







 本文深入解析了混淆矩阵的概念,包括真负类、假正类、假负类和真正类,以及如何通过混淆矩阵计算准确率、精准率、召回率和特异度等关键评估指标。同时,通过sklearn库的实例演示了混淆矩阵和评估指标的具体应用。
本文深入解析了混淆矩阵的概念,包括真负类、假正类、假负类和真正类,以及如何通过混淆矩阵计算准确率、精准率、召回率和特异度等关键评估指标。同时,通过sklearn库的实例演示了混淆矩阵和评估指标的具体应用。
混淆矩阵(Confusion matrix)
写博客之前在网上看了很多混淆矩阵的定义,说法各不一致,最后只好祭出了我的西瓜书。
混淆矩阵是判断分类好坏程度的一种方法。
另外还有ROC曲线和AUC曲线
1.概念
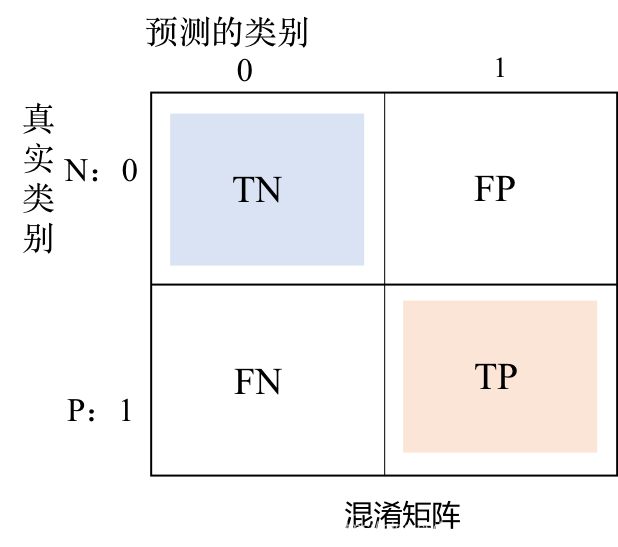
1)TN(True Negative):真负类,负类预测为负类(0->>0)
2)FP(False Positive):假正类,负类预测为正类(0->>1)
3)FN(False Negative):假负类,正类预测为负类(1->>0)
4)TP(True Positive):正类预测为正类(1->>1)
5)准确率:模型中所有判断正确的占总样本的比例
Accuracy=TP+TNTN+FP+FN+TP
Accuracy = \frac{TP+TN}{TN+FP+FN+TP}
Accuracy=TN+FP+FN+TPTP+TN
6)精准率:所有预测正类中,真实也是正类的比例
Precision=TPTP+FP
Precision = \frac{TP}{TP+FP}
Precision=TP+FPTP
7)召回率:所有真实正类中,预测也是正类的比例
Recall=Sensitivity=TPTP+FN
Recall =Sensitivity= \frac{TP}{TP+FN}
Recall=Sensitivity=TP+FNTP
8)特异度:所有真实负类中,预测为负类的比例
Specificity=TNTN+FP
Specificity = \frac{TN}{TN+FP}
Specificity=TN+FPTN
2.sklearn中的混淆矩阵
代码实现:
1)混淆矩阵(confusion_matrix)
y_test = [0, 1, 1, 0, 1, 1]
y_predict = [1, 0, 1, 0, 1, 0]
#构造混淆矩阵
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_predict)
print(cm)
#out
array([1, 1]
[2, 2])
2)精准率(precision_score)
#精准率
from sklearn.metrics import precision_score
ps = precision_score(y_test, y_predict)
print('精准率为:', '%.2f' % ps)# 2/(1+2)
#out
精准率为: 0.67
3) 召回率(recall_score)
#召回率
from sklearn.metrics import recall_score
rs = recall_score(y_test, y_predict)
print('召回率为:', '%.2f' % rs)# 2/(2+2)
#out
召回率为: 0.50

















 4883
4883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









