







如果说网络爬虫爬取的网页信息是数据大海,正则表达式就是我们进行“大海捞针”的工具。
目录
正则表达达式
定义
正则表达式即文本的高级匹配模式,提供搜索、替代、获取等功能。本质是由一系列特殊符号和字符构成的字串,而这个字串就是正则表达式。
特点
(1)方便进行检索修改文本的操作
(2)支持众多编程语言
(3)使用灵活多样
正则表达式匹配
通过设定有特殊意义的符号,描述符号和字符的重复行为及位置特征来表示一类特定规则的字符串
python 中的 re模块(处理正则表达式)
re.findall(pattern,string)
功能:使用正则表达式匹配字符串
参数: pattern 以字符串形式传入一个正则表达式
string 要匹配的目标字符串
返回值 : 得到列表,将目标字串中能用正则匹配的内容放入列表
先来看一个例子
import re
pattern = r"([A-Z])(\S+)"
l = re.findall(pattern,"Hello Word!")
print(l)
#输出结果
# [('H', 'ello'), ('W', 'ord!')]正则表达式元字符
普通字符匹配
(除了后面会说到的特殊字符全部为普通字符)
可以用普通字符来匹配对应的字符
元字符: a b c & #
匹配规则 : 匹配字符本身
import re
re.findall("abc","abcdefghabc")
# 输出结果
# ['abc', 'abc']
re.findall("python","python爱好者")
# 输出结果
# ['python']或 |
元字符: |
匹配规则: 匹配 | 两边任意一个正则表达式
import re
re.findall('ab|cd',"abdsaacdfaabvf")
# 输出结果
# ['ab', 'cd', 'ab']
匹配单个字符 .
元字符: .
匹配原则:匹配除\n外任意一个字符
import re
re.findall("你.好","你好,你很好,你非常好")
# ['你很好']
re.findall("你..好","你很好,你非常好")
# ['你非常好']
re.findall('f.o',"fao is not foo")
# ['fao', 'foo']匹配开始位置 ^
元字符: ^
匹配规则: 匹配一个字符串的开头位置
import re
re.findall("^Colin","Colin,how are you")
# ['Colin']
re.findall("^Colin","Hi,Colin")
# []匹配结束位置 $
元字符 : $
匹配规则: 匹配目标字符串的结束位置
re.findall('py$',"hello.py")
# ['py']
re.findall('py$',"hello.pyc")
# []匹配重复 *
元字符 : *
匹配规则: 匹配 * 前面的正则表达式(就是第一个字符)重复0次或者多次
re.findall("ab*",'abjkhdskfh abbbbbbbbbb abbuhdsol')
# ['ab', 'abbbbbbbbbb', 'abb']匹配重复 +
元字符 : +
匹配规则: 匹配前面的正则表达式1次或多次
re.findall(".+word$","hello word")
# ['hello word']匹配重复 ?
元字符 : ?
匹配规则: 匹配前面出现的正则表达式0次或1次
re.findall('ab?',"abbbbbscadsfab")
# ['ab', 'a', 'ab']匹配重复 {n}
元字符 : {n}
匹配规则 : 匹配前面的正则表达式n次
re.findall('ab{3}',"abbbbbadffg")
# ['abbb']匹配重复{m,n}
元字符 : {m,n}
匹配规则: 匹配前面的正则表达式m到n次
re.findall('ab{3,5}',"abbbbbaabbbg")
# ['abbbbb', 'abbb']匹配字符集合 [字符集]
元字符: [字符集]
匹配规则: 匹配中括号中字符集字符内的任意一个字符
re.findall("[aeiou]","hello world")
# ['e', 'o', 'o']
re.findall('[a-z]+',"hello 123")
# ['hello']
re.findall("^[A-Z][a-z]*","Hello word")
# ['Hello']匹配字符集合 [^ ...]
元字符: [^ ...]
匹配规则: 匹配除了中括号中字符集字符之外的任意一个字符
re.findall("[^holewd]","hello word")
# [' ', 'r']
re.findall("[^holewd123]","hello word 123456")
# [' ', 'r', ' ', '4', '5', '6']匹配任意(非)数字字符 \d \D
元字符: \d \D
匹配规则 : \d匹配任意数字字符 [0-9]
\D 匹配任意非数字字符 [^0-9]
re.findall("1\d{10}","13679481669")
# ['13679481669']
re.findall("\D+","hello word 123456")
# ['hello word ']匹配任意(非)普通字符 \w \W
(普通字符:数字、字母、下划线、)
元字符:\w \W
匹配规则:\w 匹配普通字符
\W匹配一个非普通字符
re.findall("\w+","hello colin! @123456")
# ['hello', 'colin', '123456']
re.findall("\W+","hello colin! @123456")
# [' ', '! @']匹配(空)空字符 \s \S
(空字符: 空格 \r \n \t \v \f)
元字符: \s \S
匹配规则:\s 匹配任意空字符
\S匹配任意非空字符
re.findall("\w+\s+\w+","hello word!")
# ['hello word']
re.findall("\S+","#hello$ %word! @123456&")
# ['#hello$', '%word!', '@123456&']匹配起止位置 \A(^) \Z($)
元字符: \A(^) \Z($)
匹配规则: 匹配字符串的开始和结束位置
re.findall('\Ahello',"hello world")
# ['hello']
re.findall('world\Z',"hello 123546 world")
# ['world']绝对匹配
正则表达式前后分别加^ $或\A \Z,则表示正则表达式需要匹配目标字符串的全部内容
re.findall('\Ahello world\Z',"hello world")
# ['hello world']匹配(非)单词边界 \b \B
(普通字符和其他非普通字符交接的位置认为是单词边界)
元字符: \b \B
匹配规则 : \b 单词边界
\B 非单词边界
re.findall('is',"this is a dog")
# ['is', 'is']
re.findall(r'\bis\b',"this is a dog")
# ['is']
re.findall(r'\bis',"this is a dog")
# ['is']元字符总结
匹配单个字符: a . […] [^…] \b \D \w \W \s \S
匹配重复: * + ? {n} {m,n}
匹配位置: ^ $ \A \Z \b \B
其他: | () \
正则表达式的转义
正则表达式的特殊字符
. * ? $ [] () {} ^ \
在正则表达式中如果想匹配这些特殊字符需要进行转义
re.findall("\[\d+\]","abcd[1234]")
# ['[1234]']2、r---raw 字符串 原生字符串
特点:字符串的内容就是字符串本身,不进行任何转义处理
“\\\\n” ------------> \n
r”\n” --------------> \n
re.findall("\\w+@\\w+\\.cn","qq@email.cn")
# ['qq@email.cn']
re.findall(r"\w+@\w+\.cn","qq@email.cn")
# ['qq@email.cn']贪婪和非贪婪
贪婪模式
正则表达式的重复匹配,默认总是尽可能多的向后匹配内容
* + ? {m,n}
非贪婪模式
尽可能少的匹配内容
贪婪 ----------> 非贪婪 *? +? ?? {m,n}?
re.findall(r'ab*?',"abbbbbcde")
# ['a']
re.findall(r'ab+?',"abbbbbcde")
# ['ab']正则表达式分组
概念
使用()可以为正则表达式建立子组,子组不会影响正则表达式整体的匹配内容,可以被看作是一个局部整体单元
子组的作用
形成内部整体,改变某些元字符的行为(比如重复,或等)
re.search(r"(ab)+","ababababababcd").group()
# 'abababababab'
re.search(r"\w+@\w+\.(com|cn)","www@123.cn").group()
# 'www@123.cn'子组匹配内容可以被单独获取(group(1))
re.search(r'(ab)+','ababababcdef').group(1)
# 'ab'子组注意事项
一个正则表达式中可以有多个子组,区分第一、第二、… 子组
子组不应该出现重叠的情况,尽量简单
捕获组和非捕获组 (命名组,非命名组)
格式:(?P<名字>正则表达式)
re.search(r"(?P<你好>ab)+","ababababababcd").group()
# 'abababababab'
re.search(r"(?P<你好>ab)+","ababababababcd").gro updict()
# {'你好': 'ab'}作用
方便通过名字区分每个子组
捕获组可以重复调用
格式:(?P=name) (?P<dog>ab)cd(?P=dog) ===> abcdab
re.search(r'(?P<dog>ab)cd(?P=dog)',"abcdab").group()
# 'abcdab're模块的使用
这里就不深入了,怕疼!
给一张图欣赏一下就好了,不怕疼的自己去研究一下,或者等适应了之后咱们后面在深入!

实战——抓取猫眼电影top100榜单
简单说就是去猫眼电影网站,然后爬取电影top100榜单,将其电影名,主演,上映时间,存入到本地
我们一起来分析一下
1、思路分析
访问页面——》下载页面——》解析页面——》——》保存数据
2、功能分析
1、可以自由控制爬取数据的多少(总共100条数据)
2、需要将每一部电影的名字、导演、上映时间提取出来
3、以CSV的格式保存在本地
3、找URL规律
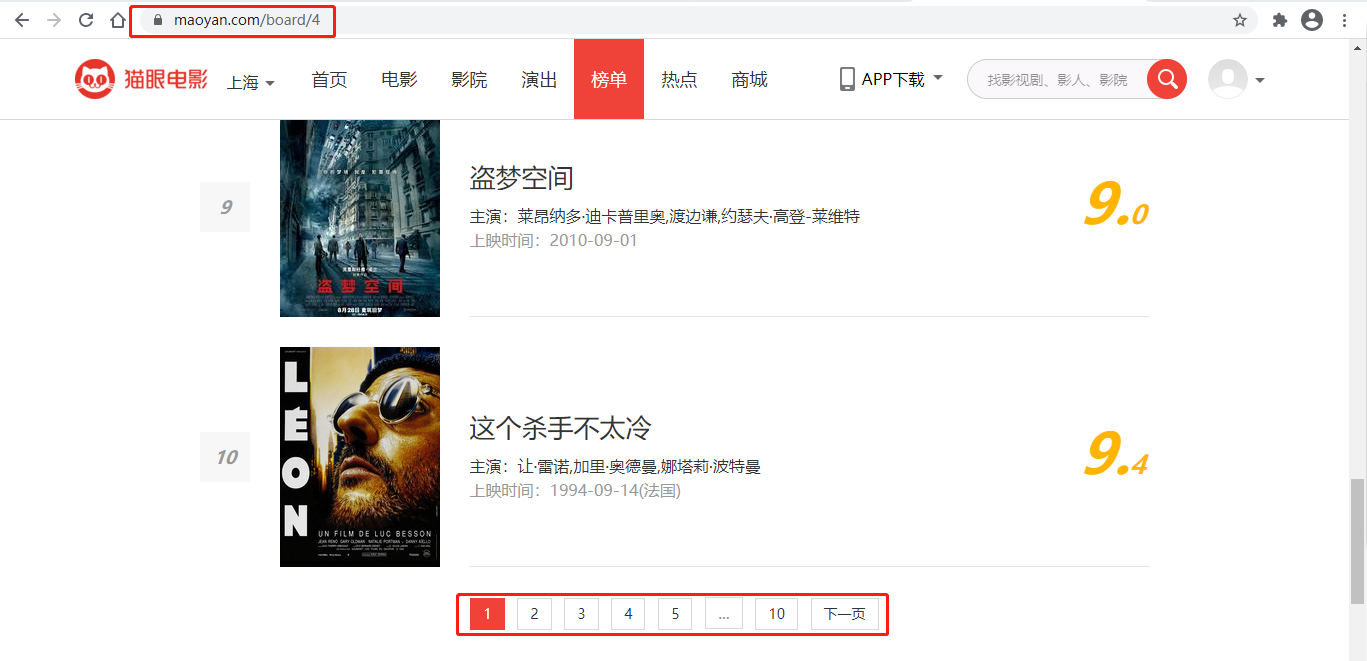
总共100条数据,每一页10条,共10页,是多少呢?
第一页
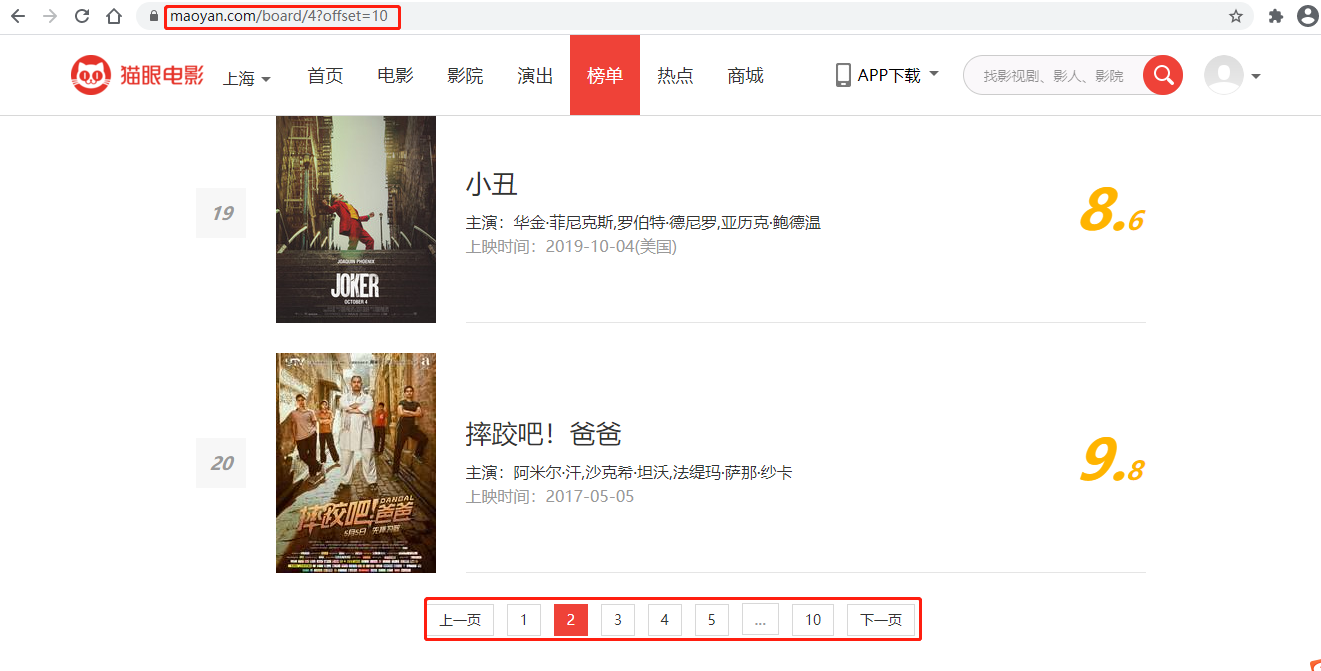
第二页
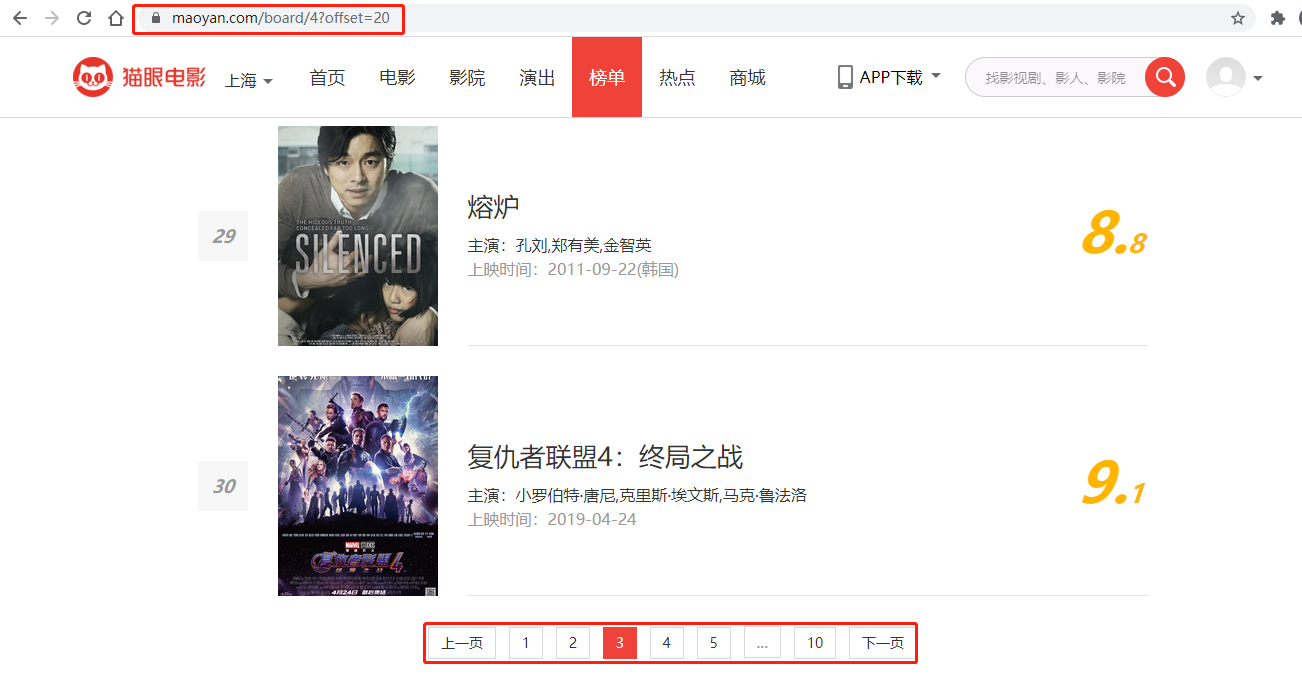
第三页
总结一下:
第1页:http://maoyan.com/board/4?offset=0
第2页:http://maoyan.com/board/4?offset=10
第2页:http://maoyan.com/board/4?offset=20
第n页:offset = (n-1)*10
4、提数据,写正则
我们先看一下源代码,可以发现每一部电影的信息在一个<dd>的东西里面,而我们需要的信息在dd里面的<div class="movie-item-info"> ... ... <./div>里面,还真是够长的,你确定不考虑一下手术嘛
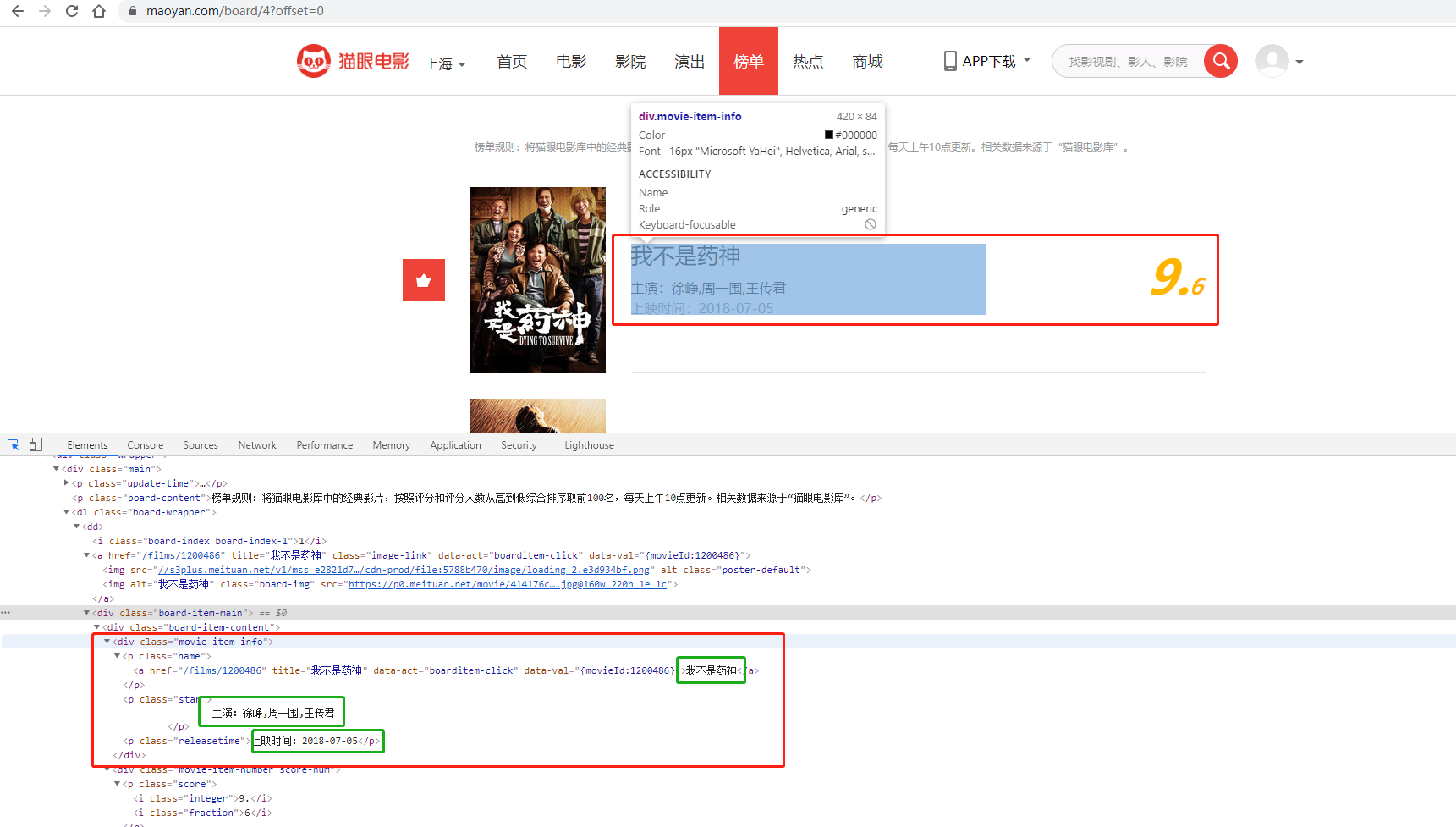
写正则
<div class="movie-item-info">.*?title="(.*?)".*?<p class="star">(.*?)</p>.*?releasetime">(.*?)</p>
5、写代码
导入一下用到的模块,为了温故而知新,这里我们用刚学过的urllib.request,另外呢,我把每一个小功能给写成了一个函数,最后封装了一下,哈哈哈
import urllib.request
import re
import csv按照之前的思路分析,我们一步一步来做
下载页面
def loadPage(self, url):
req = urllib.request.Request(url, headers=self.headers)
res = urllib.request.urlopen(req)
html = res.read().decode("utf-8")
self.parsePage(html)解析页面
# 解析页面
def parsePage(self, html):
p = re.compile('<div class="movie-item-info">.*?title="(.*?)".*?<p class="star">(.*?)</p>.*?releasetime">(.*?)</p>', re.S)
r_list = p.findall(html)
# 这里你可以输出一下,看看正则提取的数据是什么格式的
# print(r_list)
self.writePage(r_list)写入数据
# 写入文件
def writePage(self, r_list):
if self.page == 1:
# 打开CSV文件
with open("猫眼电影.csv", "a", newline="") as f:
# 初始化写入对象
writer = csv.writer(f)
# 在CSV文件开头初始化写入一行数据
writer.writerow(["电影名称", "主演", "上映时间"])
for r_tuple in r_list:
with open("猫眼电影.csv", "a", newline="") as f:
# 创建写入对象
writer = csv.writer(f)
L = [r_tuple[0].strip(), r_tuple[1].strip(), r_tuple[2].strip()]
# 同样的你可以在这里看一下拿到的数据
# print(L)
writer.writerow(L)完
对源码感兴趣的可以关注一下明哥的公众号,回复:猫眼,获取
















 666
666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









