






计算机系统与基础
1.1.1 C语言程序举例
用“系统思维”分析问题
-2147483648<2147483647
(false)与事实不符?!why?
以下表达式如何呢?
int i=-2147483648
i<2147483647
true!why?
在变化一下
-2147483647-1<2147483647
结果怎么样?
第二个例子
sum(int a[],unsigend len)
{
int i,sum=0;
for(i=0;i<=len-1;i++)
sum+=a[i];
return sum;
}
当len=0时调用sum函数时,其返回值是多少?
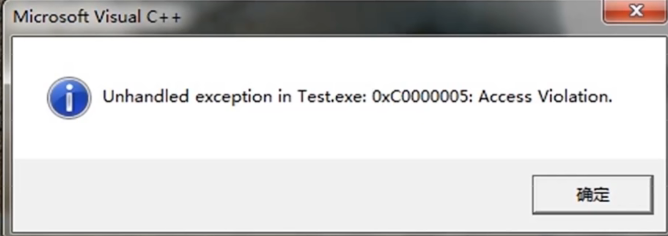
出现访存异常。但当len为int类型时,则正常。why?
若x和y为int类型,当x=65535时,y=x*x,y的值是多少?
y=-131071 why?
现实世界中,x^2>=0,但在计算机世界中不一定成立。
对于任何int类型变量x和y,(x>y)==(-x<-y)总成立吗?
当x=-2147483648,y任意(除-2147483648外)时不成立
why?


当count很大时,则count*sizeof(int)会溢出
int a=0x80000000;
int b=a/-1;
printf("%d\n",b);
运行结果为-2147483648
int a=0x80000000;
int b=-1;
int c=a/b;
printf("%d\n",c);
运行结果为"floatint point exception"
objdump 反汇编代码,得知除以-1被优化成取负指令neg,故未发生除法溢出
a/b用除法指令IDIV实现,但他不生成OF标志,那么如何判度溢出异常呢?实际上是除法错异常#DE,linux中,对#DE类型发出SIGFPE信号
编译器如何优化
#include<stdio.h>
main(){
double a=10;
printf("a=%d\n",a);
}
在IA-32上运行时,打印结果为a=0
在x86-64上运行时,带你出来的a是一个不确定之=值,为什么?
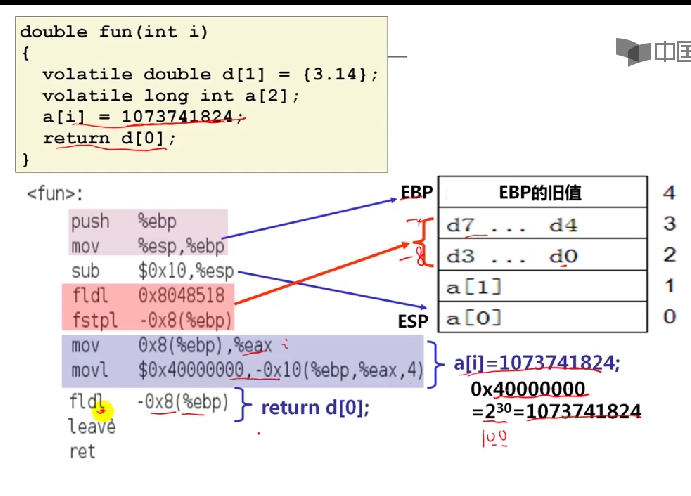
double fun(int i)
{
volatile double d[1]={3.14};
volatile long int a[2];
a[i]=1073741824;//Possibly out of bounds
return d[0];
}
对上述c语言函数,i=0~4时,fun(i)分别返回什么值?

两端复制代码

按照行优先或者列优先,时间复杂度完全一样,从算法复杂度看,两个都是完全等价的。但是执行效率大不相同!
左边的更加快

右边比左边多了一个赋值语句
#include "stdafx.h"
int main(int argc,char* argv[])
{
int a=10;
double *p=(double*)&a;
printf("%f\n",*p);//结果为0.000000
printf("%f\n,(double(a))");//结果为10.00000
return 0;
}
不是都是强制类型转化吗?怎么会不一样?
关键差别在于一条指令fldl和fildl
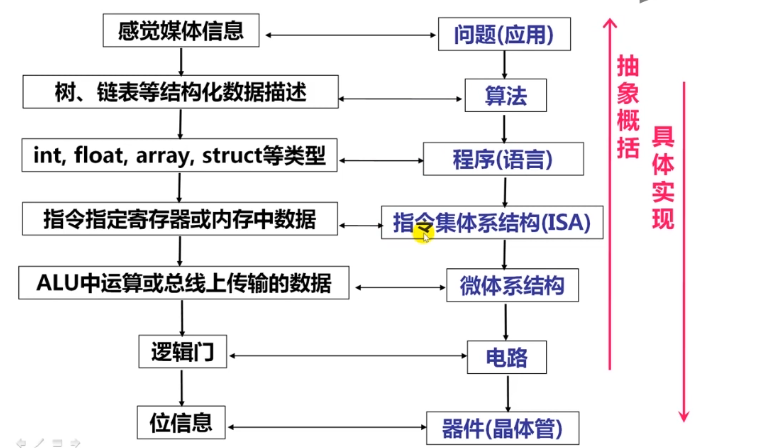
1.1.2为什么要学习计算机系统基础?
说明是计算机系统?
| 应用 |
|---|
| 算法 |
| 编程 |
| 操作系统 |
| 指令集体系结构(ISA) |
内容提要
目标:使学生清楚理解计算机是如何生成和运行可执行文件的。
'''数据的机器级表示、运算
语句和过程调用的机器级表示
操作系统、编译和链接的部分内容
cpu的通用结构
层次结构存储系统'''
1.2.1冯诺依曼结构主要思想
现代计算机的原型
存储程序:任何要计算机完成的工作都要先被编写成程序,然后将程序和原始数据送入主存并启动执行。一旦程序被启动,计算机应该能在不需操作人员干预下,自动完成逐条取出指令和执行指令的任务。
- 主存
- 自动逐条取出指令的过程
- 运算部件
- 程序由指令构成
- 指令描述如何对数据进行处理
- 应该有输入输出部件
- 计算机由运算器、控制器、存储器、输入设备、输出设备
- 存储器不仅能存放数据,而且存放指令。两者形式上没有任何区别。但计算机应能区分数据还是指令。
- 控制器应能自动取出指令来执行。
- 运算器能±/*,还有一些逻辑运算
- 操作人员可以通过输入设备和输出设备和主机进行通信
内部以二进制表示指令和数据。每条指令由操作码和地址吗。操作码指出操作类型,地址吗指出操作数的地址。有一串指令组成程序
存储程序
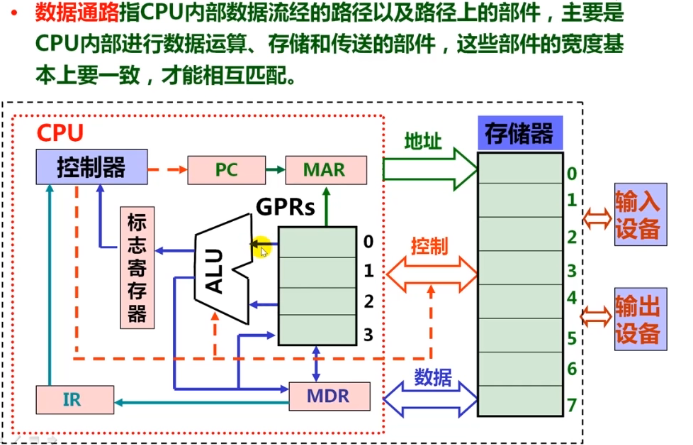
1.2.2现代计算机结构模型及工作原理
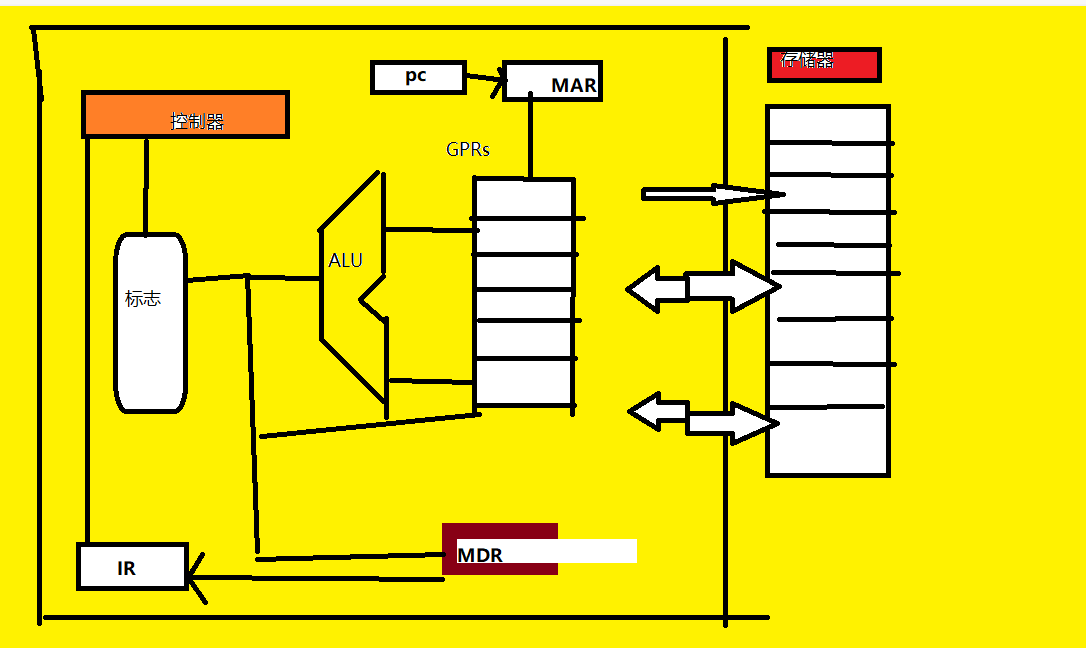
MAR (存储器地址寄存器)和MDR(存储器数据寄存器)与总线链接,相当于一个接口,IR(指令寄存器)
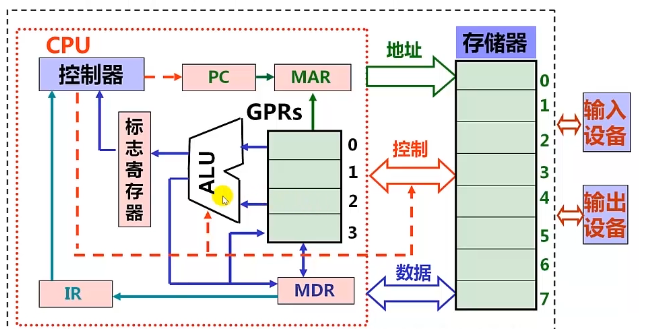
厨房:CPU,妈妈:控制器,盘子:GPRs,锅灶:ALU,架子:存储器
菜单也在存储器上
做菜前,我告诉妈妈从第五个架子(起始PC=5)指定菜谱开始做
开始做菜:
- 第一步:从5号架上取菜谱(根据pc取指令)
- 第二步:看菜谱(指令译码)
- 从架上或盘子中取原材料(取操作数)
- 洗、切、抄等具体操作(指令执行)
- 装盘(回写结果)
- 算出下一菜谱所在架子上6=5+1(修改PC的值)
1.3.1从高级语言到高级编程语言
需要将汇编语言转换成机器语言(用汇编程序转换)
机器语言和汇编语言都是面向机器结构的语言,故他们统称为机器级语言
1.3.2程序的开发和执行及其支撑环境
#include<stdio.h>
int main(){
printf("hello word\n");
}

1.4.1编程语言和计算机系统层次
1.4.2 现代计算机系统的层次结构
ISA:指令系统,是一种规约,它规定了如何使用硬件。可执行的指令的集合,包含指令格式、操作种类以及每种操作对应的操作数的相应规定
- 操作数的类型
- 每个寄存器的名称、编号、长度和用途
- 操作数所能存放的存储空间的大小和编制方式
- 操作数在存储空间存放时按照大端还是小端方式存放
- 指令获取操作数的方式,即寻址方式
- 指令执行过程的控制方式,包括程序计数器(PC),条件码定义等
计算机组成(微结构)
同一种ISA可以有不同的计算机组成,如乘法指令可用ALU或乘法器实现
不同ISA规定的指令集不同,如IA-32,MIPS,ARM
1.5.1 本课学习主要内容
int sum(int a[],unsigned len)
{
int i,sum=0;
for(i=0;i<len-1;i++)
sum+=a[i];
return sum;
}
int main(){
int a[1]={100};
int sum;
sum=sum(a,0);
printf("%d",sum);
}
- 数据的表示
- 数据的运算
- 各类语句的转化与表示(指令)
- 各类复杂数据类型的转换表示
- 过程(函数)调用的转换表示
计算机是如何生成和运行可执行文件的!
计算机是如何生成和运行可执行文件的!
- C语言程序设计层:数据的机器及表示、运算。语句和过程调用的机器级表示
- 指令集体系结构(ISA)和汇编层
- 微体系结构及硬件层
- 操作系统、编译和链接的部分内容
只用学习第一部分:计算机系统概述、数据的机器级表示与处理、程序的转换及机器级表示、程序的链接
2.1.1十进制数和二进制数
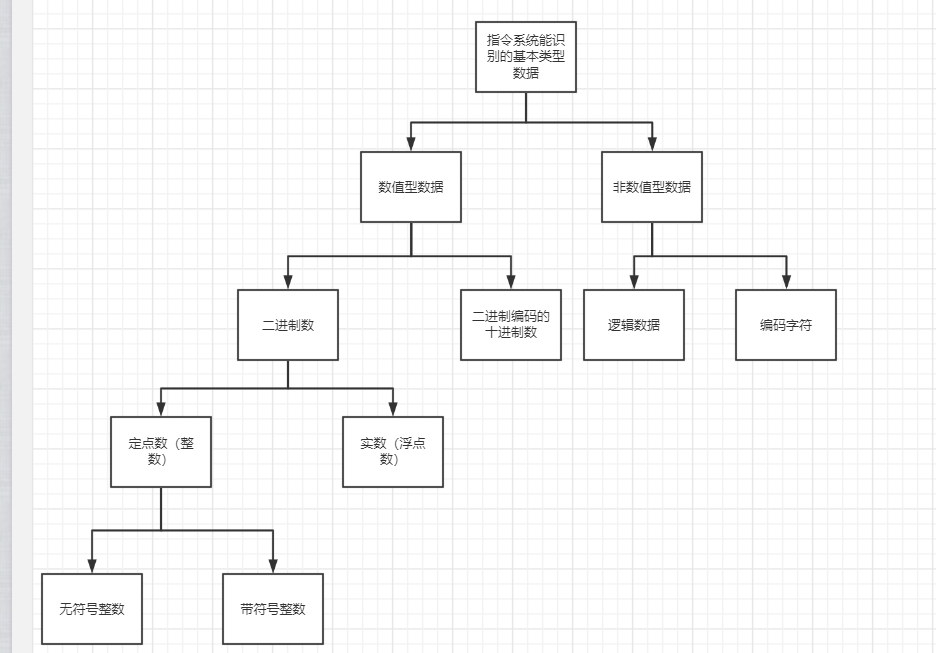
机器及数据分为两大类
- 数值数据:无符号整数、带符号整数、浮点数
- 非数值数据:逻辑数(包括位串)、西文字符和汉字
真值和机器数(非常重要的概念!)
机器数:编码以后的数,在机器里面,所有的数据都是0和1编码的序列
真值:真正的值,即现实中带正负号的数
unsigned short型变量x的真值是127,其机器数是多少?127=2^7-1即机器数是0000 0000 0111 1111
数值数据的表示
- 数值数据表示的三要数:
- 进位计数制:十进制、二进制、十六进制
- 定、浮点表示(解决小数点问题)定点整数、定点小数、浮点数(可用一个定点小数和一个定点整数来表示)
- 如何用二进制编码(解决正负号问题)原码、补码、反码、移码
2.1.2进制数之间的转换
八进制(用后缀“O”表示)
十六进制(用后缀“H”,或者前缀:”0x“表示)
二进制(用后缀”B“表示)
2 0 = 1 {2^0=1 } 20=1
2 1 = 2 {2^1=2 } 21=2
2 2 = 4 {2^2=4 } 22=4
2 3 = 8 {2^3=8 } 23=8
2 4 = 16 {2^4=16 } 24=16
2 5 = 32 {2^5=32 } 25=32
2 6 = 64 {2^6=64 } 26=64
2 7 = 128 {2^7=128 } 27=128
2 8 = 256 {2^8=256 } 28=256
2 9 = 512 {2^9=512 } 29=512
2 1 0 = 1024 {2^10=1024 } 210=1024
2 ( 11 ) = 2048 {2^(11)=2048 } 2(11)=2048
2 1 2 = 4096 {2^12=4096 } 212=4096
2 1 3 = 8192 {2^13=8192 } 213=8192
2 1 4 = 16384 {2^14=16384 } 214=16384
2 1 5 = 32768 {2^15=32768 } 215=32768
2 1 6 = 65536 {2^16=65536 } 216=65536
2 − 1 = 0.5 {2^-1=0.5 } 2−1=0.5
2 − 2 = 0.25 {2^-2=0.25 } 2−2=0.25
2 − 3 = 0.125 {2^-3=0.125 } 2−3=0.125
2 − 4 = 0.0625 {2^-4=0.0625 } 2−4=0.0625

可能小数部分总得不到0,此时得到一个近似值
说明:现实中的精确值可能在机器内部无法用0和1精确表示!
定点数和浮点数
- 计算机中只有0和1,数值数据中的小数点怎么表示呢?
- 计算中只能通过约定小数点的位置来表示
- 小数点位置约定在固定位置的数称为定点数
- 小数点位置约定为可浮动的数称为浮点数
- 计算中只能通过约定小数点的位置来表示
- 定点小数用来表示浮点数的尾数部分
- 定点整数用来表示整数,分带符号整数和无符号整数
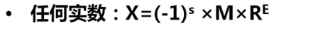
浮点数由定点小数和定点尾数表示滴(两个定点数表示一个浮点数)
2.2.1原码和移码表示
原码(Sign and Magnitude)表示
”正“号用0表示 ”负“号用1表示,数值部分不变!
| Decimal | Binary | Decimal | Binary |
|---|---|---|---|
| 0 | 0000 | -0 | 1000 |
| 1 | 0001 | -1 | 1001 |
| 2 | 0010 | -2 | 1010 |
| 3 | 0011 | -3 | 1011 |
| 4 | 0100 | -4 | 1100 |
| 5 | 0101 | -5 | 1101 |
| 6 | 0110 | -6 | 1110 |
| 7 | 0111 | -7 | 1111 |
- 容易理解,但是
- 0的表示不唯一
- 加减运算方式不统一
- 需额外对符号进行处理,故不利于硬件设计
- 特别当a<b,实现a-b比较困难
非常重要的一句话!贯穿始终!
从五十年代开始,整数都采用补码来表示,但浮点数的尾数用原码定点小数表示
###移码Excess(biased)notion
- 什么是移码表示?
- 将每一个数值加上一个偏执常数(Excess/bias)
- 通常,当编码位数为n时,bias取2^(n-1) or 2^(n-1)-1

0的移码表示唯一,当bias为2^(n-1)时,移码和补码仅第一位不同
移码用来表示浮点数的阶码?
便于浮点数加减运算时的对阶操作(比较大小)

2.2.2模运算系统和补码表示
补码-模(modular)运算
重要概念:在一个模运算系统中,一个数与他除以”模“后的余数等价
时钟是一种模12系统
结论1:一个负数的补码等于模减该负数的绝对值
结论2:对于某一确定的模。某数减去小于模的另一数,总可以用该数加上另一负数的补码来代替
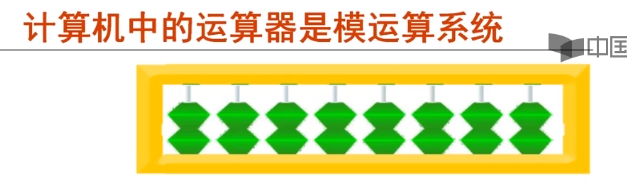

结论:一个负数的补码等于将对应正数补码各位取反,末位加一
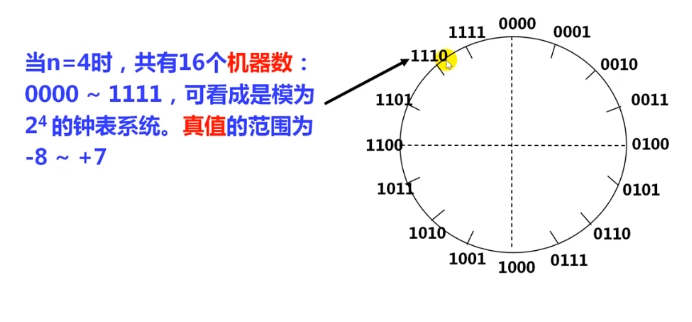
正数的补码是他本身

2.2.3补码和真值的对应关系
正数:符号位(sign bit)为0,数值部分不变
负数:符号位为1,数值部分各位取反,末位加一
求真值的补码
设机器数有b8位,求123和-123的补码表示
如何快速得到123的二进制表示?
123=127-4=0111 1111B - 100B=0111 1011B
“把符号位置1,即是-123的原码:11111011,其反码=00000100,补码=反码+1=00000101”
**负数:**对应的正数个位取反,末位+1:从右往左
遇到的第一个1的前面各位取反
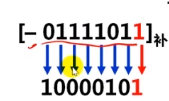
求补码的真值
- 例如:补码”11010110“的真值为-27 +26+24+22+2=-128+64+16+4=-42
- 例如:补码"01010110"的真值为-0*27+26+24+22+2=86
简便方法:
- 符号为0,则为正数,数值部分相同
- 符号为1,则为负数,数值各位取反,末位加1
补码”01010110“的真值为+1010110=64+16+4+2=86
补码”11010110“的真值为-0101010=-(32+8+2)=-42
2.3.1无符号整数和带符号整数
整数类型分为:无符号整数和带符号整数
无符号整数(unsigend integer)
- 机器中字的位排列顺序有两种方式:(例:32位字:0…01011(2))
- 无符号整数的编码没有符号位
- 能表示的最大值大于位数相同的带符号整数的最大值
带符号整数
-
计算机必须能处理正数和负数,用MSB表示数符(0–正数,1–负数)
-
有三种定点编码方式
- 原码 定点小数,用来表示浮点数的尾数
- 移码 定点整数,用来表示浮点数的阶
- 补码 50年代以来,所有计算机都用补码表示带符号整数
-
为什么用补码表示带符号整数?
-
若同时有无符号整数和带符号整数,则编译器将带符号整数强制转换为无符号数
-
无符号数无所谓原码、补码、反码
-
关系表达式 运算类型 结果 说明 0==0U 无 1 00…0B=00…0B -1<0 带 1 11…1<00…0 -1<0U 无 0* 11…1(232-1)>00…0(0) 2147483467>-2147483647-1 带 1 011…1(231-1)>100…0B(-231) 2147483647U>-2147483647-1 无 0 011…1(231-1)<100…0B(231) 2147483647>int(2147483648) 带 1 011…1(231-1)>100…0B(-231) -1>-2 带 1 11…1B(-1)>11…10B(-2) (unsigned)-1>-2 无 1 11…1B(232-1)>11…10B(232-2)
2.3.2C语言程序中整数举例
int x=-1;
unsigned u = 2147483648;
printf("x=%u=%d\n",x,x);
printf("u=%u=%d\n",u,u);
在32位机器上运行上述代码时,他的输出结果是什么?为什么?
x=4294967295=-1
u=2147483648=-2147483648
因为-1的补码整数表示为"11…1",作为32位无符号数解释时,其值为232-1=4 294 967 296-1=4294967295
231的无符号数表示为"100…0",被解释为329位带符号整数时,其值为最小负数:-232-1=-231=-2147483648
在某些32位系统上,C表达式-2147483648<2147483647的执行结果为false。why?(c90,左边的数会被解释为2147483648为unsigned int,-2147483648<2147483648按无符号整数比较,10…0>01…1)
int i=-2147483648,则i<2147483647的执行结果为true。why?
如果将表达式写成"2147483647-1<2147483647"
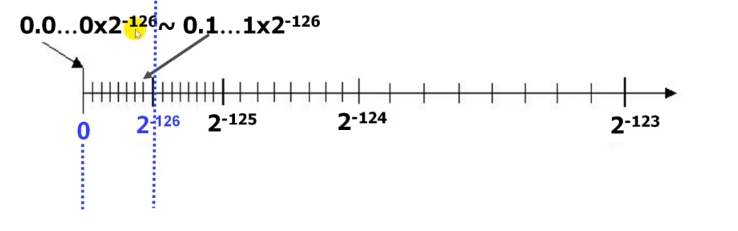
2.4.1浮点数的表示范围
- normalized(规格化形式):1.0*10-9唯一
- Unnormalized(非规格化形式):0.1*10-8

机器0:尾数为0或落在下溢区中的数
浮点数范围比定点数大,但数的个数没变多,故数之间更稀疏,且不均匀
2.4.2 IEEE754中规格化
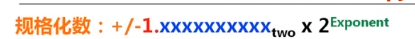

- Sign bit:1表示negative;0表示positive
- Exponent(阶码):全0和全1表示特殊值
- SP规格化阶码范围为0000 0001(-126)~1111 1110(127)
- bias(127)1+8+23,1023(double)—1+11+52

举例:机器数转换为真值
已知float型变量x的机器数为BEE00000H,求x的值是多少?
1011 1110 1110 0000 0000 0000 0000 0000
数字符号:1(负数)
阶(指数):
- 阶码:0111 1101=125 阶码的值:125-127=-2
尾数数值部分:
- 1+1x2-1+1x2-2=1.75
真值:-1.75x2-2=-0.4375
已知float型变量x的值为-12.75,求x的机器数是多少?
-12.75=-1100.11B=-1.10011Bx23
- 127+3=128+2=1000 0010
- 尾数部分:100110000000000000
2.4.3IEEE754特殊数的表示
0的机器数表示
exponent:all zeros
significand:all zeros
what about sign?Both cases valid
+0:0 0000 0000 000 0000 0000 0000 0000 0000
-1: 1 0000 0000 000 0000 0000 0000 0000 0000
+-无穷大
浮点数除0的结果是+/-无穷大,而不是溢出异常
为什么要这样处理?
- 可以利用+∞/-∞作比较。例如:X/0>Y可作为有效比较
- Exponent:all zeros(1111 1111=255)
- Significand:all zeros
- +∞:0 1111 1111 0000 0000 0000 0000 0000 000
- -∞:1 1111 1111 0000 0000 0000 0000 0000 000
非数的表示
Sqrt(-4.0)=? 0/0=?
- Exponent=255
- Significand:nonzero
非数可以帮助调试程序
非规格化数FP,还有一种情况没有定义
- Exponent0️⃣
- Significand:nonzero

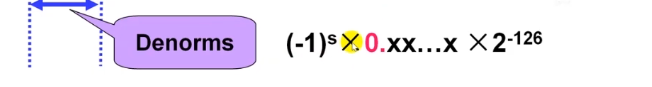
2.5.1非数值数据的表示
逻辑数据的编码表示
- 计算机何时用到逻辑数据?
- 表示关系表达式的中的逻辑值:真/假
- 表示
- 用一位表示,N位二进制数(位串)可表示N个逻辑数据
- 运算
- 按位进行。如,按位与/按位或/逻辑左移/逻辑右移
- 识别
- 逻辑数据和数值数据在形式上并无差别,也是遗传0/1序列,计算机靠指令来识别
2.6.1数据宽度和存储容量的单位
数据的基本宽度
-
比特(bit,位)是计算机中
-
二进制信息最基本的计量单位是字节(Byte)
- 现代计算机中,存储器按字节编址
- 字节是最小可寻址单位(addressable unit)
- 如果以字节为一个排列单位,则LSB表示最低有效字节,MSB表示最高有效字节
-
除比特和字节外,还经常使用字为单位。
-
字和字长的概念不同
数据的基本宽度
- 字和字长的概念不同
- 字长指数据通路的宽度
- 字长等于CPU内部总线的宽度、运算器的位数、通用寄存器的宽度(这些部件的宽度都是一样的)
- 字和字长的宽度可以一样,也可以不同。对于x86体系结构,不管字长多少,定义字的宽度都为16位,而从386开始字长就是32位了
2.7.1 数据存储时的字节排列
-
80年代开始,都采用字节编址
-
不同长度数据
-
一个基本数据可能会占用多个存储单元
-
变量的地址是其最大地址还是最小地址ffff fff6H
-
变量的地址是其最大地址还是最小地址?最小地址,即x存放在100#~103#
-
多个字节在存储单元中存放的顺序如何?
数据的存储和排列顺序
若int i=-65535,存放在100号单元(占100~103),则用“取数”指令访问100号单元,必须清楚i的4个字节是如何存放的。
65535=216-1=ffff 0001H
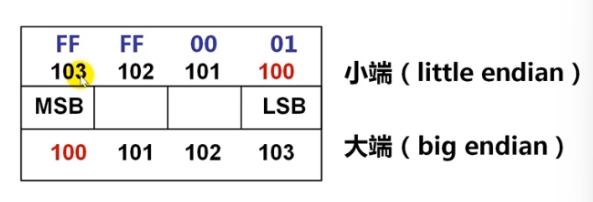
大端方式:MSB所在的地址是数的地址
小端方式:LSB所在的地址是数的地址
大端/小端方式举例
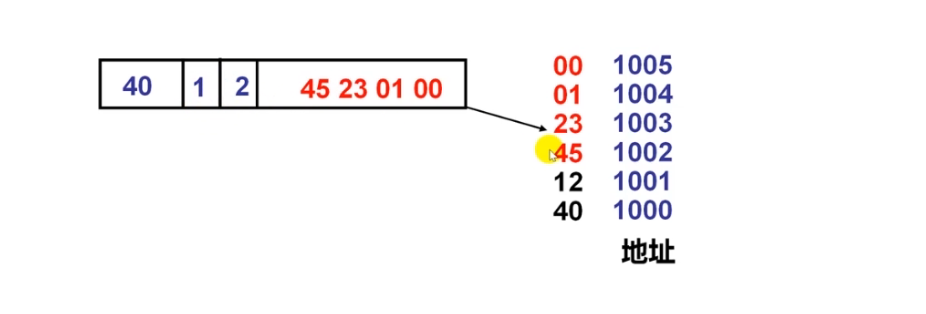
假定小端方式机器中某条指令的地址为1000
该指令的汇编形式为:mov AX,0x12345(BX)
其中操作码mov为40H,寄存器AX和BX的编号分别为0001B和0010B,立即数占32位,则存放顺序为:
- 以下是一个由反汇编器生成的一行针对IA-32处理器的机器级代码表示文本:
- 80483d2:89 85 a0 fe ff ff mov %eax,0xffff fea0(%ebp)
- 其中 80483d2是十六进制表示的指令地址
- 89 85 a0 fe ff ff是机器指令
- mov %eax,0xffff fea0(%ebp)是对应的汇编指令
- 0xffff fea0是立即数
请问:立即数0xffff fea0的值和存放地址分别是多少?IA-32是大端还是小端方式
- 立即数0x ffff fea0所存放的地址为0x80483d4
- 立即数0xffff fea0的值为-1011000B=-176
2.8.1布尔代数和基本逻辑电路
3.1.3 整数加减运算器和ALU
先看一个C程序段:
int x=9,y=-6,z1,z2;
z1=x+y;
z2=x-y;
- 上述程序段中,x和y的机器数是什么?z1和z2的机器数是什么?
- x的机器数为[x]补,y的机器数为[y]补
- z1的机器数为[x+y]补
- z2的机器数为[x-y]补
3.2.1从c表达式到逻辑电路
C语言程序中的基本数据类型、基本运算类型
- 基本数据类型
- 无符号数(二进制位串)、带符号整数(补码)
- 浮点数(IEEE754标准)
- 位串、字符串
- 基本运算类型
- 算数
- 安慰
- 逻辑
- 移位
- 扩展和截断
计算机如何实现高级语言程序中的运算
- 将各类表达式编译为指令序列
- 例如:y=(x>>2)+k转换为以下指令序列
- sarw $2,%ax; x>>2
- addw %bx,%ax ; (x>>2)+k
- 计算机直接执行指令来完成:控制器对指令进行译码,产生控制信号送运算电路
- 操作数在运算电路中运算
- sarw $2,%ax 将操作数“2”和R[ax]送移位器运算
- addw %bx,%ax:将R[ax]和R[bx]送整数加减器中运算
- 移位器和整数加减运算器都是由逻辑门电路构成的!
3.3.1C语言中的各类运算
-
算数运算(最基本的运算)
- 无符号数、带符号数、浮点数的±*/%运算等
-
按位运算
-
用途
-
操作
- 按位或“|”
- 按位与“&”
- 按位取反”~“
- 按位异或”^"
如何从数据y中提取低位字节,并使高字节为0?
-
-
移位运算
-
用途
- 提取部分信息
- 扩大或缩小2,4,8…倍
-
操作
-
左移:x<<k 右移:x>>k
-
从运算符无法区分逻辑移位还是算数,由x的类型确定
-
若x为无符号数,逻辑左(右)移
- 高(低)位移出,低(高)位补0,可能溢出!
- 问题:何时可能发生溢出,如何判度发生溢出?
- 若高位移出的是1,则左移时发生溢出
-
若x位带符号整数:算术左移、算数右移
- 左移:高位移出,低位补0.可能溢出!
- 溢出判度若移出的位不等于新的符号位,则溢出
- 右移:低位移出,高位补符,可能发生有效数据丢失
-
-
-
位扩展和位截断运算
-
用途
- 类型转换时可能需要数据扩展或截断
-
操作
- 没有专门操作运算符,根据类型转换前、后数据长短,确定是扩展还是截断
- 扩展:短转长
- 无符号数:0扩展(前面补0)
- 带符号整数:符号扩展(前面补符)
- 截断:长转短
-
short si=-32768;(80 00)
unsigned short usi=si;(80 00)
int i=si;(ff ff 80 00)
unsigned ui=usi;(00 00 80 00)
int i=32768;(00 00 80 00)
short si=(short)i;(80 00)
int j=si;(ff ff 80 00)
原因:对i截断时发生了溢出,即:32768截断为16位数时,因其超出16位能表示的最大值,故无法截断为正确的16位数!
3.4.1加减运算生成的指令
-
补码加减运算公式
- [A+B]补=[A]补+[B]补(MOD 2n)
- [A-B]补=[A]补+[-B]补(MOD2n)
-
所有运算电路的核心
- 计算机中所有运算都基于加法器实现!
- 加法器不知道所运算的是无符号数还是带符号数!
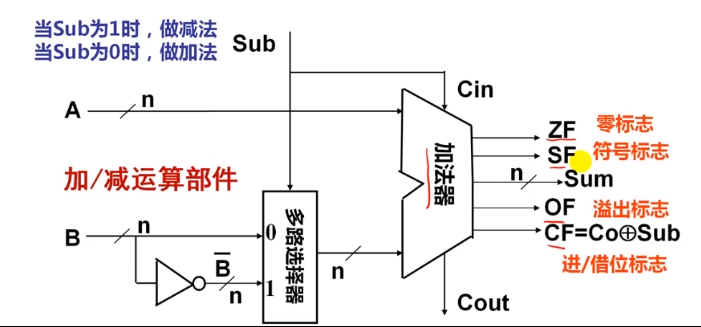
- 加法器不判定对错,总是取低n位作为结果,并生成标志信息
-
做加法时,主要判断是否溢出
- 无符号加溢出条件:CF=1
- 带符号加溢出条件:OF=1
- 若n=8,计算107+46=?
- 两个正数相加,结果为负数,故溢出!
- 无符号:sum=153,因为cf=0,故未发生溢出,结果正确!
- 带符号:sum=-103,因为of=1,故发生溢出,结果错误!
4.3.1浮点加减运算
- 阶码上溢:一个正指数超过了最大允许值
- 阶码下溢:一个负指数超过了最小允许值
- 尾数溢出:最高有效位有进位
- 非规格化尾数:数值部分高位为0
- 右规或对阶时,右端有效位丢失:尾数舍入
浮点数加法运算举例
例子:用二进制浮点数形式计算0.5+(-0.4375)=?
解:0.5=1.000x2-1 -0.4375=-1.110x2-2
- 对阶:-1.110x2-2 -0.111x2-1
- 加减:1.000x2-1+(-0.111x2-1)=0.001x2-1
4.3.2浮点运算的精度
附加位(Extra Bits)
IEEE754规定:中间结果须在右边加两个附加为(guard&round)
guard(保护位):在significand右边的位
round(舍入位):在保护位右边的位
附加位的作用:用以保护对阶时右移的位或运算的中间结果
附加位的处理:左规时被移到significand中,作为舍入的依据
举例
2.3400*102
0.0253*102
2.3653*102
问题:若没有舍入位,采用就近舍入到偶数,则结果是什么?
结果为2.36!精度没有2.37高!
IEEE754的舍入方式
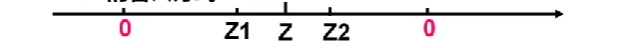
(1)就近舍入:舍入为最近可表示的数
非中间值:0舍1入
中间值:强迫结果为偶数

浮点数比较运算举例
int x;
float f;
double d;
x==(int)(float)x;//flase
x==(int)(double)x;//true
f==(float)(double)f;//true
d==(float)d;//false
f==-(-f);//true
2/3==2/3.0;//fasle
d<0.0 -> ((d*2)<0.0)//true
d>f -> -f>-d//true
d*d>=0.0 //true
x*x>=0 //false
(d+f)-d==f//false:大数吃小数
-
float型表示的范围有多大?
- 最大的数据:+1.11…1x2127 约为+3.4x1038
- 双精度:+1.8x10308
-
浮点数加法结合律是否正确呢?
- x=-1.5x1038,y=1.5x1038,z=1.0
- (x+y)+z=(-1.5x1038+1.5x1038)+1.0=1.0
- x+(y+z)=-1.5x1038+(1.5x1038+1.0)=0.0
4.3.3浮点运算精度举例
0.1的二进制表示是一个无限循环序列:0.00011[0011]…
x=0.000 1100 1100 1100 1100 1100B,显然x是0.1的近视表示,0.1-x

若x用float型表示,则x的机器数是什么?0.1与x的偏差是多少?系统运行100小时后 的时钟偏差是多少?在飞毛腿速度为2000米/秒的情况下,预测的距离偏差为多少
-
0.1=0.0 0011[0011]B=+1.1 0011 0011 0011 0011 0011 00B*2-4,故x的机器数为0 011 1101 100 1100 1100 1100 1100 1100
-
float型仅有24位有效位数,后面的有效位全被截断。故x与0.1之间的误差位:|x-0.1|=0.000 0000 0000 0000 0000 0000 0000 1100[1100]…B,这个值约等于2-240.1~~5.9610-9
-
若用32位二进制定点小数x=0.000 1100 1100 1100 1100 1100 1100 1101B表示0.1,则误差比用float表示误差更大还是更小?
- x-0.1=0.000 0000 0000 0000 0000 0000 0000 0000 00 1100[1100]…B,这个值等2-30*0.1
5.1.1程序和指令的关系
机器级指令
- 机器指令和汇编指令一一对应,都是机器级指令
- 机器指令是一个0/1序列,由若干字段组成
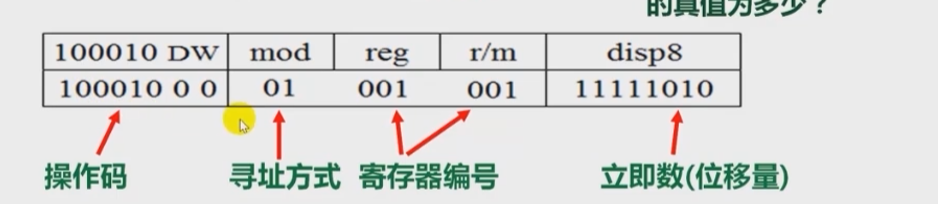
- mov[bx+di-6],cl或movb %cl,-6(%bx,%di)
- M[R[bx]+R[di]-6]<—R[cl]
GCC编译器套件进行转换的过程

- 预处理,在高级语言源程序插入所有用#include命令指定的文件和用#define声明指定的宏
- 编译:将预处理后的源程序文件编译生成相应的汇编语言程序
- 汇编:由汇编程序将汇编语言源程序文件转换为可重定位的机器语言目标代码文件
- 链接:由链接器将多个可重定位的机器语言目标文件以及库例程连接起来,生成最终的可执行目标文件
5.1.2目标代码和ISA

int add(int i,int j)
{
int x=i+j;
return x;
}
5.2.1Inter处理器概述
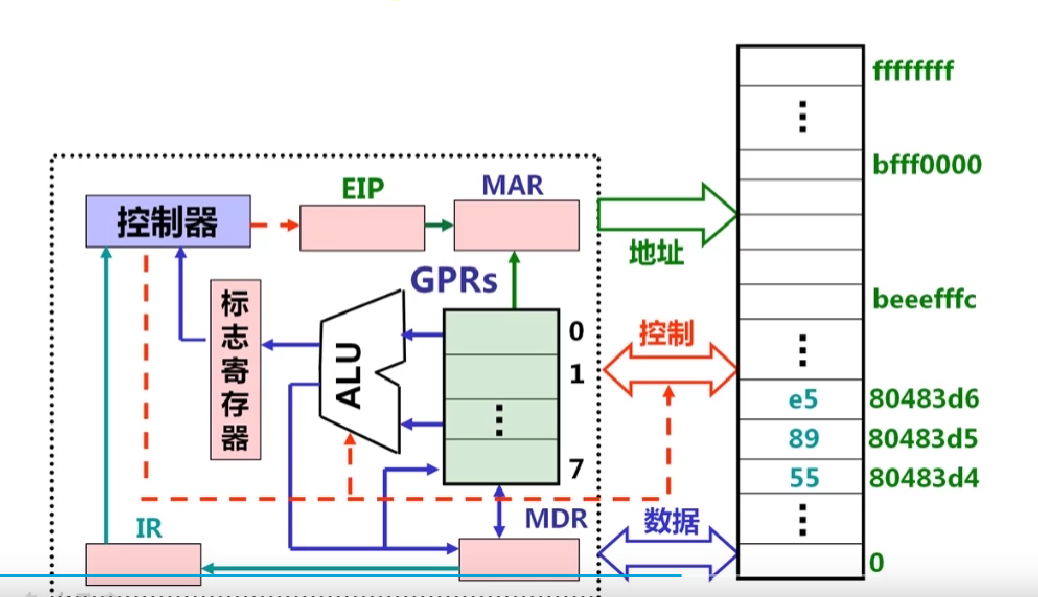
8个GPR(0~7),一个EFLAGS,PC为EIP
可寻址空间为4GB(编号为0~0xFFFF FFFF)
指令格式变长,操作码变长,指令由若干字段(OP、Mod、SIB等)组成
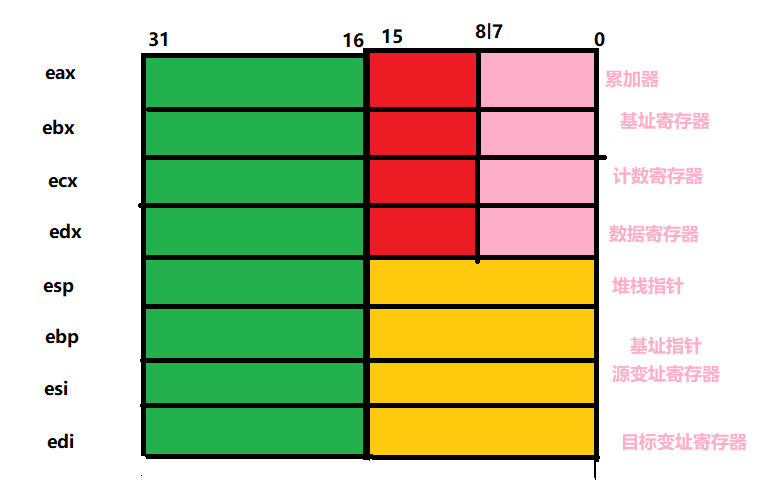
5.2.3 IA-32的寻址方式
- 寻址方式:如何根据指令给定信息得到操作数或操作数地址
- 操作数所在的位置
- 指令中:直接寻址
- 寄存器中:寄存器寻址
- 存储单元中(属于存储器操作数,按字节编址):其他寻址方式
- 存储器操作数的寻址方式与微处理器的工作模式有关
- 保护模式
保护模式下的寻址方式
| 寻址方式 | 说明 |
|---|---|
| 立即寻址 | 指令直接给出操作数 |
| 寄存器寻址 | 指定的寄存器R的内容为操作数 |
| 位移 | LA=(SR)+A |
| 基址寻址 | LA=(SR)+(B) |
| 基址+位移 | LA=(SA)+(B)+A |
| 比例变址+位移 | LA=(SR)+(I)XS+A |
| 基址+变址+位移 | LA=(SR)+(B)+(I)+A |
| 基址+比例变质加位移 | LA=(SR)+(B)+(I)XS+A |
| 相对寻址 | LA=(PC)+A |
LA:线性地址 SR:段寄存器 PC:程序计数器 R:寄存器 A:指令中给定地址段的位移量 B:基址寄存器 I:变址寄存器 S:比例系数
- SR寄存器(间接)确定操作数所在段的段基址
- 有效地址给出操作数所在段的偏移地址
5.2.4高级程序语言中寻址举例
存储器操作数的寻址方式
int x;
float a[100];
short b[4][4];//linux系统:double型变量按4B边界对齐
char c;
double d[10];//windows系统:double型变量按8B边界对齐
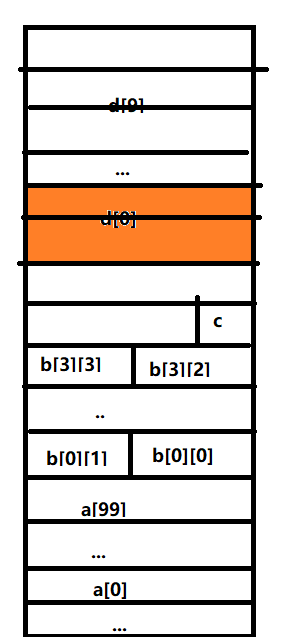
- a[i]的地址如何计算?104+i*4 ,i=99时,104+99x4=500
- b[i][j】的地址如何计算?504+ix8+j*2,i=3,j=2时 504+24+4=532
- d[i]的地址如何计算?544+ix8
- x、c:位移/基地址
- a[i]:104+ix4 ,比例变质+位移(基质)
- d【i】【j】:504+ix8+jx2 基质+比列变址+位移 movw 504(%ebp,%esi,2),%ax
5.2.5IA-32机器指令格式
6.1.1常用传送指令
传送指令
- 通用数据传送指令
- mov:一般传送,包括movb,movw和movl等
- movs:符号扩展传送:movsbw,movswl
- movz:零扩展传送 movzwl,movzbl
- push/pop:入栈,出战,pushl,pushw,popl,pop
- 地址传送指令
- lea:加载有效地址,如leal(%edx,%eax),%eax的功能为R[EAX]<-R[EDX]+R[eax],执行前R[edx]=i,R[eax]=j,则指令执行后,R[eax]=i+j
- 入栈
- 栈是高地址向低地址增长
-
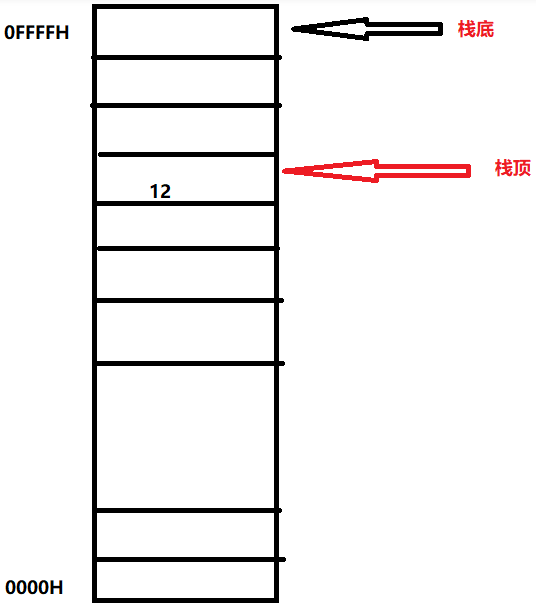
R[sp]=R[sp]-2 M[R[sp]]<-R[ax]

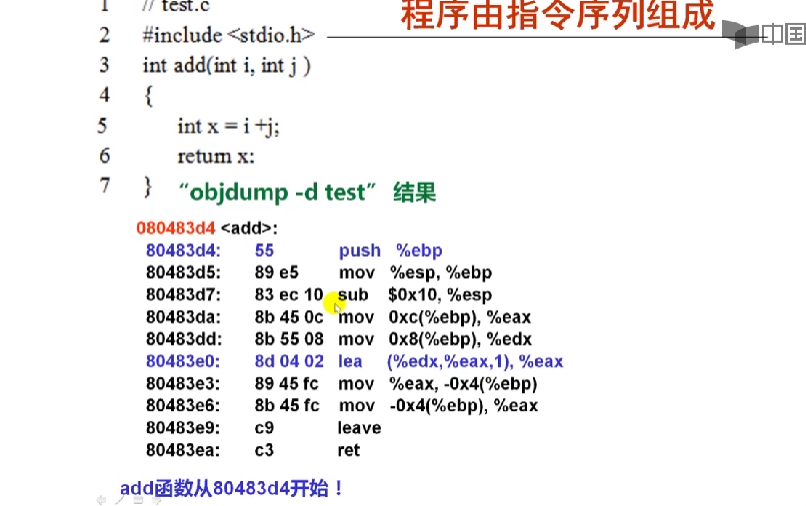
#include<stdio.h>
int add(int i,int j)
{
int x=i+j;
return x;
}
804834d: 55 push %ebp
80483d7: 89 e5 mov %esp,%ebp R[ebp]<-R[esp]
80483da: 83 ec 10 sub $0x10,%esp
80483dd: 8b 45 0c mov 0x8(%ebp),%eax
80483e0: 8d 04 02 lea (%edx,%eax,1),%eax R[eax]<-R[edx]+R[eax]
80483e3: 89 45 fc mov %eax,-0x4(%ebp),%eax
80483e9: c9 leave
80483ea: c3 ret
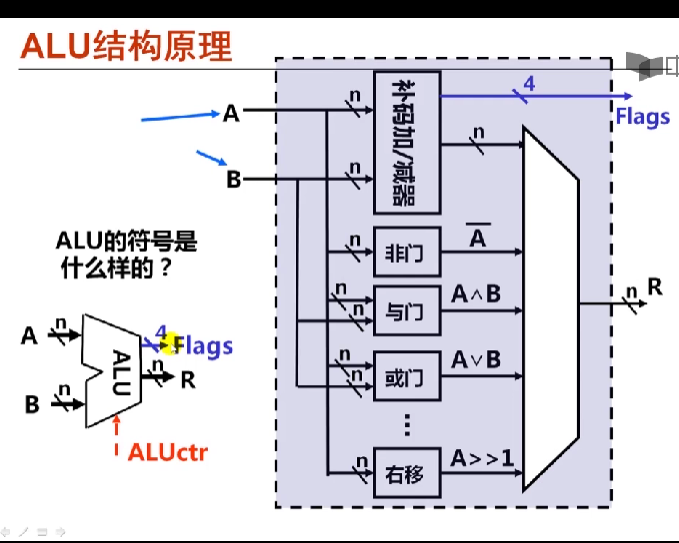
6.2.1常用定点运算指令
定点算数运算指令
-
包括a,加/减运算(影响标志、不区分无/带符号)
add:加,包括addb、addw、addl等(影响标志、不区分无/带符号)
-
增1/减1运算(影响除CF以外的标志、不区分无/带符号)
- inc:加,包括incb,incw,incl等
- dec:减,包括decb,decw,decl等
-
取负运算(影响标志、若对0取负,则结果为0且cf清零,否则CF置1)
-
比较运算(做减法得到标志、不区分无/带符号)
-
乘除运算(不影响标志,区分无/带符号)
6.2.2加法运算的底层实现举例
6.2.3加法指令和乘法指令举例
R[eax]=FFFAH,R[bx]=FFF0H,则执行以下指令后”addw %bx,%ax“
AX,BX中的内容各是什么?标志CF,OF,ZF,SF各是什么?要求分别将操作数作为无符号数和带符号数解释并验证指令执行结果
R【eax】《-R【ax】+R【bx】,指令执行后的结果如下R【ax】=FFFAH+FFF0H=FFEAH,BX中内容不变
CF=1,OF=0,ZF=0,SF=1
若是无符号整数运算,则CF=1说明结果溢出
验证:FFFA的真值为65535-5=65530,FFF0的真值为65515
FFEA的真值为65535-21=65514不等于65530+65515,即溢出
若是带符号整数运算,则OF =0说明结果没有溢出
验证:FFFA的真值为-6,FFF0的真值为-16
FFEA的真值为-22=-6+(-16),结果正确,无溢出
6.3.1逻辑运算和移位指令
按位运算指令
-
逻辑运算
- NOT:非,包括notb,notw,notl等
- AND:与,包括andb,andw,andl等
- OR:或,包括orb,orw,orl
- XOR:异或,包括xorb,xorw,xorl等
- TEST:做”与“操作测试。仅仅影响标志
仅仅not不影响标志,其他指令OF=CF=0,则ZF和SF则根据结果设置:若全0,则ZF=1,若最高位为1,则SF=1
-
移位运算(左/右移时,最高/最低位送CF)
- SHL,SHR:逻辑左/右移动,包括shlb,shrw,shrl等
- SAL/SAR:算术左/右移,左移判溢出,右移高位补符号 (移位前、后符号位发生变化,则OF=1)
- ROL/ROR:循环左/右移,包括rolb,rorw,roll等
- RCL/RCR:带循环左/右移,将CF作为操作数一部分循环移位
6.3.2按位运算指令举例
假设short型变量x被编译器分配在寄存器AX中,R[ax]=ff80H,则以下汇编代码执行后变量x的机器数和真值分别是多少?
- movw %ax,%dx R[dx]<-R[ax]
- salw $2,%ax 1111 1111 1000 0000 <<2 算术左移,OF=0
- addl %dx,%ax 1111 1110 0000 0000 +1111 1111 1000 0000
- sarw $1,%ax 1111 1101 1000 0000>>=1111 1110 1100 0000
//$2和$1分别表示立即数2和1
//x时short型变量,故都是算术移位指令,并进行带符号整数加
//上述代码执行前R[ax]=x,则执行((x<<2)+x)>>1后
//R[AX]=5X/2.算术左移时,ax中的内容在移位前、后符号未发生变换,故OF=0,没有溢出。最终ax的内容位FEC0H,解释为shrot型整数变量。其值位-320.
#include<stdio.h>
void main()
{
int a=0x8000 0000;
unsigned int b=0x8000 0000;
printf("a=0x%X\n",a>>1);
printf("b=0x%X\n",b>>1);
}
在对应机器及代码中,指令代码中是要区分算术移还是逻辑移
带符号是算术移位。无符号是逻辑移位
6.4.1条件转移指令举例
控制转移指令
- 指令执行可按顺序或跳转到转移目标指令处执行
- 无条件转移指令
- JMP DST
- 条件转移
- Jcc DST:cc为条件码,更具标志判断是否满足条件,若曼珠条件,则转移到目标指令DST处执行,否则按顺序执行
- 条件设置
- SET cc DST:按条件码cc判度的结果存到DST(是一个8位寄存器)
- 调用和返回指令(用于过程调用)
- CALL DST:返回地址RA入栈,转DST处执行
- RET:从栈中取回返回地址RA,转到RA处执行
- 无条件转移指令
| 指令 | 转移条件 | 说明 |
|---|---|---|
| jc label | cf=1 | 有进位/借位 |
| jnc label | cf=0 | 无进位/借位 |
| je/jz label | zf=1 | 相等/等于0 |
| jne/jnz label | zf=0 | 不相等/不等于0 |
| js label | sf=1 | 是负数 |
| jns label | sf=0 | 不是负数 |
| jo label | of=1 | 有溢出 |
| jno label | of=0 | 无溢出 |
| ja/jnbe label | cf=0 and zf=0 | 无符号整数A>B |
| jae/jnb label | cf=0 or zf=1 | 无符号整数A>=B |
| jb | 无符号整数a<b | |
| jbe | 无符号整数a<=b | |
| jg | 带符号整数a>b | |
| jge | 带符号整数a>=b | |
| jl | 带符号整数a<b | |
| jle | 带符号整数a<=b |
int sum(int a[],unsigned len)
{
int i,sum=0;
for(i=0;i<=len-1;i++)
sum+=a[i];
return sum;
}
subl $1,%edx
cmpl %edx,%eax
jbe .l3
6.4.2条件设置指令举例
unsigned long long
long long
unsgined
int
(unsigned) char
(unsigned) short
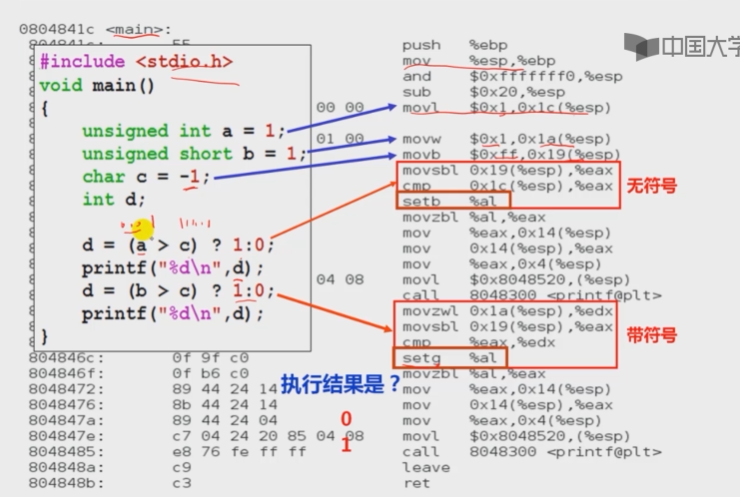
#include<stdio.h>
void main()
{
unsigned int a=1;
unsigned short b=1;
char c =-1;
int d;
d=(a>C)?1:0;
printf("%d\n",d);
d=(b>C)?1:0;
printf("%d\n",d);
}
6.5.1x87FPU常用指令
IA32浮点处理架构
- IA-32的浮点处理架构有两种
- x87fpu指令集(gcc默认)
- SSE指令集(x86-64架构所用)
- IA-32中处理的浮点数有三种类型
- float类型:32位IEEE754单精度格式
- double类型:64位IEEE754双精度格式
6.5.2 x87浮点处理指令举例

double f(int x)
{
return 1.0/x;
}
fld1:将常数1.0压入栈顶ST(0)
fidivl:将指定存储单元操作数M[R[ebp]+8]中的int型数据转换为double型,再将ST(0)除以该数,并将结果存入到ST(0)中
6.6.1MIMX及SSE指令集
- 由MMX(多媒体扩展)发展而来的SSE架构
- MMX指令使用8个64位寄存器MM0~ MM7,借用8个80位寄存器ST(0)~ST(7)中64位位数所占的位,可同时处理八个字节,或四个字,或两个双字,或一个64位数据,是一种SIMD技术
- SSE指令集将80位浮点寄存器扩充到128位多媒体扩展通用寄存器XMM0~XMM7,可同时处理16个字节,或八个字,或四个双字(32位整数或单精度浮点数)。或两个四个的数据
7.1.1过程调用概述
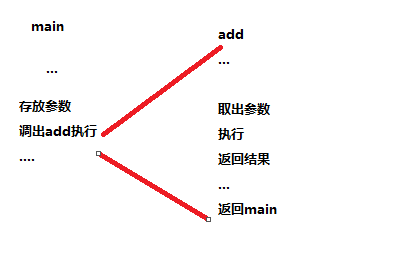
int add(int x,int y)
{
return x+y;
}
int main()
{
int t1=125;
int t2=80;
int sum=add(t1,t2);
return sum;
}
-
main是调用函数,调用了add,那么add函数执行的结果如何返回给caller(main)
-
-
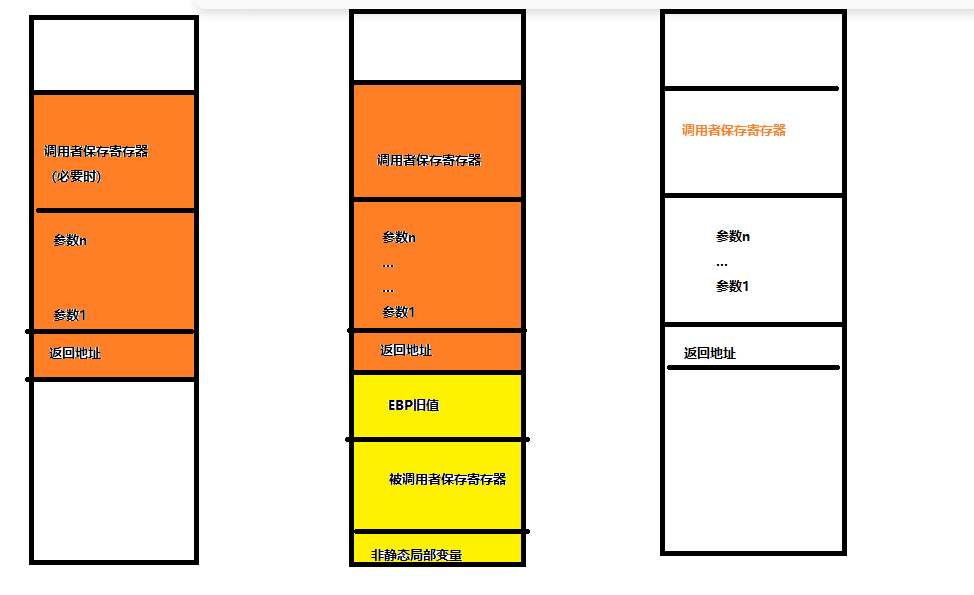
过程调用的步骤(p为调用者,q为被调用者 )
- p将入口参数(实参)放到q能访问到的过程(p过程)
- p保存放回地址,然后将控制转移到q;call指令(p过程)
- q保存p的现场,并为自己的非静态局部变量分配空间
- 执行q的过程
- q回复p的 现场,释放局部变量空间
- q取出返回地址,将控制转移到p
-
IA-32的寄存器使用约定
- 调用者p保存寄存器:EAX,EDX,ECX
- 被调用者q保存寄存器:EBX,ESI,EDI
7.1.2过程的机器代码结构
过程调用例子(p->caller->add)
int add(int x,int y)
{
return x+y;
}
int caller()
{
int t1=125;
int t2=80;
int sum=add(t1,t2);
return sum;
}
caller:
pushl %ebp
movl %esp,%ebp
subl $24,%esp
movl $125,-12(%ebp)
movl $80,-8(%ebp)
movl -8(%ebp),%eax
movl %eax,4(%esp)
movl -12(%ebp),%eax
movl %eax,(%esp)
call add
movl %eax,-4(%ebp)
movl %eax,-4(%ebp)
leave
ret
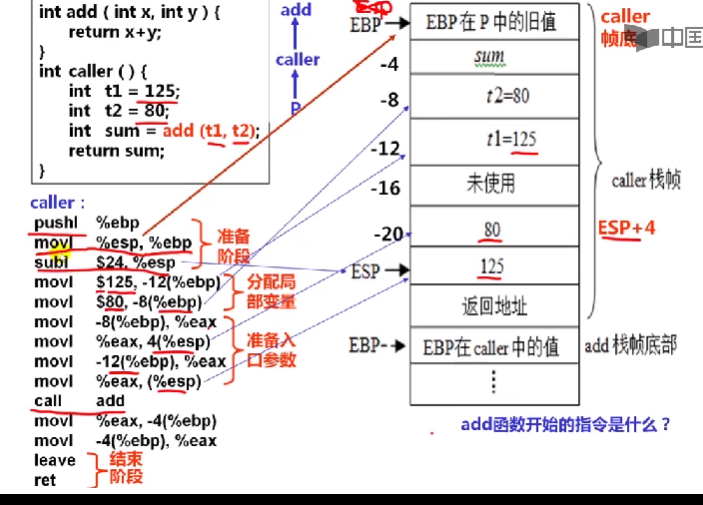
执行完add指令后,有一个返回,这个返回参数总是在EAX里面。
call指令总是把下一条指令的地址压倒栈里面
所以返回地址实际上是movl指令的地址
add的ret指令会把返回地址的指令取过来送到EIP寄存器里面
一个c过程的大致结构如下:
- 准备阶段
- 形成栈底:push指令和mov指令
- 生成栈帧:sub指令或and指令
- 保存现场(如果有被调用者保存寄存器):mov指令
- 过程
- 分配局部变量,并赋值
- 具体处理逻辑,如果遇到函数调用时
- 准备参数:将实参送栈帧入口参数处
- call指令:保存返回地址并转被调用函数
- 在EAX中准备返回参数
- 结束阶段
- 退栈:leave指令或pop指令
- 取返回地址返回:ret指令
7.1.3过程调用的参数传递
入口参数的位置
movl 参数3,8(%esp)
movl 参数2,4(%esp)
movl 参数1,(%esp)
call add R[esp]<-R[esp-4] M[R[esp]]<-返回地址 R[eip]<-add函数首地址
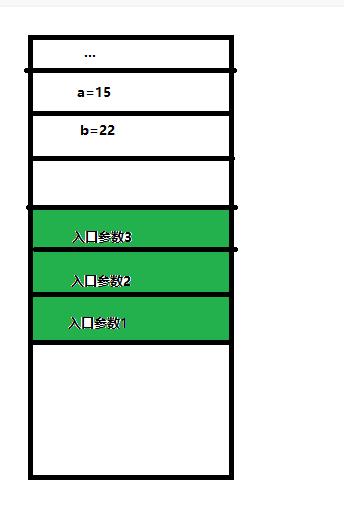
返回地址是什么?call指令的下一条指令的地址!
IA-32中,若参数类型是unsigned char,char或 unsigned short,short也都分配4个字节
故在被调用函数中,使用R[ebp]+8,R[ebp]+12,R[ebp]+16作为有效地址来访问函数的入口参数

7.1.4过程调用举例
void test(int x,int *ptr)
{
if(x>0 && *ptr>0)
*ptr+=x;
}
void caller(int a,int y)
{
int x=a>0?a:a+100;
test(x,&y);
}
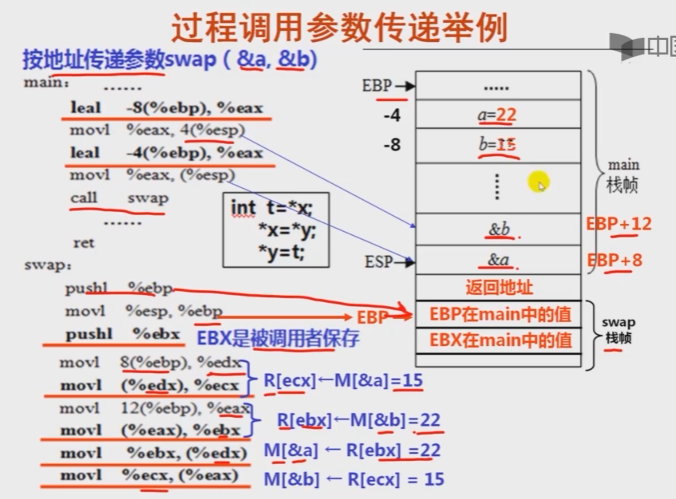
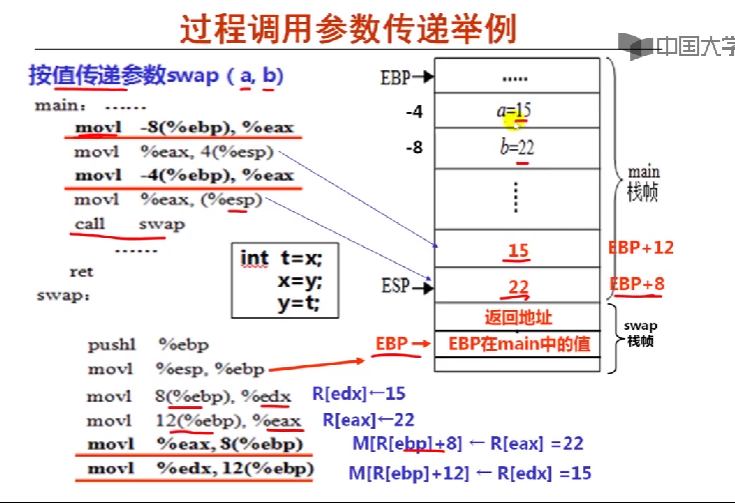
调用call的过程为p,p中给出形参a和y的实参分别是100和200,画出相应栈帧中的状态,并回答下列问题
(1)test的形参是按值传递还是按地址传递?test的形成ptr对应的实参是一个什么类型的值?
(2)test中被改变的*ptr的结果如何返回给他的调用过程caller?
(3)caller中被改变的y的结果能否返回给过程p?为什么?
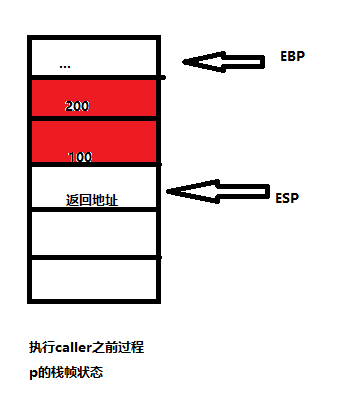
从右往左压实参
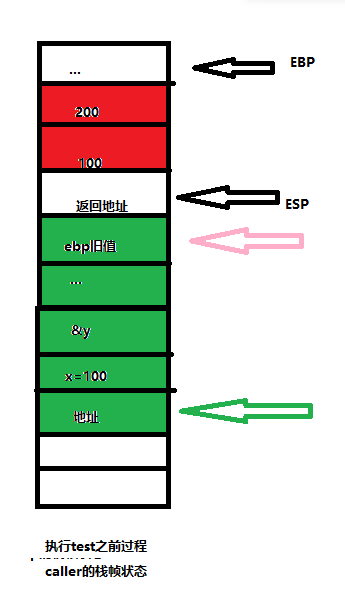
7.1.5递归过程调用举例
int nn_sum(int n)
{
int result;
if(n<=0)
retult=0;
else
return n+nn_sum(n-1);
return result;
}
p—>nn_sum(n)—>nn_sum(n-1)
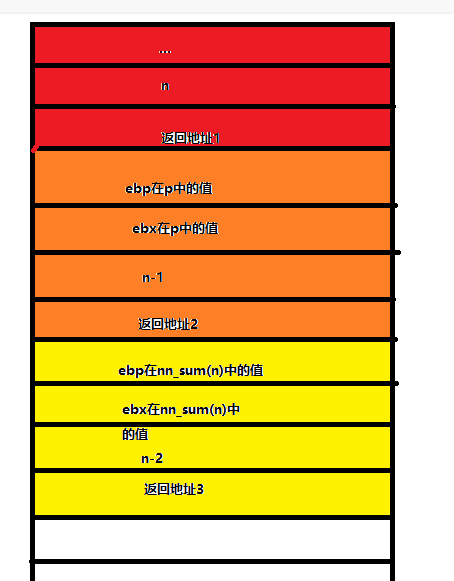
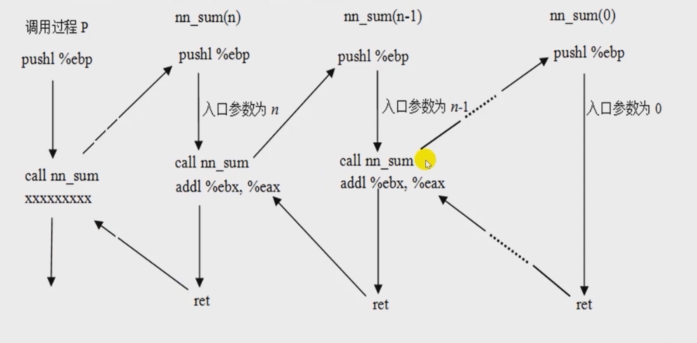
7.1.6过程调用举例
double fun(int i)
{
volatile double d[1]={3.14};;
volatile long int a[2];
a[i]=1073741824;
return d[0];
}
7.2.1选择结构的机器级表示
选择结构的机器级表示
int get_cont(int *p1,int *p2){
if (p1 > p2)
return *p2;
ekse
return *p1;
}
movl 8(%ebp),%eax R[eax]<---M[R[ebp]+8
movl 12(%ebp),%edx R[edx]<---M[R[ebp]+12]
cmpl %edx,%eax 比较p1和p2,则根据p1-p2结果置标志
jbe .L1 若p1<=p2,则转L1执行
movl (%edx),%eax R[eax]<--M[R[edx]],即R[eax]=M[p2]
jmp .L2 无条件跳转到L2执行
.L1:
movl (%eax),%eax R[EAX]<-M[R[eax]],即R[eax]=M[p1]
.L2:

7.2.2循环结构的机器级表示
int nn_sum(int n)
{
int i;
int result=0;
for (i=1;i<=n;i++)
result+=i;
return result;
}
movl 8(%ebp),%ecx
movl $0,%eax
movl $1,%edx
cmpl %ecx,%edx
jg .L2
.L1:
addl %edx,%eax
addl $1,%edx
cmpl %ecx,%edx
jle .L1
.L2
i和result分别分配在EDX和EAX中,通常复杂局部变量被分配在栈中,而这里是简单变量
注意一下cmp指令是操作对象-操作对象1
逆向工程举例
int function_test(unsigned x)
{
int result=0;
int i;
for(___;___;___;)
{
___________;
}
return result;
}
movl 8(%ebp),%ebx//R[ebx]=x
movl $0,%eax//R[eax]=0 result
movl $0,%ecx//R[ecx]=0 i
.L12:
leal (%eax,%eax),%edx //R[eax]+R[eax]=R[edx] *2相当于左移一位
movl %ebx,%eax // R[eax]=R[ebx]=x
andl $1,%eax//R[eax]与1相与
orl %edx,%eax//R[eax] or R[edx]
shrl %ebx//R[ebx]>> x逻辑右移1位,无符号整数采用的一定是逻辑右移 高位补符
addl $1,%ecx//R[ecx]+1=R[ecx] i++
cmpl $32,%ecx//R[ecx] 32
jne .L12//循环变量?i/=32
8.1.1数组的访问与分配
假定数组A的首地址存放在EDX中,i存放在ECX中,先要将A[i]取到AX中,则所用的汇编指令是什么?
movw 0(%edx,%ecx,2) %ax
int buf[2]={10,20};
int main()
{
int i,sum=0;
for(i=0;i<2;i++)
sum+=buf[i];
return sum;
}
buf是在静态区分配的数组,链接后,buf在可执行目标文件的数据段中分配了空间
08048908:
08048908:0A 00 00 00 14 00 00 00
此时,buf=&buf[0]=0x08048908
编译器通常将其存放在寄存器如(edx中)
假定i被分配在ecx中,sum被分配在eax中,则sum+=buf[i]和i++可以用什么指令实现?
addl 0(%edx,%ecx,4), %eax
addl buf(,%ecx,4) %eax
addl $1,%ecx
auto型数组的初始化和访问
int adder()
{
int buf[2]={10,20};
int i,sum=0;
for(i=0;i<2;i++)
sum+=buf[i];
return sum;
}
分配在栈中,故数组首地址通过ebp来定位
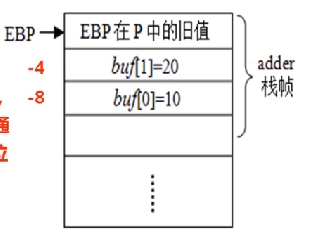
movl $10,-8(%ebp)
movl $20,-4(%ebp)
leal -8(%ebp),%edx
addl (%edx,%ecx,4) %eax
8.1.2数组与指针的关系
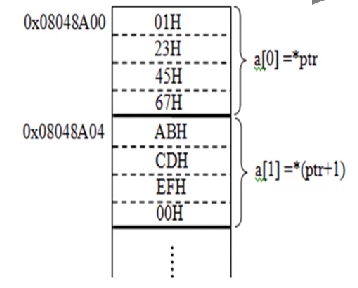
int a[10];
int *ptr=&a[0];
int a[10],*ptr;
prt=&a[0];
以下两个程序段功能完全相同,都是使ptr指向数组a的第0个元素a[0].a的值就是其首地址即a=&a[0],因而a=ptr,从而与&a[i]=prt+i=a+i以及a[i]=ptr[i]= * (ptr+i)= *(a+i)
a[0]=0x67452301 a[1]=0x00efcdab
数组与指针
假定数组A的首地址SA在ecx中,i在edx中,表达式结果在eax中
| 序号 | 表达式 | 类型 | 值的计算方式 | 汇编代码 |
|---|---|---|---|---|
| 1 | A | int * | SA | leal(%ecx),%eax |
| 2 | A[0] | int | M[SA] | movl (%ecx),%eax |
| 3 | A[i] | int | M[SA+4*i] | movl (%ecx,%edx,4) %eax |
| 4 | &A[3] | int* | SA+12 | leal 12(%ecx),%eax |
| 5 | &A[i]-A | int | (SA+4*i-SA)/4=i | movl %edx,%eax |
| 6 | *(A+i) | int | M[SA+4*i] | movl (%ecx,%edx,4) %eax |
| 7 | *(&A[0]+i-1) | int | M[SA+4*i-4] | movl -4(%ecx,%edx,4)%eax |
| 8 | A+i | int* | SA+4*i | leal (%ecx,%edx,4) |
8.1.3指针数组和多维数组
- 指针数组和多维数组
- 由若干指向同类目标的指针变量组成的数组称为指针数组
- 其定义的一般形式如下
- 例如 int *a[10],定义了一个指针数组a,他有10个元素,每个元素都是一个指向int型数据的指针。
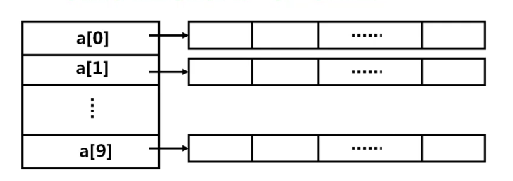
main()
{
static short num[][4]={{2,9,-1,5},
{3,8,2,-6}};
static short *pn[]={num[0],num[1]};
static short s2={0,0};
int i,j;
for(i=0;i<2;i++)
for(j=0;j<4;j++)
s[i]+=*pn[i]++;
printf("sum of line %d:%d\n",i+1,s[i]);
}
若num=0x8049300,则num,pn和s在存储区中如何存放?
08049300
08049300:02 00 09 00 ff ff 05 00 03 00 08 00 02 00 fa ff
08049310:
08049310:00 93 04 08 08 93 04 08
08049318:
08049318:00 00 00 00
若处理"s[i]+=*pn[i]++"时i在ecx,s[i]在AX,pn[i]在edx,则对应指令序列可以是什么
movl pn(,%ecx,4), %edx
addw (%edx),%ax
addl $2,pn(,%ecx,4)
8.2.1结构类型的分配和访问
- 结构体成员在内存的存放和访问
- 分配在栈中的auto结构变量的首地址由ebp和esp来定位
- 分配在静态区的结构型变量首地址是一个确定的静态区地址
- 结构性变量x各成员首地址可用基址+偏移量的寻址方式
struct cont_info{
char id[8];
char name[12];
unsigned post;
char address[100];
char phone[20];
};
结构体数据作为入口参数
void stu_phone1(struct cont_info *s_info_ptr)//按地址调用stu_phone1(&x)
{
printf("%s phone number:%s",(*s_info_ptr).name,(*s_info_ptr).phone);
}
void stu_phone2(struct cont_info s_info)//按值调用 stu_phone(x)
{
printf("%s phone number :%s",s_info.name,s_info.phone);
}
- 当结构体变量需要作为一个函数的形参时,形参和调用函数中的实参应该具有相同结构
- 若采用按值传递,则结构成员都要复制到栈中参数去,这即增加时间开销和空间开销,且更新后的数据无法再调用过程使用
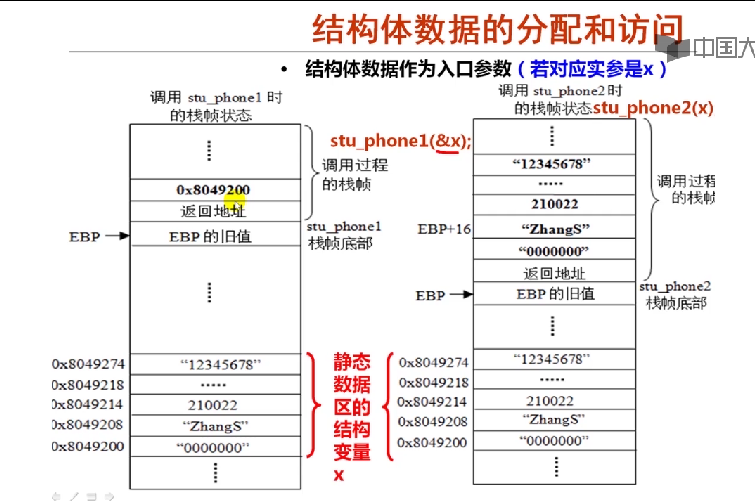
- 按地址传递参数 stu_phone(&x);
- (*stu_info_ptr).name可以写成stu_info_ptr->name
- 执行以下两条指令后 movl 8(%ebp),%edx leal 8(%edx),%eax eax存放的是字符串”zhangs"在静态存储区的 首地址时0x8049208
8.2.2联合体型的分配与访问
联合体各成员共享存储空间,按最大长度成员所需空间大小为准
union uarea{
char c_data;
short s_data;
int i_data;
long L_data;
}
在IA-32中编译时,long和int长度一样,故uarea所占空间为4个字节。而对于uarea有相同成员的结构型变量来说,其占用空间大小至少有11个字节,对齐的话则占用更多
unsigned
float2unsign(float f)
{
union{
float f;
unsigned u;
}tmp_union;
tmp_union.f=f;
return tmp_union.u;
}
//进来的时float类型,出去的时候是unsigned类型
//对相同01序列进行不同数据类型的解释

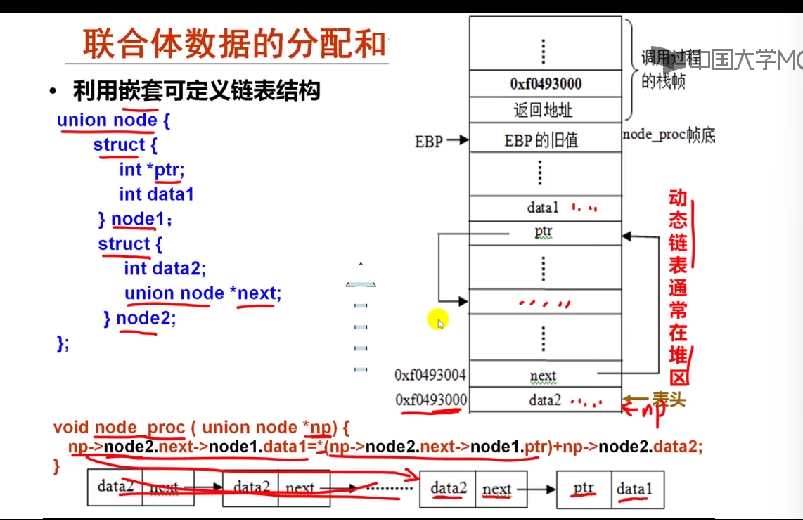
利用嵌套可定义链表结构
union node{
struct{
int *ptr;
int data1;
}node1;
struct{
int data2;
union node*next;
}node2;
}
8.3.1数据的对齐方式
- 目前机器字长为32位或64位,主存按一个传送单元(32/64/128位)进行存取,而按字节编址,例如:若传送单元为32位,则每次最多读写32位,即:第0~3字节同时读写,第4 ~7字节同时读写,…,以此推类。按边界对齐
- 指令系统支持对字节、半字、字及双子等的运算
若一个字=32位,主存每次最多存取一个字,按字节编个字节址,则每次只能读写某个字地址开始的4个单元中连续的1,2,3或4个字节
-
最简单的对齐策略:按其数据长度进行对齐
- windows:int型地址是4的倍数,short型地址是2的倍数,double和longlong是8的倍数 float是4的倍数 char不对齐
- linux非常宽松,short是2的倍数,其他类型如int,float double和指针都是4的倍数
-
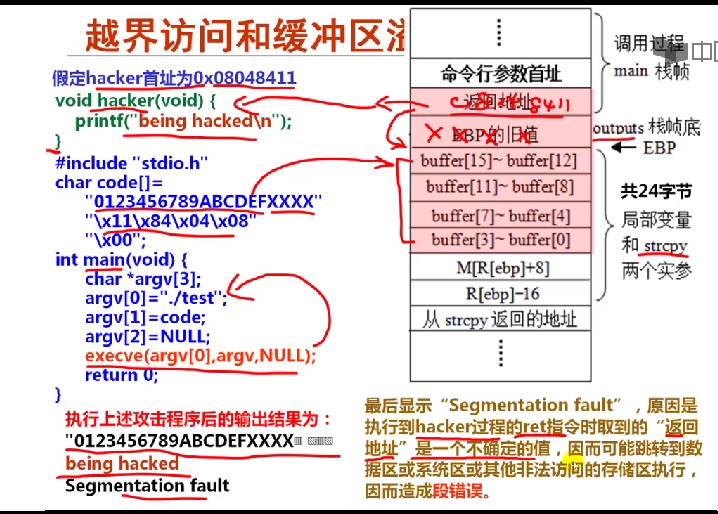
struct SD{ int i; short si; char c; double d; } //结构体变量按4字节边界对齐8.4.1越界访问和缓冲区溢出攻击
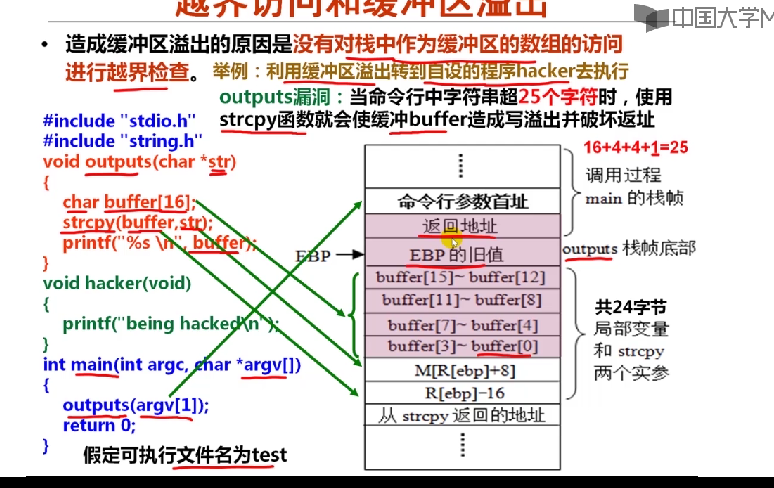
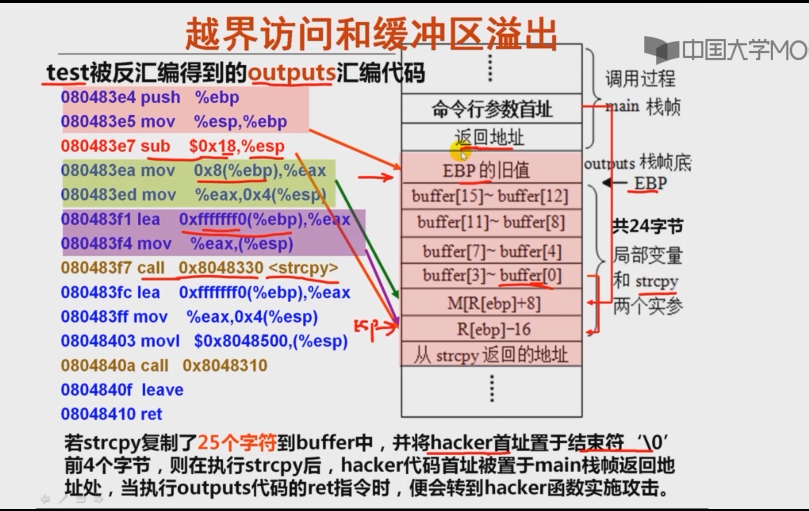
- 数据存储区可以看成是一个缓冲区,超越数组存储区范围的写入操作称为缓冲区溢出
- 造成缓冲区溢出的原因是没有对栈中作为缓冲区的数组的访问进行越界检查。举例:利用缓冲区溢出转到自设的程序hacker去执行
#incldue "stdio.h" # include "string.h" void outputs(char *str) { char buffer[16];//分配在栈中 strcpy(buffer,str); printf("$s\n",buffer); } void hacker(void) { printf("being hacked\n"); } int main(int argc,char *argv[]) { outputs(argv[1]); return 0; }
程序的加载和运行
10.1.1可执行文件生成概述
10.1.2链接器的由来
- 函数起始地址和变量其实地址是符号定义(definition)
- 调用子程序(函数或过程)和使用变量即是符号的引用
- 确定符号引用关系(符号解析)
- 合并相关.o文件
- 确定每个符号的地址
- 在指令中填入新地址
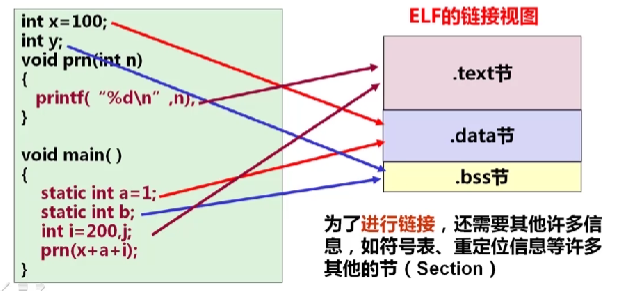
10.2.1链接过程的本质
int buf[2]={1,2};
void swap();
int main()
{
swap();
return 0;
}
swap.c
extern int buf[];
int *bufp0=&buf[0];
static int *bufp1;
void swap()
{
int temp;
bufp1[]=&buf[1];
temp=*bufp0;
*bufp0=*bufp1;
*bufp1=temp;
}
每个模块都有自己的代码、数据(初始化全局变量、为初始化全局变量,静态变量,局部变量等)
局部变量分配在栈中,不会在过程外被调用,因此不是符号定义
可执行文件存储映像
| ELF头 |
|---|
| 程序(段)头表(描述如何进行映射) |
| .init节 |
| .text节 |
| .rodata节 |
| .data节 |
| .bss节 |
| .symtab节 |
| .debug节 |
| .line节 |
| .strtab节 |
| 内核虚拟存储区 |
|---|
| 用户栈动态生成 |
| 共享库区域 |
| 堆(heap)由malloc动态生成 |
| 读写数据段(.data .bss) |
| 只读代码段(.init .text .rodata) |
| 未使用 |
10.2.2 目标文件的两种视图
- 可重定位目标文件
- 其代码和数据可和其他可重定位文件合并位可执行文件
- 可执行目标文件(linux默认位a.out,windows中的*.exe)
- 共享的目标文件(linux中的*.so)
链接视图—可重定位目标文件
- 可被链接(合并)生成可执行文件或共享目标文件
- 静态链接库文件有若干个可重定位目标文件组成
- 包含代码、数据(已初始化的全局变量和局部静态两.data和未初始化的全局变量和局部静态变量.bss)
- 包含重定位信息(指出那些符号引用出需要重定位)
- 文件扩展名位.o(相当于windows中的.obj文件)
执行试图:程序头表由不同的段组成,描述节如何映射到存储段中,可多个节映射到同一个段中,如:可合并.data节和.bss节,并映射到一个可读可写数据段中
10.3.1可重定位文件概述
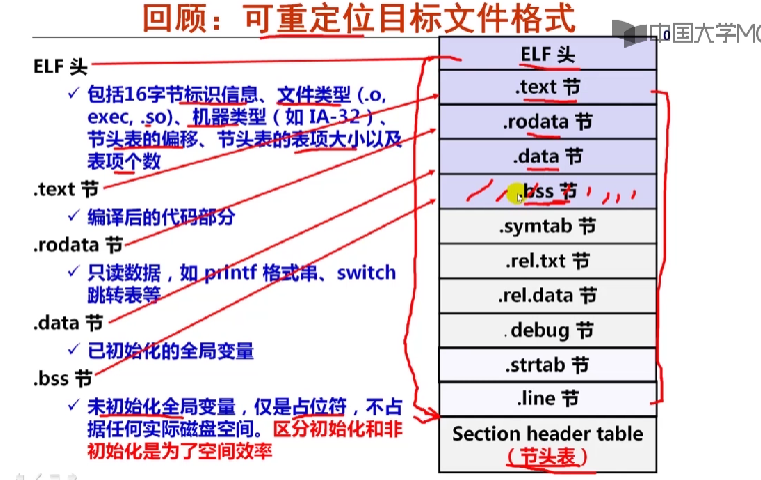
可重定位目标文件格式
elf头:包括16字节的标识信息、文件类型、机器类型、节头表的偏移、节头表的表项大小以及表项个数
.text节:编译后代码部分
.rodata节:只读数据,如printf格式串,switch跳转表等
.data节:已初始化的全局变量
.bss节:未初始化全局变量,仅仅是占位符,不占据任何实际磁盘空间。区分初始化和非初始化是为了空间效率
- c语言规定: 未初始化的全局变量和局部静态变量的默认初始值为0
- 将未初始化变量(.bss节)与已初始化
- 所有未初始化的全局变量和局部静态变量都被汇总到.bss节中,通过专门的节头表来说明.bss节预留多大的空间
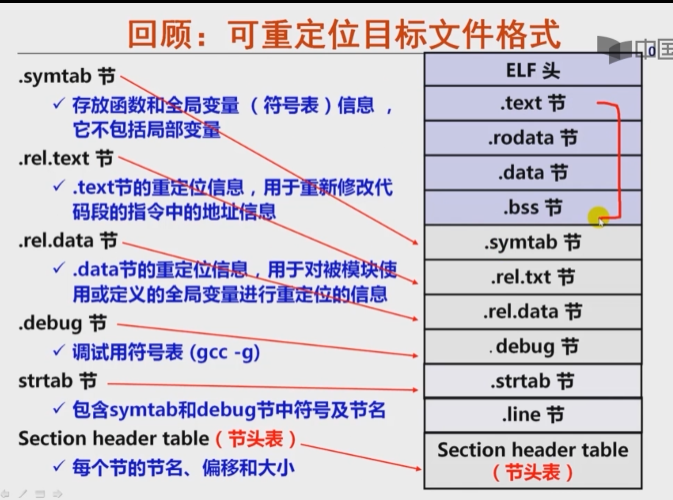
可重定位目标文件格式
- .symtab:存放函数名和全家变量(符号表)信息,他不包括局部变量
- .rel.text节:.text节的重定位信息,用于重新修改代码段的指令中的地址信息
- .rel.data节:.data节的重定位嘻嘻你,用于对被模块使用或定义的全局变量进行重定位的信息
- .debug节L调式用符号表
- strtab节:包含symtab和debug节中符号及节名
- Section header table:节头表:每个节的节名、偏移和大小
10.3.2 ELF头和节头表
- ELF头位于ELF文件开始,包含文件结构说明信息。分32位系统对应结构和64位系统对应结构,描述每个节的节名,在文件中的偏移、大小和访问属性、对齐方式等。


10.4.1可执行文件概述
| ELF头 |
|---|
| 程序头表 |
| .init节 |
| .text节 |
| .rodata节 |
| .data节 |
| .bss节 |
| .symtab节 |
| .debug节 |
| .strtab节 |
| .line节 |
| Section header table |
- elf头字段中e_entry给出执行程序时第一条指令的地址,在可重定位文件中则为0
- 多一个程序头表,也称段头表是一个结构数组
- 多一个.init节,用于定义_init函数,该函数用来进行可执行目标文件开始执行时的初始化工作
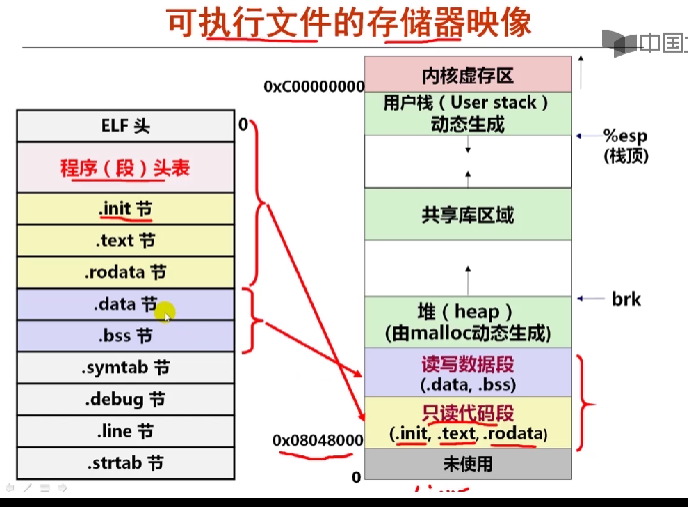
10.4.2程序头表和存储器映像
执行时视图–可执行目标文件
- 包含代码、数据(已初始化.data和未初始化.bss)
- 定义的所有变量和函数都有已经确定地址(虚拟地址空间中的地址)
- 符号引用处已被重定位,以指向所引用的定义符号
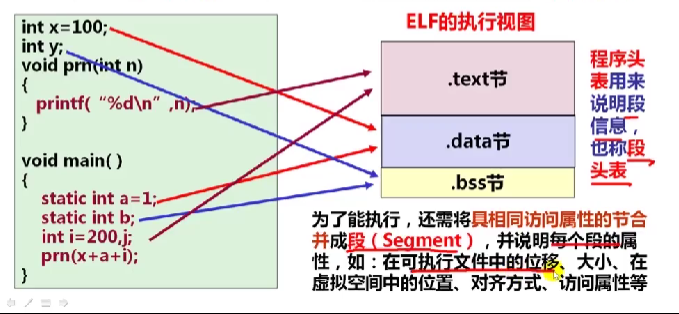
11.1.1符号和符号表的基本概念
- step1:符号解析
- 程序中有定义和引用的而符号(包括变量和函数)
- void swap{}
- swap()
- int *xp=&x;
- 编译器将定义的符号存放在一个符号表(symbol table)
- 符号表是一个结构数组,在.symtab节中
- 每个表项包含符号名、长度和位置等信息
- 编译将符号的应用存放在重定位节(.rel.text和.rel.data)中
- 链接器将每个符号的引用都与一个确定的符号定义建立关联
- 程序中有定义和引用的而符号(包括变量和函数)
- Step2:重定位
- 将多个代码段与数据段分别合并为一个单独的代码段和数据段
- 计算每个定义的符号咋虚拟地址空间中的绝对地址
- 将可执行文件中符号引用出的地址修改为重定位后的地址信息
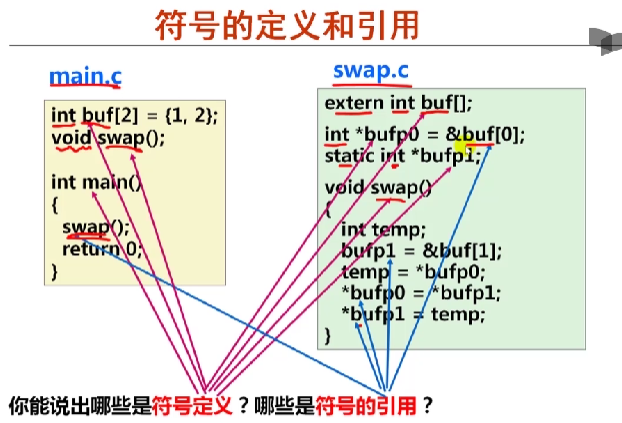
符号前面用来说明类型的都是一种定义,其他是引用。局部变量temp分配在栈中不会在过程外被引用,因此不是符号定义
链接符号的类型
每个可重定位目标木块m都有一个符号表,它包含了在m中定义的符号,分三种
- global symbols(模块内部定义的,全局符号)
- 由模块m定义并能被其他模块引用的符号。例如,非static C 函数非Static的C全局变量(指不带static的全局变量)
- External symbols(外部定义的,外部符号)
- 由其他模块定义并被模块m引用的全局符号
- 如,main.c中的函数名Swap;swap.c中的变量名buf
- 由其他模块定义并被模块m引用的全局符号
- local symbols(本模块定义并引用的,局部符号)
- 仅由模块m定义和引用的本地符号。例如,在模块m中定义的带static的c函数和变量
目标文件中的符号表
.symtab节记录符号表信息,是一个结构数组
符号表 symtab每个表项(16B)的结构如下
typedef struct
{
ELF32_Word st_name;//符号对应字符串在strtab节中的偏移量
ELF32_Addr st_value;//在对应节中的偏移量,或虚拟地址
ELF32_Word st_size;//符号对应目标字节数
unsigned char st_info;
unsigned char st_other;
ELF32_Half st_shndx;//符号对应目标所在的节,或其他情况
}ELF32_Sym
符号表信息举例
-
main.o中的符号表中最后三个条目
num value size type bind ot ndx name 8 0 8 data global 0 3 buf 9 0 33 func global 0 1 main 10 0 0 notype global 0 und swap
buf是main.o中第三节(.data)偏移为0的符号,是全局变量,占8B
main是第一节(.text)偏移为0的符号,是全局函数,占33B
11.1.3多重符号定义举例
int x=10;
int p1(void);
int main()
{
x=p1();
return x;
}
p1.c
int x=20;
int p1()
{
return x;
}
main只有一次强定义 p1有一次强定义,一次弱定义
x有两次强定义,链接器将输出一条出错信息
#include<stdio.h>
int y=100;
int z;
void p1(void);
int main()
{
z=1000;
p1();
printf("y=%d,z=%d\n",y,z);
return 0;
}
p1.c
int y;
int z;
void p1()
{
y=200;
z=2000;
}
//问打印结果是什么?
//y=200 z=2000
y一次弱定义,一次强定义,z两次弱定义
p1一次强定义,一次弱定义
main一次强定义
#include<stdio.h>
int d=100;
int x=200;
void p1(void);
int main()
{
p1();
printf("d=%d,x=%d\n",d,x);
return 0;
}
double d;
void p1()
{
d=1.0;
}
11.2.1静态共享库的创建
11.2.2符号解析过程
$gcc -c main.c
$gcc -static -o myproc main.o ./mylib.a
void myfunc1(void);
int main()
{
myfunc1();
return 0;
}
main->myfunc1->printf
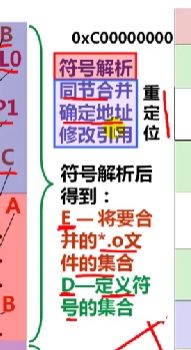
E:将被合并组成可执行文件的所有目标文件集合
U:当前所有未解析的应用符号的集合
D:当前所有定义符号的集合
开始E,U,D为空,首先扫描mian.o,把他加入E,同时把myfun1加入U,main加入D。接着扫描到mylib.a,将U中所有符号(本例中未myfunc1)与mylib.a所有目标模块依次匹配,发现在myproc1.o中定义了mufunc,故myfunc1.o加入E,myfun1从u转移到d。在myproc1.o发现还有为解析符号printf,将其加到u。不断在mylib.a的各模块上进行迭代以匹配u中的符号,知道u,d都不在变换。此时u中只有一个为界曦的符号printf,儿d中有main和myfun1。因为模块myproc2.o没有被加入e中,因而他被丢弃
链接顺序应该按照调用顺序来指定
11.2.3链接顺序问题
- 链接器对外部引用的解析算法要点如下
- 按照命令行给出的顺序扫描.o和.a文件
- 扫描期间将当前未解析的引用记录到一个列表u中
- 每遇到一个新的.o或.a中的模块,都试图用起来解析u中符号
- 如果扫描到最后,u中还有未被解析的符号,则发生错误。
12.1.1重定位的基本概念
重定位信息
- 当汇编器遇到引用时,伸成一个重定位条目
- 数据引用的重定位条目在.rel_data节中
- 指令中引用的二重定位条目在.rel_data节中
12.1.2PC相对地址重定位
int buf[2]={1,2};
void swap();
int main()
{
swap();
return 0;
}
extern int buf[];
int *bufp0=&buf[0];
static int *bufp1;
void swap()
{
int temp;
bufp1=&buf[1];
temp=*bufp0;
*bufp0=*bufp1;
*bufp1=temp;
}
符号解析后的结果是什么?
E中有main.o和swap.o两个模块!D中有所有定义的符号!
在main.o和swap.o的重定位条目中有重定位信息,反应符号引用的位置、绑定的定义符号名、重定位类型
Disassembly of seciton.text
0000 0000<main>:
0: 55 push %ebp
1: 89 e5 mov %esp,%ebp
3: 83 e4 f0 and $0xffff fff0,%esp
6: e8 fc ff ff call 7<main+0x7>
b: b8 00 00 00 00 mov $0x0,%eax
10: c9 leave
11: c3 ret
main的定义在.text节中偏移为0处开始,占0x12B 18B
ff ff ff fc
11111111,11111111,11111111,11111100
-0000000,00000000,00000000,00000100=-4
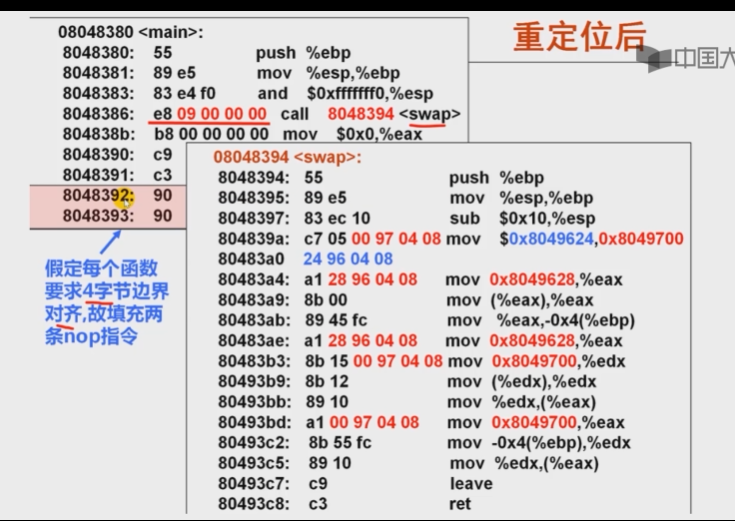
- 假定:
- 在可执行文件中main函数对应机器代码从0x8048380开始
- swap紧跟main后,其机器代码首地址按4字节边界对齐
- 0x8048380+0x12=0x8048392
- 在4字节边界对齐的情况下是0x8048394
- 则重定位call指令的机器代码是什么?
- 转移目标地址=PC+偏移地址(重定位值)
- PC=0x8048380+0x07-init
- 重定位值=转移目标地址-PC=0x8048394-0x804838b=0x9
- call指令的机器代码为”e8 09 00 00 00 "
12.1.3绝对地址重定位
main.o ,data and .rel.data节内容
0000 0000<buf>:
0000 0000<buf>:
0: 01 00 00 00 02 00 00 00
swap.o .data .rel.data节内容
0000 0000<bufp0>:
0: 00 00 00 00
0:R_386_32 buf

- 假定buf在运行时的存储地址ADDR(buf)=0x8049620
- 则重定位后,bufp0的地址及内容变为什么?
- -buf和bufp0同属于.data节,故在可执行文件中他们被合并
- bufp0紧接在buf后,故地址为0x8049620+8=0x8049628
- 因为是R_386_32方式,故bufp0内容为buf的绝对地址0x8049620 即20 96 04 08
12.1.4符号重定位举例
- buf和bufp0的地址分别是0x8049620和0x8049628
- &buf[1] (c处重定位值 )为0x8049620+0x4=0x8049624
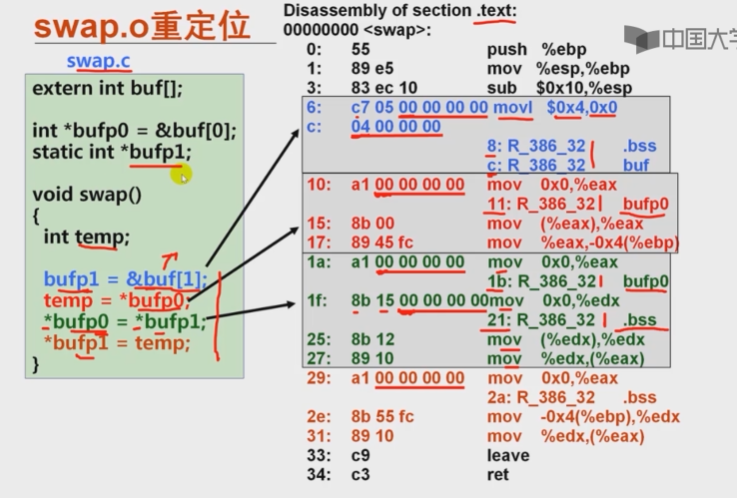
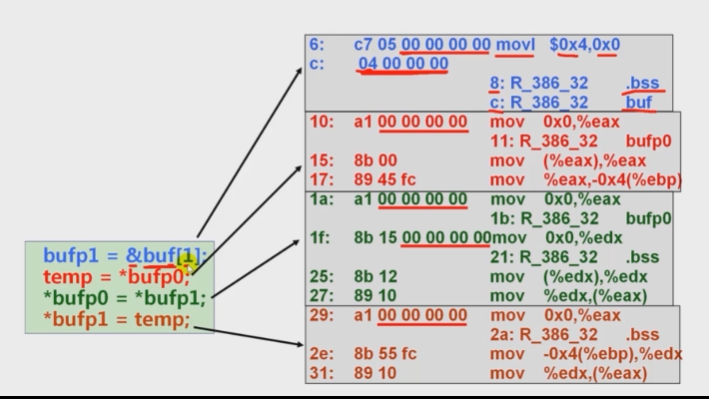
- bufp1的地址就是连接合并后.bss节的首地址,假定为0x8049700
- 8(bufp1):00 97 04 08
- c(&buf[1]):24 96 04 08
- 11(bufp0):28 96 04 08
- 1b(bufp0):28 96 04 08
- 21(bufp1):00 97 04 08
- 2a(bufp1):00 97 04 08
12.2.1可执行文件的加载
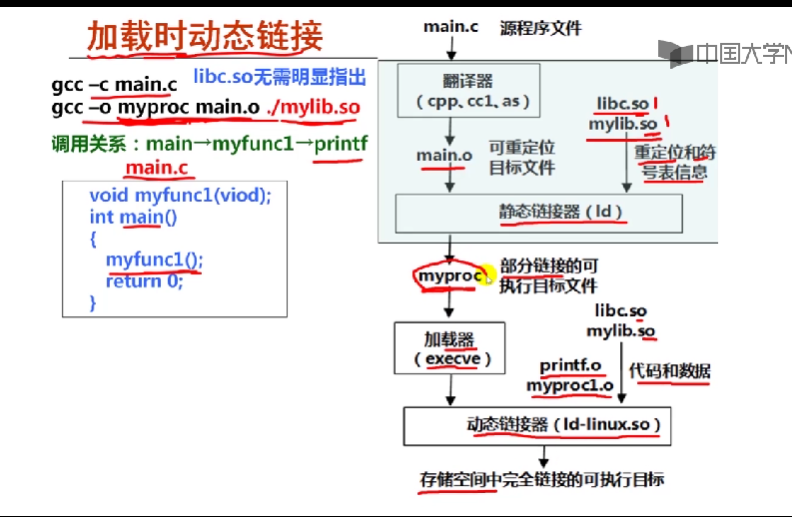
12.2.3共享库和动态链接概述
解决方案:使用shared libraries(共享库)
linux称其为动态共享对象
动态链接可以按以下两种方式进行
- 在第一次加载运行时进行(load-time linking )
- 在已经开始运行后进行(run-time linking)
- 位置无关代码
- 保证共享库代码的位置可以是不确定的
- 即使共享库代码的长度发生变化,也不会影响调用它的程序
12.2.3模块内引用和模块间数据引用
位置无关代码(position-independent code,pic)
-
引入pic的目的
- 无需修改程序代码即可将共享库加载到任意地址运行
-
共享库内所有引用情况
- 模块内的过程调用、跳转,采用pc相对偏移寻址
- 模块内数据访问,如访问模块内的全局变量和静态变量
- 模块外的过程调用、跳转
- 模块外的数据访问,如外部变量的访问
模块内部函数调用或跳转

模块内部数据引用
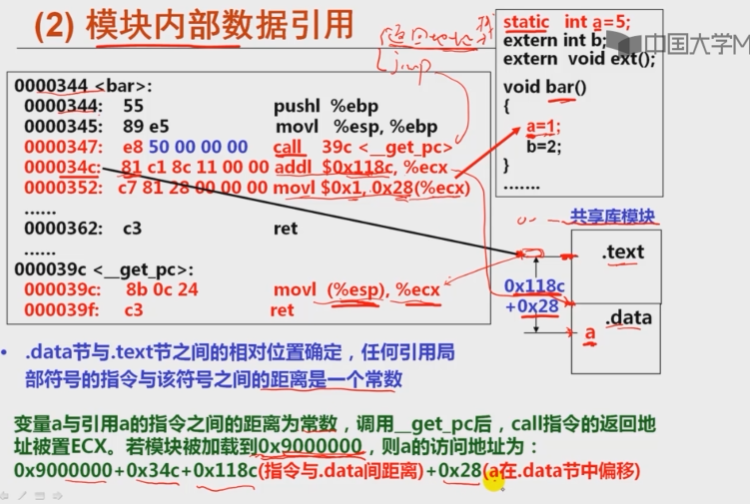
模块外数据的引用
static int a;
extern int b;
extern void ext();
void bar()
{
a=1;
b=2;
}
- 引用其他模块的全局变量,无法确定相对距离
- 在.data节开始处设置一个指针数组(全局偏移表,got)指针可指向一个全局变量

















 1210
1210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









