







Tomcat
一款开源轻量级web应用服务器,是一款优秀的servlet容器.
项目部署
隐式部署
直接丢文件夹、war、jar到webapps目录,tomcat会根据文件夹名称自动生成虚拟路径,简单,但是需要重启Tomcat服务器,包括要修改端口和访问路径的也需要重启。
显示部署
1.添加Context元素
在server.xml中的host下添加
<Host name="localhost">
<Context path="/comet" docBase="D:\work_tomcat\ref-comet.war" />
即/comet 这个虚拟路径映射到了D:\work_tomcat\ref-comet目录下(war会解压成文件),修改完servler.xml需要重启tomcat 服务器。
2.创建xml文件
在conf/Catalina/localhost中创建xml文件,访问路径为文件名,例如:
在localhost目录下新建demo.xml,内容为:
不需要写path,虚拟目录就是文件名demo,path默认为/demo,添加demo.xml不需要重启 tomcat服务器。
三种方式比较
隐式部署:可以很快部署,需要人手动移动Web应用到webapps下,在实际操作中不是很人性化。
添加context元素 : 配置速度快,需要配置两个路径,如果path为空字符串,则为缺省配置,每次修改server.xml文件后都要重新启动Tomcat服务器,重新部署。
创建xml文件:服务器后台会自动部署,修改一次后台部署一次,不用重复启动Tomcat服务器,该方式显得更为智能化。
Tomcat组件及架构
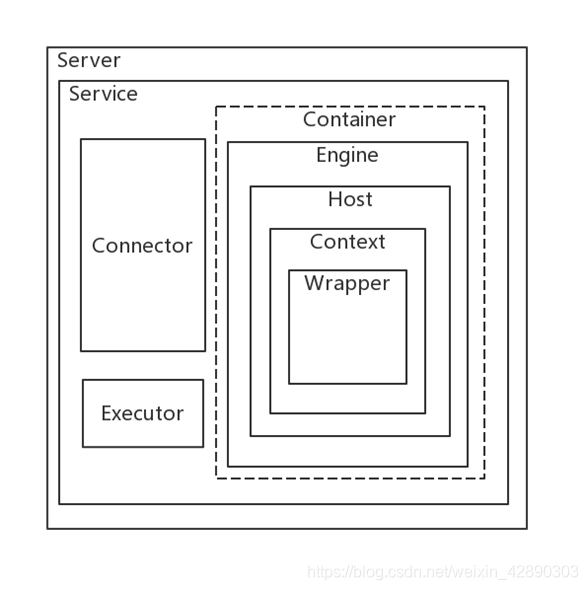
Server
Server是最顶级的组件,它代表Tomcat的运行实例,它掌管着整个Tomcat的生死大权;
- 提供了监听器机制,用于在Tomcat整个生命周期中对不同时间进行处理
- 提供Tomcat容器全局的命名资源实现,JNDI
- 监听某个端口以接受SHUTDOWN命令,用于关闭Tomcat
Service
一个概念,一个Service维护多个Connector和一个Container
Connector组件
链接器:监听转换Socket请求,将请求交给Container处理,支持不同协议以及不同的I/O方式
Container
表示能够执行客户端请求并返回响应的一类对象,其中有不同级别的容器:Engine、Host、Context、Wrapper
Engine
整个Servlet引擎,最高级的容器对象
Host
表示Servlet引擎中的虚拟机,主要与域名有关,一个服务器有多个域名是可以使用多个Host
Context
用于表示ServletContext,一个ServletContext表示一个独立的Web应用
Wrapper
用于表示Web应用中定义的Servlet
Executor
Tomcat组件间可以共享的线程池
Tomcat的核心组件
解耦:网络协议与容器的解耦。
Connector链接器封装了底层的网络请求(Socket请求及相应处理),提供了统一的接口,使Container容器与具体的请求协议以及I/O方式解耦。
Connector将Socket输入转换成Request对象,交给Container容器进行处理,处理请求后,Container通过Connector提供的Response对象将结果写入输出流。
因为无论是Request对象还是Response对象都没有实现Servlet规范对应的接口,Container会将它们进一步分装成ServletRequest和ServletResponse.
Tomcat的链接器
AJP主要是用于Web服务器与Tomcat服务器集成,AJP采用二进制传输可读性文本,使用保持持久性的TCP链接,使得AJP占用更少的带宽,并且链接开销要小得多,但是由于AJP采用持久化链接,因此有效的连接数较HTTP要更多。
对于I/0选择,要根据业务场景来定,一般高并发场景下,APR和NIO2的性能要优于NIO和BIO,(linux操作系统支持的NIO2由于是一个假的,并没有真正实现AIO,所以一般linux上推荐使用NIO,如果是APR的话,需要安装APR库,而Windows上默认安装了),所以在8.5的版本中默认是NIO。
Tomcat源码分析(从启动流程到请求处理)
Tomcat的启动流程
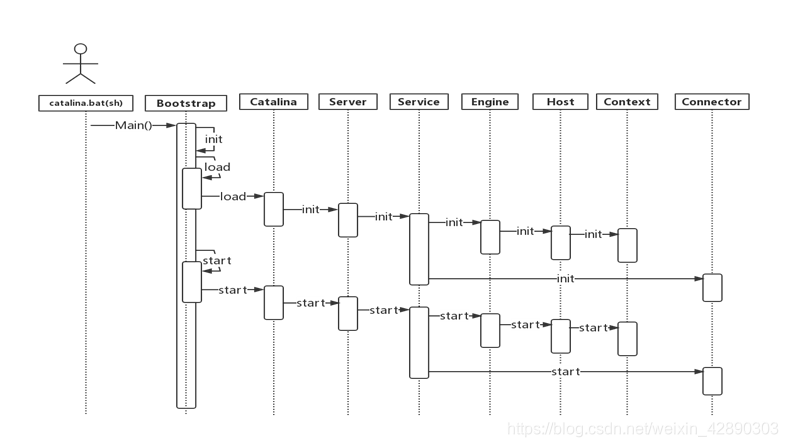
Tomcat的启动非常的标准,除去Boostrap和Catalin,我们可以对照一下Server.xml的配置文件。Server,service等等这些组件都是一一对照,同时又有先后顺序。
基本的顺序是先init方法,然后再start方法。
除了Bootstrap和catalina类,其他的Server,service等等之类的都只是一个接口,实现类均为StandardXXX类。
在Engine容器中,有四个级别的容器,他们的标准实现分别是StandardEngine、StandardHost、StandardContext、StandardWrapper
组件(容器)的生命周期管理
生命周期统一接口——Lifecycle
Tomcat内部架构中各个核心组件有包含与被包含关系,例如:Server包含了Service.Service又包含了Container和Connector,这个结构有一点像数据结构中的树,树的根结点没有父节点,其他节点有且仅有一个父节点,每一个父节点有0至多个子节点。所以,我们可以通过父容器启动它的子容器,这样只要启动根容器,就可以把其他所有的容器都启动,从而达到了统一的启动,停止、关闭的效果。
所有组件有一个统一的接口——Lifecycle,把所有的启动、停止、关闭、生命周期相关的方法都组织到一起,就可以很方便管理Tomcat各个容器组件的生命周期。
Lifecycle其实就是定义了一些状态常量和几个方法,主要方法是init,start,stop三个方法。
Container设计的目的
container从上一个组件connector手上接过解析好的内部request,根据request来进行一系列的逻辑操作,直到调用到请求的servlet,然后组装好response,返回给connecotr。
先来看看container的分类吧:Engine、Host、Context、Wrapper。它们各自的实现类分别是StandardEngine, StandardHost, StandardContext, and StandardWrapper,他们都在tomcat的org.apache.catalina.core包下。
它们之间的关系,可以查看tomcat的server.xml也能明白(根据节点父子关系),这么比喻吧:除了Wrapper最小,不能包含其他container外,Context内可以有零或多个Wrapper,Host可以拥有零或多个Context,Engine可以有零到多个Host。
Standard 的 container都是直接继承抽象类:org.apache.catalina.core.ContainerBase。
Tomcat处理一个HTTP请求的过程
用户点击网页内容,请求被发送到本机端口8080,被在那里监听的Coyote HTTP/1.1 Connector获得。
Connector把该请求交给它所在的Service的Engine来处理,并等待Engine的回应。
Engine获得请求localhost/test/index.jsp,匹配所有的虚拟主机Host。
Engine匹配到名为localhost的Host(即使匹配不到也把请求交给该Host处理,因为该Host被定义为该Engine的默认主机),名为localhost的Host获得请求/test/index.jsp,匹配它所拥有的所有的Context。Host匹配到路径为/test的Context(如果匹配不到就把该请求交给路径名为“ ”的Context去处理)。
path=“/test”的Context获得请求/index.jsp,在它的mapping table中寻找出对应的Servlet。Context匹配到URL PATTERN为*.jsp的Servlet,对应于JspServlet类。
构造HttpServletRequest对象和HttpServletResponse对象,作为参数调用JspServlet的doGet()或doPost().执行业务逻辑、数据存储等程序。
Context把执行完之后的HttpServletResponse对象返回给Host。
Host把HttpServletResponse对象返回给Engine。
Engine把HttpServletResponse对象返回Connector。
Connector把HttpServletResponse对象返回给客户Browser。
管道模式
Pipeline就像一个工厂中的生产线,负责调配工人(valve)的位置,valve则是生产线上负责不同操作的工人。
一个生产线的完成需要两步:
1,把原料运到工人边上
2,工人完成自己负责的部分
而tomcat的Pipeline实现是这样的:
1,在生产线上的第一个工人拿到生产原料后,二话不说就扔给下一个工人,下一个工人模仿第一个工人那样扔给下一个工人,直到最后一个工人,而最后一个工人被安排为上面提过的StandardValve,他要完成的工作居然是把生产资料运给自己包含的container的Pipeline上去。
2,四个container就相当于有四个生产线(Pipeline),四个Pipeline都这么干,直到最后的StandardWrapperValve拿到资源开始调用servlet。完成后返回来,一步一步的valve按照刚才丢生产原料是的顺序的倒序一次执行。如此才完成了tomcat的Pipeline的机制。
每一种container都有一个自己的StandardValve
上面四个container对应的四个是:
- StandardEngineValve
- StandardHostValve
- StandardContextValve
- StandardWrapperValve
在管道中连接一个或者多个阀门,每一个阀门负责一部分逻辑处理,数据按照规定的顺序往下流。此种模式分解了逻辑处理任务,可方便对某个任务单元进行安装、拆卸,提高流程的可拓展性,可重用性,机动性,灵活性。
Tomcat中定制阀门
管道机制给我们带来了更好的拓展性,例如,你要添加一个额外的逻辑处理阀门是很容易的。
- 自定义个阀门PrintIPValve,只要继承ValveBase并重写invoke方法即可。注意在invoke方法中一定要执行调用下一个阀门的操作,否则会出现异常。
public class PrintIPValve extends ValveBase{
@Override
public void invoke(Request request, Response response) throws IOException, ServletException {
System.out.println("------自定义阀门PrintIPValve:"+request.getRemoteAddr());
getNext().invoke(request,response);
}
}
- 配置Tomcat的核心配置文件server.xml,这里把阀门配置到Engine容器下,作用范围就是整个引擎,也可以根据作用范围配置在Host或者是Context下
<Valve className="org.apache.catalina.valves.PrintIPValve"/>
- 源码中是直接可以有效果,但是如果是运行版本,则可以将这个类导出成一个Jar包放入Tomcat/lib目录下,也可以直接将.class文件打包进catalina.jar包中。
Tomcat中提供常用的阀门
- AccessLogValve,请求访问日志阀门,通过此阀门可以记录所有客户端的访问日志,包括远程主机IP,远程主机名,请求方法,请求协议,会话ID,请求时间,处理时长,数据包大小等。它提供任意参数化的配置,可以通过任意组合来定制访问日志的格式
- JDBCAccessLogValve,同样是记录访问日志的阀门,但是它有助于将访问日志通过JDBC持久化到数据库中。
- ErrorReportValve,这是一个讲错误以HTML格式输出的阀门。
- PersistentValve,这是对每一个请求的会话实现持久化的阀门。
- RemoteAddrValve,访问控制阀门。可以通过配置决定哪些IP可以访问WEB应用。
- RemoteHostValve,访问控制阀门,通过配置觉得哪些主机名可以访问WEB应用。
- RemoteIpValve,针对代理或者负载均衡处理的一个阀门,一般经过代理或者负载均衡转发的请求都将自己的IP添加到请求头”X-Forwarded-For”中,此时,通过阀门可以获取访问者真实的IP。
- SemaphoreValve,这个是一个控制容器并发访问的阀门,可以作用在不同容器上。
Tomcat源码分析(类加载与类加载器)
类加载与类加载器
类加载
类加载:主要是将.class文件中的二进制字节读入到JVM中
我们可以看到因为这个定义,所以并没有规定一定是要磁盘加载文件,可以通过网络,内存什么的加载。只要是二进制流字节数据,JVM就认。
类加载过程:
1.通过类的全限定名获取该类的二进制字节流;
2.将字节流所代表的静态结构转化为方法区的运行时数据结构
3.在内存中生成一个该类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口
类加载器
定义:JVM设计者把“类加载”这个动作放到java虚拟机外部去实现,以便让应用程序决定如何获取所需要的类。实现这个动作的代码模块成为“类加载器”
类与类加载器
对于任何一个类,都需要由加载它的类加载器和这个类来确定其在JVM中的唯一性。也就是说,两个类来源于同一个Class文件,并且被同一个类加载器加载,这两个类才相等。
注意:这里所谓的“相等”,一般使用instanceof关键字做判断。
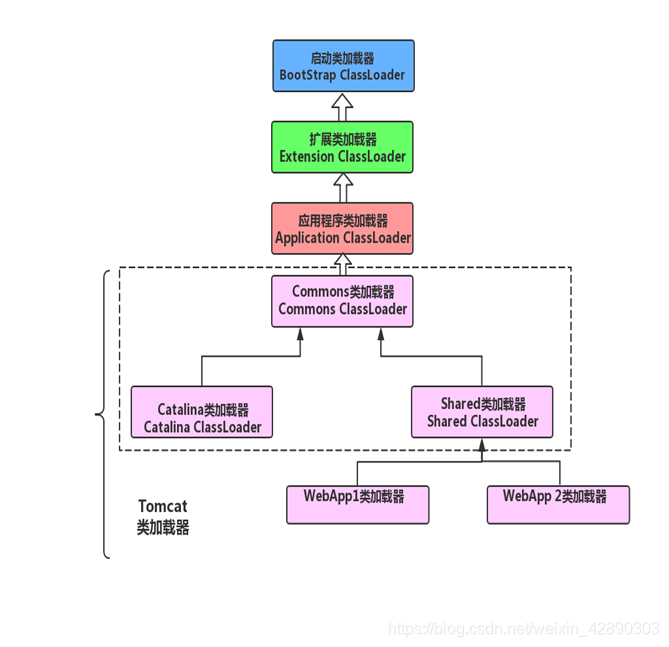
类加载器与双亲委派模型
类加载器
启动类加载器:该加载器使用C++语言实现,属于虚拟机自身的一部分。
启动类加载器(Bootstrap ClassLoader):负责加载JAVA_HOME\lib目录中并且能被虚拟机识别的类库加载到JVM内存中,如果名称不符合的类库即使在lib目录中也不会被加载。该类加载器无法被java程序直接引用
拓展类加载器与应用程序类加载器:另一部分就是所有其它的类加载器,这些类加载器是由Java语言实现,独立于JVM外部,并且全部继承抽象类java.lang.ClassLoader。
扩展类加载器(Extension ClassLoader):该加载器主要负责加载JAVA_HOME\lib\ext目录中的类库,开发者可以使用扩展加载器。
应用程序类加载器(Application ClassLoader):该列加载器也称为系统加载器,它负责加载用户类路径(Classpath)上所指定的类库,开发者可以直接使用该类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
双亲委派模型
定义:双亲委派模型的工作过程为:如果一个类加载器收到了类请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父加载器去完成,每一层都是如此,因此所有类加载的请求都会传到启动类加载器,只有当父加载器无法完成该请求时,子加载器才去自己加载。
实现方式:该模型要求除了顶层的启动类加载器外,其余的类加载器都应当有自己的父类加载器。子类加载器不是以继承的关系来实现,而是通过组合关系来复用父加载器的代码。
意义:好处双亲委派模型的好处就是java类随着它的类加载器一起具备了一种带有优先级的层次关系。例如:Object,无论那个类加载器去加载该类,最终都是由启动类加载器进行加载的,因此Object类在程序的各种类加载环境中都是一个类。如果不用改模型,那么java.lang.Object类存放在classpath中,那么系统中就会出现多个Object类,程序变得很混乱。
双亲委派模型
从虚拟机的角度来说,有两种不同的类加载器:一种是启动类加载器(Bootstrap ClassLoader),该加载器使用C++语言实现,属于虚拟机自身的一部分。另一部分就是所有其它的类加载器,这些类加载器是由Java语言实现,独立于JVM外部,并且全部继承抽象类java.lang.ClassLoader.
从java开发人员的角度看,大部分java程序会用到以下三种系统提供的类加载器:
- 启动类加载器(Bootstrap ClassLoader):负责加载JAVA_HOME\lib目录中并且能被虚拟机识别的类库加载到JVM内存中,如果名称不符合的类库即使在lib目录中也不会被加载。该类加载器无法被java程序直接引用。
- 扩展类加载器(Extension ClassLoader):该加载器主要负责加载JAVA_HOME\lib\ext目录中的类库,开发者可以使用扩展加载器。
- 应用程序类加载器(Application ClassLoader):该列加载器也称为系统加载器,它负责加载用户类路径(Classpath)上所指定的类库,开发者可以直接使用该类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
Tomcat中的类加载解决方案
Tomcat类加载的考虑
- 隔离性
Web应用类库相互隔离,避免依赖库或者应用包相互影响,比如有两个Web应用,一个采用了Spring 4,一个采用了Spring 5,而如果如果采用同一个类加载器,那么Web应用将会由于jar包覆盖而无法启动成功。 - 灵活性
因为隔离性,所以Web应用之间的类加载器相互独立,如果一个Web应用重新部署时,该应用的类加载器重新加载,同时不会影响其他web应用。
比如:不需要重启Tomcat的创建xml文件的类加载,
还有context元素中的reloadable字段:如果设置为true的话,Tomcat将检测该项目是否变更,当检测到变更时,自动重新加载Web应用。 - 性能
由于每一个Web应用都有一个类加载器,所以在Web应用在加载类时,不会搜索其他Web应用包含的Jar包,性能自然高于只有一个类加载的情况。
Tomcat中的类加载器
Tomcat提供3个基础类加载器(common、catalina、shared)和Web应用类加载器(每个WEB应用一个)。
Tomcat中的类加载源码分析
三个基础类加载器
3个基础类加载器的加载路径在catalina.properties配置,默认情况下,3个基础类加载器的实例都是一个commonClassLoader。
createClassLoader调用ClassLoaderFactory属于一种工厂模式,并且都是使用URLClassLoader。
可以通过修改配置创建3个不同的类加载机制,使它们各司其职。
举个例子:如果我们不想实现自己的会话存储方案,并且这个方案依赖了一些第三方包,我们不希望这些包对Web应用可见,因此我们可以配置server.loader(Catalina类加载器),创建独立的Catalina类加载器。
共享性:
Tomcat通过Common类加载器实现了Jar包在应用服务器与Web应用之间的共享,
通过Shared类加载器实现了Jar包在Web应用之间的共享
通过Catalina类加载器加载服务器依赖的类。
类加载工厂
因为类加载需要做很多事情,比如读取字节数组、验证、解析、初始化等。而Java提供的URLClassLoader类能够方便的将Jar、Class或者网络资源加载到内存中。而Tomcat中则用一个工厂类,ClassLoaderFactory把创建类加载器的细节进行封装,可以通过它方便的创建自定义类加载器。
使用加载器工厂的好处
- ClassLoadFactory有一个内部Repository,它就是表示资源的类,资源的类型用一个RepositoryType的枚举表示。
- 同时我们看到,如果在检查jar包的时候,如果有检查的URL地址的如果检查有异常就忽略掉,可以确保部分类加载正确。
尽早设置线程上下文类加载器
每一个运行线程中有一个成员ContextClassLoader,用于在运行时动态载入其他类,当程序中没有显示声明由哪个类加载器去加载哪个类,将默认由当前线程类加载器加载,所以一般系统默认的ContextClassLoad是系统类加载器。
一般在实际的系统上,使用线程上下文类加载器,可以设置不同的加载方式,这个也是Java灵活的类加载方式的体现,也可以很轻松的打破双亲委派模式,同时也会避免类加载的异常。
Webapp类加载器
每个web应用会对一个Context节点,在JVM中就会对应一个org.apache.catalina.core.StandardContext对象,而每一个StandardContext对象内部都一个加载器实例loader实例变量。这个loader实际上是WebappLoader对象。而每一个 WebappLoader 对象内部关联了一个 classLoader 变量(就这这个类的定义中,可以看到该变量的类型是org.apache.catalina.loader.WebappClassLoader)。
一个web应用会对应一个StandardContext 一个WebappLoader 一个WebappClassLoader 。
一个web应用对应着一个StandardContext实例,每个web应用都拥有独立web应用类加载器(WebappClassLoader),这个类加载器在StandardContext.startInternal()中被构造了出来。
热加载源码分析
当配置信息中有reloadable的属性,并且值为true时,打开热加载。

据Tomcat的启动流程,我们分析下Context的初始化start方法,Context只是一个接口,具体实现类是StandardContext,我们分析下startInternal方法(此方法由之前的骨架类中的start方法触发)
Tomcat性能优化
嵌入式Tomcat的优点
部署复杂度
如果按照传统部署,我们需要下载Tomcat,同时需要配置服务器,同时还需要修改端口,同时也要避免应用系统的jar包与服务器中存在的lib包的冲突,所有的这些都会增加部署的复杂度,并且这种配置大部分还是一次性的,不可重用。如果你遇到大规模的服务器集群环境(部署N多个应用)时,会增加我们的运维成本,如果按照嵌入式启动,这种方式几乎是一键式的,可以把以上问题轻松的解决。
架构约束
Tomcat启动的时候默认不单单只启动了HTTP协议,还有AJP协议等等,如果我们就只想简简单单的启动一个HTTP服务,同时不想启动那些多组件,可以使用嵌入式Tomcat,避免在部署启动时的架构约束。
微服务架构
现在微服务已经是主流的架构,其中微服务中每项服务都拥有自己的进程并利用轻量化机制实现通讯。这些服务都是围绕业务功能建立,可以自动化部署或独立部署。将微服务架构与Tomcat技术相结合,可以轻松将系统部署到云服务器上。当前SpringBoot支持的嵌入式服务器组件就是Tomcat.
嵌入式常用的配置
etConnector:用于设置链接器,包括协议、I/0、端口、压缩、加密等等。
setHost:用于设置Host
setBaseDir::用于设置临时文件的目录,这些目录用于存放JSP生成的源代码及Class文件
Tomcat性能优化
Tomcat自身提供的配置帮助文档,启动后在tomcat中找到。















 1034
1034











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









