







为了了解清楚物流的中转次数,为试验提供数据基础,这个周末对物流进行了一些研究。简记如下:
一、收集快递单号
从公司数据银行申请了数据,申请的数据没有涉密字段,流程很快就通过了。
然后用“取数易”导出表单,并选取了代表性快递公司,诸如EMS,圆通,申通,韵达,中通,顺丰等。
这个数据量非常大,需要筛选下范围。
需要注意的是,快递查询有失效性,不同的快递公司允许查询的最久远时间不同,因此选取快递单号的时候需要注意,不要选太久以前的。
二、采用Selenium获得物流信息
关于Selenium的详细介绍,我在以前的文章《利用Python Selenium自动化获取页面信息》讲的很清楚,这篇文章就不重复介绍了,可以翻以前文章学习。
记录下发现的几个注意点:
1.从百度上查询快递,有限制查询次数,试验发现一次最多查询50个,再多一些,就会显示查询频次过高。
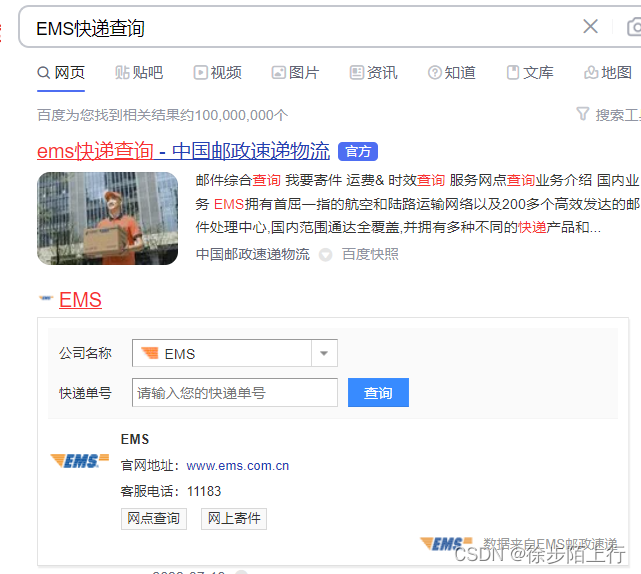
是在这个页面查询
2.除了查询个数限制,网页也有时长限制,在一个页面过久会提示页面已过期,无法再次查询。但是如果你很频繁的刷新,也很可能会触发到百度的验证机制,需要双重旋转图片验证码验证。类似下面这种验证码。

3.直接用.text方法来获取文本,会获取不全,这里使用了.get_attribute('innerText')的方法来获取。
参考代码如下:
# -*- coding: gbk -*-
# 王永平 2022.7.17
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import os
#快递单号数组列表
tracking_number = [
'3121028xxxxxxxx',
'3121043xxxxxxxx',
'3121061xxxxxxxx',
#作为示例代码,这里省去了很多,未公开快递单号......
'3121077xxxxxxxx',
'3121077xxxxxxxx'
]
s_start_i = input("输入起始位置:")
start_i = int(s_start_i)
#这里要注意用对chromedriver的版本
browser = webdriver.Chrome(r'C:\Program Files\Google\Chrome\Application\chromedriver.exe')
#需要访问的网站,韵达
my_url = "https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=%E9%9F%B5%E8%BE%BE%E5%BF%AB%E9%80%92&oq=%25E5%25BF%25AB%25E9%2580%2592%25E5%258D%2595%25E5%258F%25B7%25E8%258B%25B1%25E6%2596%2587&rsv_pq=a17e66630004e933&rsv_t=cdd4YUULNI2Q7gdijAIaLAe8Moy%2BxPX6h7JMbjmTr%2FtMYvCd4lIc5lSRQqo&rqlang=cn&rsv_enter=0&rsv_dl=tb&rsv_btype=t&inputT=7679&rsv_sug2=0&rsv_sug4=7679"
browser.get(my_url)
#两个文件,一个用来记录详细的快递运输状态,另外一个只是用作记录中转次数,主要是方便后续的数据处理
f = open("E://1.txt",'a+')
f2 = open("E://2.txt",'a+')
#屏蔽日志错误
options = webdriver.ChromeOptions()
options.add_argument('log-level=3')
num = 0
#设置一次只分析100单,其中50单的时候,需要等待6分钟,这主要是因为网站限制查询频次,如果太短了,还要进行2重验证码验证、链接失效等问题
#可以另外建立一个程序,定时再执行本程序
for i in range(100):
#每50单会被限制查询
if num > 49:
f.write("-----------------分界----------------\n")
f2.write("-----------------分界----------------\n")
f.close
f2.close
num = 0
#等待时的时间点
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
time.sleep(6*60)
f = open("E://1.txt",'a+')
f2 = open("E://2.txt",'a+')
zzcs = 1 #中转次数,默认为1
log2 = "" #物流详细信息
num = num + 1
try:
#清空输入框
browser.find_element(By.XPATH,"/html/body/div[2]/div[4]/div[1]/div[3]/div[2]/div[1]/div[1]/div/div[2]/div[2]/input").clear()
#输入快递单号
browser.find_element(By.XPATH,"/html/body/div[2]/div[4]/div[1]/div[3]/div[2]/div[1]/div[1]/div/div[2]/div[2]/input").send_keys(tracking_number[start_i+i])
time.sleep(0.5)
browser.find_element(By.XPATH,"/html/body/div[2]/div[4]/div[1]/div[3]/div[2]/div[1]/div[1]/div/div[2]/div[2]/a").click()
#给点时间,避免服务器还未来得及反应过来
time.sleep(1.5)
#判断个数
ul = browser.find_element_by_xpath("/html/body/div[2]/div[4]/div[1]/div[3]/div[2]/div[1]/div[4]/div/div[1]/div/ul")
list = ul.find_elements_by_xpath('li')
k = len(list) # 计算有多少个li
print("第"+str(start_i+i)+"单")
print("快递单号:"+tracking_number[start_i+i]+",")
f.write("['快递单号:"+tracking_number[start_i+i]+",")
#输出结果
for j in range(k-1):
lng = browser.find_element(By.XPATH,"/html/body/div[2]/div[4]/div[1]/div[3]/div[2]/div[1]/div[4]/div/div[1]/div/ul/li["+str(j+1)+"]/div/div[2]").get_attribute('innerText')
print(lng)
if "到达" in lng:
zzcs = zzcs + 1
else:
zzcs = zzcs
log2 = log2+lng+","
except:
log2 = "出错"
f2.write(str(start_i+i)+",快递单号,"+tracking_number[start_i+i]+",中转次数,"+str(zzcs)+",\n")
f.write("第"+str(start_i+i)+"单,"+log2+"']\n-------------------------|-----------------------\n")
print("--------分界线---------")
print("--------完成100单分析---------")
f.close
f2.close防止网页限制,可以把上述主体部分封装为一个函数,然后每隔一段时间调用即可。
获取结果截图1:
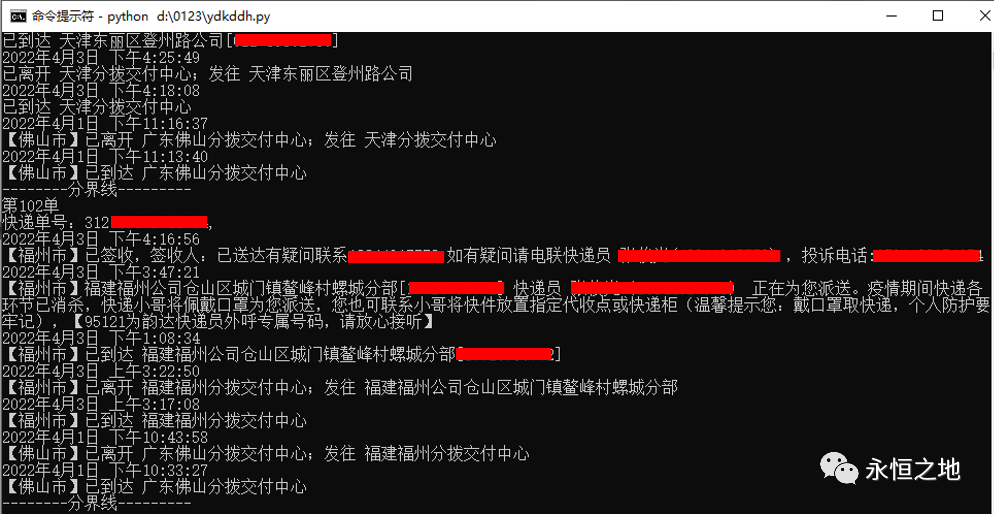
获取结果截图2:

以上只是对中转次数的分析。获取物流信息后,其实还可以做时效性分析,运输距离分析等等一系列内容。















 1800
1800











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









