







Redis基础篇–zset(有序列表)
zset
内部实现: 类似于Java语言里SortedSet和HashMap的结合体。它的内部实现用的是一种叫做"跳跃列表"的数据结构。
用途举例
zset可以用来存储粉丝列表,value值是粉丝的用户ID,score是关注时间,便可以对粉丝列表按关注时间进行排序。
zset可以用来存储学生的成绩,value值是学生的ID,score是他的考试成绩,我们对成绩按分数进行排序就可以得到他的名次。
常见命令:
zadd books 9.0 python #添加一个元素,score为9.0
zrange books 0 -1 #按score排序列出,参数区间为排名范围
zrevrange 0 -1 #按score逆序列出,参数区间为排名范围
zcard books #相当于count()
zscore books python #获取指定value的score,内部score使用double类型进行存储,所以存在小数点精度问题
zrank books python #排名
zrangebyscore books 0 8.91 #根据分值区间遍历zset
zrangebyscore books -inf 8.91 withscores #根据分值区间(-∞,8.91]遍历zset,同时返回分值。inf代表infinite,无穷大的意思
zrem books python #删除value
跳跃列表
使用跳跃列表的前提:zset需要支持随机的插入和删除,所以不宜使用数组来表示。用链表表示,但是同时又需要按照score进行排序,需要找插入点,通常会使用二分查找,但是二分查找的对象必须是数组。所以单独的链表或数组都不足以支撑zset的需求。
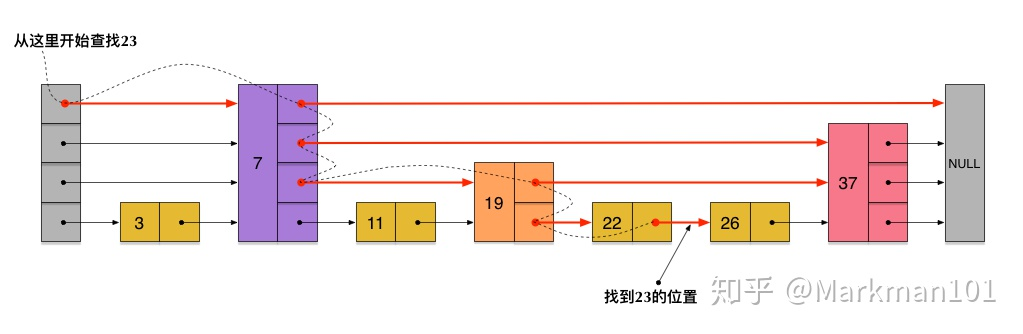
跳跃列表类似于层级制,最下面一层的所有元素都会串起来。然后每隔几个元素挑选出一个代表,再将这几个代表使用另外一层指针串起来。然后在这些代表里再挑出二级代表,再串起来。最终就形成了金字塔结构。

内部结构
struct zslnode {
string value;
double score;
zslnode*[] forwards; /* 多层连接指针 */
zslnode * backward; /* 回溯指针 */
}
struct zsl {
zslnode * header; /* 跳跃列表头指针 */
int maxLevel; /* 跳跃列表当前的最高层 */
map<string, zslnode*> ht; /* hash结构的所有键值对 */
}
查找过程
从header的最高层开始遍历找到第一个节点(最后一个比"我"小的元素),然后逐层降到最底层进行遍历就找到了期望的节点。
参考:Redis内部数据结构之跳表
随机层数
对于每一个新插入的节点,都需要调用一个随机算法给它分配一个合理的层数。直观上期望的目标是50%的概率被分配到Level1,25%的概率被分配到Level2,12.5%的概率被Level3,以此类推,2的-63次方的概率被分配到最顶层。
元素排名
redis在skiplist的forward指针上进行了优化,给每一个forward指针都增加了span属性,span是跨度的意思,表示从当前层的节点沿着forward指针跳到下一个节点中间会跳过多少个节点。redis在插入、删除操作时会小心翼翼地更新span值的大小
struct zslforward {
zslnode * item;
long sapn; /* 跨度 */
}
这样当我们要计算一个元素的排名时,只需要将"搜索路径"经过的所有节点的跨度span值进行叠加就可以算出元素的最终rank值















 8842
8842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









