,则覆盖目标
-t : 指定使用线程数(默认为1)
-q : 指定线程池大小(默认为1024)
-ignoreCrc : 跳过下载文件的CRC校验
示例:
# 下载文件到本地
hadoop fs -get/tmp gao















 694
694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









