







目录
JSX(转成虚拟dom)
JSX通过Babel编译时会被编译成React.createElement
// 编译前
<div className="content">
<h3>Hello React</h3>
<p>React is great</p>
</div>
// 编译后
React.createElement(
'div',
{
className: 'content'
},
React.createElement('h3', null, 'Hello World'),
React.createElement('p', null, 'React is greate')
)
React.createElement代表一个节点元素,第一个参数是节点的名称,第二个是节点的属性,后面的参数都是子节点。
我们可以自己在babeljs.is网站试验。React.createElement就是用来创建虚拟DOM的,返回的就是一个虚拟DOM对象。React再将虚拟DOM转换为真实DOM显示到页面中。
jsx在运行时会被Babel转换为React.createElement对象,React.createElement会被React转换成虚拟DOM对象,虚拟DOM对象会被React转换成真实DOM对象。
JSX语法的出现就是为了让React开发人员编写用户界面代码更加轻松。
createElement
createElement方法接收type, props, childrens三个参数。分别表示标签类型,标签属性和标签子元素。在这个方法中要返回一个虚拟DOM对象,在这个对象中有个type属性其实就是参数传入的值,接着是props和children。
/**
* 创建 React Element
* type 元素类型
* config 配置属性
* children 子元素
* 1. 分离 props 属性和特殊属性
* 2. 将子元素挂载到 props.children 中
* 3. 为 props 属性赋默认值 (defaultProps)
* 4. 创建并返回 ReactElement
*/
export function createElement(type, config, children) {
/**
* propName -> 属性名称
* 用于后面的 for 循环
*/
let propName;
/**
* 存储 React Element 中的普通元素属性 即不包含 key ref self source
*/
const props = {};
/**
* 待提取属性
* React 内部为了实现某些功能而存在的属性
*/
let key = null;
let ref = null;
let self = null;
let source = null;
// 如果 config 不为 null
if (config != null) {
// 如果 config 对象中有合法的 ref 属性
if (hasValidRef(config)) {
// 将 config.ref 属性提取到 ref 变量中
ref = config.ref;
}
// 如果在 config 对象中拥有合法的 key 属性
if (hasValidKey(config)) {
// 将 config.key 属性中的值提取到 key 变量中
key = '' + config.key;
}
self = config.__self === undefined ? null : config.__self;
source = config.__source === undefined ? null : config.__source;
// 遍历 config 对象
for (propName in config) {
// 如果当前遍历到的属性是对象自身属性
// 并且在 RESERVED_PROPS 对象中不存在该属性
/**
* const RESERVED_PROPS = {
* key: true,
* ref: true,
* _self: true,
* _source:true
*}
*/
if (
hasOwnProperty.call(config, propName) &&
!RESERVED_PROPS.hasOwnProperty(propName)
) {
// 将满足条件的属性添加到 props 对象中 (普通属性)
props[propName] = config[propName];
}
}
}
/**
* 将第三个及之后的参数挂载到 props.children 属性中
* 如果子元素是多个 props.children 是数组
* 如果子元素是一个 props.children 是对象
*/
// 由于从第三个参数开始及以后都表示子元素
// 所以减去前两个参数的结果就是子元素的数量
const childrenLength = arguments.length - 2;
// 如果子元素的数量是 1
if (childrenLength === 1) {
// 直接将子元素挂载到到 props.children 属性上
// 此时 children 是对象类型
props.children = children;
// 如果子元素的数量大于 1
} else if (childrenLength > 1) {
// 创建数组, 数组中元素的数量等于子元素的数量
const childArray = Array(childrenLength);
// 开启循环 循环次匹配子元素的数量
for (let i = 0; i < childrenLength; i++) {
// 将子元素添加到 childArray 数组中
// i + 2 的原因是实参集合的前两个参数不是子元素
childArray[i] = arguments[i + 2];
}
// 将子元素数组挂载到 props.children 属性中
props.children = childArray;
}
/**
* 如果当前处理是组件
* 看组件身上是否有 defaultProps 属性
* 这个属性中存储的是 props 对象中属性的默认值
* 遍历 defaultProps 对象 查看对应的 props 属性的值是否为 undefined
* 如果为undefined 就将默认值赋值给对应的 props 属性值
*/
// 将 type 属性值视为函数 查看其中是否具有 defaultProps 属性
if (type && type.defaultProps) {
// 将 type 函数下的 defaultProps 属性赋值给 defaultProps 变量
const defaultProps = type.defaultProps;
// 遍历 defaultProps 对象中的属性 将属性名称赋值给 propName 变量
for (propName in defaultProps) {
// 如果 props 对象中的该属性的值为 undefined
if (props[propName] === undefined) {
// 将 defaultProps 对象中的对应属性的值赋值给 props 对象中的对应属性的值
props[propName] = defaultProps[propName];
}
}
}
// 如果处于开发环境
}
// 返回 ReactElement
return ReactElement(
type,
key,
ref,
self,
source,
// 在 Virtual DOM 中用于识别自定义组件
ReactCurrentOwner.current,
props,
);
}
代码看似很多,其实逻辑非常清晰:
处理参数,对传进来的数据进行加工处理,比如提取config参数,处理props等
调用真正的创建虚拟DOM的APIReactElement创建ReactNode
数据加工部分分为三步:
- 第一步,判断config有没有传,不为null就做处理
判断ref、key,__self、__source这些是否存在或者有效,满足条件就分别赋值给前面新建的变量。
遍历config,并将config自身的属性依次赋值给前面新建props。 - 第二步,处理子元素。默认从第三个参数开始都是子元素。
如果子元素只有一个,直接赋值给props.children。
如果子元素有多个,转成数组后再赋值给props.children。 - 第三步,处理默认属性defaultProps
一个纯粹的标签也可以理解成一个最最最基础的组件,而组件支持 defaultProps,所以这一步判断有没有defaultProps,如果有同样遍历,并将值不为undefined的部分都拷贝到props对象上。
ReactElement
/**
* ReactElement 就是虚拟节点的概念
* @param {*} key 虚拟节点的唯一标识,后期可以进行优化
* @param {*} type 虚拟节点类型,type可能是字符串('div', 'span'),也可能是一个function,function时为一个自定义组件
* @param {*} props 虚拟节点的属性
*/
function ReactElement(type, key, ref, self, source, owner, props) {
const element = {
// 这个标签允许我们将其标识为唯一的React Element
$$typeof: REACT_ELEMENT_TYPE,
// 元素的内置属性
type: type,
key: key,
ref: ref,
props: props,
// 记录负责创建此元素的组件。
_owner: owner,
};
return element
}
这里提一下REACT_ELEMENT_TYPE,他的实现是:
export const REACT_ELEMENT_TYPE = Symbol.for(‘react.element’);
$$typeof定义为Symbol(react.element),而Symbol一大特性就是标识唯一性,即便两个看着一模一样的Symbol,它们也不会相等。而react之所以这样做,本质也是为了防止xss攻击,防止外部伪造虚拟dom结构。
JSX与Fiber节点
从上面的内容我们可以发现,JSX是一种描述当前组件内容的数据结构,他不包含组件schedule、reconcile、render所需的相关信息。
比如如下信息就不包括在JSX中:
- 组件在更新中的优先级
- 组件的state
- 组件被打上的用于Renderer的标记
- 这些内容都包含在Fiber节点中。
所以,在组件mount时,Reconciler根据JSX描述的组件内容生成组件对应的Fiber节点。
在update时,Reconciler将JSX与Fiber节点保存的数据对比,生成组件对应的Fiber节点,并根据对比结果为Fiber节点打上标记
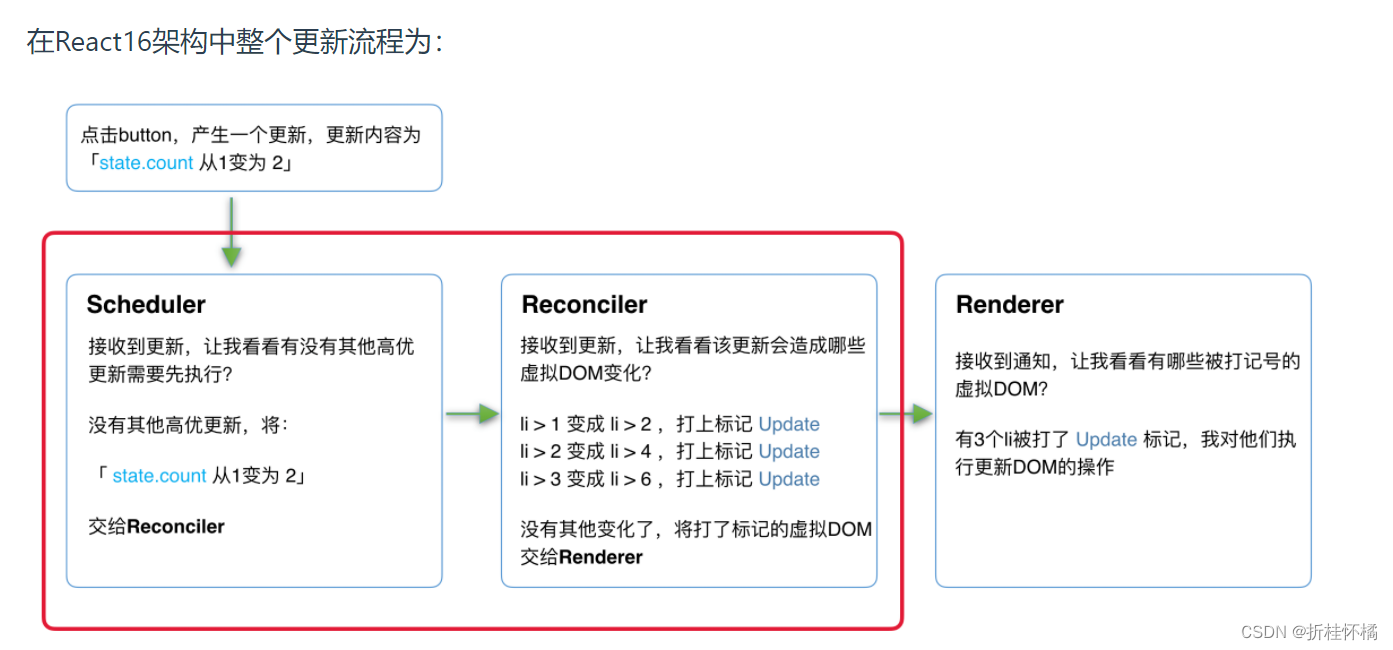
架构
Scheduler(调度器)—— 调度任务的优先级,高优任务优先进入Reconciler
Reconciler(协调器)—— 负责找出变化的组件
Renderer(渲染器)—— 负责将变化的组件渲染到页面上
概念
调度器(Scheduler)
既然我们以浏览器是否有剩余时间作为任务中断的标准,那么我们需要一种机制,当浏览器有剩余时间时通知我们。Scheduler还提供了多种调度优先级供任务设置。
协调器(Reconciler)
Reconciler内部采用了Fiber的架构,Reconciler与Renderer不再是交替工作。当Scheduler将任务交给Reconciler后,Reconciler会为变化的虚拟DOM打上代表增/删/更新的标记,类似这样:
export const Placement = /* */ 0b0000000000010;
export const Update = /* */ 0b0000000000100;
export const PlacementAndUpdate = /* */ 0b0000000000110;
export const Deletion = /* */ 0b0000000001000;
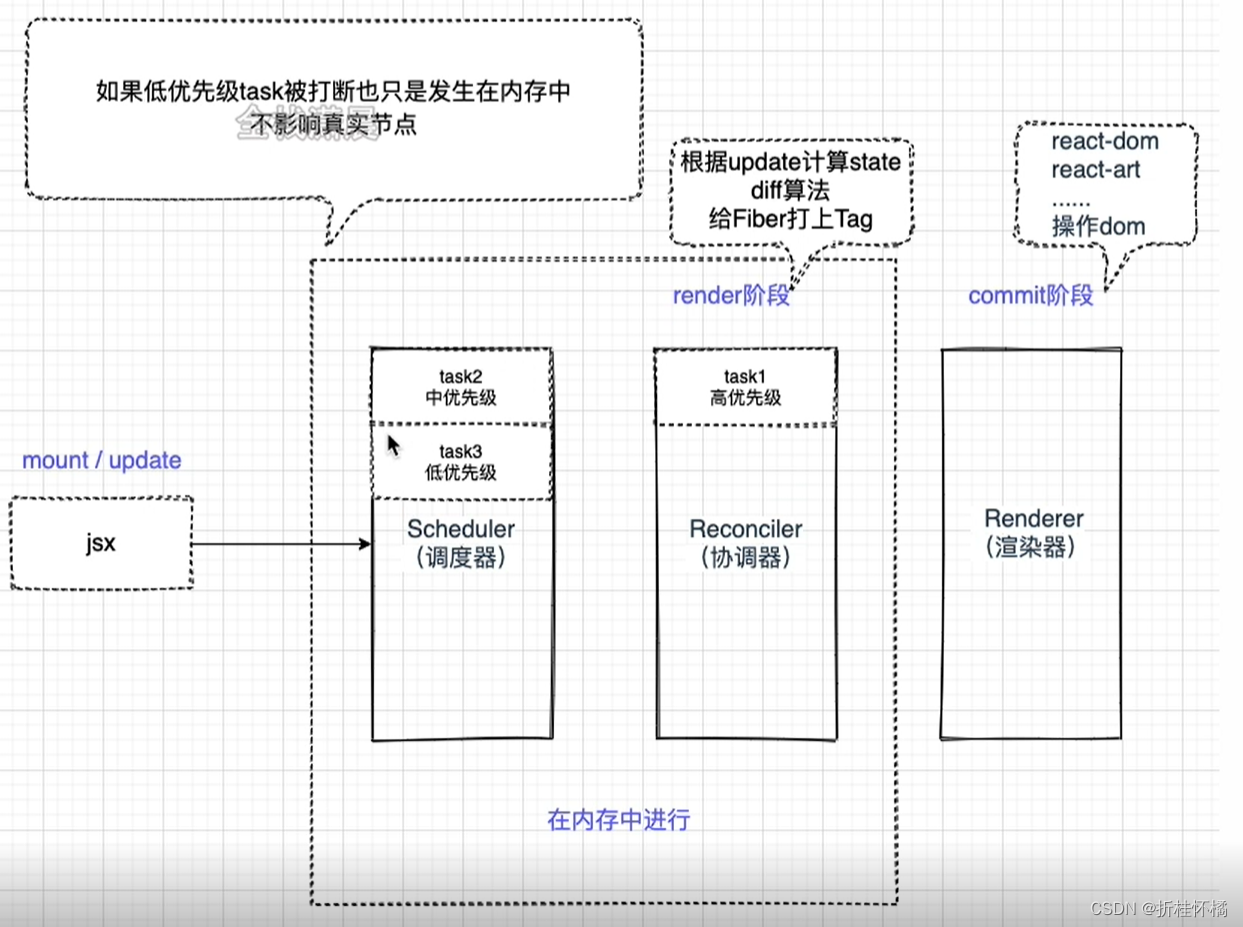
整个Scheduler与Reconciler的工作都在内存中进行。只有当所有组件都完成Reconciler的工作,才会统一交给Renderer。
渲染器(Renderer)
Renderer根据Reconciler为虚拟DOM打的标记,同步执行对应的DOM操作
渲染阶段render
function App() {
return (
<div>
<p>{this.state.count}</p>
<button >click me</button>
</div>
)
}
ReactDOM.render(
<App />,
document.getElementById('root')
);
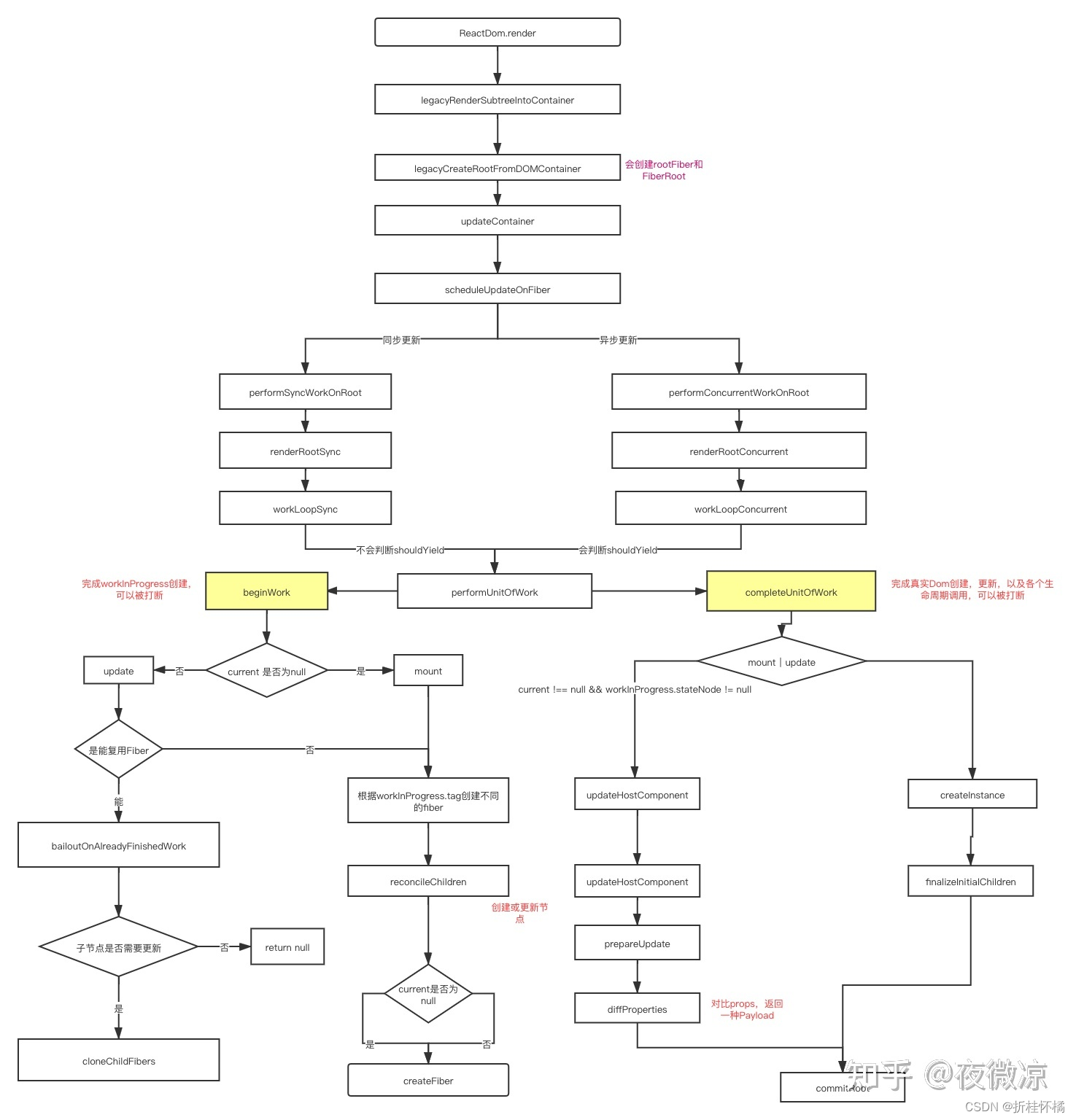
“递”阶段
首先从rootFiber开始向下深度优先遍历。为遍历到的每个Fiber节点调用beginWork方法 (opens new window)。
该方法会根据传入的Fiber节点创建子Fiber节点,并将这两个Fiber节点连接起来。
当遍历到叶子节点(即没有子组件的组件)时就会进入“归”阶段。
“归”阶段
在“归”阶段会调用completeWork (opens new window)处理Fiber节点。
当某个Fiber节点执行完completeWork,如果其存在兄弟Fiber节点(即fiber.sibling !== null),会进入其兄弟Fiber的“递”阶段。
如果不存在兄弟Fiber,会进入父级Fiber的“归”阶段。
“递”和“归”阶段会交错执行直到“归”到rootFiber。至此,render阶段的工作就结束了。
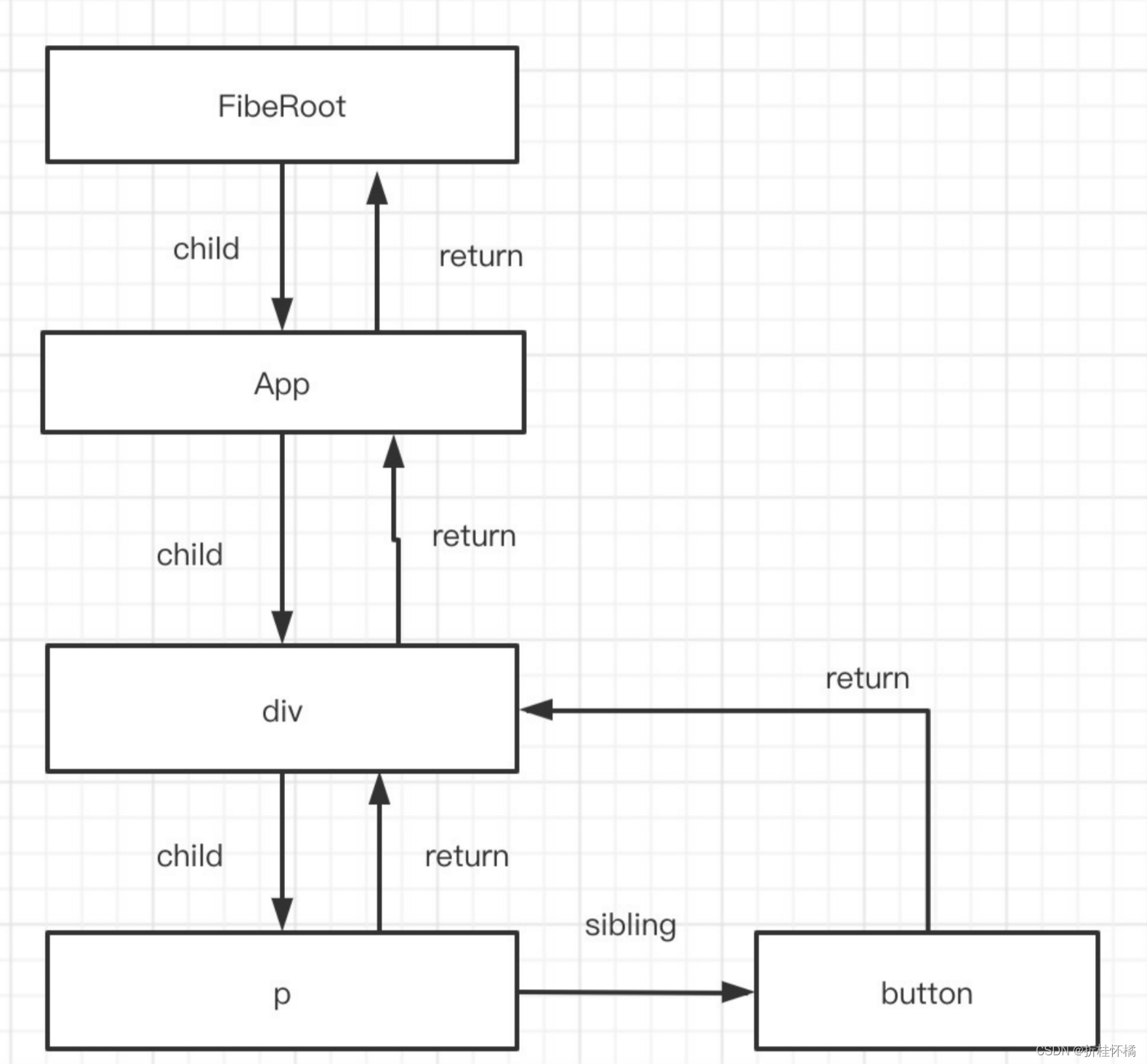
render阶段会依次执行:
第一步:FiberRoot beignwork
第二步:App Fiber beignWork
第三步:div Fiber beignWork
第四步:p Fiber beignWork
第五步:因为p节点之后文本子节点,react会进行优化,直接进行completeUnitOfWork阶段,完成后将workInProgress设置为button fiber
第六步:button Fiber beignWork
第七步:同第五步p节点的优化,button会直接completeUnitOfWork阶段
第八步:div completeUnitOfWork
第九步:App completeUnitOfWork
第十步:FiberRoot completeUnitOfWork
- beginWork()为捕获阶段,此阶段会采取深度优先的方式遍历节点,并完成Fiber树创建以及diff算法。
- completeUnitOfWork()为冒泡阶段,此阶段要完成生命周期(部分)的调用,形成effectlist等
React 源码之commit阶段
在commit阶段是同步执行的,不可以被打断,也就是说所有的更新需要一次性完成。
协调:将虚拟DOM与真实DOM的状态进行同步,是一个使一致的过程
Diff:判断要删除、新建、移动的节点,是一个找不同的过程
Reconciler != Diff,但是一般说调和(协调)就是指的Diff算法,因为Diff算法确实是调和过程最具代表性的一环
双缓存Fiber树
什么是“双缓存
这种在内存中构建并直接替换的技术叫做双缓存 (opens new window)。React使用“双缓存”来完成Fiber树的构建与替换——对应着DOM树的创建与更新
在React中最多会同时存在两棵Fiber树。当前屏幕上显示内容对应的Fiber树称为current Fiber树,正在内存中构建的Fiber树称为workInProgress Fiber树。
current Fiber树中的Fiber节点被称为current fiber,workInProgress Fiber树中的Fiber节点被称为workInProgress fiber,他们通过alternate属性连接。
currentFiber.alternate === workInProgressFiber;
workInProgressFiber.alternate === currentFiber;
React应用的根节点通过使current指针在不同Fiber树的rootFiber间切换来完成current Fiber树指向的切换。
即当workInProgress Fiber树构建完成交给Renderer渲染在页面上后,应用根节点的current指针指向workInProgress Fiber树,此时workInProgress Fiber树就变为current Fiber树。
每次状态更新都会产生新的workInProgress Fiber树,通过current与workInProgress的替换,完成DOM更新。
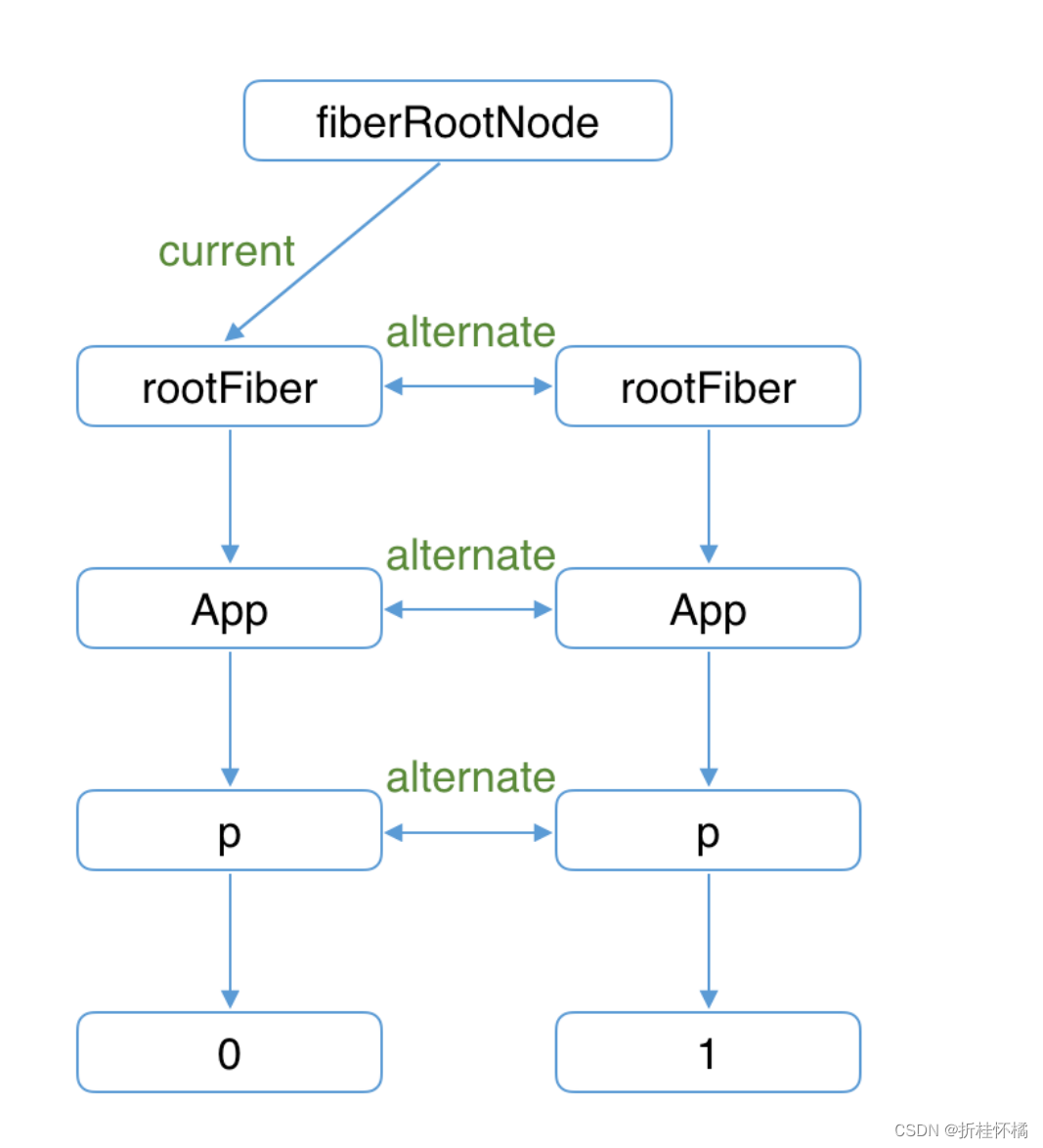
mount时
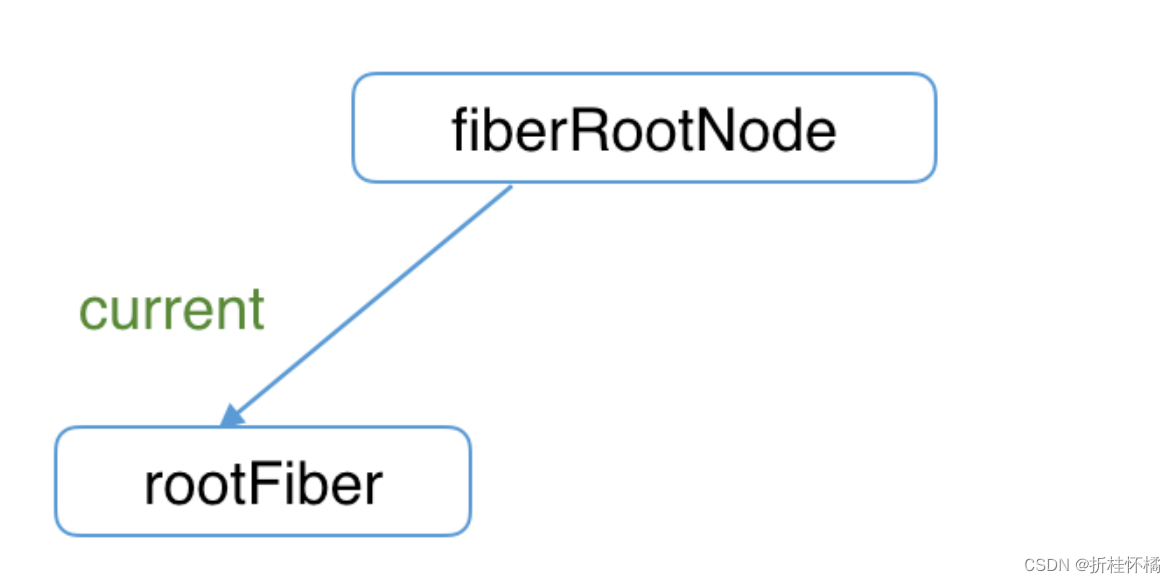
首次执行ReactDOM.render会创建fiberRootNode(源码中叫fiberRoot)和rootFiber。其中fiberRootNode是整个应用的根节点,rootFiber是所在组件树的根节点。
之所以要区分fiberRootNode与rootFiber,是因为在应用中我们可以多次调用ReactDOM.render渲染不同的组件树,他们会拥有不同的rootFiber。但是整个应用的根节点只有一个,那就是fiberRootNode。
fiberRootNode的current会指向当前页面上已渲染内容对应Fiber树,即current Fiber树
beginWork(递)
从传参看方法执行
function beginWork(
current: Fiber | null,
workInProgress: Fiber,
renderLanes: Lanes,
): Fiber | null {
// ...省略函数体
}
其中传参:
- current:当前组件对应的Fiber节点在上一次更新时的Fiber节点,即workInProgress.alternate
- workInProgress:当前组件对应的Fiber节点
- renderLanes:优先级相关,在讲解Scheduler时再讲解
我们知道,除rootFiber以外, 组件mount时,由于是首次渲染,是不存在当前组件对应的Fiber节点在上一次更新时的Fiber节点,即mount时current === null。
组件update时,由于之前已经mount过,所以current !== null。
所以我们可以通过current === null ?来区分组件是处于mount还是update。
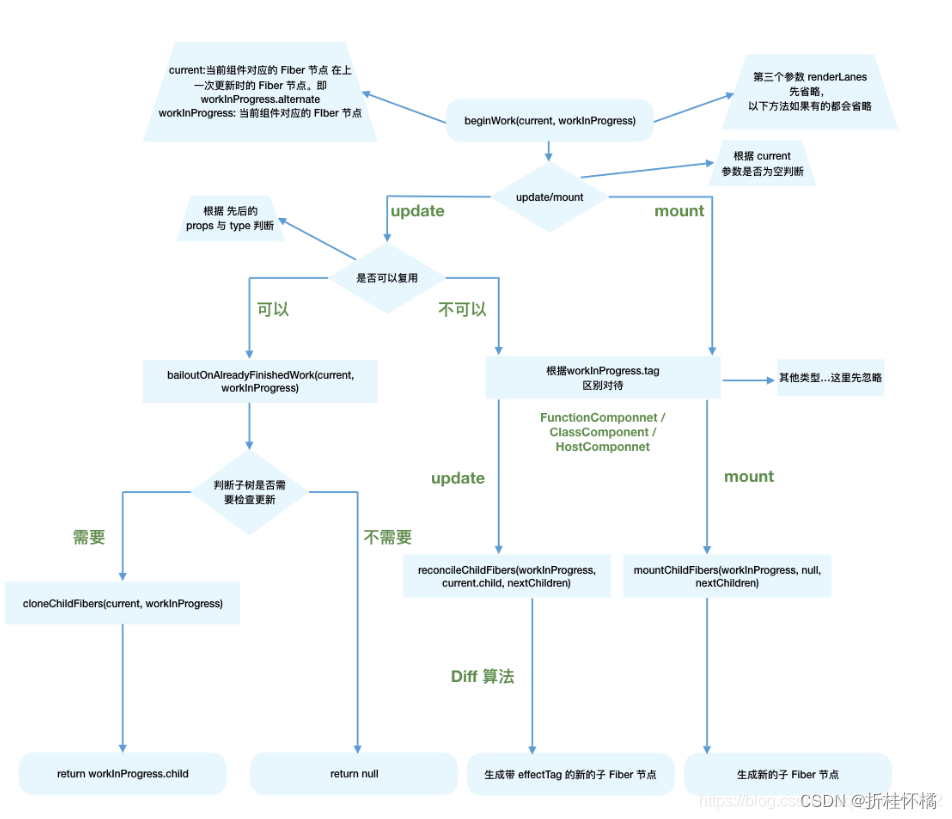
基于此原因,beginWork的工作可以分为两部分:
mount:
mount时除fiberRootNode以外,current === null
根据workInProgress.tag判断需要创建的Fiber节点类型,并且创建相应的Fiber节点。我们可以从这里看到tag的所有类型。对于我们常见的组件类型,如FuctionComponent,ClassComponent,HostComponent,最终会进入reconcileChildren方法。
update
着另一条线路来看看update阶段。在该阶段,首先通过对传入的两个Fiber节点的type和props进行比较,判断该节点是否可以复用。若不可以复用,则把他当成新的Fiber节点看待,走类似mount阶段的流程,最后生成带effecTag的新的Fiber节点;若可以复用,则检查子树是否需要更新。若子树需要更新,则执行cloneChildFibers并且返回子节点;否则直接返回null.
reconcileChildren
从该函数名就能看出这是Reconciler模块的核心部分。它对于从不同路径来的Fiber节点做了不同的事情:
- 对于mount组件,他会创建新的Fiber节点
- 对于update组件,他会将当前组件于该节点上次更新时对应的Fiber节点(Diff算法)进行比较,将比较的结果生成新的Fiber节点
export function reconcileChildren(
current: Fiber | null,
workInProgress: Fiber,
nextChildren: any,
renderLanes: Lanes
) {
if (current === null) {
// 对于mount的组件
workInProgress.child = mountChildFibers(
workInProgress,
null,
nextChildren,
renderLanes,
);
} else {
// 对于update的组件
workInProgress.child = reconcileChildFibers(
workInProgress,
current.child,
nextChildren,
renderLanes,
);
}
}
effectTag(做具体标记)
我们知道,render阶段的工作是在内存中进行,当工作结束后会通知Renderer需要执行的DOM操作。要执行DOM操作的具体类型就保存在fiber.effectTag中
completeUnitOfWork(归)
和beginWork一样,它也是通过判断current === null?来判断mount阶段和update阶段。
update
当update时,Fiber节点已经存在对应DOM节点,所以不需要生成DOM节点。需要做的主要是处理props,比如:
- onClick、onChange等回调函数的注册
- 处理style prop
- 处理DANGEROUSLY_SET_INNER_HTML prop
- 处理children prop
- 我们去掉一些当前不需要关注的功能(比如ref)。可以看到最主要的逻辑是调用updateHostComponent方法。
在updateHostComponent内部,被处理完的props会被赋值给workInProgress.updateQueue,并最终会在commit阶段被渲染在页面上。
mount
- 为Fiber节点生成对应的DOM节点
- 将子孙DOM节点插入刚生成的DOM节点中
- 与update逻辑中的updateHostComponent类似的处理props的过程
effectList
?:作为DOM操作的依据,commit阶段需要找到所有有effectTag的Fiber节点并依次执行effectTag对应操作。如果再遍历一次Fiber树是及其低效的操作,那么怎么办呢?
在completeWork的上层函数completeUnitOfWork中,每个执行完completeWork且存在effectTag的Fiber节点,会被保存在一条被称为effectList的单向链表中。
effectList中第一个Fiber节点白存在fiber.firstEffect,最后一个元素保存在fiber.lastEffect中,在归的阶段,所有有effectTag的Fiber节点都会被追加到effectList中,最终形成以rootFiber.firstEffect为起点的单向链表。这样,在commit阶段只需要遍历effectList九能执行所有的effect了。
提交阶段commit
在rootFiber.firstEffect上保存了一条需要执行副作用的Fiber节点的单向链表effectList,这些Fiber节点的updateQueue中保存了变化的props。
这些副作用对应的DOM操作在commit阶段执行。
除此之外,一些生命周期钩子(比如componentDidXXX)、hook(比如useEffect)需要在commit阶段执行。
commit阶段的主要工作(即Renderer的工作流程)分为三部分:
-
before mutation阶段(执行DOM操作前)
-
mutation阶段(执行DOM操作)
-
layout阶段(执行DOM操作后)
before mutation阶段
我们知道了在before mutation阶段,会遍历effectList,依次执行:
-
处理DOM节点渲染/删除后的 autoFocus、blur逻辑
-
调用getSnapshotBeforeUpdate生命周期钩子
-
调度useEffect
mutation阶段
mutation阶段会遍历effectList,依次执行commitMutationEffects。该方法的主要工作为“根据effectTag调用不同的处理函数处理Fiber
layout阶段
该阶段之所以称为layout,因为该阶段的代码都是在DOM渲染完成(mutation阶段完成)后执行的。layout阶段会遍历effectList,依次执行commitLayoutEffects。该方法的主要工作为“根据effectTag调用不同的处理函数处理Fiber并更新ref















 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









