







学习linux就一个感受:
真是盖了帽了,我的linux。
Linux架构
https://www.cnblogs.com/vamei/archive/2012/10/10/2718229.html
冯诺依曼体系结构:
cpu在ip中取cs然后运行
Linux优化总结版
一般定位问题的方法
1、我首先会去看看系统的平均负载,使用top或者htop命令查看,平均负载体现的是系统的一个整体情况,他应该是cpu、内存、磁盘性能的一个综合,一般是平均负载的值大于机器cpu的核数,这时候说明机器资源已经紧张了
2、平均负载高了以后,接下来就要看看具体是什么资源导致,我首先会在top中看cpu每个核的使用情况,如果占比很高,那瓶颈应该是cpu,接下来就要看看是什么进程导致的
3、如果cpu没有问题,那接下来我会去看内存,首先是用free去查看内存的是用情况,但不直接看他剩余了多少,还要结合看看cache和buffer,然后再看看具体是什么进程占用了过高的内存,我也是是用top去排序
4、内存没有问题的话就要去看磁盘了,磁盘我用iostat去查看,我遇到的磁盘问题比较少
5、还有就是带宽问题,一般会用iftop去查看流量情况,看看流量是否超过的机器给定的带宽
6、涉及到具体应用的话,就要根据具体应用的设定参数来查看,比如连接数是否查过设定值等
7、如果系统层各个指标查下来都没有发现异常,那么就要考虑外部系统了,比如数据库、缓存、存储等
如何迅速分析内存的性能瓶颈
-
先用 free 和 top,查看系统整体的内存使用情况。
-
再用 vmstat 和 pidstat,sar,查看一段时间的趋势,从而判断出内存问题的类型。
-
最后进行详细分析,比如内存分配分析,swap、缓存 / 缓冲区分析、具体进程的内存使用分析等。
如何迅速磁盘io的性能瓶颈
-
文件系统:使用查看文件系统容量的工具 df。它既可以查看文件系统数据的空间容量,也可以查看索引节点的容量。至于文件系统缓存,我们通过 /proc/meminfo、/proc/slabinfo 以及 slabtop 等各种来源,观察页缓存、目录项缓存、索引节点缓存以及具体文件系统的缓存情况。
-
磁盘 I/O: 用 iostat 和 pidstat 观察了磁盘和进程的 I/O 情况。它们都是最常用的 I/O 性能分析工具。通过 iostat ,我们可以得到磁盘的 I/O 使用率、吞吐量、响应时间以及 IOPS 等性能指标;而通过 pidstat ,则可以观察到进程的 I/O 吞吐量以及块设备 I/O 的延迟等。
-
一般的查看:先是top看%iowait到升高,iostat -d 查看磁盘的具体使用情况。 再看pidstat是哪个进程在操作磁盘,再strace看进程的调用栈(系统调用)。用lsof 来定位应用程序。
如何迅速cpu的性能瓶颈
-
top查看占用率
-
uptime查看平均负载,平均负载指的是:平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数。不要过高,否则就可能导致进程响应变慢
-
查看上下文切换是否过多:使用vmstat 查看上下文切换
-
僵尸进程查找
- 使用top找到疑似僵尸进程
- 使用pstree -aps 3084查看父进程
- 接着查看 app 应用程序的代码,看看子进程结束的处理是否正确,比如有没有调用 wait() 或 waitpid() ,抑或是,有没有注册 SIGCHLD 信号的处理函数。
-
无法通过top查看到的cpu大量占用的情况:
- 可能是:应用本身在不停地崩溃重启,而启动过程的资源初始化,很可能会占用相当多的 CPU。对于这类进程,我们可以用 pstree 或者 execsnoop 找到它们的父进程,再从父进程所在的应用入手,排查问题的根源。
网路性能可以使用的工具
Linux 网络基于 TCP/IP 协议栈构建,而在协议栈的不同层,我们所关注的网络性能也不尽相同。
在应用层,我们关注的是应用程序的并发连接数、每秒请求数、处理延迟、错误数等,可以使用 wrk、JMeter 等工具,模拟用户的负载,得到想要的测试结果。
而在传输层,我们关注的是 TCP、UDP 等传输层协议的工作状况,比如 TCP 连接数、 TCP 重传、TCP 错误数等。此时,你可以使用 iperf、netperf 等,来测试 TCP 或 UDP 的性能。
再向下到网络层,我们关注的则是网络包的处理能力,即 PPS。Linux 内核自带的 pktgen,就可以帮你测试这个指标。
什么是系统调用
为了方便调用内核,Linux将内核的功能接口制作成系统调用(system call)。系统调用看起来就像C语言的函数。你可以在程序中直接调用。Linux系统有两百多个这样的系统调用。用户不需要了解内核的复杂结构,就可以使用内核。系统调用是操作系统的最小功能单位。一个操作系统,以及基于操作系统的应用,都不可能实现超越系统调用的功能。一个系统调用函数就像是汉字的一个笔画。任何一个汉字都要由基本的笔画(点、横、撇等等)构成。我不能臆造笔画。
在命令行中输入$man 2 syscalls可以查看所有的系统调用。你也可以通过$man 2 read来查看系统调用read()的说明。在这两个命令中的2都表示我们要在2类(系统调用类)中查询 (具体各个类是什么可以通过$man man看到)。
什么是系统函数
系统调用提供的功能非常基础,所以使用起来很麻烦。一个简单的给变量分配内存空间的操作,就需要动用多个系统调用。Linux定义一些库函数(library routine)来将系统调用组合成某些常用的功能。上面的分配内存的操作,可以定义成一个库函数(像malloc()这样的函数)。再比如说,在读取文件的时候,系统调用要求我们设置好所需要的缓冲。我可以使用Standard IO库中的读取函数。这个读取函数既负责设置缓冲,又负责使用读取的系统调用函数。使用库函数对于机器来说并没有效率上的优势,但可以把程序员从细节中解救出来。库函数就像是汉字的偏旁部首,它由笔画组成,但使用偏旁部首更容易组成字,比如"铁"。当然,你也完全可以不使用库函数,而直接调用系统函数,就像“人”字一样,不用偏旁部首。
(实际上,一个操作系统要称得上是UNIX系统,必须要拥有一些库函数,比如ISO C标准库,POSIX标准等。)
stdin,stdout 和STDOUT_FILENO,STDIN_FILENO
标准输入描述字用stdin,标准输出用stdout,标准出错用stderr表示。
stdin等是FILE *类型,属于标准I/O,在<stdio.h>。
STDIN_FILENO等是文件描述符,是非负整数,一般定义为0, 1, 2,属于没有buffer的I/O,直接调用系统调用,在<unistd.h>。
管道和重定向
原理都是在shell调用了exec()或这个函数的变种。调用exec前后做环境准备和环境清理的工作。比如重定向就是关闭了stdout,打开一个文件描述符,执行指定函数的时候就会找到这个文件然后输出结果。
shell是什么
shell是一个特殊的应用。很多用户将它称为命令行。shell是一个命令解释器(interpreter),当我们输入“ls -l”的时候,它将此字符串解释为
- 在默认路径找到该文件(/bin/ls),
- 执行该文件,并附带参数"-l"。
UNIX的一条哲学是让每个程序尽量独立的做好一个小的功能。而shell充当了这些小功能之间的"胶水",让不同程序能够以一个清晰的接口(文本流)协同工作,从而增强各个程序的功能。这也是Linux老鸟鼓励新手多用shell,少用图形化界面的原因之一。
中断
Linux 将中断处理过程分成了两个阶段,也就是上半部和下半部:上半部用来快速处理中断,它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作。下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行。
软中断与硬中断
kernal
调度
知道每个任务的调度时间:
- 先到先执行:周转和响应时间(响应的时间-提交时间)都长。
- 短作业优先(SJF) :周转时间一般较短(运行完时间-提交时间),当长作业先到,还会出现fifo一样的短作业等待长作业资源于是拉长周转时间的现象。
- 最短完成时间优先响应(STCF):抢占式短作业优先,即在SJF中添加抢占策略。响应时间和周转时间都很短
以上的响应时间都长。
- rr,即时间片轮询 : 响应时间短,周转时间很长。
不知道每个任务的调度时间:
-
多级反馈队列
-
提交后都是高优先级:当时间片到期,说明是个cpu密集型,降低优先级;当有io而退出执行,说明是个io密集型,优先级不变。(io密集认为是和外界交互高,所以要优先调度才有好的体验,所以优先级自然被内核认为很高)
-
彩票调度。只需要一个不错的随机数生成器来选择中奖彩票和一个记录系统中所有进程的数据结构(一个列表),以及所有彩票的总数。
首先,计A的票后,counter增加到100。因为100小于300,继续遍历。然后counter会增加到150(B的彩票),仍然小于300,继续遍历。最后,counter增加到400(显然大于300),因此退出遍历,current指向C(中奖者)。
- 随机发彩票
- 最小步长调度
多处理器调度:
为了理解多处理器调度带来的新问题,必须先知道它与单CPU之间的基本区别。区别的核心在于对硬件缓存(cache)的使用,以及多处理器之间共享数据的方式。
- 单队列多处理器调度(Single Queue MultiprocessorScheduling,SQMS)
- 缺点:需要加锁;缺乏缓存亲和性(指一个任务在同一个cpu上运行更快,换cpu就慢了)解决:引入亲和度机制
- 多队列多处理器调度(Multi-Queue MultiprocessorScheduling,MQMS)
- 在MQMS中,基本调度框架包含多个调度队列,每个队列可以使用不同的调度规则,比如轮转或其他任何可能的算法。当一个工作进入系统后,系统会依照一些启发性规则(如随机或选择较空的队列)将其放入某个调度队列。这样一来,每个CPU调度之间相互独立,就避免了单队列的方式中由于数据共享及同步带来的问题。
在构建多处理器调度程序方面,Linux社区一直没有达成共识。一直以来,存在3种不同的调度程序:O(1)调度程序、完全公平调度程序(CFS)以及BF(译为脑残)调度程序(BFS)
操作系统如何重获cpu
在这个虚拟的世界中,一个友好的进程如何放弃CPU:
- 主动调用yield():包括io操作等
- 异常,陷入内核陷阱表,比如0为除数
- 时钟中断。
内核陷阱表:内核函数与对应的地址.当程序陷入时,只需要查陷阱表,找到调用的的地址.程序就不会乱跳转.
调度时寄存器的切换
有两种类型的寄存器保存/恢复。
第一种是发生时钟中断的时候。在这种情况下,运行进程的用户寄存器由硬件隐式保存,使用该进程的内核栈。
第二种是当操作系统决定从A切换到B。在这种情况下,内核寄存器被软件(即OS)明确地保存,但这次被存储在该进程的进程结构的内存中。
内核栈(下文有详解)
内核栈是什么?在task_struct里的一个数据结构 在上下文切换的时候,操作系统的调度器进行切换时,将即将运行的线程的寄存器从内核栈中回复,将上一个的寄存器存到内存栈中
用户空间的堆栈,在task_struct->mm->vm_area里面描述,都是属于进程虚拟地址空间的一个区域。
而内核态的栈在tsak_struct->stack里面描述,其底部是thread_info对象,thread_info可以用来快速获取task_struct对象。整个stack区域一般只有一个内存页(可配置),32位机器也就是4KB。
CPU上下文切换
CPU 上下文切换,就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
根据任务的不同,CPU 的上下文切换就可以分为几个不同的场景,也就是进程上下文切换、线程上下文切换以及中断上下文切换。
核态的切换
用户进程进行系统调用,就会切换到内核态,完成后又切换回用户进程,所以一次调用完成了两次cpu的切换
系统调用过程中,并不会涉及到虚拟内存等进程用户态的资源,也不会切换进程。这跟我们通常所说的进程上下文切换是不一样的:
- 进程上下文切换,是指从一个进程切换到另一个进程运行。
- 而系统调用过程中一直是同一个进程在运行。
所以,系统调用过程通常称为特权模式切换,而不是上下文切换。但实际上,系统调用过程中,CPU 的上下文切换还是无法避免的。
进程的上下文切换会切换哪些内容?
进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。
进程的上下文切换就比系统调用时多了一步:在保存当前进程的内核状态和 CPU 寄存器之前,需要先把该进程的虚拟内存、栈等保存下来;而加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。

进程切换的场景
- 其一,为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行。
- 其二,进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。
- 其三,当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。
- 其四,当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
- 最后一个,发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。
线程上下文切换
线程与进程最大的区别在于,线程是调度的基本单位,而进程则是资源拥有的基本单位。说白了,所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存、全局变量等资源。所以,对于线程和进程,我们可以这么理解:
- 当进程只有一个线程时,可以认为进程就等于线程。
- 当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
- 另外,线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
这么一来,线程的上下文切换其实就可以分为两种情况:
- 第一种, 前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样。
- 第二种,前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。
中断上下文切换
中断上下文切换并不涉及到进程的用户态,即假如打断了一个用户进程,用户态的虚拟内存等等不用保存,当中断处理程序执行的时候是不破坏这些内容的,中断后继续执行就像什么都没发生一样。
上下文切换调优
一般步骤:
有监控的情况下,首先去看看监控大盘,看看有没有异常报警,如果初期还没有监控的情况我会按照下面步骤去看看系统层面有没有异常
1、我首先会去看看系统的平均负载,使用top或者htop命令查看,平均负载体现的是系统的一个整体情况,他应该是cpu、内存、磁盘性能的一个综合,一般是平均负载的值大于机器cpu的核数,这时候说明机器资源已经紧张了
2、平均负载高了以后,接下来就要看看具体是什么资源导致,我首先会在top中看cpu每个核的使用情况,如果占比很高,那瓶颈应该是cpu,接下来就要看看是什么进程导致的
3、如果cpu没有问题,那接下来我会去看内存,首先是用free去查看内存的是用情况,但不直接看他剩余了多少,还要结合看看cache和buffer,然后再看看具体是什么进程占用了过高的内存,我也是是用top去排序
4、内存没有问题的话就要去看磁盘了,磁盘我用iostat去查看,我遇到的磁盘问题比较少
5、还有就是带宽问题,一般会用iftop去查看流量情况,看看流量是否超过的机器给定的带宽
6、涉及到具体应用的话,就要根据具体应用的设定参数来查看,比如连接数是否查过设定值等
7、如果系统层各个指标查下来都没有发现异常,那么就要考虑外部系统了,比如数据库、缓存、存储等
CPU的优化
负载的优化
- 查询
- 判断
- 解决
具体操作
查询
uptime指令
返回
$ uptime
02:34:03 up 2 days, 20:14, 1 user, load average: 0.63, 0.83, 0.88
解释
02:34:03 //当前时间
up 2 days, 20:14 //系统运行时间
1 user //正在登录用户数
而最后三个数字呢,依次则是过去 1 分钟、5 分钟、15 分钟的平均负载(Load Average)。即平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数
判断
查出cpu个数
# 关于grep和wc的用法请查询它们的手册或者网络搜索
$ grep 'model name' /proc/cpuinfo | wc -l
得到cpu的个数后,
- 当平均负载比 CPU 个数还大的时候,系统已经出现了过载。
那么,在实际生产环境中,平均负载多高时,需要我们重点关注呢?在我(倪朋飞)看来,当平均负载高于 CPU 数量 70%的时候,你就应该分析排查负载高的问题了。一旦负载过高,就可能导致进程响应变慢,进而影响服务的正常功能。
平均负载案例分析
- 工具
sysstat 包含了常用的 Linux 性能工具,用来监控和分析系统的性能。我们的案例会用到这个包的两个命令 mpstat 和 pidstat。mpstat 是一个常用的多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有 CPU 的平均指标。pidstat 是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标。
stress 是一个 Linux 系统压力测试工具,这里我们用作异常进程模拟平均负载升高的场景。
平均使用率的优化
平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数。所以,它不仅包括了正在使用 CPU 的进程,还包括等待 CPU 和等待 I/O 的进程。而 CPU 使用率,是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完全对应。比如:
- CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;
- I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;
- 大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
CPU 上下文切换优化
CPU 上下文切换,是保证 Linux 系统正常工作的核心功能之一,一般情况下不需要我们特别关注。但过多的上下文切换,会把 CPU 时间消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,从而缩短进程真正运行的时间,导致系统的整体性能大幅下降。
怎么查看系统的上下文切换情况
vmstat
# 每隔5秒输出1组数据
$ vmstat 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 7005360 91564 818900 0 0 0 0 25 33 0 0 100 0 0
特别关注的四列内容:-
- cs(context switch)是每秒上下文切换的次数。
- in(interrupt)则是每秒中断的次数。
- r(Running or Runnable)是就绪队列的长度,也就是正在运行和等待 CPU 的进程数。
- b(Blocked)则是处于不可中断睡眠状态的进程数。
前面提到过的 pidstat 了。给它加上 -w 选项,你就可以查看每个进程上下文切换的情况了。
# 每隔5秒输出1组数据
$ pidstat -w 5
Linux 4.15.0 (ubuntu) 09/23/18 _x86_64_ (2 CPU)
08:18:26 UID PID cswch/s nvcswch/s Command
08:18:31 0 1 0.20 0.00 systemd
08:18:31 0 8 5.40 0.00 rcu_sched
...
这个结果中有两列内容是我们的重点关注对象。一个是 cswch ,表示每秒自愿上下文切换(voluntary context switches)的次数,另一个则是 nvcswch ,表示每秒非自愿上下文切换(non voluntary context switches)的次数。
- 所谓自愿上下文切换,是指进程无法获取所需资源,导致的上下文切换。比如说, I/O、内存等系统资源不足时,就会发生自愿上下文切换。
- 而非自愿上下文切换,则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换。
注意:pidstat 默认显示进程的指标数据,加上 -t 参数后,才会输出线程的指标。
无法通过top查看到的cpu大量占用的情况
碰到常规问题无法解释的 CPU 使用率情况时,首先要想到有可能是短时应用导致的问题,比如有可能是下面这两种情况。
- 第一,应用里直接调用了其他二进制程序,这些程序通常运行时间比较短,通过 top 等工具也不容易发现。
- 第二,应用本身在不停地崩溃重启,而启动过程的资源初始化,很可能会占用相当多的 CPU。对于这类进程,我们可以用 pstree 或者 execsnoop 找到它们的父进程,再从父进程所在的应用入手,排查问题的根源。
系统中出现大量不可中断进程和僵尸进程怎么办?
dstat 是一个新的性能工具,它吸收了 vmstat、iostat、ifstat 等几种工具的优点,可以同时观察系统的 CPU、磁盘 I/O、网络以及内存使用情况。
查看这些进程的磁盘读写情况。对了,别忘了工具是什么。一般要查看某一个进程的资源使用情况,都可以用我们的老朋友 pidstat,不过这次记得加上 -d 参数,以便输出 I/O 使用情况。
strace 正是最常用的跟踪进程系统调用的工具。
- 使用top找到僵尸进程
- 使用pstree -aps 3084查看父进程
- 所以,我们接着查看 app 应用程序的代码,看看子进程结束的处理是否正确,比如有没有调用 wait() 或 waitpid() ,抑或是,有没有注册 SIGCHLD 信号的处理函数。
内存
一个关键字:虚拟
动机:(为了每个进程能获得)隔离,很大,连续的内存
目标:透明,效率,保护。
虚拟内存(VM)系统的一个主要目标是透明(transparency)。操作系统实现虚拟内存的方式,应该让运行的程序看不见。因此,程序不应该感知到内存被虚拟化的事实,相反,程序的行为就好像它拥有自己的私有物理内存。在幕后,操作系统(和硬件)完成了所有的工作,让不同的工作复用内存,从而实现这个假象。
虚拟内存的另一个目标是效率(efficiency)。操作系统应该追求虚拟化尽可能高效(efficient),包括时间上(即不会使程序运行得更慢)和空间上(即不需要太多额外的内存来支持虚拟化)。在实现高效率虚拟化时,操作系统将不得不依靠硬件支持,包括TLB这样的硬件功能(我们将在适当的时候学习)。
最后,虚拟内存第三个目标是保护(protection)。操作系统应确保进程受到保护(protect),不会受其他进程影响,操作系统本身也不会受进程影响。当一个进程执行加载、存储或指令提取时,它不应该以任何方式访问或影响任何其他进程或操作系统本身的内存内容(即在它的地址空间之外的任何内容)。因此,保护让我们能够在进程之间提供隔离(isolation)的特性,每个进程都应该在自己的独立环境中运行,避免其他出错或恶意进程的影响。 《操作系统导论》
内存的演进
- 基址+偏移的映射模式(一般由硬件转换)。缺点:如果将整个地址空间放入物理内存,那么栈和堆之间的空间并没有被进程使用,却依然占用了实际的物理内存。
- 分段:在MMU中引入不止一个基址和界限寄存器对,而是给地址空间内的每个逻辑段(segment)一对。
- 计算物理地址:虚拟地址-虚拟基址+物理(段)基址
- 优点:栈和堆之间没有使用的区域就不需要再分配物理内存,让我们能将更多地址空间放进物理内存。
- 空闲列表管理算法:首次匹配,最优匹配,最坏匹配。
段页式内存概念
操作系统有两种方法,来解决大多数空间管理问题。第一种是将空间分割成不同长度的分片,就像虚拟内存管理中的分段。遗憾的是,这个解决方法存在固有的问题。具体来说,将空间切成不同长度的分片以后,空间本身会碎片化(fragmented),随着时间推移,分配内存会变得比较困难。因此,值得考虑第二种方法:将空间分割成固定长度的分片。在虚拟内存中,我们称这种思想为分页 ---------《操作系统导论》
用户空间内存包括多个不同的内存段,比如只读段、数据段、堆、栈以及文件映射段等。这些内存段正是应用程序使用内存的基本方式。
段中出现内存泄漏的情况
- 只读段,包括程序的代码和常量,由于是只读的,不会再去分配新的内存,所以也不会产生内存泄漏。
- 数据段,包括全局变量和静态变量,这些变量在定义时就已经确定了大小,所以也不会产生内存泄漏。
- 最后一个内存映射段,包括动态链接库和共享内存,其中共享内存由程序动态分配和管理。所以,如果程序在分配后忘了回收,就会导致跟堆内存类似的泄漏问题。
页是存储管理方式适合高效率的利用存储空间。
段式存储管理方式是从程序的角度来管理内存,便于程序的共享和保护
为了结合这两部分的优点,于是产生了段页式的存储管理方式。在段式存储管理中结合分页存储管理技术,在一个分段内划分页面,就形成了段页式存储管理。
注意段分为代码段数据段和栈段等的划分方法

总线寻址问题
在32位机器中,地址总线32位,每个地址存一个字节(数据总线8位)
所以32位的寻址空间就是4GB
虚拟内存
https://zhenbianshu.github.io/2018/11/understand_virtual_memory.html
虚拟内存
毋庸置疑,虚拟内存绝对是操作系统中最重要的概念之一。我想主要是由于内存的重要”战略地位”。CPU太快,但容量小且功能单一,其他 I/O 硬件支持各种花式功能,可是相对于 CPU,它们又太慢。于是它们之间就需要一种润滑剂来作为缓冲,这就是内存大显身手的地方。
而在现代操作系统中,多任务已是标配。多任务并行,大大提升了 CPU 利用率,但却引出了多个进程对内存操作的冲突问题,虚拟内存概念的提出就是为了解决这个问题。

上图是虚拟内存最简单也是最直观的解释。
操作系统有一块物理内存(中间的部分),有两个进程(实际会更多)P1 和 P2,操作系统偷偷地分别告诉 P1 和 P2,我的整个内存都是你的,随便用,管够。可事实上呢,操作系统只是给它们画了个大饼,这些内存说是都给了 P1 和 P2,实际上只给了它们一个序号而已。只有当 P1 和 P2 真正开始使用这些内存时,系统才开始使用辗转挪移,拼凑出各个块给进程用,P2 以为自己在用 A 内存,实际上已经被系统悄悄重定向到真正的 B 去了,甚至,当 P1 和 P2 共用了 C 内存,他们也不知道。
操作系统的这种欺骗进程的手段,就是虚拟内存。对 P1 和 P2 等进程来说,它们都以为自己占用了整个内存,而自己使用的物理内存的哪段地址,它们并不知道也无需关心。
分页和页表
虚拟内存是操作系统里的概念,对操作系统来说,虚拟内存就是一张张的对照表,P1 获取 A 内存里的数据时应该去物理内存的 A 地址找,而找 B 内存里的数据应该去物理内存的 C 地址。
我们知道系统里的基本单位都是 Byte 字节,如果将每一个虚拟内存的 Byte 都对应到物理内存的地址,每个条目最少需要 8字节(32位虚拟地址->32位物理地址),在 4G 内存的情况下,就需要 32GB 的空间来存放对照表,那么这张表就大得真正的物理地址也放不下了,于是操作系统引入了 页(Page)的概念。
在系统启动时,操作系统将整个物理内存以 4K 为单位,划分为各个页。之后进行内存分配时,都以页为单位,那么虚拟内存页对应物理内存页的映射表就大大减小了,4G 内存,只需要 8M 的映射表即可,一些进程没有使用到的虚拟内存,也并不需要保存映射关系,而且Linux 还为大内存设计了多级页表,可以进一页减少了内存消耗。操作系统虚拟内存到物理内存的映射表,就被称为页表。
内存寻址和分配
我们知道通过虚拟内存机制,每个进程都以为自己占用了全部内存,进程访问内存时,操作系统都会把进程提供的虚拟内存地址转换为物理地址,再去对应的物理地址上获取数据。CPU 中有一种硬件,内存管理单元 MMU(Memory Management Unit)专门用来将翻译虚拟内存地址。CPU 还为页表寻址设置了缓存策略,由于程序的局部性,其缓存命中率能达到 98%。
以上情况是页表内存在虚拟地址到物理地址的映射,而如果进程访问的物理地址还没有被分配,系统则会产生一个缺页中断,在中断处理时,系统切到内核态为进程虚拟地址分配物理地址。
页表存在哪里
由于页表如此之大,我们没有在MMU中利用任何特殊的片上硬件,来存储当前正在运行的进程的页表,而是将每个进程的页表存储在内存中。
即页表
页表项都有哪些位
- 有效位(validbit)通常用于指示特定地址转换是否有效。例如,当一个程序开始运行时,它的代码和堆在其地址空间的一端,栈在另一端。所有未使用的中间空间都将被标记为无效(invalid),如果进程尝试访问这种内存,就会陷入操作系统,可能会导致该进程终止。因此,有效位对于支持稀疏地址空间至关重要。通过简单地将地址空间中所有未使用的页面标记为无效,我们不再需要为这些页面分配物理帧,从而节省大量内存。
- 我们还可能有保护位(protection bit),表明页是否可以读取、写入或执行。同样,以这些位不允许的方式访问页,会陷入操作系统。还有其他一些重要的部分,但现在我们不会过多讨论。
- 存在位(present bit)表示该页是在物理存储器还是在磁盘上(即它已被换出,swapped out)。当我们研究如何将部分地址空间交换(swap)到磁盘,从而支持大于物理内存的地址空间时,我们将进一步理解这一机制。交换允许操作系统将很少使用的页面移到磁盘,从而释放物理内存。
- 脏位(dirty bit)也很常见,表明页面被带入内存后是否被修改过。
- 参考位(reference bit,也被称为访问位,accessed bit)有时用于追踪页是否被访问,也用于确定哪些页很受欢迎,因此应该保留在内存中。
分页寻址的过程
硬件将虚拟地址转化为物理地址。
- 找到页表基址寄存器,找到页表在内存中的位置
- 提取pte,计算获得物理地址
进程调用mmap,内核做了哪些呢?
- 建立进程虚拟地址空间与文件内容空间之间的映射
- 而后第一次读写mmap映射的内存时,由于页表并未与物理内存映射,触发缺页异常
- 缺页异常程序先根据要访问的偏移和大小从page cache中查询是否有该文件的缓存,如果找到就更新进程页表指向page cache那段物理内存
- 没找到就将文件从磁盘加载到内核page cache,然后再令进程的mmap虚拟地址的页表指向这段page cache中文件部分的物理内存
所以结论是,内核会把文件读到page cache中。
也只有这样,其它进程打开的文件会和mmap打开的文件读写结果保持一致。
虚拟内存的好处
-
进程内存管理
-
数据共享
-
SWAP
虚拟内存可以让帮进程”扩充”内存。我们前文提到了虚拟内存通过缺页中断为进程分配物理内存,内存总是有限的,如果所有的物理内存都被占用了怎么办呢?
Linux 提出 SWAP 的概念,Linux 中可以使用 SWAP 分区,在分配物理内存,但可用内存不足时,将暂时不用的内存数据先放到磁盘上,让有需要的进程先使用,等进程再需要使用这些数据时,再将这些数据加载到内存中,通过这种”交换”技术,Linux 可以让进程使用更多的内存。
缺页中断
Major/Minor page fault区别
分页寻址的问题以及TLB的引出
页表在内存中,所以寻找页表也是个很慢的内存寻址过程
解决:增加旁路转换器translation-lookaside buffer。更好的名称应该是地址转换缓存(address-translation cache)
它就是频繁发生的虚拟到物理地址转换的硬件缓存(cache),即硬件承担许多页表访问的责任
- 频繁
- 硬件
- 缓存
TLB:
也叫快表,直译为旁路快表缓冲,也可以理解为页表缓冲,地址变换高速缓存。
举例,找你家的地址省市县一级一级的找还是直接记录你名字和你家的地址
TLB是translation lookaside buffer的简称。首先,我们知道MMU的作用是把虚拟地址转换成物理地址。虚拟地址和物理地址的映射关系存储在页表中,而现在页表又是分级的。64位系统一般都是3~5级。常见的配置是4级页表,就以4级页表为例说明。分别是PGD、PUD、PMD、PTE四级页表。在硬件上会有一个叫做页表基地址寄存器,它存储PGD页表的首地址。MMU就是根据页表基地址寄存器从PGD页表一路查到PTE,最终找到物理地址(PTE页表中存储物理地址)。这就像在地图上显示你的家在哪一样,我为了找到你家的地址,先确定你是中国,再确定你是某个省,继续往下某个市,最后找到你家是一样的原理。一级一级找下去。这个过程你也看到了,非常繁琐。如果第一次查到你家的具体位置,我如果记下来你的姓名和你家的地址。下次查找时,是不是只需要跟我说你的姓名是什么,我就直接能够告诉你地址,而不需要一级一级查找。四级页表查找过程需要四次内存访问。延时可想而知,非常影响性能。
由于页表存放在主存中,因此程序每次访存至少需要两次:一次访存获取物理地址,第二次访存才获得数据。提高访存性能的关键在于依靠页表的访问局部性。当一个转换的虚拟页号被使用时,它可能在不久的将来再次被使用到,。
TLB是一种高速缓存,内存管理硬件使用它来改善虚拟地址到物理地址的转换速度。当前所有的个人桌面,笔记本和服务器处理器都使用TLB来进行虚拟地址到物理地址的映射。使用TLB内核可以快速的找到虚拟地址指向物理地址,而不需要请求RAM内存获取虚拟地址到物理地址的映射关系。这与data cache和instruction caches有很大的相似之处。
TLB原理
当cpu要访问一个虚拟地址/线性地址时,CPU会首先根据虚拟地址的高20位(20是x86特定的,不同架构有不同的值)在TLB中查找。如果是表中没有相应的表项,称为TLB miss,需要通过访问慢速RAM中的页表计算出相应的物理地址。同时,物理地址被存放在一个TLB表项中,以后对同一线性地址的访问,直接从TLB表项中获取物理地址即可,称为TLB hit。
想像一下x86_32架构下没有TLB的存在时的情况,对线性地址的访问,首先从PGD中获取PTE(第一次内存访问),在PTE中获取页框地址(第二次内存访问),最后访问物理地址,总共需要3次RAM的访问。如果有TLB存在,并且TLB hit,那么只需要一次RAM访问即可。
TLB结构
VPN | PFN | 其他位
其他位包含是否有效,进程切换后这个共享的tlb的所有项都被置为无效。
TLB的歧义问题
我们知道不同的进程之间看到的虚拟地址范围是一样的,所以多个进程下,不同进程的相同的虚拟地址可以映射不同的物理地址。这就会造成歧义问题。例如,进程A将地址0x2000映射物理地址0x4000。进程B将地址0x2000映射物理地址0x5000。当进程A执行的时候将0x2000对应0x4000的映射关系缓存到TLB中。当切换B进程的时候,B进程访问0x2000的数据,会由于命中TLB从物理地址0x4000取数据。这就造成了歧义。
如何消除这种歧义,我们可以借鉴VIVT数据cache的处理方式,在进程切换时将整个TLB无效。切换后的进程都不会命中TLB,但是会导致性能损失。清空TLB,这是一个可行的解决方案,进程不会再读到错误的地址映射。但是,有一定开销:每次进程运行,当它访问数据和代码页时,都会触发TLB未命中。如果操作系统频繁地切换进程,这种开销会很高。为了减少这种开销,一些系统增加了硬件支持,实现跨上下文切换的TLB共享。比如有的系统在TLB中添加了一个地址空间标识符
TLB未命中
- 硬件来处理,比如x86构造,硬件遍历页表
- 软件处理。risc架构使用这种。TLB未命中时,硬件系统会抛出一个异常(见图19.3第11行),这会暂停当前的指令流,将特权级提升至内核模式,跳转至陷阱处理程序(trap handler)。接下来你可能已经猜到了,这个陷阱处理程序是操作系统的一段代码,用于处理TLB未命中。这段代码在运行时,会查找页表中的转换映射,然后用特别的“特权”指令更新TLB,并从陷阱返回。此时,硬件会重试该指令(导致TLB命中)。
让页表更小
简单的解决方案
更大的页
许多体系结构(例如MIPS、SPARC、x86-64)现在都支持多种页大小。通常使用一个小的(4KB或8KB)页大小。但是,如果一个“聪明的”应用程序请求它,则可以为地址空间的特定部分使用一个大型页(例如,大小为4MB),从而让这些应用程序可以将常用的(大型的)数据结构放入这样的空间,同时只占用一个TLB项。
混合方法:分页和分段
杂合方案的关键区别在于,每个分段都有界限寄存器,每个界限寄存器保存了段中最大有效页的值。例如,如果代码段使用它的前3个页(0、1和2),则代码段页表将只有3个项分配给它,并且界限寄存器将被设置为3。内存访问超出段的末尾将产生一个异常,并可能导致进程终止。以这种方式,与线性页表相比,杂合方法实现了显著的内存节省。栈和堆之间未分配的页不再占用页表中的空间(仅将其标记为无效)。
多级页表
将线性页表变成了类似树的东西,这种方法非常有效,许多现代系统都用它
多级页表分配的页表空间,与你正在使用的地址空间内存量成比例。因此它通常很紧凑,并且支持稀疏的地址空间。
反向页表(神奇)
项是物理地址,哪个进程哪个虚拟地址使用了这个地址。
换出
见下面
换入换出
页面替换策略:
- 最优替换:替换将来最迟使用到的页面,基于未来知识,无法实现。
- fifo
- lru 策略替换最近最少使用的页面,基于历史
- lfu 最不经常使用,基于历史
- 近似lru的时钟算法:系统中的所有页都放在一个循环列表中。时钟指针(clock hand)开始时指向某个特定的页(哪个页不重要)。当必须进行页替换时,操作系统检查当前指向的页P的使用位是1还是0。如果是1,则意味着页面P最近被使用,因此不适合被替换。然后,P的使用位设置为0,时钟指针递增到下一页(P + 1)。该算法一直持续到找到一个使用位为0的页,使用位为0意味着这个页最近没有被使用过(在最坏的情况下,所有的页都已经被使用了,那么就将所有页的使用位都设置为0)。
为什么要有脏页标志位?
脏页:踢出时要写磁盘,
干净页:直接踢出。
其他技术
预取技术:提前将磁盘中的页读到内存,利用空间局部性原理
聚簇写入:将多个页一次io写入内存
物理内存比虚拟内存小,就会频繁发生换入换出
- 目前的策略是运行一个杀手程序,杀死内存使用多的程序
懒加载页(缺页中断)
- 当页加载到地址空间中,只需要将页表项中添加,并置为不可访问。只有当用的时候,缺页中断,陷入系统调用,在去将物理页置零(防止其他进程使用)。
在一个初级实现中,操作系统响应一个请求,在物理内存中找到页,将该页添加到你的堆中,并将其置零(安全起见,这是必需的。否则,你可以看到其他进程使用该页时的内容。),然后将其映射到你的地址空间(设置页表以根据需要引用该物理页)。但是初级实现可能是昂贵的,特别是如果页没有被进程使用。
利用按需置零,当页添加到你的地址空间时,操作系统的工作很少。它会在页表中放入一个标记页不可访问的条目。如果进程读取或写入页,则会向操作系统发送陷阱。在处理陷阱时,操作系统注意到(通常通过页表项中“保留的操作系统字段”部分标记的一些位),这实际上是一个按需置零页。此时,操作系统会完成寻找物理页的必要工作,将它置零,并映射到进程的地址空间。如果该进程从不访问该页,则所有这些工作都可以避免,从而体现按需置零的好处。
写时复制
(copy-on-write,COW)
- 还是惰性思想的体现,如果复制前后的文件都是为了读,两者直接共享物理空间地址算了。好懒哦
如果操作系统需要将一个页面从一个地址空间复制到另一个地址空间,不是实际复制它,而是将其映射到目标地址空间,并在两个地址空间中将其标记为只读。如果两个地址空间都只读取页面,则不会采取进一步的操作,因此操作系统已经实现了快速复制而不实际移动任何数据。
- fork()就利用了cow,来复制新的进程空间
页缓存与文件的io
io分为两种,直接io和非直接io
详细见下面io一节,本节介绍页缓存。
对于非直接io, 需要与页缓存交互
Linux系统在读取文件时,会优先从页缓存中读取文件内容,如果页缓存不存在,系统会先从磁盘中读取文件内容更新到页缓存中,然后再从页缓存中读取文件内容并返回。大致过程如下:
- 进程调用库函数read发起读取文件请求
- 内核检查已打开的文件列表,调用文件系统提供的read接口
- 找到文件对应的inode,然后计算出要读取的具体的页
- 通过inode查找对应的页缓存,1)如果页缓存节点命中,则直接返回文件内容;2)如果没有对应的页缓存,则会产生一个缺页异常(page fault)。这时系统会创建新的空的页缓存并从磁盘中读取文件内容,更新页缓存,然后重复第4步
- 读取文件返回
所以说,所有的文件内容的读取,无论最初有没有命中页缓存,最终都是直接来源于页缓存。
进程/线程和虚拟内存的关系
常用内存管理命令
-
查看系统内存状态
查看系统内存情况的方式有很多,free、 vmstat等命令都可输出当前系统的内存状态,需要注意的是可用内存并不只是 free 这一列,由于操作系统的 lazy 特性,大量的 buffer/cache 在进程不再使用后,不会被立即清理,如果之前使用它们的进程再次运行还可以继续使用,它们在必要时也是可以被利用的。此外,通过
cat /proc/meminfo可以查看系统内存被使用的详细情况,包括脏页状态等。详情可参见:/PROC/MEMINFO之谜。 -
pmap
如果想单独查看某一进程的虚拟内存分布情况,可以使用 pmap pid 命令,它会把虚拟内存各段的占用情况从低地址到高地址都列出来。可以添加 -XX 参数来输出更详细的信息。
-
修改内存配置
我们也可以修改 Linux 的系统配置,使用sysctl vm [-options] CONFIG或 直接读写/proc/sys/vm/目录下的文件来查看和修改配置。 -
SWAP 操作
虚拟内存的 SWAP 特性并不总是有益,放任进程不停地将数据在内存与磁盘之间大量交换会极大地占用 CPU,降低系统运行效率,所以有时候我们并不希望使用 swap。
我们可以修改 vm.swappiness=0 来设置内存尽量少使用 swap,或者干脆使用 swapoff 命令禁用掉 SWAP。
内存回收与分配
总结:https://time.geekbang.org/column/article/75797
在内存资源紧张时,Linux 通过直接内存回收和定期扫描的方式,来释放文件页和匿名页,以便把内存分配给更需要的进程使用。
- 文件页的回收比较容易理解,直接清空,或者把脏数据写回磁盘后再释放。
- 而对匿名页的回收,需要通过 Swap 换出到磁盘中,下次访问时,再从磁盘换入到内存中。
你可以设置 /proc/sys/vm/min_free_kbytes,来调整系统定期回收内存的阈值(也就是页低阈值),还可以设置 /proc/sys/vm/swappiness,来调整文件页和匿名页的回收倾向。
在 NUMA 架构下,每个 Node 都有自己的本地内存空间,而当本地内存不足时,默认既可以从其他 Node 寻找空闲内存,也可以从本地内存回收。
你可以设置 /proc/sys/vm/zone_reclaim_mode ,来调整 NUMA 本地内存的回收策略。
一旦发现内存紧张,系统会通过三种方式回收内存。
- 基于 LRU(Least Recently Used)算法,回收缓存;
- 基于 Swap 机制,回收不常访问的匿名页;(也是基于lru算法)
- 基于 OOM(Out of Memory)机制,杀掉占用大量内存的进程。
# 查询oom日志 $ dmesg | grep -i "Out of memory" Out of memory: Kill process 9329 (java) score 321 or sacrifice child
回收内存既包括了文件页,又包括了匿名页。
- 对文件页的回收,当然就是直接回收缓存,或者把脏页写回磁盘后再回收。
- 而对匿名页的回收,其实就是通过 Swap 机制,把它们写入磁盘后再释放内存。
内存回收又分为:
-
直接内存回收
-
定期回收内存
kswapd0 定义了三个内存阈值(watermark,也称为水位),分别是页最小阈值(pages_min)、页低阈值(pages_low)和页高阈值(pages_high)。剩余内存,则使用 pages_free 表示。
我们可以看到,一旦剩余内存小于页低阈值,就会触发内存的回收。这个页低阈值,其实可以通过内核选项 /proc/sys/vm/min_free_kbytes 来间接设置。min_free_kbytes 设置了页最小阈值,而其他两个阈值,都是根据页最小阈值计算生成的,计算方法如下 :
pages_low = pages_min*5/4
pages_high = pages_min*3/2
三个内存阈值(页最小阈值、页低阈值和页高阈值),都可以通过内存域在 proc 文件系统中的接口 /proc/zoneinfo 来查看。
$ cat /proc/zoneinfo
...
Node 0, zone Normal
pages free 227894
min 14896
low 18620
high 22344
...
nr_free_pages 227894
nr_zone_inactive_anon 11082
nr_zone_active_anon 14024
nr_zone_inactive_file 539024
nr_zone_active_file 923986
...
从这个输出结果可以发现,剩余内存远大于页高阈值,所以此时的 kswapd0 不会回收内存。
NUMA 与 Swap
http://kuanghy.github.io/2019/11/16/linux-swap
Linux 的交换分区(swap),或者叫内存置换空间(swap space),是磁盘上的一块区域,可以是一个分区,也可以是一个文件,或者是他们的组合。交换分区的作用是,当系统物理内存吃紧时,Linux 会将内存中不常访问的数据保存到 swap 上,这样系统就有更多的物理内存为各个进程服务,而当系统需要访问 swap 上存储的内容时,再将 swap 上的数据加载到内存中,也就是常说的 swap out 和 swap in。
Swap 说白了就是把一块磁盘空间或者一个本地文件(以下讲解以磁盘为例),当成内存来使用。它包括换出和换入两个过程。
- 所谓换出,就是把进程暂时不用的内存数据存储到磁盘中,并释放这些数据占用的内存。
- 而换入,则是在进程再次访问这些内存的时候,把它们从磁盘读到内存中来。
在 NUMA 架构下,多个处理器被划分到不同 Node 上,且每个 Node 都拥有自己的本地内存空间。
内存管理算法(空闲列表,Buddy和Slab)
使用空闲列表(链表的形式)
- 每个malloc的空间,都会返回一个ptr,ptr前是这段空间的大小以及一个magic数:1234567。以便free。
- 在所分配的空间的本身会有一个空闲链表的,可以获得头结点,链表的内容是本空闲区域长度以及下一个链表节点的地址(next)。
- 除了单纯的空闲列表,还有种更快的空闲空间分配方式:slab
- 思想:如果某个应用程序经常申请一种(或几种)大小的内存空间,那就用一个独立的列表,只管理这样大小的对象。其他大小的请求都交给更通用的内存分配程序。
- 实践:在内核启动时,它为可能频繁请求的内核对象创建一些对象缓存(object cache),如锁和文件系统inode等。这些的对象缓存每个分离了特定大小的空闲列表,因此能够很快地响应内存请求和释放。如果某个缓存中的空闲空间快耗尽时,它就向通用内存分配程序申请一些内存厚块(slab)(总量是页大小和对象大小的公倍数)。相反,如果给定厚块中对象的引用计数变为0,通用的内存分配程序可以从专门的分配程序中回收这些空间,这通常发生在虚拟内存系统需要更多的空间的时候。
因为合并对分配程序很关键,所以人们设计了一些方法,让合并变得简单,一个好例子就是二分伙伴分配程序(binary buddy allocator)
Buddy分配算法
把所有的空闲页框分组为11个块链表,每个块链表分别包含大小为1,2,4,8,16,32,64,128,256,512和1024个连续页框的页框块。最大可以申请1024个连续页框,对应4MB大小的连续内存。每个页框块的第一个页框的物理地址是该块大小的整数倍,如图:
假设要申请一个256个页框的块,先从256个页框的链表中查找空闲块,如果没有,就去512个页框的链表中找,找到了则将页框块分为2个256个页框的块,一个分配给应用,另外一个移到256个页框的链表中。如果512个页框的链表中仍没有空闲块,继续向1024个页框的链表查找,如果仍然没有,则返回错误。页框块在释放时,会主动将两个连续的页框块合并为一个较大的页框块。
slab
https://blog.csdn.net/qq_26626709/article/details/52742484
- 在linux内核中伙伴系统用来管理物理内存,其分配的单位是页,分配的粒度又太大。
- 由于内核无法借助标准的C库,因而需要别的手段来实现内核中动态内存的分配管理,linux采用的是slab分配器。slab分配器不仅可以提供动态内存的管理功能,而且可以作为经常分配并释放的内存的缓存。
- 通过slab缓存,内核能够储备一些对象,供后续使用。需要注意的是slab分配器只管理内核的常规地址空间(准确的说是直接被映射到内核地址空间的那部分内存包括ZONE_NORMAL和ZONE_DMA)。
采用了slab分配器后,在释放内存时,slab分配器将释放的内存块保存在一个列表中,而不是返回给伙伴系统。在下一次内核申请同样类型的对象时,会使用该列表中的内存开。slab分配器分配的优点:- 可以提供小块内存的分配支持
- 不必每次申请释放都和伙伴系统打交道,提供了分配释放效率
- 如果在slab缓存的话,其在CPU高速缓存的概率也会较高。
- 伙伴系统的操作队系统的数据和指令高速缓存有影响,slab分配器降低了这种副作用
- 伙伴系统分配的页地址都页的倍数,这对CPU的高速缓存的利用有负面影响,页首地址对齐在页面大小上使得如果每次都将数据存放到从伙伴系统分配的页开始的位置会使得高速缓存的有的行被过度使用,而有的行几乎从不被使用。slab分配器通过着色使得slab对象能够均匀的使用高速缓存,提高高速缓存的利用率
两个主要作用:
- Slab对小对象进行分配,不用为每个小对象分配一个页,节省了空间。
- 内核中一些小对象创建析构很频繁,Slab对这些小对象做缓存,可以重复利用一些相同的对象,减少内存分配次数。
slab分配器专为小内存分配而生。slab分配器分配内存以Byte为单位。但是slab分配器并没有脱离伙伴系统,而是基于伙伴系统分配的大内存进一步细分成小内存分配。我们先来看一张图:
kmem_cache是一个cache_chain的链表,描述了一个高速缓存,每个高速缓存包含了一个slabs的列表,这通常是一段连续的内存块。存在3种slab:
- slabs_full(完全分配的slab)
- slabs_partial(部分分配的slab)
- slabs_empty(空slab,或者没有对象被分配)。
slab是slab分配器的最小单位,在实现上一个slab有一个货多个连续的物理页组成(通常只有一页)。单个slab可以在slab链表之间移动,例如如果一个半满slab被分配了对象后变满了,就要从slabs_partial中被删除,同时插入到slabs_full中去。
内存优化
缓存优化
运行 cachestat 和 cachetop
$ cachestat 1 3
TOTAL MISSES HITS DIRTIES BUFFERS_MB CACHED_MB
2 0 2 1 17 279
2 0 2 1 17 279
2 0 2 1 17 279
- TOTAL ,表示总的 I/O 次数;
- MISSES ,表示缓存未命中的次数;
- HITS ,表示缓存命中的次数;
- DIRTIES, 表示新增到缓存中的脏页数;
- BUFFERS_MB 表示 Buffers 的大小,以 MB 为单位;
- CACHED_MB 表示 Cache 的大小,以 MB 为单位。
除了缓存的命中率外,还有一个指标你可能也会很感兴趣,那就是指定文件在内存中的缓存大小。你可以使用 pcstat 这个工具,来查看文件在内存中的缓存大小以及缓存比例。
除了缓存的命中率外,还有一个指标你可能也会很感兴趣,那就是指定文件在内存中的缓存大小。你可以使用 pcstat 这个工具,来查看文件在内存中的缓存大小以及缓存比例。
除了缓存的命中率外,还有一个指标你可能也会很感兴趣,那就是指定文件在内存中的缓存大小。你可以使用 pcstat 这个工具,来查看文件在内存中的缓存大小以及缓存比例。
当 Swap 使用升高时,要如何定位和分析呢?
- 模拟大文件读取
# 写入空设备,实际上只有磁盘的读请求
$ dd if=/dev/sda1 of=/dev/null bs=1G count=2048
- 接着,在第二个终端中运行 sar 命令,查看内存各个指标的变化情况。你可以多观察一会儿,查看这些指标的变化情况。
# 间隔1秒输出一组数据
# -r表示显示内存使用情况,-S表示显示Swap使用情况
$ sar -r -S 1
04:39:56 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
04:39:57 6249676 6839824 1919632 23.50 740512 67316 1691736 10.22 815156 841868 4
04:39:56 kbswpfree kbswpused %swpused kbswpcad %swpcad
04:39:57 8388604 0 0.00 0 0.00
04:39:57 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
04:39:58 6184472 6807064 1984836 24.30 772768 67380 1691736 10.22 847932 874224 20
04:39:57 kbswpfree kbswpused %swpused kbswpcad %swpcad
04:39:58 8388604 0 0.00 0 0.00
…
04:44:06 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
04:44:07 152780 6525716 8016528 98.13 6530440 51316 1691736 10.22 867124 6869332 0
04:44:06 kbswpfree kbswpused %swpused kbswpcad %swpcad
04:44:07 8384508 4096 0.05 52 1.27
套路:如何“快准狠”找到系统内存的问题?
-
内存性能指标
首先,最容易想到的是系统内存使用情况,比如已用内存、剩余内存、共享内存、可用内存、缓存和缓冲区的用量等。
注意缓存是指文件,缓冲是指磁盘
- 已用内存和剩余内存很容易理解,就是已经使用和还未使用的内存。
- 共享内存是通过 tmpfs 实现的,所以它的大小也就是 tmpfs 使用的内存大小。tmpfs 其实也是一种特殊的缓存。
- 可用内存是新进程可以使用的最大内存,它包括剩余内存和可回收缓存。
- 缓存包括两部分,一部分是磁盘读取文件的页缓存,用来缓存从磁盘读取的数据,可以加快以后再次访问的速度。另一部分,则是 Slab 分配器中的可回收内存。
- 缓冲区是对原始磁盘块的临时存储,用来缓存将要写入磁盘的数据。这样,内核就可以把分散的写集中起来,统一优化磁盘写入。
第二类很容易想到的,应该是进程内存使用情况,比如进程的虚拟内存、常驻内存、共享内存以及 Swap 内存等。
-
虚拟内存,包括了进程代码段、数据段、共享内存、已经申请的堆内存和已经换出的内存等。这里要注意,已经申请的内存,即使还没有分配物理内存,也算作虚拟内存。
-
常驻内存是进程实际使用的物理内存,不过,它不包括 Swap 和共享内存。
-
共享内存,既包括与其他进程共同使用的真实的共享内存,还包括了加载的动态链接库以及程序的代码段等。
-
Swap 内存,是指通过 Swap 换出到磁盘的内存。
强调一下,缺页异常。
系统调用内存分配请求后,并不会立刻为其分配物理内存,而是在请求首次访问时,通过缺页异常来分配。缺页异常又分为下面两种场景。
-
可以直接从物理内存中分配时,被称为次缺页异常。
-
需要磁盘 I/O 介入(比如 Swap)时,被称为主缺页异常。
第三类重要指标就是 Swap 的使用情况,比如 Swap 的已用空间、剩余空间、换入速度和换出速度等。
- 内存性能工具
free vmstat cachetop cachestat memleak sar
3. 如何迅速分析内存的性能瓶颈
-
先用 free 和 top,查看系统整体的内存使用情况。
-
再用 vmstat 和 pidstat,sar,查看一段时间的趋势,从而判断出内存问题的类型。
-
最后进行详细分析,比如内存分配分析,swap、缓存 / 缓冲区分析、具体进程的内存使用分析等。
第一个例子,当你通过 free,发现大部分内存都被缓存占用后,可以使用 vmstat 或者 sar 观察一下缓存的变化趋势,确认缓存的使用是否还在继续增大。如果继续增大,则说明导致缓存升高的进程还在运行,那你就能用缓存 / 缓冲区分析工具(比如 cachetop、slabtop 等),分析这些缓存到底被哪里占用。
第二个例子,当你 free 一下,发现系统可用内存不足时,首先要确认内存是否被缓存 / 缓冲区占用。排除缓存 / 缓冲区后,你可以继续用 pidstat 或者 top,定位占用内存最多的进程。找出进程后,再通过进程内存空间工具(比如 pmap),分析进程地址空间中内存的使用情况就可以了。
第三个例子,当你通过 vmstat 或者 sar 发现内存在不断增长后,可以分析中是否存在内存泄漏的问题。比如你可以使用内存分配分析工具 memleak ,检查是否存在内存泄漏。如果存在内存泄漏问题,memleak 会为你输出内存泄漏的进程以及调用堆栈。
内存优化的措施:
内存调优最重要的就是,保证应用程序的热点数据放到内存中,并尽量减少换页和交换。常见的优化思路有这么几种。
- 最好禁止 Swap。如果必须开启 Swap,降低 swappiness 的值,减少内存回收时 Swap 的使用倾向。
swappiness的值的大小对如何使用swap分区是有着很大的联系的。swappiness=0的时候表示最大限度使用物理内存,然后才是swap空间,swappiness=100的时候表示积极的使用swap分区,并且把内存上的数据及时的搬运到swap空间里面。linux的基本默认设置为60
- 减少内存的动态分配。比如,可以使用内存池、大页(HugePage)等。
- 尽量使用缓存和缓冲区来访问数据。比如,可以使用堆栈明确声明内存空间,来存储需要缓存的数据;或者用 Redis 这类的外部缓存组件,优化数据的访问。
- 使用 cgroups 等方式限制进程的内存使用情况。这样,可以确保系统内存不会被异常进程耗尽。
- 通过 /proc/pid/oom_adj ,调整核心应用的 oom_score。这样,可以保证即使内存紧张,核心应用也不会被 OOM 杀死。
进程,线程
线程
调用pthread_create创建,创建即运行
fork和exec的区别
fork()是新线程,exec是原来的线程。
对于fork():
1、子进程复制父进程的所有进程内存到其内存地址空间中。父、子进程的
“数据段”,“堆栈段”和“代码段”完全相同,即子进程中的每一个字节都
和父进程一样。
2、子进程的当前工作目录、umask掩码值和父进程相同,fork()之前父进程
打开的文件描述符,在子进程中同样打开,并且都指向相同的文件表项。
3、子进程拥有自己的进程ID。
对于exec():
1、进程调用exec()后,将在同一块进程内存里用一个新程序来代替调用
exec()的那个进程,新程序代替当前进程映像,当前进程的“数据段”,
“堆栈段”和“代码段”背新程序改写。
2、新程序会保持调用exec()进程的ID不变。
3、调用exec()之前打开打开的描述字继续打开(好像有什么参数可以令打开
的描述字在新程序中关闭)
早期操作系统都是单线程,即一个、
进程只有一个线程。目前的操作系统都包含多个线程。如下图为单线程和多线程。
在Linux中,线程只是一种特殊的进程。多个线程之间可以共享内存空间和IO接口。所以,进程是Linux程序的唯一的实现方式。

引入线程的原因
引入线程主要出于三方面因素考虑:性能、应用和硬件。
从性能角度来看,由于进程是重量级的,负载了程序运行中所有的内容,操作系统的开销比较大,另外切换进程需保存现场和恢复现场,消耗也是比较大。所以需要引入一种比进程开销更小的线程单位。
从应用角度来看,进程内的代码也有并行执行的要求。如PPT在编辑(输入、拼写、存盘等操作)的时候,也需要同时进行其他操作(如排版)。
从硬件角度来看,多核处理器是目前主流的硬件架构,为了充分利用多核处理器的性能,加速进程的运行,也是引入线程的重要原因。
Linux进程的5种状态都是啥以及怎样转换
就绪状态和运行状态
就绪状态的状态标志state的值为TASK_RUNNING。此时,程序已被挂入运行队列,处于准备运行状态。一旦获得处理器使用权,即可进入运行状态。
当进程获得处理器而运行时 ,state的值仍然为TASK_RUNNING,并不发生改变;但Linux会把一个专门用来指向当前运行任务的指针current指向它,以表示它是一个正在运行的进程。
可中断等待状态
状态标志state的值为TASK_INTERRUPTIBL。此时,由于进程未获得它所申请的资源而处在等待状态。一旦资源有效或者有唤醒信号,进程会立即结束等待而进入就绪状态。
不可中断等待状态
状态标志state的值为TASK_UNINTERRUPTIBL。此时,进程也处于等待资源状态。一旦资源有效,进程会立即进入就绪状态。这个等待状态与可中断等待状态的区别在于:处于TASK_UNINTERRUPTIBL状态的进程不能被信号量或者中断所唤醒,只有当它申请的资源有效时才能被唤醒。
这个状态被应用在内核中某些场景中,比如当进程需要对磁盘进行读写,而此刻正在DMA中进行着数据到内存的拷贝,如果这时进程休眠被打断(比如强制退出信号)那么很可能会出现问题,所以这时进程就会处于不可被打断的状态下。
停止状态
状态标志state的值为TASK_STOPPED。当进程收到一个SIGSTOP信号后,就由运行状态进入停止状态,当受到一个SIGCONT信号时,又会恢复运行状态。这种状态主要用于程序的调试,又被叫做“暂停状态”、“挂起状态”。
中止状态
状态标志state的值为TASK_DEAD。进程因某种原因而中止运行,进程占有的所有资源将被回收,除了task_struct结构(以及少数资源)以外,并且系统对它不再予以理睬,所以这种状态也叫做“僵死状态”,进程成为僵尸进程。
转换要记住从运行扩散开去的状态。

锁的实现的底层
三个硬件支持的原语
- 测试并设置:它返回old_ptr指向的旧值,同时更新为new的新值。
- 比较并赋值
- 链接的加载和条件式存储指令:条件式存储(store-conditional)指令:只有上一次加载的地址在期间都没有更新时,才会成功
- 获取并增加:原子地返回特定地址的旧值,并且让该值自增一
如何减少自旋:
- yield()让出调度,但是来回切换也低效
- 线程睡眠,并设置线程的等待队列,在解锁时唤醒。(利用了park的原语)
Linux中采用
- Linux提供了futex:调用futex_wait(address, expected)时,如果address处的值等于expected,就会让调线程睡眠。否则,调用立刻返回。调用futex_wake(address)唤醒等待队列中的一个线程。
- 两阶段锁:两阶段锁的第一阶段会先自旋一段时间,希望它可以获取锁。但是,如果第一个自旋阶段没有获得锁,第二阶段调用者会睡眠,直到锁可用。上文的Linux锁就是这种锁,不过只自旋一次;更常见的方式是在循环中自旋固定的次数,然后使用futex睡眠。
底层原语
-
互斥锁
-
条件变量:可以等待某个条件,实现睡眠/唤醒(唤醒是使用信号机制)
- 线程可以使用条件变量(condition variable),来等待一个条件变成真。条件变量是一个显式队列,当某些执行状态(即条件,condition)不满足时,线程可以把自己加入队列,等待(waiting)该条件。另外某个线程,当它改变了上述状态时,就可以唤醒一个或者多个等待线程(通过在该条件上发信号),让它们继续执行。
-
信号量
数据结构的并发性
计数器的实现
- 锁临界区的实现方式
- 局部计数器,超过阈值更新到全局技术器的方式
并发链表的实现
信号量
在Linux下,信号量和线程互斥锁的实现都是通过futex系统调用。
Futex(快速用户区互斥的简称)是一个在Linux上实现锁定和构建高级抽象锁如信号量和POSIX互斥的基本工具。它们第一次出现在内核开发的2.5.7版;其语义在2.5.40固定下来,然后在2.6.x系列稳定版内核中出现。
Futex 是fast userspace mutex的缩写,意思是快速用户空间互斥体。Linux内核把它们作为快速的用户空间的锁和信号量的预制构件提供给开发者。Futex非常基础,借助其自身的优异性能,构建更高级别的锁的抽象,如POSIX互斥体。大多数程序员并不需要直接使用Futex,它一般用来实现像NPTL这样的系统库。
Futex 由一块能够被多个进程共享的内存空间(一个对齐后的整型变量)组成;这个整型变量的值能够通过汇编语言调用CPU提供的原子操作指令来增加或减少,并且一个进程可以等待直到那个值变成正数。Futex 的操作几乎全部在应用程序空间完成;只有当操作结果不一致从而需要仲裁时,才需要进入操作系统内核空间执行。这种机制允许使用 futex 的锁定原语有非常高的执行效率:由于绝大多数的操作并不需要在多个进程之间进行仲裁,所以绝大多数操作都可以在应用程序空间执行,而不需要使用(相对高代价的)内核系统调用。
Futex保存在用户空间的共享内存中,并且通过原子操作进行操作。在大部分情况下,资源不存在争用的情况下,进程或者线程可以立刻获得资源成功,实际上就没有必要调用系统调用,陷入内核了。实际上,futex的作用就在于减少系统调用的次数,来提高系统的性能。
死锁以及避免
-
死锁的四个条件?
【1】互斥条件:资源不能被共享,只能由一个进程使用。
【2】请求与保持条件:已经得到资源的进程可以再次申请新的资源。不主动丢弃资源
【3】非剥夺条件:已经分配的资源不能从相应的进程中被强制地剥夺。
【4】循环等待条件:系统中若干进程组成环路,该环路中每个进程都在等待相邻进程正占用的资源。 -
死锁的避免(银行家算法):系统对进程发出的每一个系统能够满足的资源申请进行动态检查,并根据检查结果决定是否分配资源,如果分配后系统可能发生死锁,则不予分配,否则予以分配。这是一种保证系统不进入死锁状态的动态策略。
-
死锁的预防(破坏死锁产生的4个必要条件来预防死锁):资源的互斥性是固有的
(1)破坏”请求与保持条件“:第一种方法静态分配,即每个进程在开始执行时就申请他所需要的全部资源。第二种是动态分配,即每个进程在申请所需要的资源时他本身不占用系统资源。
(2)破坏“不可剥夺”条件:一个进程不能获得所需要的全部资源时便处于等待状态,等待期间他占有的资源将被隐式的释放重新加入到系统的资源列表中,可以被其他的进程使用,而等待的进程只有重新获得自己原有的资源以及新申请的资源才可以重新启动,执行。
(3)破坏“循环等待”条件:资源有序分配,其基本思想是将系统中的所有资源顺序编号,将紧缺的、稀少的采用较大的编号,在申请资源时必须按照编号的顺序进行,一个进程只有获得较小编号的进程才能申请较大编号的进程。
进程和线程的区别
https://blog.csdn.net/pange1991/article/details/84770181、
- 线程切换地址空间保持不变:即不用切换当前使用的页表。
对于 Linux 来讲,所有的线程都当作进程来实现,因为没有单独为线程定义特定的调度算法,也没有单独为线程定义特定的数据结构(所有的线程或进程的核心数据结构都是 task_struct)。
对于一个进程,相当于是它含有一个线程,就是它自身。对于多线程来说,原本的进程称为主线程,它们在一起组成一个线程组。
进程拥有自己的地址空间,所以每个进程都有自己的页表。而线程却没有,只能和其它线程共享某一个地址空间和同一份页表。
这个区别的 根本原因 是,在进程/线程创建时,因是否拷贝当前进程的地址空间还是共享当前进程的地址空间,而使得指定的参数不同而导致的。
具体地说,进程和线程的创建都是执行 clone 系统调用进行的。而 clone 系统调用会执行 do_fork 内核函数,而它则又会调用 copy_process 内核函数来完成。主要包括如下操作:
- 在调用 copy_process 的过程中,会创建并拷贝当前进程的 task_stuct,同时还会创建属于子进程的 thread_info 结构以及内核栈。
- 此后,会为创建好的 task_stuct 指定一个新的 pid(在 task_struct 结构体中)。
- 然后根据传递给 clone 的参数标志,来选择拷贝还是共享打开的文件,文件系统信息,信号处理函数,进程地址空间等。这就是进程和线程不一样地方的本质所在。
每个进程或线程都有三个数据结构,分别是 struct thread_info, struct task_struct 和 内核栈。
thread_info 对象中存放的进程/线程的基本信息,它和这个进程/线程的内核栈存放在内核空间里的一段 2 倍页长的空间中。其中 thread_info 结构存放在低地址段的末尾,其余空间用作内核栈。内核使用 伙伴系统 为每个进程/线程分配这块空间。
thread_info 结构体中有一个 struct task_struct *task,task 指向的就是这个进程或线程相关的 task_struct 对象(也在内核空间中),这个对象叫做进程描述符(叫做任务描述符更为贴切,因为每个线程也都有自己的 task_struct)。内核使用 slab 分配器为每个进程/线程分配这块空间。(分配到内核空间哦)
slab分配器分配内存以Byte为单位。但是slab分配器并没有脱离伙伴系统,而是基于伙伴系统分配的大内存进一步细分成小内存分配。(见上面)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0LDf1a4r-1599039007492)(http://abcdxyzk.github.io/images/kernel/2018-01-10-1.png)]
总结:进程VS 线程
- 进程采用fork创建,线程采用clone创建
- 进程fork创建的子进程的逻辑流位置在fork返回的位置,线程clone创建的KSE的逻辑流位置在clone调用传入的方法位置,比如Java的Thread的run方法位置
- 进程拥有独立的虚拟内存地址空间和内核数据结构(页表,打开文件表等),当子进程修改了虚拟页之后,会通过写时拷贝创建真正的物理页。线程共享进程的虚拟地址空间和内核数据结构,共享同样的物理页
- 多个进程通信只能采用进程间通信的方式,比如信号,管道,而不能直接采用简单的共享内存方式,原因是每个进程维护独立的虚拟内存空间,所以每个进程的变量采用的虚拟地址是不同的。多个线程通信就很简单,直接采用共享内存的方式,因为不同线程共享一个虚拟内存地址空间,变量寻址采用同一个虚拟内存
- 进程上下文切换需要切换页表等重量级资源,线程上下文切换只需要切换寄存器等轻量级数据
- 进程的用户栈独享栈空间,线程的用户栈共享虚拟内存中的栈空间,没有进程高效,线程独享内核栈
- 一个应用程序可以有多个进程,执行多个程序代码,多个线程只能执行一个程序代码,共享进程的代码段
- 进程采用父子结构,线程采用对等结构
进程与线程的对应关系
https://www.jianshu.com/p/aedb25f9ca37
- 用户线程的调度,是在用户进程中调度,内核不参与调度。
- 内核线程调度需要内核参与
进程打开的文件资源有哪些
操作操作系统用了3个数据结构来为每个进程管理它打开的文件资源
- 描述符表
- 打开文件表
- v-node
 -
-
什么是PCB?包含哪些信息
https://blog.csdn.net/qq_38410730/article/details/81173170

注意区分下图的虚拟内存,这是进程
PCB前后指针连接,然后放在相应事件的队列中,进程调度器进行调度。

进程控制块包含三类信息
1.标识信息。
用于唯一地标识一个进程,常常分由用户使用的外部标识符和被系统使用的内部标识号。几乎所有操作系统中进程都被赋予一个唯一的、内部使用的数值型的进程号,操作系统的其他控制表可以通过进程号来交叉引用进程控制表。常用的标识信息包括进程标识符、父进程的标识符、用户进程名、用户组名等。
2.现场信息。
用于保留一个进程在运行时存放在处理器现场中的各种信息,任何一个进程在让出处理器时必须把此时的处理器现场信息保存到进程控制块中,而当该进程重新恢复运行时也应恢复处理器现场。常用的现场信息包括通用寄存器的内容、控制寄存器(如PSW寄存器)的内容、用户堆战指针、系统堆饺指针等。
3.进程控制信息。
用于管理和调度一个进程。常用的控制信息包括:
l)进程的调度相关信息,如进程状态、等待事件和等待原因、进程优先级、队列指引元等
2)进程组成信息,如正文段指针、数据段指针
3)引进程间通信相关信息,如消息队列指针、信号量等互斥和同步机制
4)进程在辅存储器内的地址
5)CPU资源的占用和使用信息,如时间片余量、进程己占用CPU的时间、进程己执行的时间总和,记账信息
6)进程特权信息,如在内存访问和处理器状态方面的特权…
————————————————
版权声明:本文为CSDN博主「斜阳雨陌」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_15037231/article/details/55046945
PCB是进程存在的唯一标志。 Linux 系统中用task_struct 数据结构来描述每个进程的进程控制块
即内核为每个进程在内核自己的空间中分配一个变量(task_struct结构体)以保存上述信息。内核可以通过查看自己空间中的各个进程的附加信息就能知道进程的概况,而不用进入到进程自身的空间
PCB中包括:
-
进程标识符:(用于标识)
进程标识符用于惟一地标识一个进程。一个进程通常有外部标识符和内部标识符两种,分别用来方便用户对进程的访问和系统对进程的访问。
内部标识符。在所有的操作系统中,都为每一个进程赋予了一个惟一的数字标识符,它通常是一个进程的序号。
外部标识符。它由创建者提供,通常是由字母、数字组成,往往是由用户(进程)在访问该进程时使用。 -
处理机状态:(存数据)
处理机状态信息主要是由处理机的各种寄存器中的内容组成的。处理机在运行时,许多信息都放在寄存器中。当处理机被中断时,所有这些信息都必须保存在 PCB 中,以便在该进程重新执行时,能从断点继续执行。这些寄存器包括:
① 通用寄存器,又称为用户可视寄存器,它们是用户程序可以访问的,用于暂存信息,在大多数处理机中,有 8~32 个通用寄存器,在 RISC 结构的计算机中可超过 100 个;
② 指令计数器,其中存放了要访问的下一条指令的地址;
③ 程序状态字 PSW,其中含有状态信息,如条件码、执行方式、中断屏蔽标志等;
④ 用户栈指针,指每个用户进程都有一个或若干个与之相关的系统栈,用于存放过程和系统调用参数及调用地址,栈指针指向该栈的栈顶。 -
进程调度信息:(用于调度)
在 PCB 中还存放一些与进程调度和进程对换有关的信息,包括:
① 进程状态,指明进程的当前状态,作为进程调度和对换时的依据;
② 进程优先级,用于描述进程使用处理机的优先级别的一个整数,优先级高的进程应优先获得处理机;
③ 进程调度所需的其它信息,它们与所采用的进程调度算法有关,比如,进程已等待 CPU 的时间总和、进程已执行的时间总和等;
④ 事件,指进程由执行状态转变为阻塞状态所等待发生的事件,即阻塞原因。 -
进程控制信息:(用于继续执行)
① 程序和数据的地址,指进程的程序和数据所在的内存或外存地(首)址,以便再调度到该进程执行时,能从 PCB 中找到其程序和数据;
② 进程同步和通信机制,指实现进程同步和进程通信时必需的机制,如消息队列指针、信号量等,它们可能全部或部分地放在 PCB 中;
③ 资源清单,即一张列出了除 CPU 以外的、进程所需的全部资源及已经分配到该进程的资源的清单;
④ 链接指针,它给出了本进程(PCB)所在队列中的下一个进程的 PCB 的首地址。
PCB的组织方式:
链接方式:这是把具有同一状态的 PCB,用其中的链接字链接成一个队列。这样,可以形成就绪队列、若干个阻塞队列和空白队列等。对其中的就绪队列常按进程优先级的高低排列,把优先级高的进程的 PCB 排在队列前面。此外,也可根据阻塞原因的不同而把处于阻塞状态的进程的 PCB 排成等待 I/O 操作完成的队列和等待分配内存的队列等。
TCB
线程控制块(Thread ControlBlock,TCB),保存每个线程的状态。但是,与进程相比,线程之间的上下文切换有一点主要区别:地址空间保持不变(即不需要切换当前使用的页表)。
讲讲僵尸进程和孤儿进程
关键词:调用wait
当子进程终结时,它会通知父进程,并清空自己所占据的内存,并在内核里留下自己的退出信息(exit code,如果顺利运行,为0;如果有错误或异常状况,为>0的整数)。在这个信息里,会解释该进程为什么退出。父进程在得知子进程终结时,有责任对该子进程使用wait系统调用。这个wait函数能从内核中取出子进程的退出信息,并清空该信息在内核中所占据的空间。但是,如果父进程早于子进程终结,子进程就会成为一个孤儿(orphand)进程。孤儿进程会被过继给init进程,init进程也就成了该进程的父进程。init进程负责该子进程终结时调用wait函数。
当然,一个糟糕的程序也完全可能造成子进程的退出信息滞留在内核中的状况(父进程不对子进程调用wait函数),这样的情况下,子进程成为僵尸(zombie)进程。当大量僵尸进程积累时,内存空间会被挤占。
进程空间全解析
https://blog.csdn.net/zhangzhebjut/article/details/39060253
http://abcdxyzk.github.io/blog/2018/01/10/kernel-task-thread/
https://www.cnblogs.com/sparkdev/p/8410350.html
看看本节的子标题已经十分迷惑了,不同的叫法完全是从不同的角度来考虑的。
内核和用户,“态”的不同,指进程执行不同指令进入了不同的特权级别;“空间”的不同,指的是地址空间的划分。又因为指令又存在内存里,所以两者有联系。
简单区分:
- 用户态和内核态
每个进程空间按照如下方式分为不同区域:

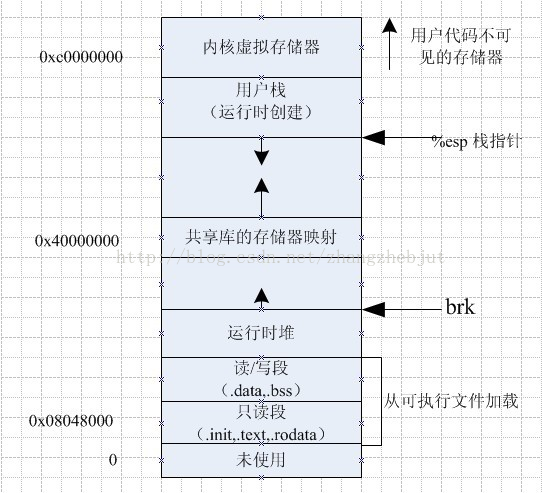
Text区域用来储存指令(instruction),说明每一步的操作。Global Data用于存放全局变量,栈(Stack)用于存放局部变量,堆(heap)用于存放动态变量 (dynamic variable. 程序利用malloc系统调用,直接从内存中为dynamic variable开辟空间)。Text和Global data在进程一开始的时候就确定了,并在整个进程中保持固定大小。
除了上面的信息之外,每个进程还要包括一些进程附加信息,包括PID,PPID,PGID(参考Linux进程基础以及Linux进程关系)等,用来说明进程的身份、进程关系以及其它统计信息。这些信息并不保存在进程的内存空间中。**内核会为每个进程在内核自己的空间中分配一个变量(task_struct结构体)以保存上述信息。**内核可以通过查看自己空间中的各个进程的附加信息就能知道进程的概况,而不用进入到进程自身的空间 (就好像我们可以通过门牌就可以知道房间的主人是谁一样,而不用打开房门)。每个进程的附加信息中有位置专门用于保存接收到的信号(正如我们在Linux信号基础中所说的“信箱”)。
- task_struct是存在内核中的
用户态和内核态
见下面
内核线程和用户进程
(后者叫做普通进程更好)
- 普通进程可以处于用户态,内核态
- 内核进程(叫线程更贴切)只能处于内核态,用户空间的页表mm为null。
普通进程:
**当一个任务(普通进程)执行系统调用而陷入内核代码中执行时,我们就称进程处于内核运行态(或简称为内核态)**。**当进程运行在内核空间时就处于内核态,而进程运行在用户空间时则处于用户态。**
有三种陷入的方式
-
系统调用
-
软中断
-
硬件中断
此时处理器处于特权级最高的(0级)内核代码中执行。当进程处于内核态时,执行的内核代码会使用当前进程的内核栈。
每个进程都有自己的内核栈。
当进程在执行用户自己的代码时,则称其处于用户运行态(用户态)。即此时处理器在特权级最低的(3级)用户代码中运行。
内核线程:
实际上我们可以将每个处理器在任何指定时间点上的活动概括为下列三者之一:
- 运行于用户空间,执行用户进程。
- 运行于内核空间,处于进程上下文,代表某个特定的进程执行。
- 运行于内核空间,处于中断上下文,与任何进程无关,处理某个特定的中断。
第三个就是运行在内核线程,由于一般线的最大的特征是一组线程共享页表,也就是虚拟空间,而内核线程显然只共享内核空间,进程空间是null,所以更像是线程而不是进程。
普通线程虽然也是同主线程共享地址空间,但是它的 task_struct 对象中的 mm 不为空,指向的是主线程的 mm_struct 对象。
(普通)线程:
见前面进程与线程的区别
注意一点:线程独享内核栈空间。
内核空间和用户空间
-
每个进程空间的0-3G的空间是用户进程独有,称为用户空间,3 - 4G空间是内核空间,所有进程共有。即:
内核空间是一样的,用户空间各有各的不同 ---------熄而斯泰。
内核空间中存放的是内核代码和数据,而进程的用户空间中存放的是用户程序的代码和数据。不管是内核空间还是用户空间,它们都处于虚拟空间中。 虽然内核空间占据了每个虚拟空间中的最高1GB字节,但映射到物理内存却总是从最低地址(0x00000000),另外,使用虚拟地址可以很好的保护内核空间被用户空间破坏,虚拟地址到物理地址转换过程有操作系统和CPU共同完成(操作系统为CPU设置好页表,CPU通过MMU单元进行地址转换)。
-
内核空间在页表中拥有较高的特权级(ring2或以下),因此只要用户态的程序试图访问这些页,就会导致一个页错误(page fault)。在Linux中,内核空间是持续存在的,并且在所有进程中都映射到同样的物理内存,内核代码和数据总是可寻址的,随时准备处理中断和系统调用。与之相反,用户模式地址空间的映射随着进程切换的发生而不断的变化
内核栈和用户栈区别
链接:https://www.jianshu.com/p/6b2ec520ae02
链接:https://www.zhihu.com/question/57013926/answer/151506606
内核在创建进程时,会同时创建task_struct和进程相应堆栈。每个进程都会有两个栈,一个用户栈,存在于用户空间,一个内核栈,存在于内核空间。当进程在用户空间运行时,CPU堆栈寄存器的内容是用户堆栈地址,使用用户栈。当进程在内核空间时,CPU堆栈寄存器的内容是内核栈地址空间,使用的是内核栈。
当进程因为中断或系统调用进入内核时,进程使用的堆栈也需要从用户栈到内核栈。进程陷入内核态后,先把用户堆栈的地址保存到内核堆栈中,然后设置设置CPU堆栈寄存器为内核栈的地址,这样就完成了用户栈到内核栈的转换。
当进程从内核态恢复到用户态时,把内核中保存的用户态堆栈的地址恢复到堆栈指针寄存器即可。这样就实现了内核栈到用户栈的转换。
注意:陷入内核栈时,如何知道内核栈的地址呢?
进程由用户栈到内核栈转换时,进程的内核栈总是空的。每次从用户态陷入内核时,得到的内核栈都是空的,所以在进程陷入内核时,直接把内核栈顶地址给堆栈指针寄存器即可。
详解
**当创建一个进程时:**创建内核栈、thread_info 和 task_struct:
thread_info 含有task_struct,task_struct含有内核栈地址stack。stack又 指向了thread_info。
真是盖了帽了,我的linux。
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
void *stack;
atomic_t usage;
unsigned int flags; /* per process flags, defined below */
unsigned int ptrace;
int lock_depth; /* BKL lock depth */
/* ...... */
};
Linux 通过
clone()系统调用实现fork(),然后由fork()去调用do_fork()。定义在<kernel/fork.c>中的do_fork()负责完成进程创建的大部分工作,它通过调用copy_process()函数,然后让进程运行起来。copy_process()完成了许多工作,这里重点看内核栈相关部分。copy_process()调用dup_task_struct来创建内核栈、thread_info和task_struct:
内核栈是什么?在task_struct里的一个数据结构 在上下文切换的时候,操作系统的调度器进行切换时,将即将运行的线程的寄存器从内核栈中回复,将上一个的寄存器存到内存栈中

作者:向晨
链接:https://www.zhihu.com/question/57013926/answer/151306072
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
进程间的通信
信号
信号的面试题
如何发送信号
使用kill,比如:
kill -SIGCONT 27397
常见的信号
SIGINT 当键盘按下CTRL+C从shell中发出信号,信号被传递给shell中前台运行的进程,对应该信号的默认操作是中断 (INTERRUPT) 该进程。
SIGQUIT 当键盘按下CTRL+\从shell中发出信号,信号被传递给shell中前台运行的进程,对应该信号的默认操作是退出 (QUIT) 该进程。
SIGTSTP 当键盘按下CTRL+Z从shell中发出信号,信号被传递给shell中前台运行的进程,对应该信号的默认操作是暂停 (STOP) 该进程。
SIGCONT 用于通知暂停的进程继续。
SIGALRM 起到定时器的作用,通常是程序在一定的时间之后才生成该信号。
IO篇
工具
1.用iostat看磁盘的await,utils,iops,bandwidth
2.用smartctl看磁盘的health status
3.用iotop/pidstat找出持续读写的进程做优化
4.测试工具 fio ,来测试磁盘的 IOPS、吞吐量以及响应时间等核心指标。
本节详细介绍
https://time.geekbang.org/column/article/76876
文件系统的原理是啥
要点:
- inode同样占用磁盘空间,并且会存在页缓存cache中。
含义
- 磁盘为系统提供了最基本的持久化存储。
- 文件系统则在磁盘的基础上,提供了一个用来管理文件的树状结构。
文件系统,本身是对存储设备上的文件,进行组织管理的机制。组织方式不同,就会形成不同的文件系统。
在 Linux 中一切皆文件。不仅普通的文件和目录,就连块设备、套接字、管道等,也都要通过统一的文件系统来管理。为了方便管理,Linux 文件系统为每个文件都分配两个数据结构,索引节点(index node)和目录项(directory entry)。它们主要用来记录文件的元信息和目录结构。
- 索引节点,简称为 inode,用来记录文件的元数据,比如 inode 编号、文件大小、访问权限、修改日期、数据的位置等。索引节点和文件一一对应,它跟文件内容一样,都会被持久化存储到磁盘中。所以记住,索引节点同样占用磁盘空间。
- 目录项,简称为 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的关联关系。多个关联的目录项,就构成了文件系统的目录结构。不过,不同于索引节点,目录项是由内核维护的一个内存数据结构,所以通常也被叫做目录项缓存。
磁盘在执行文件系统格式化时,会被分成三个存储区域,超级块、索引节点区和数据块区。其中,超级块,存储整个文件系统的状态。索引节点区,用来存储索引节点。数据块区,则用来存储文件数据。
磁盘在执行文件系统格式化时,会被分成三个存储区域,超级块、索引节点区和数据块区。其中,
- 超级块,存储整个文件系统的状态。
- 索引节点区,用来存储索引节点。
- 数据块区,则用来存储文件数据。
虚拟文件系统
目录项、索引节点、逻辑块以及超级块,构成了 Linux 文件系统的四大基本要素。不过,为了支持各种不同的文件系统,Linux 内核在用户进程和文件系统的中间,又引入了一个抽象层,也就是虚拟文件系统 VFS(Virtual File System)。
(真实与虚拟解耦,接口调用,分层的思想)
VFS 定义了一组所有文件系统都支持的数据结构和标准接口。这样,用户进程和内核中的其他子系统,只需要跟 VFS 提供的统一接口进行交互就可以了,而不需要再关心底层各种文件系统的实现细节。
在 VFS 的下方,Linux 支持各种各样的文件系统,如 Ext4、XFS、NFS 等等。按照存储位置的不同,这些文件系统可以分为三类。(通俗点讲:不是所有的目录下文件都存在磁盘中的,但是受文件系统管理)
- 第一类是基于磁盘的文件系统,也就是把数据直接存储在计算机本地挂载的磁盘中。常见的 Ext4、XFS、OverlayFS 等,都是这类文件系统。
- 第二类是**基于内存的文件系统,也就是我们常说的虚拟文件系统。**这类文件系统,不需要任何磁盘分配存储空间,但会占用内存。我们经常用到的 /proc 文件系统,其实就是一种最常见的虚拟文件系统。此外,/sys 文件系统也属于这一类,主要向用户空间导出层次化的内核对象。
- 第三类是网络文件系统,也就是用来访问其他计算机数据的文件系统,比如 NFS、SMB、iSCSI 等。
这些文件系统,要先挂载到 VFS 目录树中的某个子目录(称为挂载点),然后才能访问其中的文件。拿第一类,也就是基于磁盘的文件系统为例,在安装系统时,要先挂载一个根目录(/),在根目录下再把其他文件系统(比如其他的磁盘分区、/proc 文件系统、/sys 文件系统、NFS 等)挂载进来。文件系统 I/O
文件系统 I/O
文件读写方式的各种差异,导致 I/O 的分类多种多样。最常见的有,缓冲与非缓冲 I/O、直接与非直接 I/O、阻塞与非阻塞 I/O、同步与异步 I/O 等。 接下来,我们就详细看这四种分类。
第一种,根据是否利用标准库缓存,可以把文件 I/O 分为缓冲 I/O 与非缓冲 I/O。缓冲 I/O,是指利用标准库缓存来加速文件的访问,而标准库内部再通过系统调度访问文件。非缓冲 I/O,是指直接通过系统调用来访问文件,不再经过标准库缓存。注意,这里所说的“缓冲”,是指标准库内部实现的缓存。比方说,你可能见到过,很多程序遇到换行时才真正输出,而换行前的内容,其实就是被标准库暂时缓存了起来。无论缓冲 I/O 还是非缓冲 I/O,它们最终还是要经过系统调用来访问文件。而根据上一节内容,我们知道,系统调用后,还会通过页缓存,来减少磁盘的 I/O 操作。
第二种,根据是否利用操作系统的页缓存,可以把文件 I/O 分为直接 I/O 与非直接 I/O。
- 直接 I/O,是指跳过操作系统的页缓存,直接跟文件系统交互来访问文件。
- 非直接 I/O 正好相反,文件读写时,先要经过系统的页缓存,然后再由内核或额外的系统调用,真正写入磁盘。想要实现直接 I/O,需要你在系统
在Linux 2.4内核中块缓存buffer cache和页缓存page cache是并存的,表现的现象是同一份文件的数据,可能即出现在buffer cache中,又出现在页缓存中,这样就造成了物理内存的浪费。Linux 2.6内核对两个cache进行了合并,统一使用页缓存在做缓存,只有极少数的情况下才使用到buffer cache。
第三种,根据应用程序是否阻塞自身运行,可以把文件 I/O 分为阻塞 I/O 和非阻塞 I/O:
- 所谓阻塞 I/O,是指应用程序执行 I/O 操作后,如果没有获得响应,就会阻塞当前线程,自然就不能执行其他任务。
- 所谓非阻塞 I/O,是指应用程序执行 I/O 操作后,不会阻塞当前的线程,可以继续执行其他的任务,随后再通过轮询或者事件通知的形式,获取调用的结果。比方说,访问管道或者网络套接字时,设置 O_NONBLOCK 标志,就表示用非阻塞方式访问;而如果不做任何设置,默认的就是阻塞访问。
第四种,根据是否等待响应结果,可以把文件 I/O 分为同步和异步 I/O:
- 所谓同步 I/O,是指应用程序执行 I/O 操作后,要一直等到整个 I/O 完成后,才能获得 I/O 响应。
- 所谓异步 I/O,是指应用程序执行 I/O 操作后,不用等待完成和完成后的响应,而是继续执行就可以。等到这次 I/O 完成后,响应会用事件通知的方式,告诉应用程序。
举个例子,在操作文件时,如果你设置了 O_SYNC 或者 O_DSYNC 标志,就代表同步 I/O。如果设置了 O_DSYNC,就要等文件数据写入磁盘后,才能返回;而 O_SYNC,则是在 O_DSYNC 基础上,要求文件元数据也要写入磁盘后,才能返回。再比如,在访问管道或者网络套接字时,设置了 O_ASYNC 选项后,相应的 I/O 就是异步 I/O。这样,内核会再通过 SIGIO 或者 SIGPOLL,来通知进程文件是否可读写。
你也应该可以理解,“Linux 一切皆文件”的深刻含义。无论是普通文件和块设备、还是网络套接字和管道等,它们都通过统一的 VFS 接口来访问。性能观测
Linux 磁盘I/O是怎么工作的
文件系统是对存储设备上的文件,进行组织管理的一种机制。而 Linux 在各种文件系统实现上,又抽象了一层虚拟文件系统 VFS,它定义了一组,所有文件系统都支持的,数据结构和标准接口。
这样,对应用程序来说,只需要跟 VFS 提供的统一接口交互,而不需要关注文件系统的具体实现;对具体的文件系统来说,只需要按照 VFS 的标准,就可以无缝支持各种应用程序。VFS 内部又通过目录项、索引节点、逻辑块以及超级块等数据结构,来管理文件。
- 目录项,记录了文件的名字,以及文件与其他目录项之间的目录关系。
- 索引节点,记录了文件的元数据。
- 逻辑块,是由连续磁盘扇区构成的最小读写单元,用来存储文件数据。
- 超级块,用来记录文件系统整体的状态,如索引节点和逻辑块的使用情况等。
其中,目录项是一个内存缓存;而超级块、索引节点和逻辑块,都是存储在磁盘中的持久化数据。
磁盘性能指标
磁盘和文件区分
我们通常说的“文件”,其实是指普通文件。而磁盘或者分区,则是指块设备文件。
磁盘是存储数据的块设备,也是文件系统的载体。所以,文件系统确实还是要通过磁盘,来保证数据的持久化存储。
在读写普通文件时,I/O 请求会首先经过文件系统,然后由文件系统负责,来与磁盘进行交互。而在读写块设备文件时,会跳过文件系统,直接与磁盘交互,也就是所谓的“裸 I/O”。这两种读写方式使用的缓存自然不同。文件系统管理的缓存,其实就是 Cache 的一部分。而裸磁盘的缓存,用的正是 Buffer。
磁盘
机械磁盘的最小读写单位是扇区,一般大小为 512 字节。
固态磁盘的最小读写单位是页,通常大小是 4KB、8KB 等。
架构
- 就是直接作为独立磁盘设备来使用。这些磁盘,往往还会根据需要,划分为不同的逻辑分区,每个分区再用数字编号。比如我们前面多次用到的 /dev/sda ,还可以分成两个分区 /dev/sda1 和 /dev/sda2。
- 另一个比较常用的架构,是把多块磁盘组合成一个逻辑磁盘,构成冗余独立磁盘阵列,也就是 RAID(Redundant Array of Independent Disks),从而可以提高数据访问的性能,并且增强数据存储的可靠性。
- 最后一种架构,是把这些磁盘组合成一个网络存储集群,再通过 NFS、SMB、iSCSI 等网络存储协议,暴露给服务器使用。
其实在 Linux 中,磁盘实际上是作为一个块设备来管理的,也就是以块为单位读写数据,并且支持随机读写。每个块设备都会被赋予两个设备号,分别是主、次设备号。主设备号用在驱动程序中,用来区分设备类型;而次设备号则是用来给多个同类设备编号。
通用块层
(又是抽象层的思想)
跟虚拟文件系统 VFS 类似,为了减小不同块设备的差异带来的影响,Linux 通过一个统一的通用块层,来管理各种不同的块设备。
通用块层,其实是处在文件系统和磁盘驱动中间的一个块设备抽象层。它主要有两个功能 。
- 第一个功能跟虚拟文件系统的功能类似。向上,为文件系统和应用程序,提供访问块设备的标准接口;向下,把各种异构的磁盘设备抽象为统一的块设备,并提供统一框架来管理这些设备的驱动程序。
- 第二个功能,通用块层还会给文件系统和应用程序发来的 I/O 请求排队,并通过重新排序、请求合并等方式,提高磁盘读写的效率。
I/O 调度
-
第一种 NONE ,更确切来说,并不能算 I/O 调度算法。因为它完全不使用任何 I/O 调度器,对文件系统和应用程序的 I/O 其实不做任何处理,常用在虚拟机中(此时磁盘 I/O 调度完全由物理机负责)。
-
第二种 NOOP ,是最简单的一种 I/O 调度算法。它实际上是一个先入先出的队列,只做一些最基本的请求合并,常用于 SSD 磁盘。第三种 CFQ(Completely Fair Scheduler),也被称为完全公平调度器,是现在很多发行版的默认 I/O 调度器,它为每个进程维护了一个 I/O 调度队列,并按照时间片来均匀分布每个进程的 I/O 请求。类似于进程 CPU 调度,CFQ 还支持进程 I/O 的优先级调度,所以它适用于运行大量进程的系统,像是桌面环境、多媒体应用等。最后一种 DeadLine 调度算法,分别为读、写请求创建了不同的 I/O 队列,可以提高机械磁盘的吞吐量,并确保达到最终期限(deadline)的请求被优先处理。DeadLine 调度算法,多用在 I/O 压力比较重的场景,比如数据库等。
I/O 栈
可以把 Linux 存储系统的 I/O 栈,由上到下分为三个层次,分别是文件系统层、通用块层和设备层。这三个 I/O 层的关系如下图所示,这其实也是 Linux 存储系统的 I/O 栈全景图。
- 文件系统层,包括虚拟文件系统和其他各种文件系统的具体实现。它为上层的应用程序,提供标准的文件访问接口;对下会通过通用块层,来存储和管理磁盘数据。
- 通用块层,包括块设备 I/O 队列和 I/O 调度器。它会对文件系统的 I/O 请求进行排队,再通过重新排序和请求合并,然后才要发送给下一级的设备层。
- 设备层,包括存储设备和相应的驱动程序,负责最终物理设备的 I/O 操作。
针对各个层的缓冲:
- 为了优化文件访问的性能,会使用页缓存、索引节点缓存、目录项缓存等多种缓存机制,以减少对下层块设备的直接调用。
- 为了优化块设备的访问效率,会使用缓冲区,来缓存块设备的数据。
磁盘性能指标
说到磁盘性能的衡量标准,必须要提到五个常见指标,也就是我们经常用到的,使用率、饱和度、IOPS、吞吐量以及响应时间等。这五个指标,是衡量磁盘性能的基本指标。
- 使用率,是指磁盘处理 I/O 的时间百分比。过高的使用率(比如超过 80%),通常意味着磁盘 I/O 存在性能瓶颈。
- 饱和度,是指磁盘处理 I/O 的繁忙程度。过高的饱和度,意味着磁盘存在严重的性能瓶颈。当饱和度为 100% 时,磁盘无法接受新的 I/O 请求。
- IOPS(Input/Output Per Second),是指每秒的 I/O 请求数。
- 吞吐量,是指每秒的 I/O 请求大小。
- 响应时间,是指 I/O 请求从发出到收到响应的间隔时间。
测试工具 fio ,来测试磁盘的 IOPS、吞吐量以及响应时间等核心指标。
iostat 是最常用的磁盘 I/O 性能观测工具,它提供了每个磁盘的使用率、IOPS、吞吐量等各种常见的性能指标,当然,这些指标实际上来自 /proc/diskstats。
# -d -x表示显示所有磁盘I/O的指标
$ iostat -d -x 1
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
loop1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
pidstat 加上 -d 参数,你就可以看到进程的 I/O 情况,如下所示:
用户 ID(UID)和进程 ID(PID) 。
每秒读取的数据大小(kB_rd/s) ,单位是 KB。
每秒发出的写请求数据大小(kB_wr/s) ,单位是 KB。
每秒取消的写请求数据大小(kB_ccwr/s) ,单位是 KB。
块 I/O 延迟(iodelay),包括等待同步块 I/O 和换入块 I/O 结束的时间,单位是时钟周期。
iotop。它是一个类似于 top 的工具,你可以按照 I/O 大小对进程排序,然后找到 I/O 较大的那些进程。
$ iotop
Total DISK READ : 0.00 B/s | Total DISK WRITE : 7.85 K/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
15055 be/3 root 0.00 B/s 7.85 K/s 0.00 % 0.00 % systemd-journald
从这个输出,你可以看到,前两行分别表示,进程的磁盘读写大小总数和磁盘真实的读写大小总数。因为缓存、缓冲区、I/O 合并等因素的影响,它们可能并不相等。
排查案例
案例篇:如何找出狂打日志的“内鬼”?
先是top看%iowait到升高,iostat -d 查看磁盘的具体使用情况。 再看pidstat是哪个进程在操作磁盘,再strace看进程的调用栈(系统调用)。用lsof 来定位应用程序以及它正在写入的日志文件路径。可以看到某个进程的写调用不合理,原因是生产时日志级别没调,
看/proc/meminfo就可以看到系统的buffer和cache各占了多少吧。前后一对比就知道是谁了。
案例篇:为什么我的磁盘I/O延迟很高?
步骤和前面一样,但是但 strace 跟踪这个进程,却没有找到任何 write 系统调用。
写文件是由子线程执行的,所以直接strace跟踪进程没有看到write系统调用,可以通过pstree查看进程的线程信息,再用strace跟踪。或者,通过strace -fp pid 跟踪所有线程。,多进程和多线程都可以跟踪。
使用以个新的工具: filetop。它是 bcc 软件包的一部分,基于 Linux 内核的 eBPF(extended Berkeley Packet Filters)机制,主要跟踪内核中文件的读写情况,并输出线程 ID(TID)、读写大小、读写类型以及文件名称。
# 切换到工具目录
$ cd /usr/share/bcc/tools
# -C 选项表示输出新内容时不清空屏幕
$ ./filetop -C
TID COMM READS WRITES R_Kb W_Kb T FILE
514 python 0 1 0 2832 R 669.txt
514 python 0 1 0 2490 R 667.txt
514 python 0 1 0 2685 R 671.txt
514 python 0 1 0 2392 R 670.txt
514 python 0 1 0 2050 R 672.txt
...
TID COMM READS WRITES R_Kb W_Kb T FILE
514 python 2 0 5957 0 R 651.txt
514 python 2 0 5371 0 R 112.txt
514 python 2 0 4785 0 R 861.txt
514 python 2 0 4736 0 R 213.txt
514 python 2 0 4443 0 R 45.txt
再介绍一个好用的工具,opensnoop 。它同属于 bcc 软件包,可以动态跟踪内核中的 open 系统调用。这样,我们就可以找出这些 txt 文件的路径。
pidstat -wut 1既可以看上下文切换 又可以看cpu使用统计 还可以看各线程.
案例篇:一个SQL查询要15秒,这是怎么回事?
观察 top 的输出,我们发现,两个 CPU 的 iowait 都比较高,特别是 CPU0,iowait 已经超过 60%。而具体到各个进程, CPU 使用率并不高,最高的也只有 1.7%。
在 SHELL 中,特殊标量 $? 表示上一条命令退出时的返回值。
案例篇:Redis响应严重延迟,如何解决?
-
pidstat -d 1 观察io状况,定位PID 为 9085
$ pidstat -d 1 12:49:35 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 12:49:36 0 368 0.00 16.00 0.00 86 jbd2/sda1-8 12:49:36 100 9085 0.00 636.00 0.00 1 redis-server -
strace -f -T -tt -p 9085 查看系统调用
可以看到: epoll_pwait、read、write、fdatasync 这些系统调用都比较频繁。那么,刚才观察到的写磁盘,应该就是 write 或者 fdatasync 导致的了。
# -f表示跟踪子进程和子线程,-T表示显示系统调用的时长,-tt表示显示跟踪时间 $ strace -f -T -tt -p 9085 [pid 9085] 14:20:16.826131 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 65, NULL, 8) = 1 <0.000055> [pid 9085] 14:20:16.826301 read(8, "*2\r\n$3\r\nGET\r\n$41\r\nuuid:5b2e76cc-"..., 16384) = 61 <0.000071> [pid 9085] 14:20:16.826477 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000063> [pid 9085] 14:20:16.826645 write(8, "$3\r\nbad\r\n", 9) = 9 <0.000173> [pid 9085] 14:20:16.826907 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 65, NULL, 8) = 1 <0.000032> [pid 9085] 14:20:16.827030 read(8, "*2\r\n$3\r\nGET\r\n$41\r\nuuid:55862ada-"..., 16384) = 61 <0.000044> [pid 9085] 14:20:16.827149 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000043> [pid 9085] 14:20:16.827285 write(8, "$3\r\nbad\r\n", 9) = 9 <0.000141> [pid 9085] 14:20:16.827514 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 64, NULL, 8) = 1 <0.000049> [pid 9085] 14:20:16.827641 read(8, "*2\r\n$3\r\nGET\r\n$41\r\nuuid:53522908-"..., 16384) = 61 <0.000043> [pid 9085] 14:20:16.827784 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000034> [pid 9085] 14:20:16.827945 write(8, "$4\r\ngood\r\n", 10) = 10 <0.000288> [pid 9085] 14:20:16.828339 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 63, NULL, 8) = 1 <0.000057> [pid 9085] 14:20:16.828486 read(8, "*3\r\n$4\r\nSADD\r\n$4\r\ngood\r\n$36\r\n535"..., 16384) = 67 <0.000040> [pid 9085] 14:20:16.828623 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000052> [pid 9085] 14:20:16.828760 write(7, "*3\r\n$4\r\nSADD\r\n$4\r\ngood\r\n$36\r\n535"..., 67) = 67 <0.000060> [pid 9085] 14:20:16.828970 fdatasync(7) = 0 <0.005415> [pid 9085] 14:20:16.834493 write(8, ":1\r\n", 4) = 4 <0.000250> -
再来运行 lsof 命令,找出这些系统调用的操作对象:
$ lsof -p 9085 redis-ser 9085 systemd-network 3r FIFO 0,12 0t0 15447970 pipe redis-ser 9085 systemd-network 4w FIFO 0,12 0t0 15447970 pipe redis-ser 9085 systemd-network 5u a_inode 0,13 0 10179 [eventpoll] redis-ser 9085 systemd-network 6u sock 0,9 0t0 15447972 protocol: TCP redis-ser 9085 systemd-network 7w REG 8,1 8830146 2838532 /data/appendonly.aof redis-ser 9085 systemd-network 8u sock 0,9 0t0 15448709 protocol: TCP描述符编号为 3 的是一个 pipe 管道,5 号是 eventpoll,7 号是一个普通文件,而 8 号是一个 TCP socket。7号的写路径为/data/appendonly.aof。可知是日志问题。
-
查看redis的持久化配置:appendfsync 配置的是 always,而 appendonly 配置的是 yes。
- always 表示,每个操作都会执行一次 fsync,是最为安全的方式;
- everysec 表示,每秒钟调用一次 fsync ,这样可以保证即使是最坏情况下,也只丢失 1 秒的数据;
- 而 no 表示交给操作系统来处理。
$ docker exec -it redis redis-cli config get 'append*' 1) "appendfsync" 2) "always" 3) "appendonly" 4) "yes"Redis 提供了两种数据持久化的方式,分别是快照和追加文件。
- 快照方式,会按照指定的时间间隔,生成数据的快照,并且保存到磁盘文件中。为了避免阻塞主进程,Redis 还会 fork 出一个子进程,来负责快照的保存。这种方式的性能好,无论是备份还是恢复,都比追加文件好很多。不过,它的缺点也很明显。在数据量大时,fork 子进程需要用到比较大的内存,保存数据也很耗时。所以,你需要设置一个比较长的时间间隔来应对,比如至少 5 分钟。这样,如果发生故障,你丢失的就是几分钟的数据。
- 追加文件,则是用在文件末尾追加记录的方式,对 Redis 写入的数据,依次进行持久化,所以它的持久化也更安全。
-
但是:只是读取为什么会写aof呢?
仔细观察:
read(8, "*2\r\n$3\r\nGET\r\n$41\r\nuuid:53522908-"..., 16384) write(8, "$4\r\ngood\r\n", 10) read(8, "*3\r\n$4\r\nSADD\r\n$4\r\ngood\r\n$36\r\n535"..., 16384) write(7, "*3\r\n$4\r\nSADD\r\n$4\r\ngood\r\n$36\r\n535"..., 67) write(8, ":1\r\n", 4)可以发现:每当 GET 返回 good 时,随后都会有一个 SADD 操作,这也就导致了,明明是查询接口,Redis 却有大量的磁盘写。
-
解决
第一个问题,Redis 配置的 appendfsync 是 always,这就导致 Redis 每次的写操作,都会触发 fdatasync 系统调用。今天的案例,没必要用这么高频的同步写,使用默认的 1s 时间间隔,就足够了。第二个问题,Python 应用在查询接口中会调用 Redis 的 SADD 命令,这很可能是不合理使用缓存导致的。
套路篇:如何迅速分析出系统I/O的瓶颈在哪里?
性能指标
如果你配置了 RAID,从文件系统看到的使用量跟实际磁盘的占用空间,也会因为 RAID 级别的不同而不一样。比方说,配置 RAID10 后,你从文件系统最多也只能看到所有磁盘容量的一半。
前面内容回顾:
第一,在文件系统的原理中,我介绍了查看文件系统容量的工具 df。它既可以查看文件系统数据的空间容量,也可以查看索引节点的容量。至于文件系统缓存,我们通过 /proc/meminfo、/proc/slabinfo 以及 slabtop 等各种来源,观察页缓存、目录项缓存、索引节点缓存以及具体文件系统的缓存情况。
第二,在磁盘 I/O 的原理中,我们分别用 iostat 和 pidstat 观察了磁盘和进程的 I/O 情况。它们都是最常用的 I/O 性能分析工具。通过 iostat ,我们可以得到磁盘的 I/O 使用率、吞吐量、响应时间以及 IOPS 等性能指标;而通过 pidstat ,则可以观察到进程的 I/O 吞吐量以及块设备 I/O 的延迟等。
第三,在狂打日志的案例中,我们先用 top 查看系统的 CPU 使用情况,发现 iowait 比较高;然后,又用 iostat 发现了磁盘的 I/O 使用率瓶颈,并用 pidstat 找出了大量 I/O 的进程;最后,通过 strace 和 lsof,我们找出了问题进程正在读写的文件,并最终锁定性能问题的来源——原来是进程在狂打日志。
第四,在磁盘 I/O 延迟的单词热度案例中,我们同样先用 top、iostat ,发现磁盘有 I/O 瓶颈,并用 pidstat 找出了大量 I/O 的进程。可接下来,想要照搬上次操作的我们失败了。在随后的 strace 命令中,我们居然没看到 write 系统调用。于是,我们换了一个思路,用新工具 filetop 和 opensnoop ,从内核中跟踪系统调用,最终找出瓶颈的来源。
最后,在 MySQL 和 Redis 的案例中,同样的思路,我们先用 top、iostat 以及 pidstat ,确定并找出 I/O 性能问题的瓶颈来源,它们正是 mysqld 和 redis-server。随后,我们又用 strace+lsof 找出了它们正在读写的文件。
IO性能
文件系统,是对存储设备上的文件,进行组织管理的一种机制。为了支持各类不同的文件系统,Linux 在各种文件系统实现上,抽象了一层虚拟文件系统(VFS)。
VFS 定义了一组所有文件系统都支持的数据结构和标准接口。这样,用户进程和内核中的其他子系统,就只需要跟 VFS 提供的统一接口进行交互。
为了降低慢速磁盘对性能的影响,文件系统又通过页缓存、目录项缓存以及索引节点缓存,缓和磁盘延迟对应用程序的影响。
容量
对文件系统来说,最常见的一个问题就是空间不足。当然,你可能本身就知道,用 df 命令,就能查看文件系统的磁盘空间使用情况。比如:(加 -h 可以转换为常用单位)
$ df /dev/sda1
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sda1 30308240 3167020 27124836 11% /
-
除了文件数据,索引节点也占用磁盘空间。你可以给 df 命令加上 -i 参数,查看索引节点的使用情况
$ df -i /dev/sda1 Filesystem Inodes IUsed IFree IUse% Mounted on /dev/sda1 3870720 157460 3713260 5% /
问题1:
索引节点的容量,(也就是 Inode 个数)是在格式化磁盘时设定好的,一般由格式化工具自动生成。当你发现索引节点空间不足,但**磁盘空间充足时,很可能就是过多小文件导致的。**所以,
- 一般来说,删除这些小文件,或者把它们移动到索引节点充足的其他磁盘中,就可以解决这个问题。
缓存
可以用 free 或 vmstat,来观察页缓存的大小。复习一下,free 输出的 Cache,是页缓存和可回收 Slab 缓存的和,你可以从 /proc/meminfo ,直接得到它们的大小:
$ cat /proc/meminfo | grep -E "SReclaimable|Cached"
Cached: 748316 kB
SwapCached: 0 kB
SReclaimable: 179508 kB
实际上,内核使用 Slab 机制,管理目录项和索引节点的缓存。/proc/meminfo 只给出了 Slab 的整体大小,具体到每一种 Slab 缓存,还要查看 /proc/slabinfo 这个文件。
运行下面的命令,你就可以得到,所有目录项和各种文件系统索引节点的缓存情况:
$ cat /proc/slabinfo | grep -E '^#|dentry|inode'
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
xfs_inode 0 0 960 17 4 : tunables 0 0 0 : slabdata 0 0 0
...
ext4_inode_cache 32104 34590 1088 15 4 : tunables 0 0 0 : slabdata 2306 2306 0hugetlbfs_inode_cache 13 13 624 13 2 : tunables 0 0 0 : slabdata 1 1 0
sock_inode_cache 1190 1242 704 23 4 : tunables 0 0 0 : slabdata 54 54 0
shmem_inode_cache 1622 2139 712 23 4 : tunables 0 0 0 : slabdata 93 93 0
proc_inode_cache 3560 4080 680 12 2 : tunables 0 0 0 : slabdata 340 340 0
inode_cache 25172 25818 608 13 2 : tunables 0 0 0 : slabdata 1986 1986 0
dentry 76050 121296 192 21 1 : tunables 0 0 0 : slabdata 5776 5776 0
dentry 行表示目录项缓存,inode_cache 行,表示 VFS 索引节点缓存,其余的则是各种文件系统的索引节点缓存。
/proc/slabinfo 的列比较多,具体含义你可以查询 man slabinfo。在实际性能分析中,我们更常使用 slabtop ,来找到占用内存最多的缓存类型。比如,下面就是我运行 slabtop 得到的结果:
# 按下c按照缓存大小排序,按下a按照活跃对象数排序
$ slabtop
Active / Total Objects (% used) : 277970 / 358914 (77.4%)
Active / Total Slabs (% used) : 12414 / 12414 (100.0%)
Active / Total Caches (% used) : 83 / 135 (61.5%)
Active / Total Size (% used) : 57816.88K / 73307.70K (78.9%)
Minimum / Average / Maximum Object : 0.01K / 0.20K / 22.88K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
69804 23094 0% 0.19K 3324 21 13296K dentry
16380 15854 0% 0.59K 1260 13 10080K inode_cache
58260 55397 0% 0.13K 1942 30 7768K kernfs_node_cache
485 413 0% 5.69K 97 5 3104K task_struct
1472 1397 0% 2.00K 92 16 2944K kmalloc-2048
从这个结果你可以看到,在我的系统中,目录项和索引节点占用了最多的 Slab 缓存。不过它们占用的内存其实并不大,加起来也只有 23MB 左右。
网络篇
网络是一种把不同计算机或网络设备连接到一起的技术,它本质上是一种进程间通信方式
应用层,负责为应用程序提供统一的接口。
表示层,负责把数据转换成兼容接收系统的格式。
会话层,负责维护计算机之间的通信连接。
传输层,负责为数据加上传输表头,形成数据包。
网络层,负责数据的路由和转发。
数据链路层,负责 MAC 寻址、错误侦测和改错。
物理层,负责在物理网络中传输数据帧。
工具
netstat
查看 TCP 状态
interval: 重新显示选定的统计信息,各个显示间暂停的间隔秒数。
-a: 显示所有连接和侦听端口。
-n: 以数字形式(如 IP 地址)显示地址和端口号。
-r: 显示路由表。
-s: 显示每个协议的统计信息。
-o(Windows): 显示拥有的与每个连接关联的进程 ID。
-b(Windows)/-p(Linux) : 显示对应的可执行程序名字。
网络包的接收流程
- 内核分配一个主内存地址段(DMA缓冲区),网卡设备可以在DMA缓冲区中读写数据
- 当来了一个网络包,网卡将网络包写入DMA缓冲区,写完后通知CPU产生硬中断
- 硬中断处理程序锁定当前DMA缓冲区,网卡中断处理程序会为网络帧分配内核数据结构(sk_buff),并将其拷贝到 sk_buff 缓冲区中(另一块内存区),清空并解锁当前DMA缓冲区,然后通知软中断去处理网络包。
https://segmentfault.com/a/1190000008836467
网卡到内存
+-----+
| | Memroy
+--------+ 1 | | 2 DMA +--------+--------+--------+--------+
| Packet |-------->| NIC |------------>| Packet | Packet | Packet | ...... |
+--------+ | | +--------+--------+--------+--------+
| |<--------+
+-----+ |
| +---------------+
| |
3 | Raise IRQ | Disable IRQ
| 5 |
| |
↓ |
+-----+ +------------+
| | Run IRQ handler | |
| CPU |------------------>| NIC Driver |
| | 4 | |
+-----+ +------------+
|
6 | Raise soft IRQ
|
↓
- 1: 数据包从外面的网络进入物理网卡。如果目的地址不是该网卡,且该网卡没有开启混杂模式,该包会被网卡丢弃。
- 2: 网卡将数据包通过DMA的方式写入到指定的内存地址,该地址由网卡驱动分配并初始化。注: 老的网卡可能不支持DMA,不过新的网卡一般都支持。
- 3: 网卡通过硬件中断(IRQ)通知CPU,告诉它有数据来了
- 4: CPU根据中断表,调用已经注册的中断函数,这个中断函数会调到驱动程序(NIC Driver)中相应的函数
- 5: 驱动先禁用网卡的中断,表示驱动程序已经知道内存中有数据了,告诉网卡下次再收到数据包直接写内存就可以了,不要再通知CPU了,这样可以提高效率,避免CPU不停的被中断。
- 6: 启动软中断。这步结束后,硬件中断处理函数就结束返回了。由于硬中断处理程序执行的过程中不能被中断,所以如果它执行时间过长,会导致CPU没法响应其它硬件的中断,于是内核引入软中断,这样可以将硬中断处理函数中耗时的部分移到软中断处理函数里面来慢慢处理。
为什么要使用两部分中断
当网卡接收流入网络的数据包时,需要通知内核数据包到了,网卡需要立即完成这件事,从而优化网络的吞吐量和传输周期,以避免超时。因此网卡立即发出中断,通知内核这里有最新的数据包。内核通过执行网卡已注册的中断处理程序作出应答。中断开始运行,应答硬件,复制最新的网络数据包到内存,然后读取网卡更多的数据包,这些都是重要的、紧迫的、又与硬件相关的的工作。处理和操作其他数据包的其他工作在随后的下半部分进行。
内核的网络模块
+-----+
17 | |
+----------->| NIC |
| | |
|Enable IRQ +-----+
|
|
+------------+ Memroy
| | Read +--------+--------+--------+--------+
+--------------->| NIC Driver |<--------------------- | Packet | Packet | Packet | ...... |
| | | 9 +--------+--------+--------+--------+
| +------------+
| | | skb
Poll | 8 Raise softIRQ | 6 +-----------------+
| | 10 |
| ↓ ↓
+---------------+ Call +-----------+ +------------------+ +--------------------+ 12 +---------------------+
| net_rx_action |<-------| ksoftirqd | | napi_gro_receive |------->| enqueue_to_backlog |----->| CPU input_pkt_queue |
+---------------+ 7 +-----------+ +------------------+ 11 +--------------------+ +---------------------+
| | 13
14 | + - - - - - - - - - - - - - - - - - - - - - - +
↓ ↓
+--------------------------+ 15 +------------------------+
| __netif_receive_skb_core |----------->| packet taps(AF_PACKET) |
+--------------------------+ +------------------------+
|
| 16
↓
+-----------------+
| protocol layers |
+-----------------+
- 7: 内核中的ksoftirqd进程专门负责软中断的处理,当它收到软中断后,就会调用相应软中断所对应的处理函数,对于上面第6步中是网卡驱动模块抛出的软中断,ksoftirqd会调用网络模块的net_rx_action函数
- 8: net_rx_action调用网卡驱动里的poll函数来一个一个的处理数据包
- 9: 在pool函数中,驱动会一个接一个的读取网卡写到内存中的数据包,内存中数据包的格式只有驱动知道
- 10: 驱动程序将内存中的数据包转换成内核网络模块能识别的skb格式,然后调用napi_gro_receive函数
- 11: napi_gro_receive会处理GRO相关的内容,也就是将可以合并的数据包进行合并,这样就只需要调用一次协议栈。然后判断是否开启了RPS,如果开启了,将会调用enqueue_to_backlog
- 12: 在enqueue_to_backlog函数中,会将数据包放入CPU的softnet_data结构体的input_pkt_queue中,然后返回,如果input_pkt_queue满了的话,该数据包将会被丢弃,queue的大小可以通过net.core.netdev_max_backlog来配置
- 13: CPU会接着在自己的软中断上下文中处理自己input_pkt_queue里的网络数据(调用__netif_receive_skb_core)
- 14: 如果没开启RPS,napi_gro_receive会直接调用__netif_receive_skb_core
- 15: 看是不是有AF_PACKET类型的socket(也就是我们常说的原始套接字),如果有的话,拷贝一份数据给它。tcpdump抓包就是抓的这里的包。
- 16: 调用协议栈相应的函数,将数据包交给协议栈处理。
- 17: 待内存中的所有数据包被处理完成后(即poll函数执行完成),启用网卡的硬中断,这样下次网卡再收到数据的时候就会通知CPU
IP层
|
|
↓ promiscuous mode &&
+--------+ PACKET_OTHERHOST (set by driver) +-----------------+
| ip_rcv |-------------------------------------->| drop this packet|
+--------+ +-----------------+
|
|
↓
+---------------------+
| NF_INET_PRE_ROUTING |
+---------------------+
|
|
↓
+---------+
| | enabled ip forword +------------+ +----------------+
| routing |-------------------->| ip_forward |------->| NF_INET_FORWARD |
| | +------------+ +----------------+
+---------+ |
| |
| destination IP is local ↓
↓ +---------------+
+------------------+ | dst_output_sk |
| ip_local_deliver | +---------------+
+------------------+
|
|
↓
+------------------+
| NF_INET_LOCAL_IN |
+------------------+
|
|
↓
+-----------+
| UDP layer |
+-----------+
- ip_rcv: ip_rcv函数是IP模块的入口函数,在该函数里面,第一件事就是将垃圾数据包(目的mac地址不是当前网卡,但由于网卡设置了混杂模式而被接收进来)直接丢掉,然后调用注册在NF_INET_PRE_ROUTING上的函数
- NF_INET_PRE_ROUTING: netfilter放在协议栈中的钩子,可以通过iptables来注入一些数据包处理函数,用来修改或者丢弃数据包,如果数据包没被丢弃,将继续往下走
- routing: 进行路由,如果是目的IP不是本地IP,且没有开启ip forward功能,那么数据包将被丢弃,如果开启了ip forward功能,那将进入ip_forward函数
- ip_forward: ip_forward会先调用netfilter注册的NF_INET_FORWARD相关函数,如果数据包没有被丢弃,那么将继续往后调用dst_output_sk函数
- dst_output_sk: 该函数会调用IP层的相应函数将该数据包发送出去,同下一篇要介绍的数据包发送流程的后半部分一样。
- ip_local_deliver:如果上面routing的时候发现目的IP是本地IP,那么将会调用该函数,在该函数中,会先调用NF_INET_LOCAL_IN相关的钩子程序,如果通过,数据包将会向下发送到UDP层
UDP层
|
|
↓
+---------+ +-----------------------+
| udp_rcv |----------->| __udp4_lib_lookup_skb |
+---------+ +-----------------------+
|
|
↓
+--------------------+ +-----------+
| sock_queue_rcv_skb |----->| sk_filter |
+--------------------+ +-----------+
|
|
↓
+------------------+
| __skb_queue_tail |
+------------------+
|
|
↓
+---------------+
| sk_data_ready |
+---------------+
- udp_rcv: udp_rcv函数是UDP模块的入口函数,它里面会调用其它的函数,主要是做一些必要的检查,其中一个重要的调用是__udp4_lib_lookup_skb,该函数会根据目的IP和端口找对应的socket,如果没有找到相应的socket,那么该数据包将会被丢弃,否则继续
- sock_queue_rcv_skb: 主要干了两件事,一是检查这个socket的receive buffer是不是满了,如果满了的话,丢弃该数据包,然后就是调用sk_filter看这个包是否是满足条件的包,如果当前socket上设置了filter,且该包不满足条件的话,这个数据包也将被丢弃(在Linux里面,每个socket上都可以像tcpdump里面一样定义filter,不满足条件的数据包将会被丢弃)
- __skb_queue_tail: 将数据包放入socket接收队列的末尾
- sk_data_ready: 通知socket数据包已经准备好
调用完sk_data_ready之后,一个数据包处理完成,等待应用层程序来读取,上面所有函数的执行过程都在软中断的上下文中。
enqueue_to_backlog函数也会被netif_rx函数调用,而netif_rx正是lo设备发送数据包时调用的函数
socket
应用层一般有两种方式接收数据,一种是recvfrom函数阻塞在那里等着数据来,这种情况下当socket收到通知后,recvfrom就会被唤醒,然后读取接收队列的数据;另一种是通过epoll或者select监听相应的socket,当收到通知后,再调用recvfrom函数去读取接收队列的数据。两种情况都能正常的接收到相应的数据包。
网络包的发送流程
首先,应用程序调用 Socket API(比如 sendmsg)发送网络包。由于这是一个系统调用,所以会陷入到内核态的套接字层中。套接字层会把数据包放到 Socket 发送缓冲区中。接下来,网络协议栈从 Socket 发送缓冲区中,取出数据包;再按照 TCP/IP 栈,从上到下逐层处理。比如,传输层和网络层,分别为其增加 TCP 头和 IP 头,执行路由查找确认下一跳的 IP,并按照 MTU 大小进行分片。分片后的网络包,再送到网络接口层,进行物理地址寻址,以找到下一跳的 MAC 地址。然后添加帧头和帧尾,放到发包队列中。这一切完成后,会有软中断通知驱动程序:发包队列中有新的网络帧需要发送。最后,驱动程序通过 DMA ,从发包队列中读出网络帧,并通过物理网卡把它发送出去。
网络性能指标
实际上,我们通常用带宽、吞吐量、延时、PPS(Packet Per Second)等指标衡量网络的性能。
- 带宽,表示链路的最大传输速率,单位通常为 b/s (比特 / 秒)。
- 吞吐量,表示单位时间内成功传输的数据量,单位通常为 b/s(比特 / 秒)或者 B/s(字节 / 秒)。吞吐量受带宽限制,而吞吐量 / 带宽,也就是该网络的使用率。
- 延时,表示从网络请求发出后,一直到收到远端响应,所需要的时间延迟。在不同场景中,这一指标可能会有不同含义。比如,它可以表示,建立连接需要的时间(比如 TCP 握手延时),或一个数据包往返所需的时间(比如 RTT)。
- PPS,是 Packet Per Second(包 / 秒)的缩写,表示以网络包为单位的传输速率。PPS 通常用来评估网络的转发能力,比如硬件交换机,通常可以达到线性转发(即 PPS 可以达到或者接近理论最大值)。而基于 Linux 服务器的转发,则容易受网络包大小的影响。
除了这些指标,网络的可用性(网络能否正常通信)、并发连接数(TCP 连接数量)、丢包率(丢包百分比)、重传率(重新传输的网络包比例)等也是常用的性能指标。
查看指标
ip和ifconfig
$ ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.240.0.30 netmask 255.240.0.0 broadcast 10.255.255.255
inet6 fe80::20d:3aff:fe07:cf2a prefixlen 64 scopeid 0x20<link>
ether 78:0d:3a:07:cf:3a txqueuelen 1000 (Ethernet)
RX packets 40809142 bytes 9542369803 (9.5 GB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 32637401 bytes 4815573306 (4.8 GB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
$ ip -s addr show dev eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 78:0d:3a:07:cf:3a brd ff:ff:ff:ff:ff:ff
inet 10.240.0.30/12 brd 10.255.255.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::20d:3aff:fe07:cf2a/64 scope link
valid_lft forever preferred_lft forever
RX: bytes packets errors dropped overrun mcast
9542432350 40809397 0 0 0 193
TX: bytes packets errors dropped carrier collsns
4815625265 32637658 0 0 0 0
重要的几个:
第一,网络接口的状态标志。ifconfig 输出中的 RUNNING ,或 ip 输出中的 LOWER_UP ,都表示物理网络是连通的,即网卡已经连接到了交换机或者路由器中。如果你看不到它们,通常表示网线被拔掉了。
第二,MTU 的大小。MTU 默认大小是 1500,根据网络架构的不同(比如是否使用了 VXLAN 等叠加网络),你可能需要调大或者调小 MTU 的数值。
第三,网络接口的 IP 地址、子网以及 MAC 地址。这些都是保障网络功能正常工作所必需的,你需要确保配置正确。
第四,网络收发的字节数、包数、错误数以及丢包情况,特别是 TX 和 RX 部分的 errors、dropped、overruns、carrier 以及 collisions 等指标不为 0 时,通常表示出现了网络 I/O 问题。其中:
- errors 表示发生错误的数据包数,比如校验错误、帧同步错误等;
- dropped 表示丢弃的数据包数,即数据包已经收到了 Ring Buffer,但因为内存不足等原因丢包;
- overruns 表示超限数据包数,即网络 I/O 速度过快,导致 Ring Buffer 中的数据包来不及处理(队列满)而导致的丢包;
- carrier 表示发生 carrirer 错误的数据包数,比如双工模式不匹配、物理电缆出现问题等;
- collisions 表示碰撞数据包数。套接字信息
套接字信息
可以用 netstat 或者 ss ,来查看套接字、网络栈、网络接口以及路由表的信息。我个人更推荐,使用 ss 来查询网络的连接信息,因为它比 netstat 提供了更好的性能(速度更快)。
# head -n 3 表示只显示前面3行
# -l 表示只显示监听套接字
# -n 表示显示数字地址和端口(而不是名字)
# -p 表示显示进程信息
$ netstat -nlp | head -n 3
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN 840/systemd-resolve
# -l 表示只显示监听套接字
# -t 表示只显示 TCP 套接字
# -n 表示显示数字地址和端口(而不是名字)
# -p 表示显示进程信息
$ ss -ltnp | head -n 3
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 127.0.0.53%lo:53 0.0.0.0:* users:(("systemd-resolve",pid=840,fd=13))
LISTEN 0 128 0.0.0.0:22 0.0.0.0:* users:(("sshd",pid=1459,fd=3))
netstat 和 ss 的输出也是类似的,都展示了套接字的状态、接收队列、发送队列、本地地址、远端地址、进程 PID 和进程名称等。
其中,接收队列(Recv-Q)和发送队列(Send-Q)需要你特别关注,它们通常应该是 0。当你发现它们不是 0 时,说明有网络包的堆积发生。当然还要注意,在不同套接字状态下,它们的含义不同。
当套接字处于连接状态(Established)时,
- Recv-Q 表示套接字缓冲还没有被应用程序取走的字节数(即接收队列长度)。
- 而 Send-Q 表示还没有被远端主机确认的字节数(即发送队列长度)
当套接字处于监听状态(Listening)时,
- Recv-Q 表示全连接队列的长度。
- 而 Send-Q 表示全连接队列的最大长度。
所谓全连接,是指服务器收到了客户端的 ACK,完成了 TCP 三次握手,然后就会把这个连接挪到全连接队列中。这些全连接中的套接字,还需要被 accept() 系统调用取走,服务器才可以开始真正处理客户端的请求。
与全连接队列相对应的,还有一个半连接队列。所谓半连接是指还没有完成 TCP 三次握手的连接,连接只进行了一半。服务器收到了客户端的 SYN 包后,就会把这个连接放到半连接队列中,然后再向客户端发送 SYN+ACK 包。
协议栈统计信息
使用 netstat 或 ss ,也可以查看协议栈的信息:
$ netstat -s
...
Tcp:
3244906 active connection openings
23143 passive connection openings
115732 failed connection attempts
2964 connection resets received
1 connections established
13025010 segments received
17606946 segments sent out
44438 segments retransmitted
42 bad segments received
5315 resets sent
InCsumErrors: 42
...
$ ss -s
Total: 186 (kernel 1446)
TCP: 4 (estab 1, closed 0, orphaned 0, synrecv 0, timewait 0/0), ports 0
Transport Total IP IPv6
* 1446 - -
RAW 2 1 1
UDP 2 2 0
TCP 4 3 1
...
这些协议栈的统计信息都很直观。ss 只显示已经连接、关闭、孤儿套接字等简要统计,而 netstat 则提供的是更详细的网络协议栈信息。
比如,上面 netstat 的输出示例,就展示了 TCP 协议的主动连接、被动连接、失败重试、发送和接收的分段数量等各种信息。
网络吞吐和 PPS
如何查看系统当前的网络吞吐量和 PPS。在这里,我推荐使用我们的老朋友 sar。
给 sar 增加 -n 参数就可以查看网络的统计信息,比如网络接口(DEV)、网络接口错误(EDEV)、TCP、UDP、ICMP 等等。执行下面的命令,你就可以得到网络接口统计信息:
# 数字1表示每隔1秒输出一组数据
$ sar -n DEV 1
Linux 4.15.0-1035-azure (ubuntu) 01/06/19 _x86_64_ (2 CPU)
13:21:40 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
13:21:41 eth0 18.00 20.00 5.79 4.25 0.00 0.00 0.00 0.00
13:21:41 docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
13:21:41 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
怎样查带宽:
$ ethtool eth0 | grep Speed Speed: 1000Mb/s
连通性和延时
通常使用 ping ,来测试远程主机的连通性和延时
# -c3表示发送三次ICMP包后停止
$ ping -c3 114.114.114.114
PING 114.114.114.114 (114.114.114.114) 56(84) bytes of data.
64 bytes from 114.114.114.114: icmp_seq=1 ttl=54 time=244 ms
64 bytes from 114.114.114.114: icmp_seq=2 ttl=47 time=244 ms
64 bytes from 114.114.114.114: icmp_seq=3 ttl=67 time=244 ms
--- 114.114.114.114 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2001ms
rtt min/avg/max/mdev = 244.023/244.070/244.105/0.034 ms
第一部分,是每个 ICMP 请求的信息,包括 ICMP 序列号(icmp_seq)、TTL(生存时间,或者跳数)以及往返延时。
第二部分,则是三次 ICMP 请求的汇总。
使用过curl吗,可以干什么用
1. https://www.ruanyifeng.com/blog/2019/09/curl-reference.html
curl 是常用的命令行工具,用来请求 Web 服务器。它的名字就是客户端(client)的 URL 工具的意思。
它的功能非常强大,命令行参数多达几十种。如果熟练的话,完全可以取代 Postman 这一类的图形界面工具。
- 不带请求
1. https://www.ruanyifeng.com/blog/2019/09/curl-reference.html
- -A :参数指定客户端的用户代理标头,即User-Agent。curl 的默认用户代理字符串是curl/[version]。
- -b想服务器发送cookies
C10K 和 C1000K 问题
C 是 Client 的缩写。C10K 就是单机同时处理 1 万个请求(并发连接 1 万)的问题,而 C1000K 也就是单机支持处理 100 万个请求(并发连接 100 万)的问题。
C10K
多路复用(I/O Multiplexing)
第一种,使用非阻塞 I/O 和水平触发通知,比如使用 select 或者 poll。
第二种,使用非阻塞 I/O 和边缘触发通知,比如 epoll。
- epoll 使用红黑树,在内核中管理文件描述符的集合,这样,就不需要应用程序在每次操作时都传入、传出这个集合。
- epoll 使用事件驱动的机制,只关注有 I/O 事件发生的文件描述符,不需要轮询扫描整个集合。
- epoll 是在 Linux 2.6 中才新增的功能(2.4 虽然也有,但功能不完善)。由于边缘触发只在文件描述符可读或可写事件发生时才通知,那么应用程序就需要尽可能多地执行 I/O,并要处理更多的异常事件。
第三种,使用异步 I/O(Asynchronous I/O,简称为 AIO)
工作模型优化
第一种,主进程 + 多个 worker 子进程
这也是最常用的一种模型。这种方法的一个通用工作模式就是:主进程执行 bind() + listen() 后,创建多个子进程;然后,在每个子进程中,都通过 accept() 或 epoll_wait() ,来处理相同的套接字。
惊群的问题
-
accept() 的惊群问题,已经在 Linux 2.6 中解决了;
-
epoll 的问题,到了 Linux 4.5 ,才通过 EPOLLEXCLUSIVE 解决。
为了避免惊群问题, Nginx 在每个 worker 进程中,都增加一个了全局锁(accept_mutex)。这些 worker 进程需要首先竞争到锁,只有竞争到锁的进程,才会加入到 epoll 中,这样就确保只有一个 worker 子进程被唤醒。
第二种,监听到相同端口的多进程模型
由于内核确保了只有一个进程被唤醒,就不会出现惊群问题了。比如,Nginx 在 1.9.1 中就已经支持了这种模式。
不过要注意,想要使用 SO_REUSEPORT 选项,需要用 Linux 3.9 以上的版本才可以。
C1000K
首先从物理资源使用上来说,100 万个请求需要大量的系统资源。比如,
- 假设每个请求需要 16KB 内存的话,那么总共就需要大约 15 GB 内存。
- 而从带宽上来说,假设只有 20% 活跃连接,即使每个连接只需要 1KB/s 的吞吐量,总共也需要 1.6 Gb/s 的吞吐量。千兆网卡显然满足不了这么大的吞吐量,所以还需要配置万兆网卡,或者基于多网卡 Bonding 承载更大的吞吐量。
其次,从软件资源上来说,大量的连接也会占用大量的软件资源,比如文件描述符的数量、连接状态的跟踪(CONNTRACK)、网络协议栈的缓存大小(比如套接字读写缓存、TCP 读写缓存)等等。
最后,大量请求带来的中断处理,也会带来非常高的处理成本。这样,就需要多队列网卡、中断负载均衡、CPU 绑定、RPS/RFS(软中断负载均衡到多个 CPU 核上),以及将网络包的处理卸载(Offload)到网络设备(如 TSO/GSO、LRO/GRO、VXLAN OFFLOAD)等各种硬件和软件的优化。
C1000K 的解决方法,本质上还是构建在 epoll 的非阻塞 I/O 模型上。只不过,除了 I/O 模型之外,还需要从应用程序到 Linux 内核、再到 CPU、内存和网络等各个层次的深度优化,特别是需要借助硬件,来卸载那些原来通过软件处理的大量功能。
C10M
实际上,在 C1000K 问题中,各种软件、硬件的优化很可能都已经做到头了。特别是当升级完硬件(比如足够多的内存、带宽足够大的网卡、更多的网络功能卸载等)后,你可能会发现,无论你怎么优化应用程序和内核中的各种网络参数,想实现 1000 万请求的并发,都是极其困难的。
究其根本,还是 Linux 内核协议栈做了太多太繁重的工作。从网卡中断带来的硬中断处理程序开始,到软中断中的各层网络协议处理,最后再到应用程序,这个路径实在是太长了,就会导致网络包的处理优化,到了一定程度后,就无法更进一步了。
要解决这个问题,最重要就是跳过内核协议栈的冗长路径,把网络包直接送到要处理的应用程序那里去。这里有两种常见的机制,DPDK 和 XDP。
**第一种机制,DPDK,**是用户态网络的标准。它跳过内核协议栈,直接由用户态进程通过轮询的方式,来处理网络接收。
**第二种机制,XDP(**eXpress Data Path),则是 Linux 内核提供的一种高性能网络数据路径。它允许网络包,在进入内核协议栈之前,就进行处理,也可以带来更高的性能。XDP 底层跟我们之前用到的 bcc-tools 一样,都是基于 Linux 内核的 eBPF 机制实现的。
各协议层的性能测试
转发性能
如何来测试网络包的处理能力:使用pktgen模拟包的产生,然后生成测试报告。
TCP/UDP 性能
iperf 或者 netperf。
iperf 和 netperf 都是最常用的网络性能测试工具,测试 TCP 和 UDP 的吞吐量。它们都以客户端和服务器通信的方式,测试一段时间内的平均吞吐量。
# -c表示启动客户端,192.168.0.30为目标服务器的IP
# -b表示目标带宽(单位是bits/s)
# -t表示测试时间
# -P表示并发数,-p表示目标服务器监听端口
$ iperf3 -c 192.168.0.30 -b 1G -t 15 -P 2 -p 10000
结果
[ ID] Interval Transfer Bandwidth
...
[SUM] 0.00-15.04 sec 0.00 Bytes 0.00 bits/sec sender
[SUM] 0.00-15.04 sec 1.51 GBytes 860 Mbits/sec receiver
HTTP 性能
要测试 HTTP 的性能,也有大量的工具可以使用,比如 ab、webbench 等,都是常用的 HTTP 压力测试工具。(只能模拟请求,无负载)
那么,为了得到应用程序的实际性能,就要求性能工具本身可以模拟用户的请求负载,而 iperf、ab 这类工具就无能为力了。幸运的是,我们还可以用 wrk、TCPCopy、Jmeter 或者 LoadRunner 等实现这个目标。
以 wrk 为例,它是一个 HTTP 性能测试工具,内置了 LuaJIT,方便你根据实际需求,生成所需的请求负载,或者自定义响应的处理方法。比如,你可以在 setup 阶段,为请求设置认证参数(来自于 wrk 官方示例)
-- example script that demonstrates response handling and
-- retrieving an authentication token to set on all future
-- requests
token = nil
path = "/authenticate"
request = function()
return wrk.format("GET", path)
end
response = function(status, headers, body)
if not token and status == 200 then
token = headers["X-Token"]
path = "/resource"
wrk.headers["X-Token"] = token
end
end
案例篇:DNS 解析时快时慢,我该怎么办?
DNS 解析受到各种网络状况的影响,性能可能不稳定。比如公网延迟增大,缓存过期导致要重新去上游服务器请求,或者流量高峰时 DNS 服务器性能不足等,都会导致 DNS 响应的延迟增大。
此时,可以借助 nslookup 或者 dig 的调试功能,分析 DNS 的解析过程,再配合 ping 等工具调试 DNS 服务器的延迟,从而定位出性能瓶颈。通常,你可以用缓存、预取、HTTPDNS 等方法,优化 DNS 的性能。
案例篇:怎么使用 tcpdump 和 Wireshark 分析网络流量?
在实际分析网络性能时,先用 tcpdump 抓包,后用 Wireshark 分析,也是一种常用的方法。
命令
shell基本
$表示普通用户,#表示管理员用户root。
编写shell脚本
第一行一般:shebang(#!)+解释器路径
#!/bin/bash
然后设置可执行权限
然后执行
当启动一个交互式shell时,它会执行一组命令来初始化提示文本、颜色等设置。这组命令来自用户主目录中的脚本文件/.bashrc(对于登录shell则是/.bash_profile)。Bash shell还维护了一个历史记录文件~/.bash_history,用于保存用户运行过的命令。
echo
echo是用于终端打印的最基本命令。默认情况下,echo在每次调用后会添加一个换行符。如果需要打印像!这样的特殊字符,那就不要将其放入双引号中,而是使用单引号,或是在特殊字符之前加上一个反斜线(\):
下面三种都可以
echo 'hello world !'
echo hello world !
echo "hello world \!"
%s、%c、%d和%f都是格式替换符(format substitution character),它们定义了该如何打印后续参数。%-5s指明了一个格式为左对齐且宽度为5的字符串替换(-表示左对齐)。如果不指明-,字符串就采用右对齐形式。宽度指定了保留给某个字符串的字符数量。对Name而言,其保留宽度是10。因此,任何Name字段的内容都会被显示在10字符宽的保留区域内,如果内容不足10个字符,余下的则以空格填充。对于浮点数,可以使用其他参数对小数部分进行舍入(round off)。对于Mark字段,我们将其格式化为%-4.2f,其中.2指定保留两位小数。注意,在每行的格式字符串后都有一个换行符(\n)。
变量
查看全局环境变量
env
查看与某个进程有关的变量
cat /proc/[pid]/environ
/proc/PID/environ是一个包含环境变量以及对应变量值的列表。每一个变量以name=value的形式来描述,彼此之间由null字符(\0)分隔。形式上确实不太易读。
要想生成一份易读的报表,可以将cat命令的输出通过管道传给tr,将其中的\0替换成\n:
cat /proc/[pid]/environ | tr '\0' '\n'
自己定义和使用变量
怎样不打开一个文件的情况下修改配置
1.使用grep,定位配置所在的行
grep -n ^key /etc/txt.conf
2.使用sed
批量替换文件内容
将当前目录及所有子目录下的所有pom.xml文件中的”http://repo1.maven.org/maven2“ 替换为”http://localhost:8081/nexus/content/groups/public“.
find -name 'pom.xml' | xargs perl -pi -e 's|http://repo1.maven.org/maven2|http://localhost:8081/nexus/content/groups/public|g'
修改内核配置用啥
用sysctl
- 查询配置如:
sysctl kernel.sysrq - 修改配置如:
sysctl -w net.ipv4.tcp_sack=1
Linux三剑客
https://www.cnblogs.com/ppc-srever/p/9322973.html
- grep
- sed
- awk
grep是linux下一个强大的搜索工具,几乎操作linux的用户每天都会或多或少的用到grep命令,单一个功能再强大,也存在短板,grep最明显的短板就是不能对已知结果进行更改,因此sed和awk工具就弥补了grep的短板,有人习惯称grep,sed和awk并称为linux下三剑客,是体现了三个工具一个计算机工作者不可缺少的必备技能之一
sed
https://www.runoob.com/linux/linux-comm-sed.html
https://www.runoob.com/linux/linux-comm-sed.html
- 以行为单位的替换与显示
- 以行为单位的新增/删除
sed的使用:
因参数过多,个人将列举部分常用的参数
- a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
- c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
- d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
- i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
- p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
- s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g
查询:
 指定行区间查找以root开头的内容
指定行区间查找以root开头的内容
匹配行之后增加显示内容
文本逆向排序输出
显示行号(空行也显示)或(空行不显示行号)
显示文件总行数
显示偶数和奇数行
文件中每行内容逆向显示
将数字按照“个十百”显示
删除:
删除指定内容:
-
将 /etc/passwd 的内容列出并且列印行号,同时,请将第 2~5 行删除!
[root@www ~]# nl /etc/passwd | sed '2,5d' -
只要删除第 2 行
nl /etc/passwd | sed '2d' -
要删除第 3 到最后一行
nl /etc/passwd | sed '3,$d'
修改:
-
指定内容进行替换,如将第2-5行的内容取代成为『No 2-5 number』呢?
[root@www ~]# nl /etc/passwd | sed '2,5c No 2-5 number' 1 root:x:0:0:root:/root:/bin/bash No 2-5 number 6 sync:x:5:0:sync:/sbin:/bin/sync
新增
在第二行后(亦即是加在第三行)加上『drink tea?』字样!
[root@www ~]# nl /etc/passwd | sed '2a drink tea'
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
drink tea
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
.....(后面省略).....
grep
注意 | 是管道重定向的意思
比如
grep -o hello a | wc -l
与普通重定向的区别
> 是重定向
|是管道重定向
区别是:
1、左边的命令应该有标准输出 | 右边的命令应该接受标准输入
左边的命令应该有标准输出 > 右边只能是文件
左边的命令应该需要标准输入 < 右边只能是文件
2、管道触发两个子进程执行"|"两边的程序;而重定向是在一个进程内执行
常见的用法要牢记
grep参数使用:
因参数过多,个人将列举部分常用的参数
-
查找指定进程和个数
[root@aly-centos7 /]# ps -ef | grep nginx root 14475 14272 0 13:21 pts/0 00:00:00 grep --color=auto nginx [root@aly-centos7 /]# ps -ef | grep -c nginx 1 -
查看多个文件相同的部分
查看passwd1,passwd2,passwd3相同的部分
[root@aly-centos7 /]# cat passwd1 | grep -f passwd2 | grep -f passwd3 -
从单个和多个文件查找指定内容并显示行号
-
指定字符查找开头,非开头,结尾的内容
[root@aly-centos7 /]# grep "^r" passwd3 #查找指定字符开头 root:x:0:0:root:/root:/bin/bash root,root root123 [root@aly-centos7 /]# grep "^[^r]" passwd3 #查找非指定字符开头 bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin [root@aly-centos7 /]# grep "n$" passwd3 #查找指定结尾 bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin [root@aly-centos7 /]# 指定字符查找开头,非开头,结尾的内容 -
过滤指定日志里面的ip个数
[root@aly-centos7 /]#cat qq.log | grep -c "[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}" 130205 -
过滤指定路径下所以文件里面包含指定字符内容
grep -r -n "root" /etc/
grep用于常规的查询操作固然方便,但是最大的弊端就是查出来不能增删改,导致如果是写一些脚本就会很不方便,这个时候就需要sed和awk这样的工具来实现。
pdistat
太强了
-u -r -p -d
https://www.jellythink.com/archives/444















 3446
3446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









