







数据库隔离级别
`提示:以下演示数据库版本均为mysql5.7
文章目录
前言
数据库事务是日常开发工作中经常使用到的,要想深入理解数据库事务,需要先了解数据库的四大隔离级别的特点,以及他们对数据库事务的影响,才能知道实际运用数据库事务的时候如何编写业务代码
数据库事务(从上到下的隔离性依次递增):
1.读未提交-RU(read-uncommited)
2.读已提交-RC(read-commited)
3.可重复读-RR(repeatable-read)
4.串行化-SR(SERIALIZABLE)
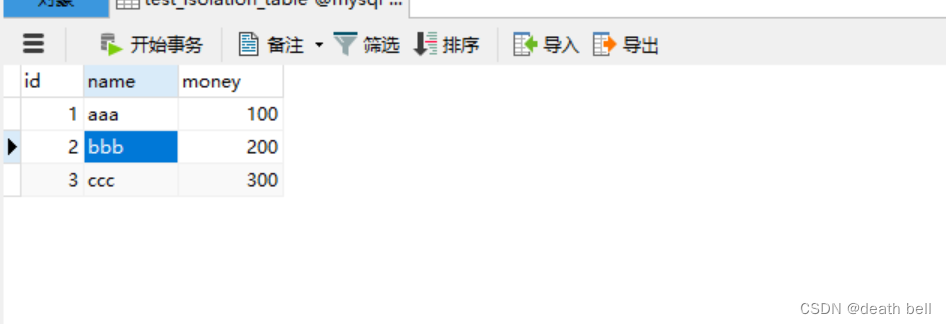
一、新建一张测试表,插入三条数据
DROP TABLE IF EXISTS `test_myisam`;
CREATE TABLE `test_myisam` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
INSERT INTO `test_isolation_table` VALUES (1, 'aaa', 100);
INSERT INTO `test_isolation_table` VALUES (2, 'bbb', 200);
INSERT INTO `test_isolation_table` VALUES (3, 'ccc', 300);
二、查询当前的数据库事务隔离等级
1.
代码如下(示例):
show variables like '%tx_isolation%';
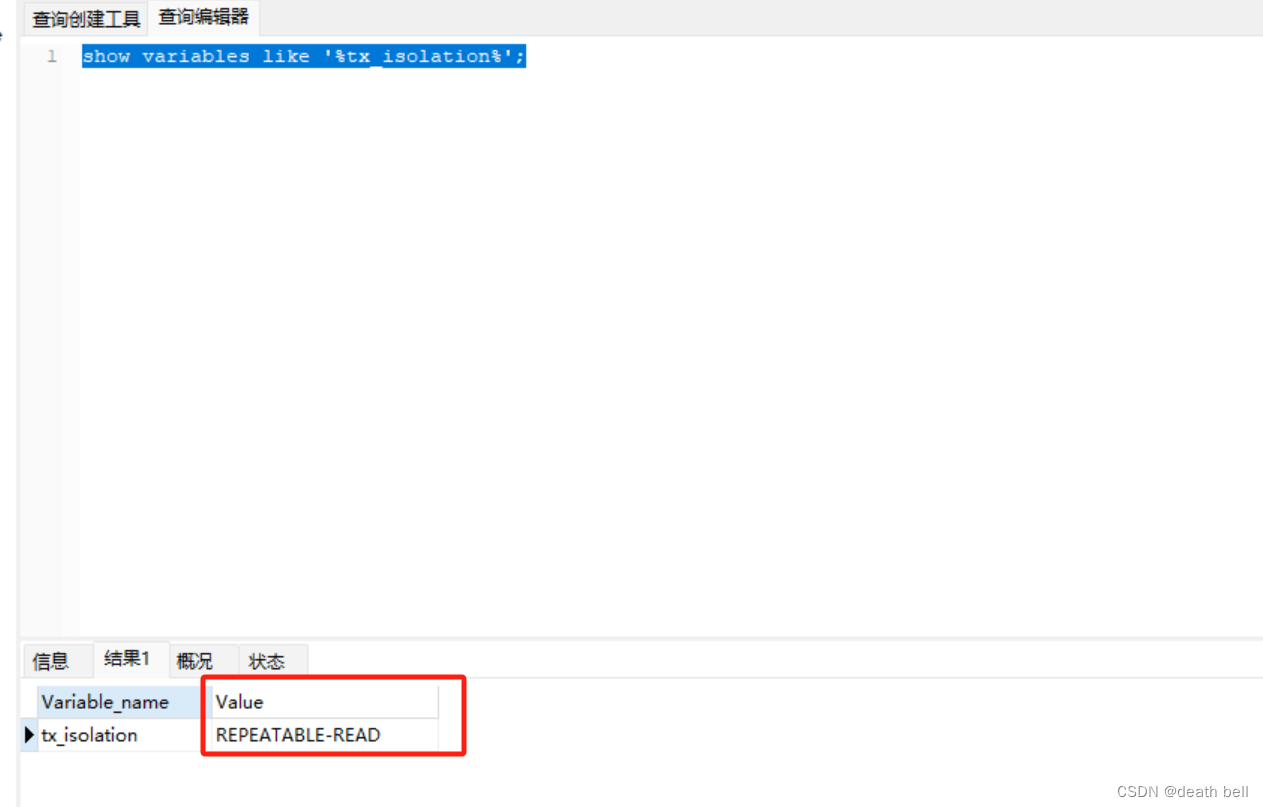
可以看到默认的数据隔离登记是REPEATABLE-READ (可重复读)
1.实验读未提交(READ-UNCOMMITTED)
`提示:以下每个实验之间结束最好都要commit当前事务,以免出现未提交事务导致结果和预料不一样情况,影响理解。
新建两个查询窗口,分别开启两个事务进行测试:
事务一代码:
SET autocommit = 0; #关闭自动提交
set tx_isolation='read-uncommitted'; #设置读未提交
begin; #开启事务
select *from test_isolation_table;
#COMMIT;
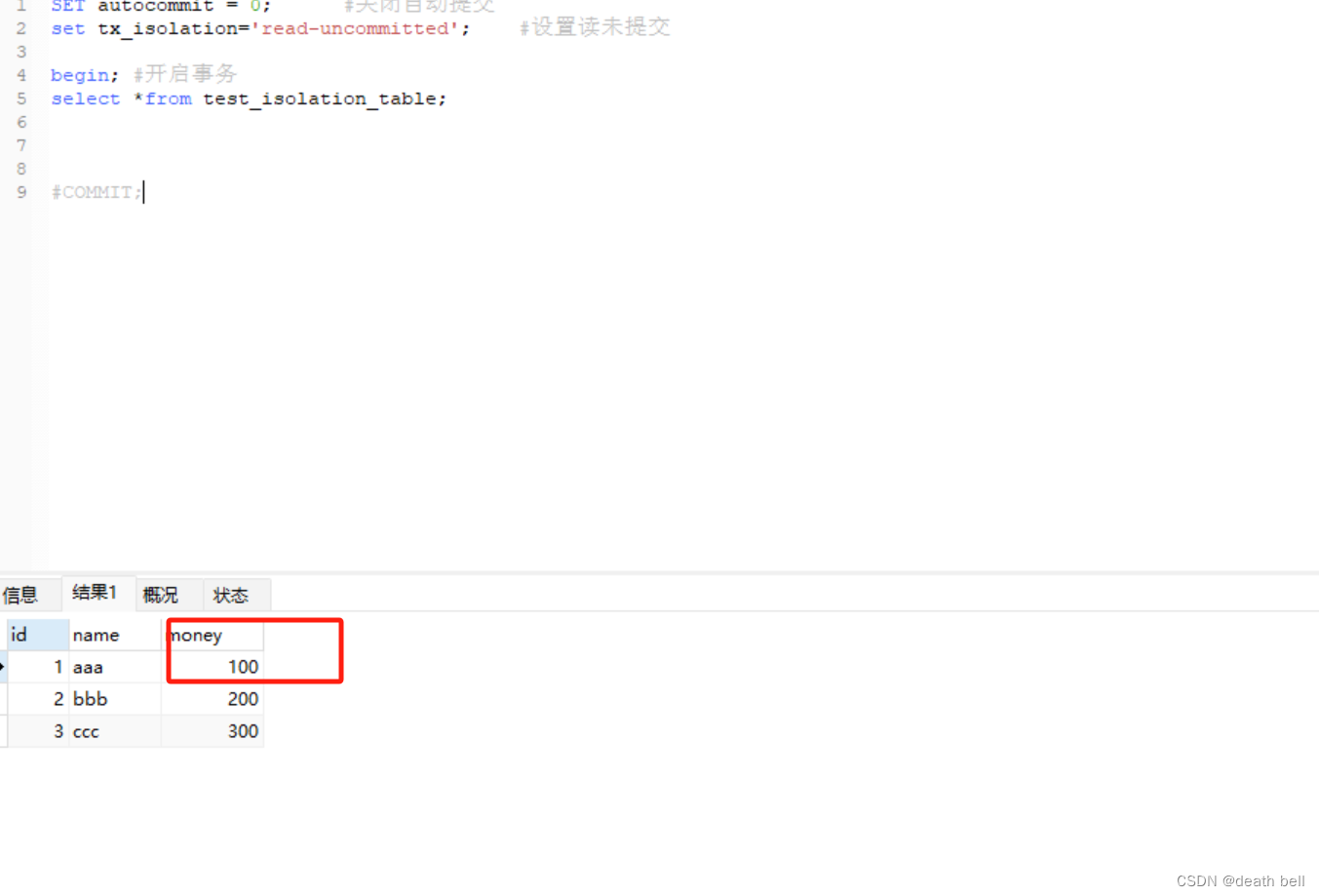
此时可以看到id为1的金额还是100
事务二代码:
SET autocommit = 0; #关闭自动提交
set tx_isolation='read-uncommitted'; #设置读未提交
begin ;#开启事务
update test_isolation_table set money = 500 where id = 1
#COMMIT;
更新id为1的金额为500,但事务未提交(两个事务的COMMIT均先注释)
单独执行事务1的查询语句:
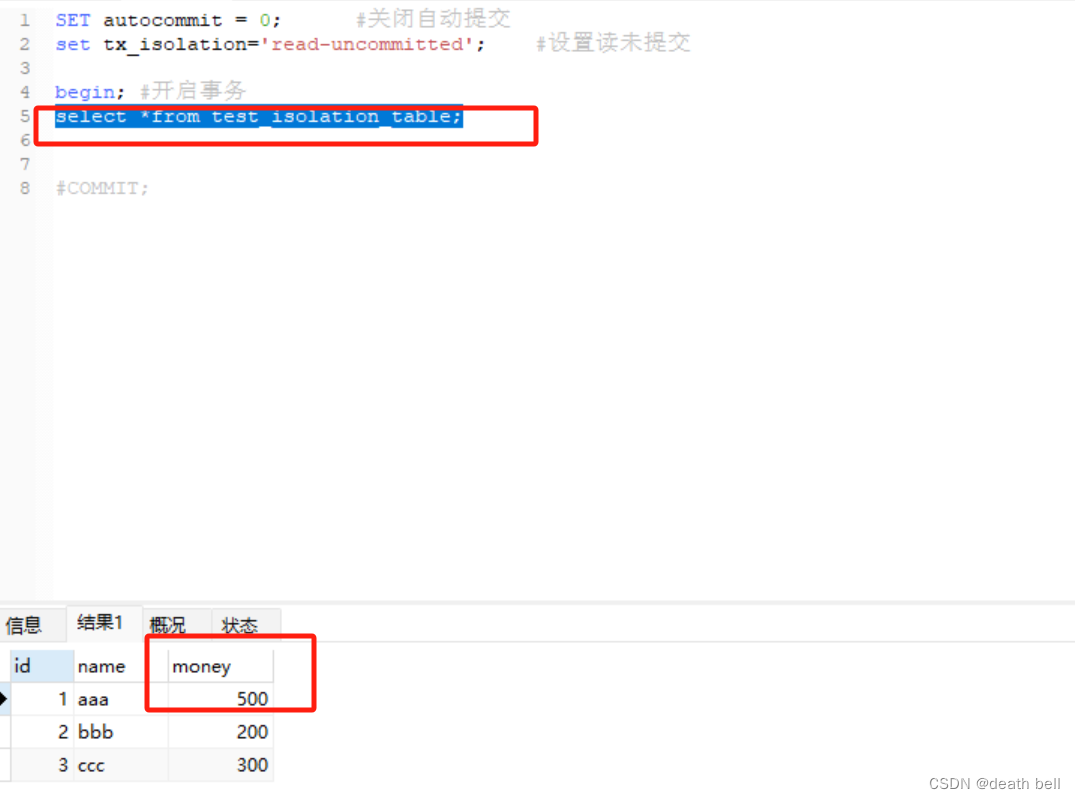
可以看到事务1已经读取到最新未提交的数据
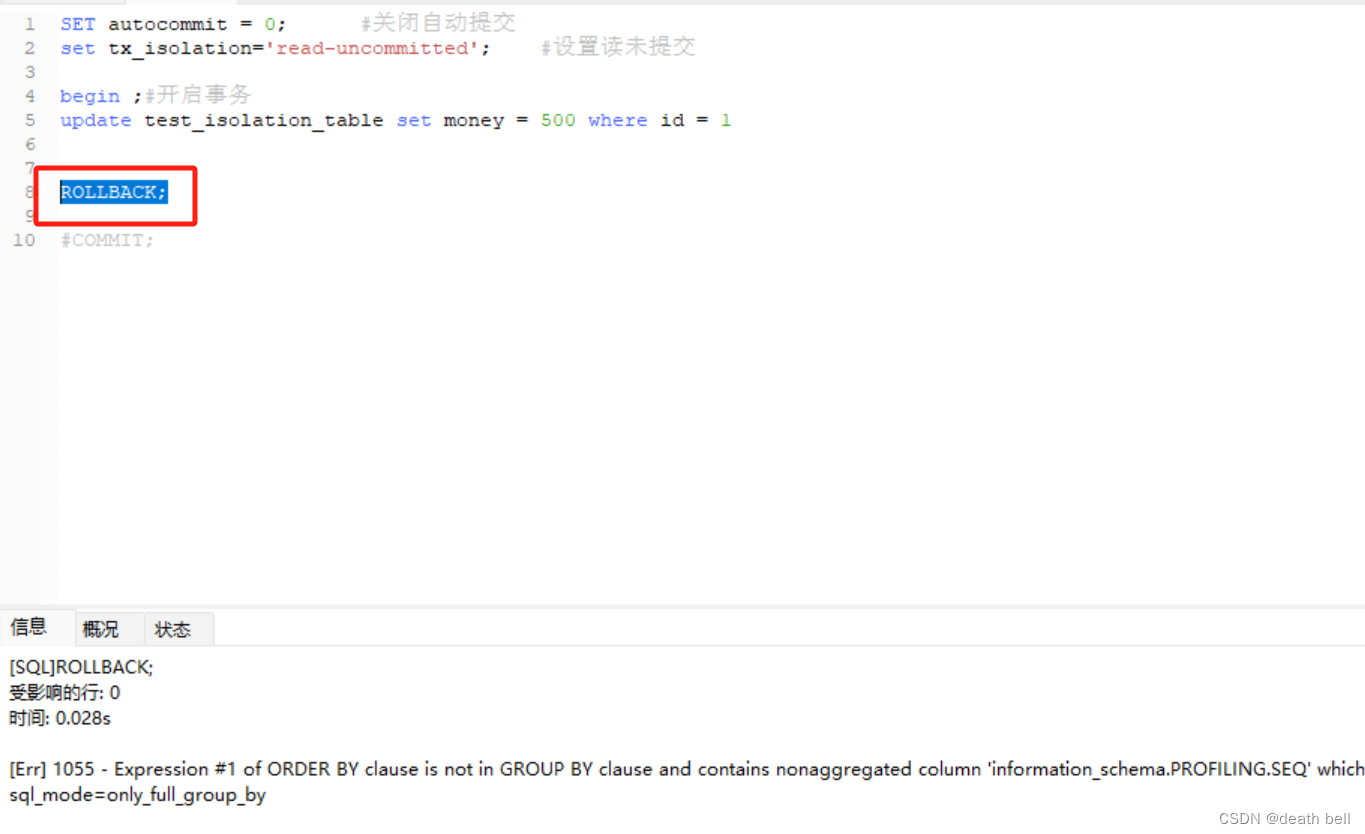 单独回滚事务2数据
单独回滚事务2数据
再次查询事务1的查询语句
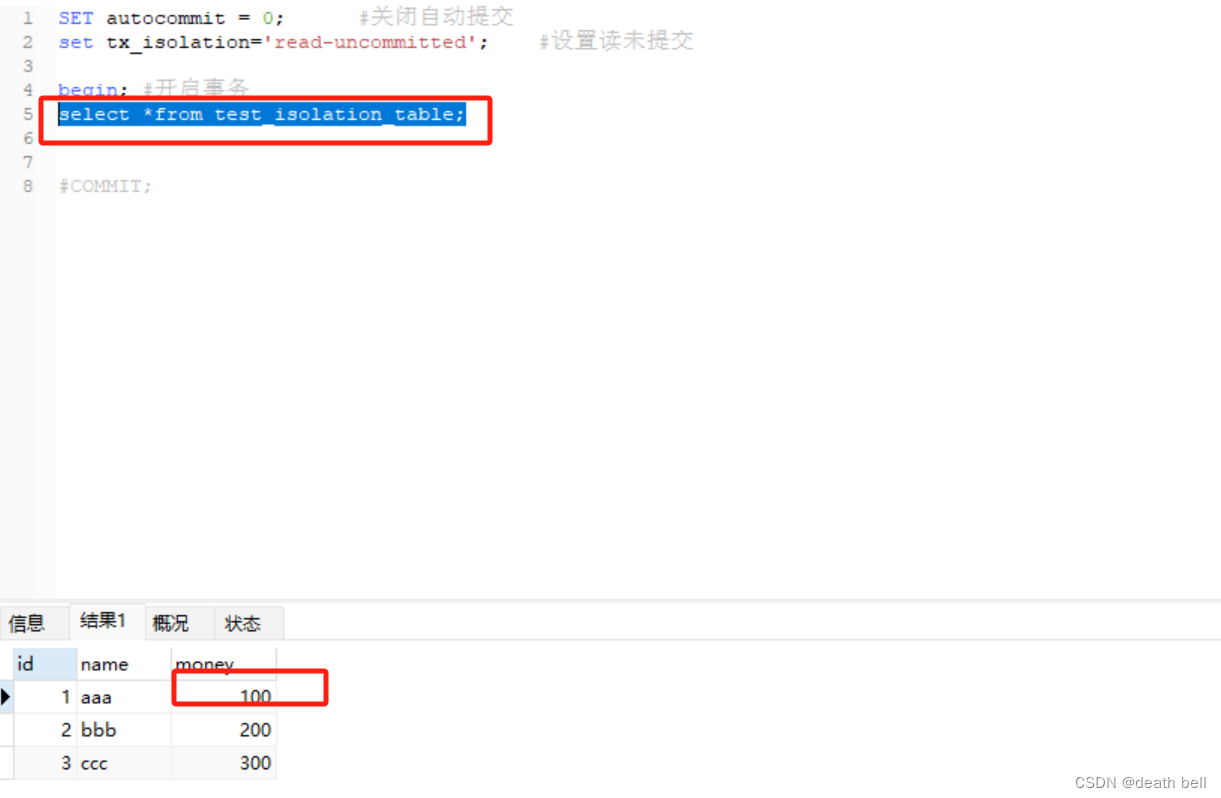
可以看到此时事务读取到的数据回到100
该隔离级别可能产生的问题:
1.脏读(事务A因为另一个事务的回滚导致读取到无效数据)
2,脏写(事务A因为另一个事务的回滚导致读取到无效数据,并用数据进行处理入库)
2.实验设置读已提交(READ-COMMITTED)
事务一代码:
SET autocommit = 0; #关闭自动提交
set tx_isolation='READ-COMMITTED'; #设置读已提交隔离级别
begin; #开启事务
select *from test_isolation_table;
#COMMIT;
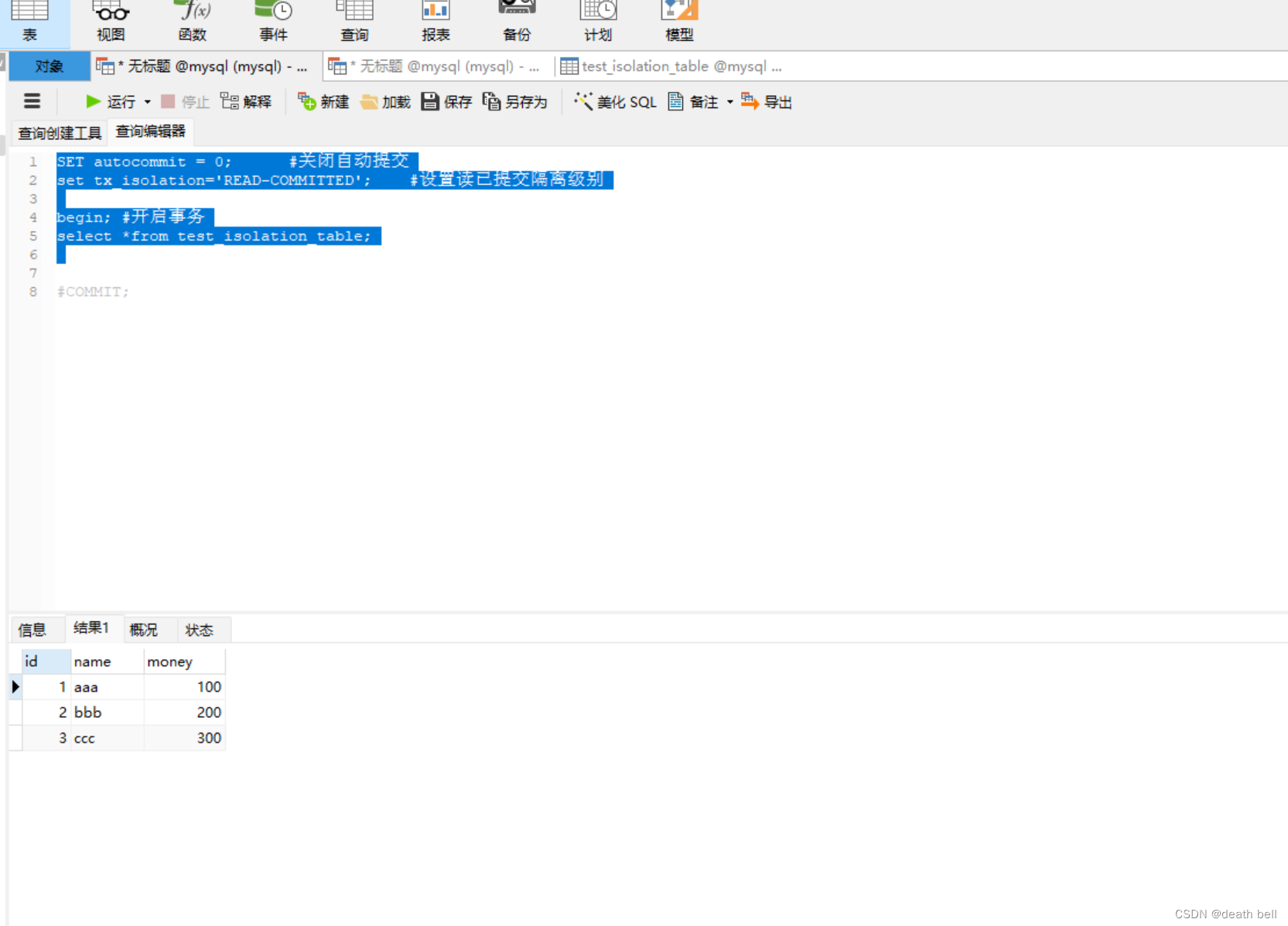
事务二代码:
SET autocommit = 0; #关闭自动提交
set tx_isolation='READ-COMMITTED'; #设置读已提交隔离级别
begin ;#开启事务
update test_isolation_table set money = 500 where id = 1
#COMMIT;
事务一查询:
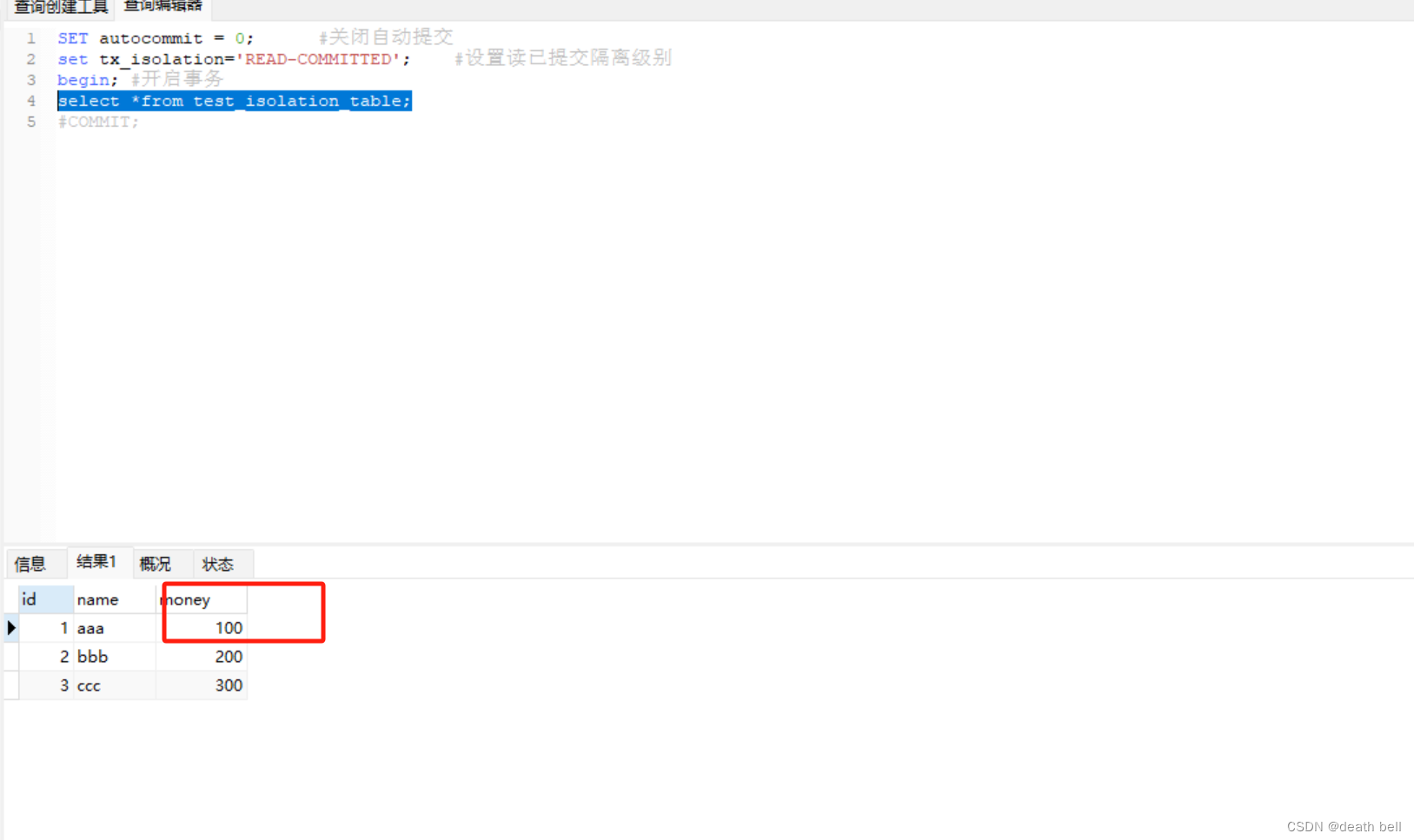
此时金额还是100 因为事务2事务未提交
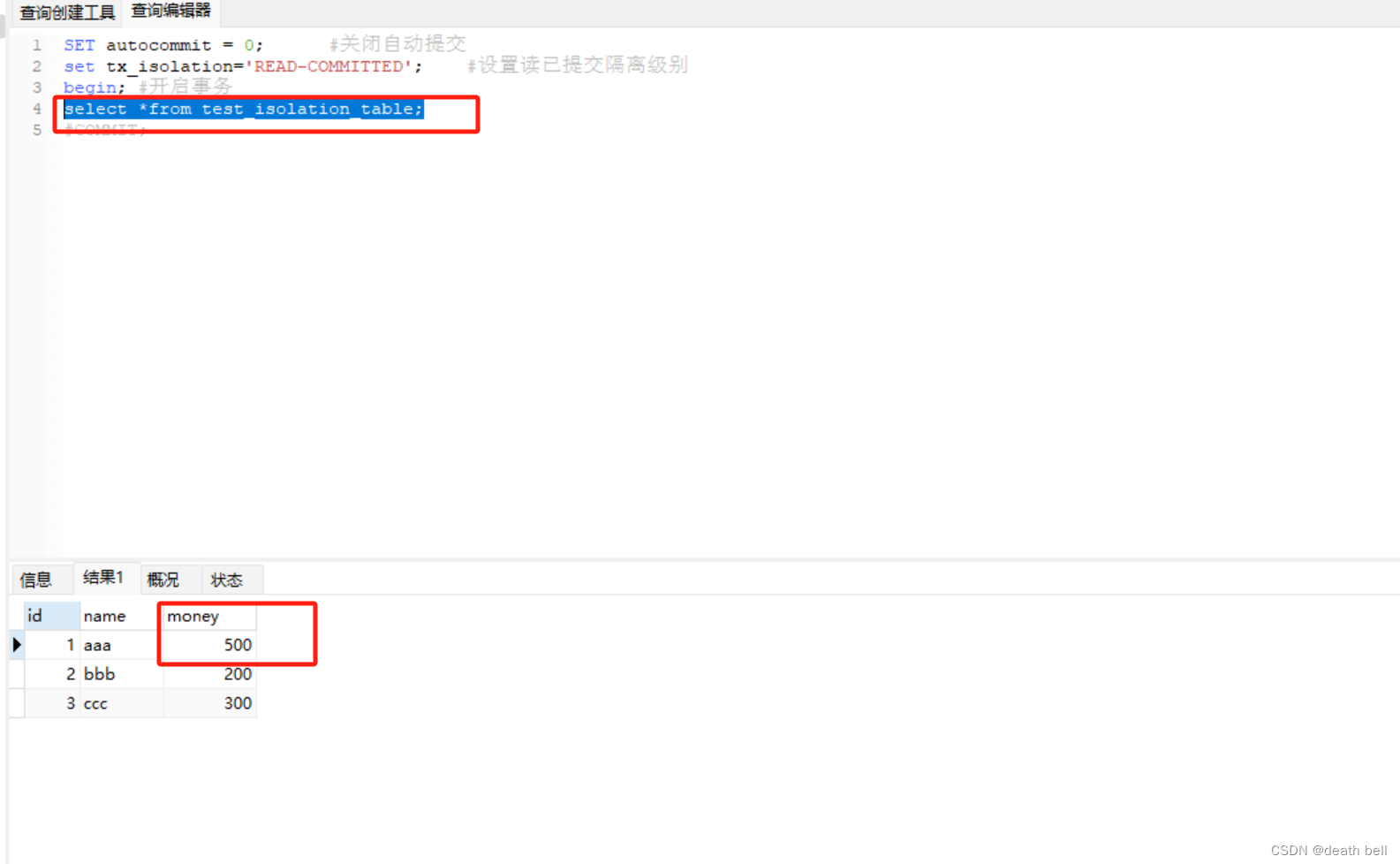
提交事务2
事务1再查询已经是500
该隔离级别可能产生的问题:
1.不可重复读(事务在不同的时间点查询到的数据可能不一致)
2,幻读(同一查询在不同时间执行,结果不一致)
3.实验设置可重复读-RR(REPEATABLE-READ)
事务1代码:
SET autocommit = 0; #关闭自动提交
SET tx_isolation = 'REPEATABLE-READ'; #设置可重复读隔离级别
begin; #开启事务
select *from test_isolation_table;
#COMMIT;
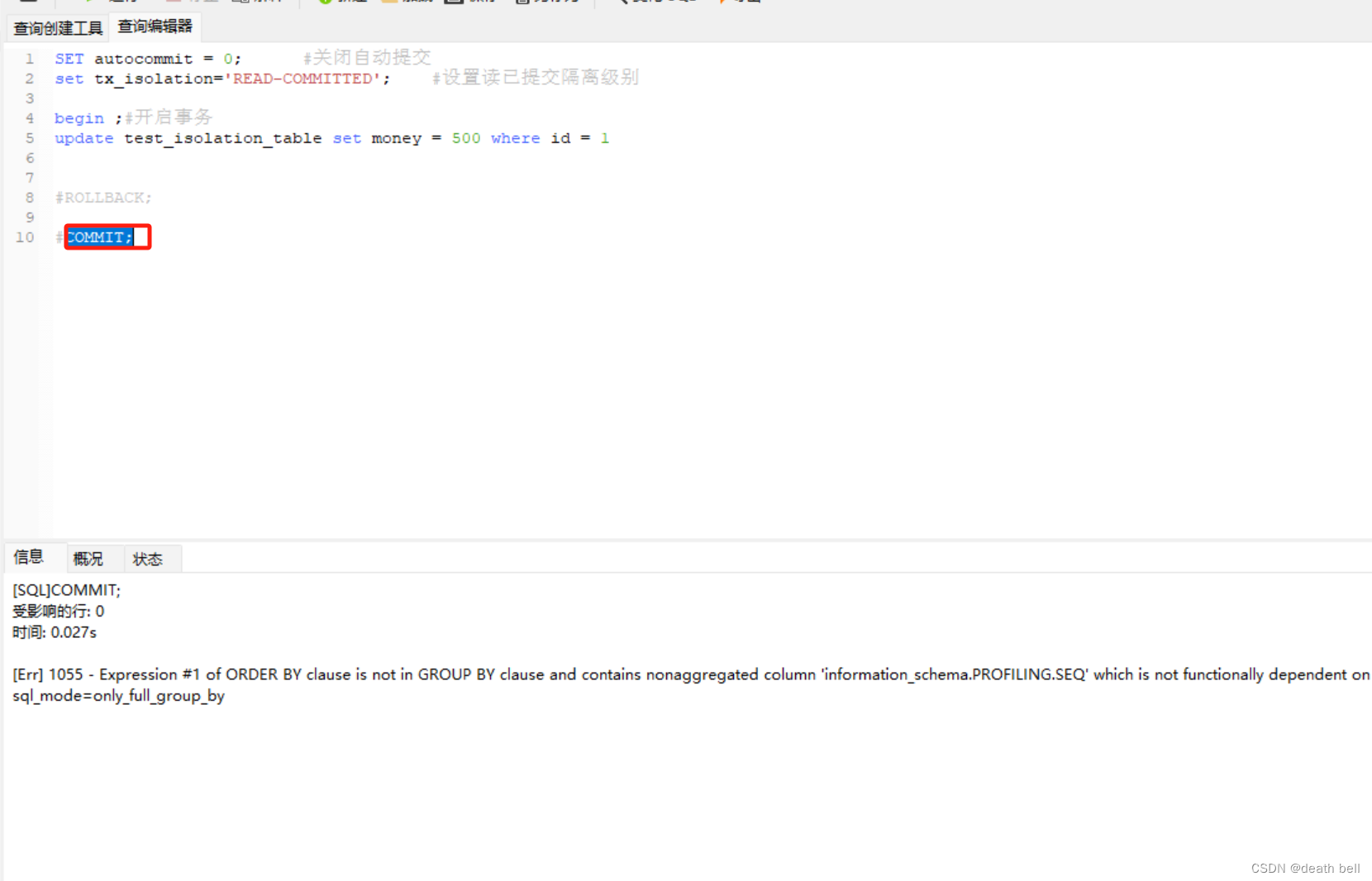
事务2代码:
SET autocommit = 0; #关闭自动提交
SET tx_isolation = 'REPEATABLE-READ'; #设置可重复读隔离级别
begin ;#开启事务
update test_isolation_table set money = 500 where id = 1
#ROLLBACK;
COMMIT;
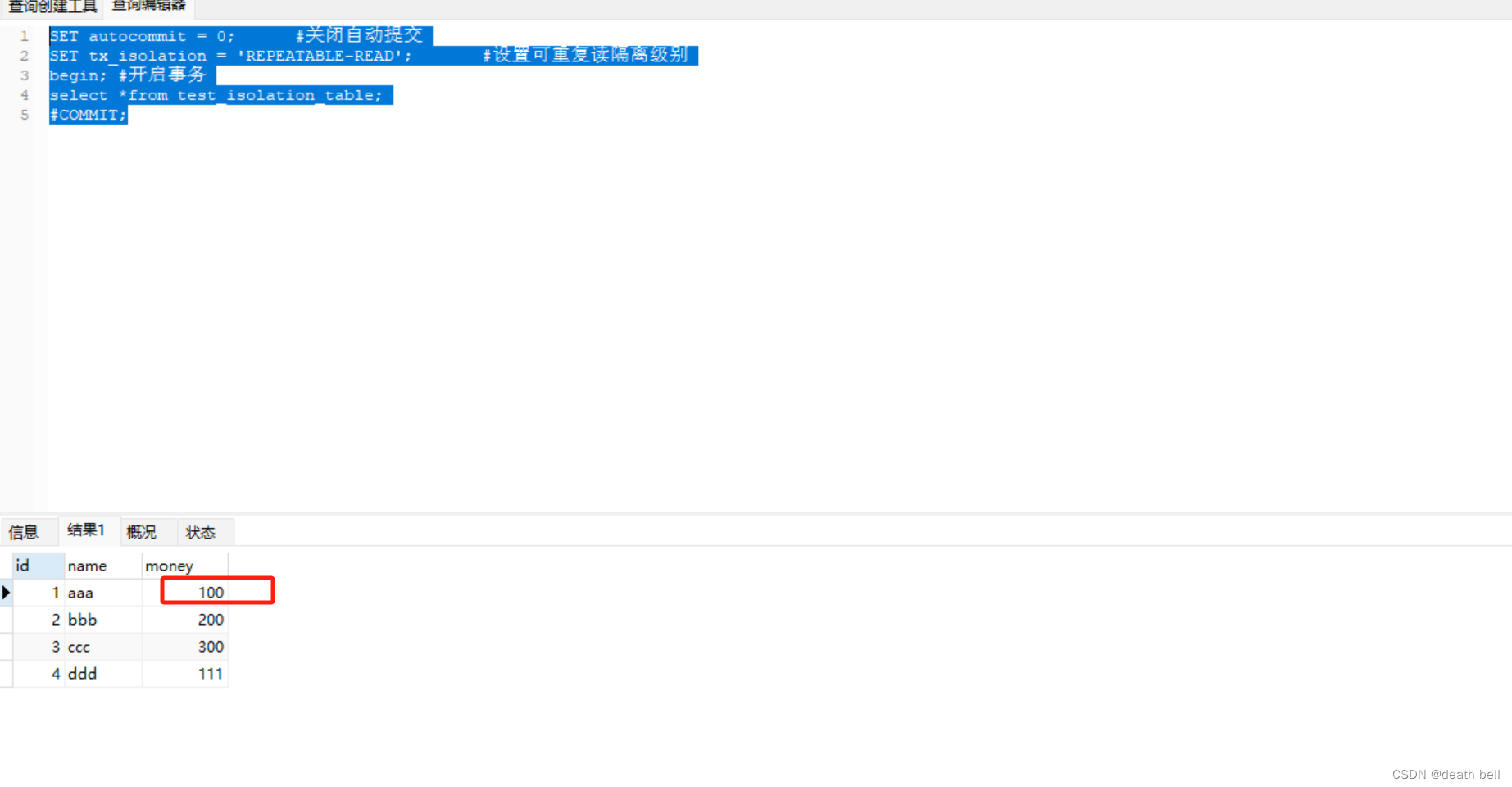
事务2已经更新数据并已经提交事务,但是事务1继续查询仍是100
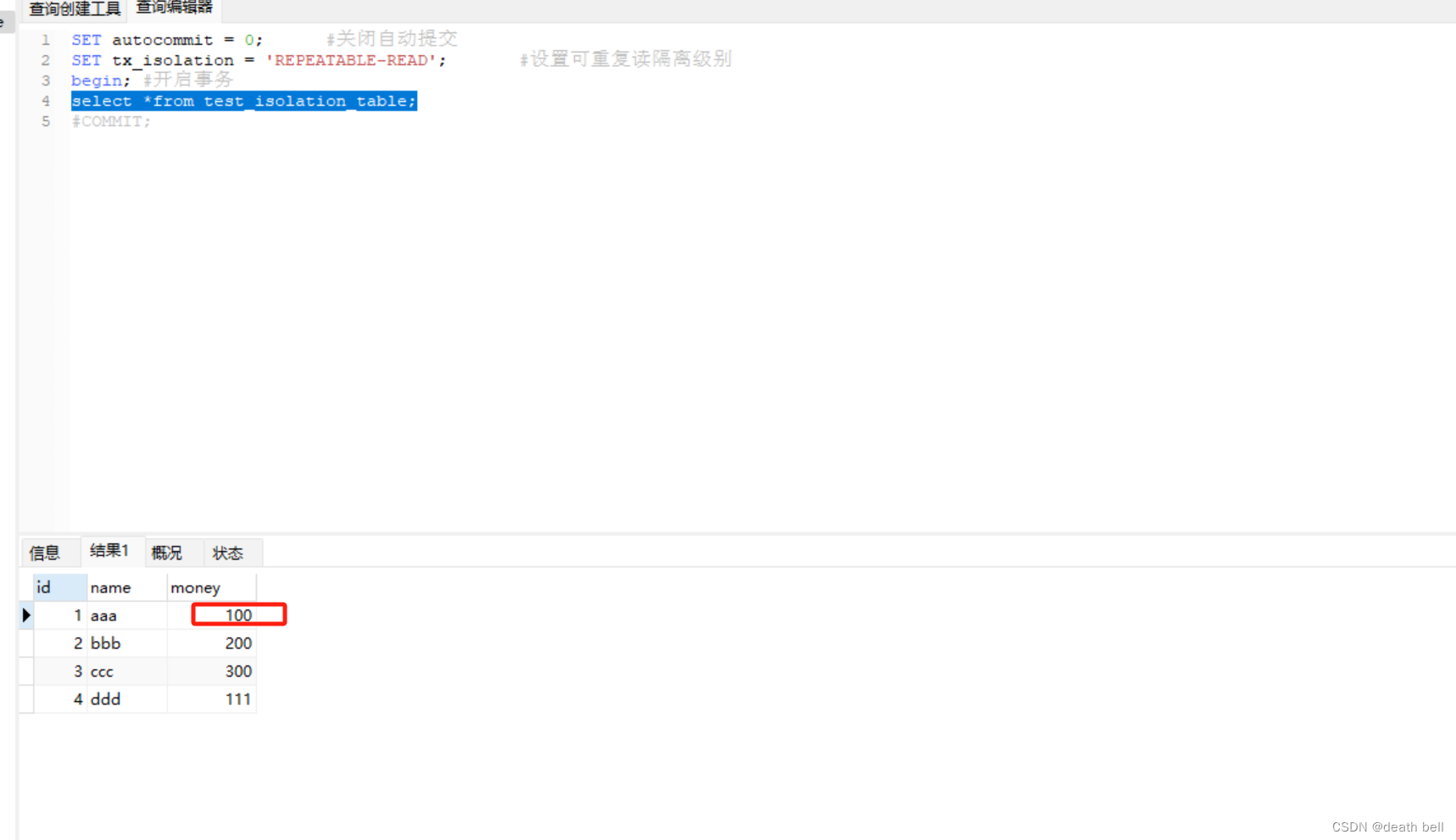
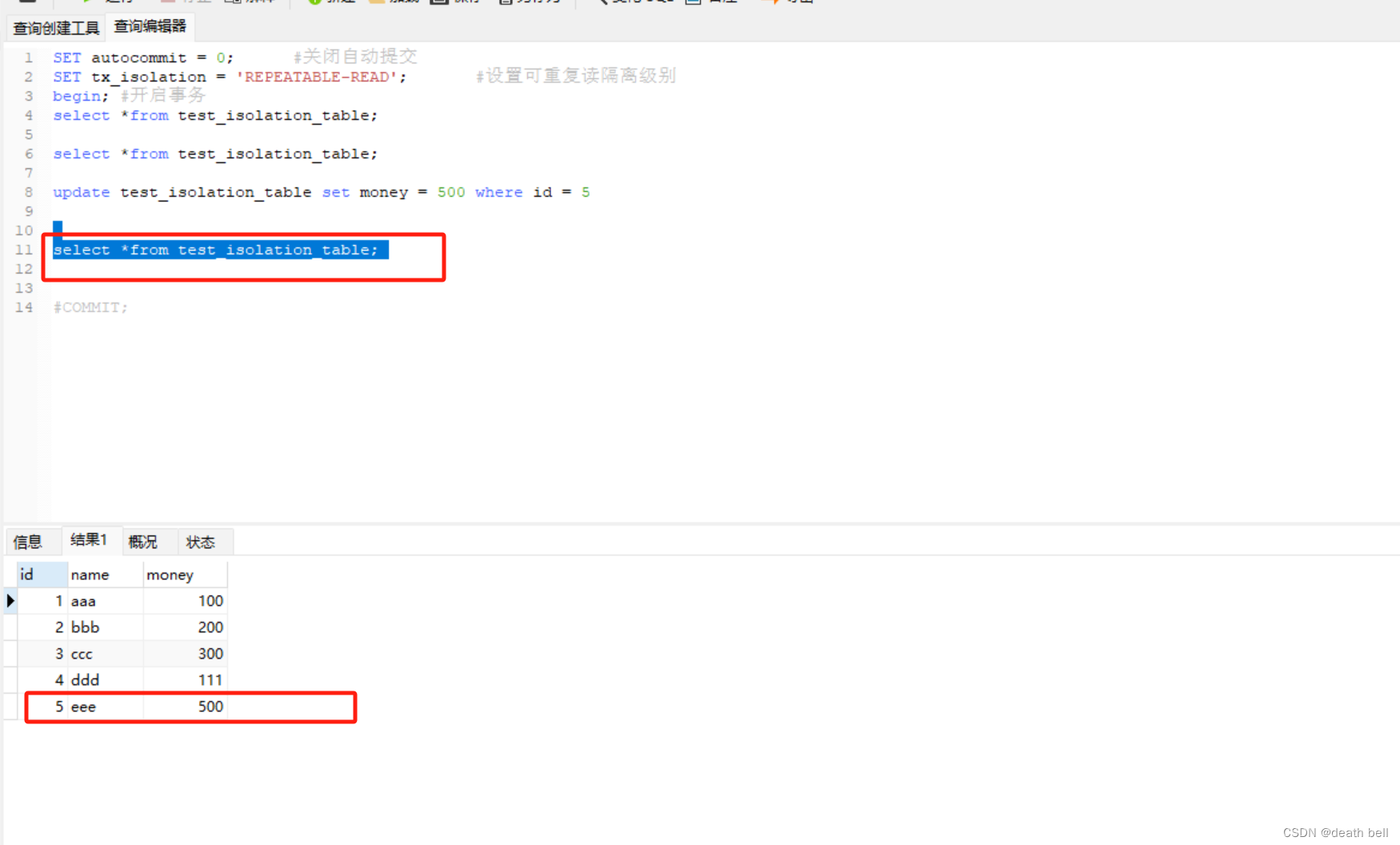
此时再次新建一个与事务1相同代码的事务3进行查询 发现金额可以查到最新的数据
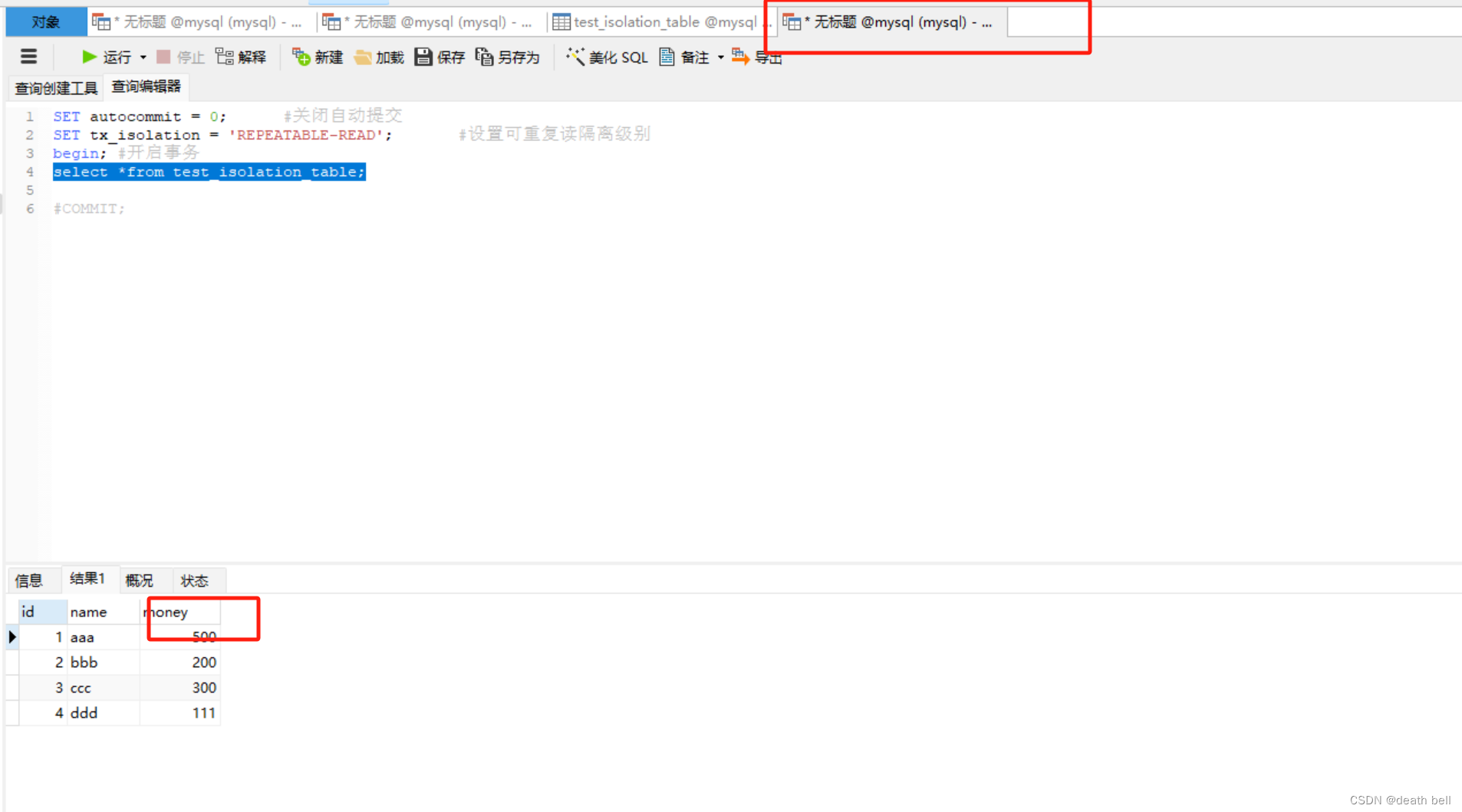
但是该隔离级别解决了不可重复读问题,幻读问题依旧存在,我们在表中增加一行数据
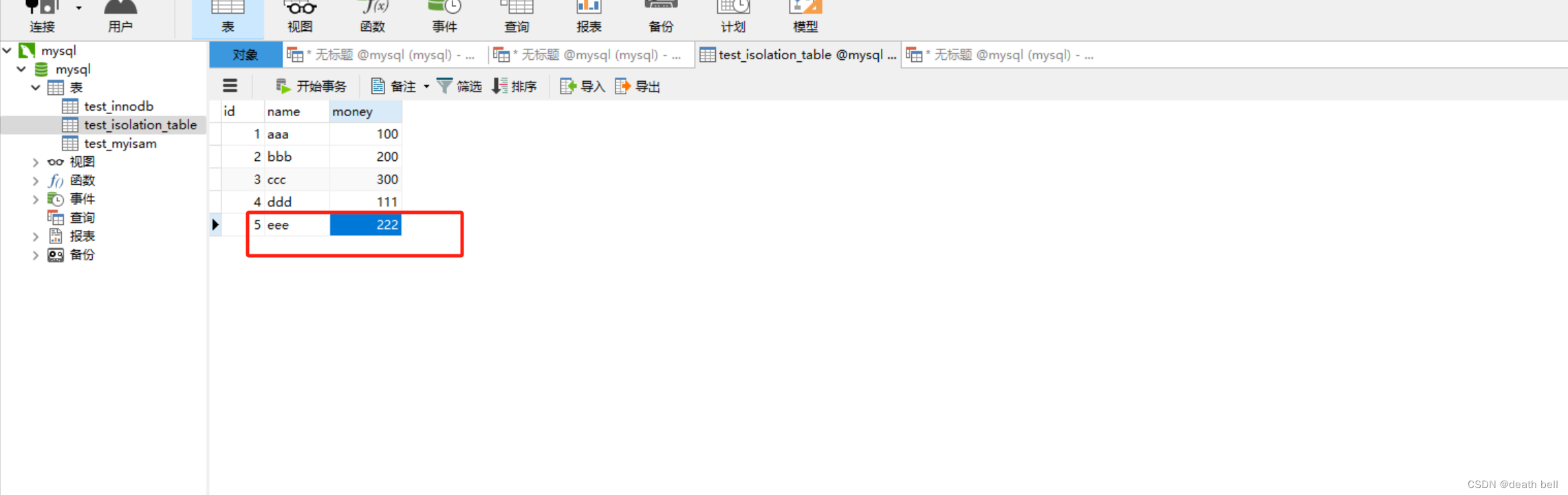
事务1继续查询还是过去的条数
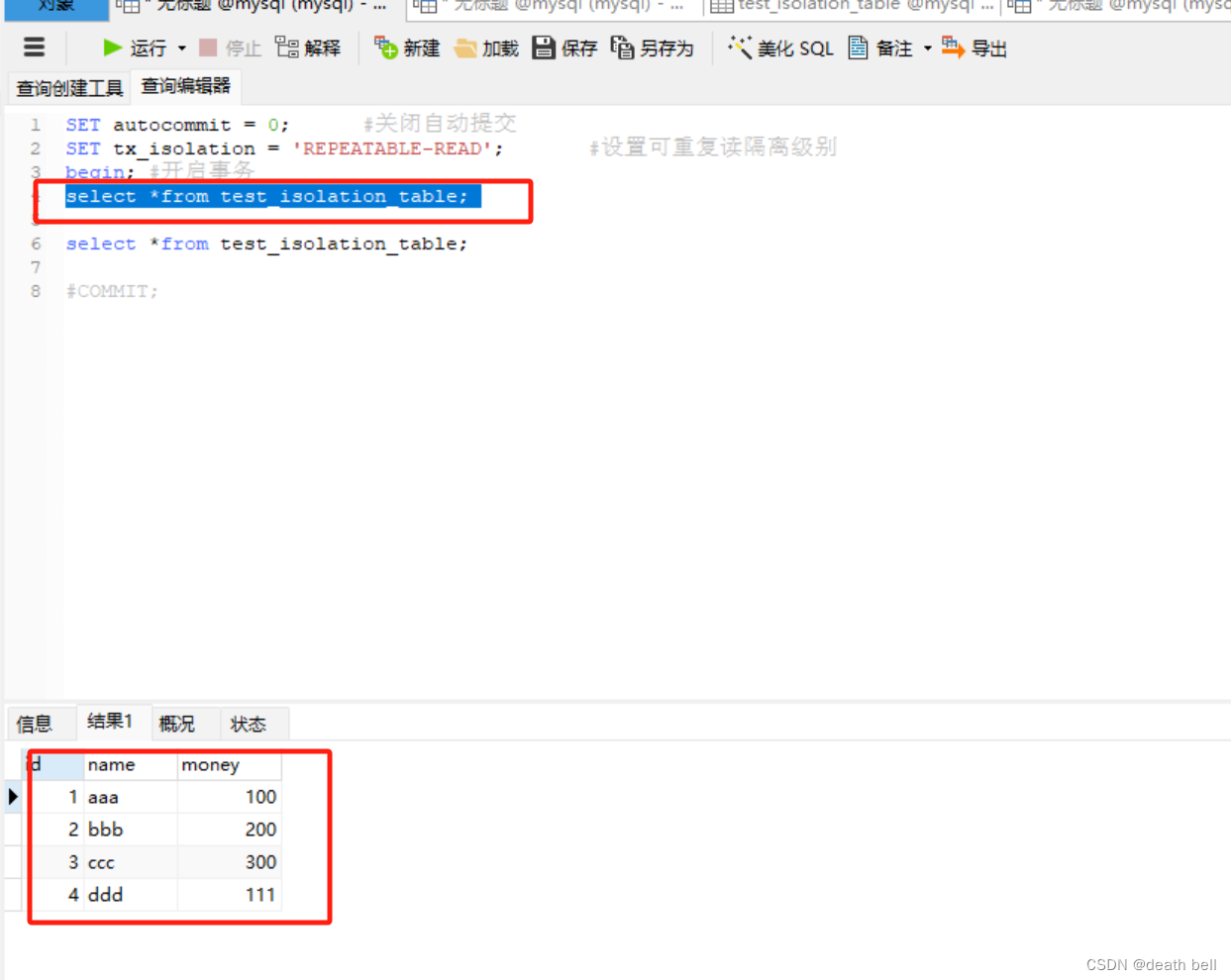
但是如果更新id为5的数据
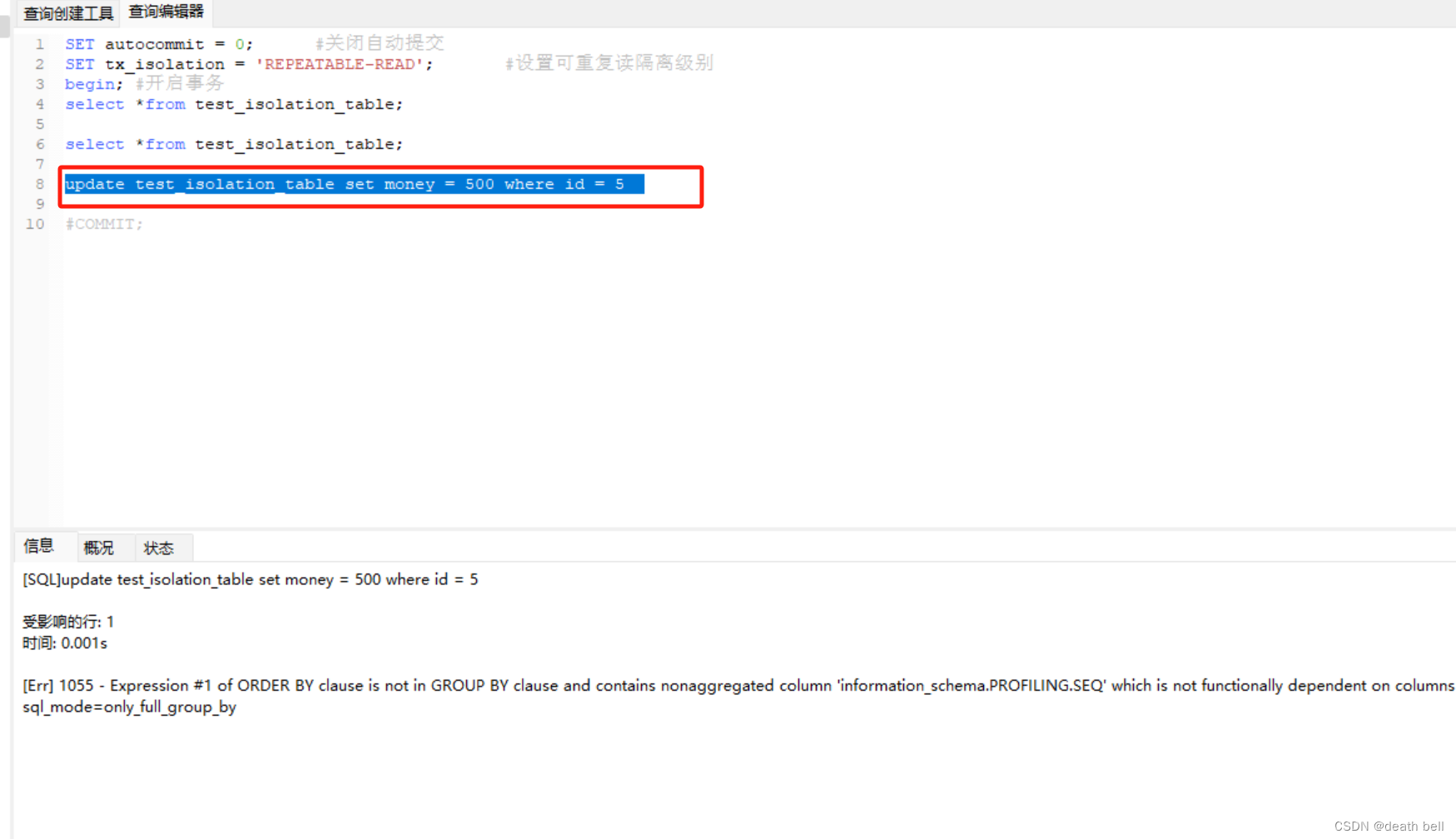
再次查询,发现已经能查询到之前查询不到的数据,幻读问题出现。因为数据库update的时候实际上是更新的最新已提交的数据,该隔离级别如果中间有update操作,可能会出现幻读问题,即读取的别的事务的新增数据
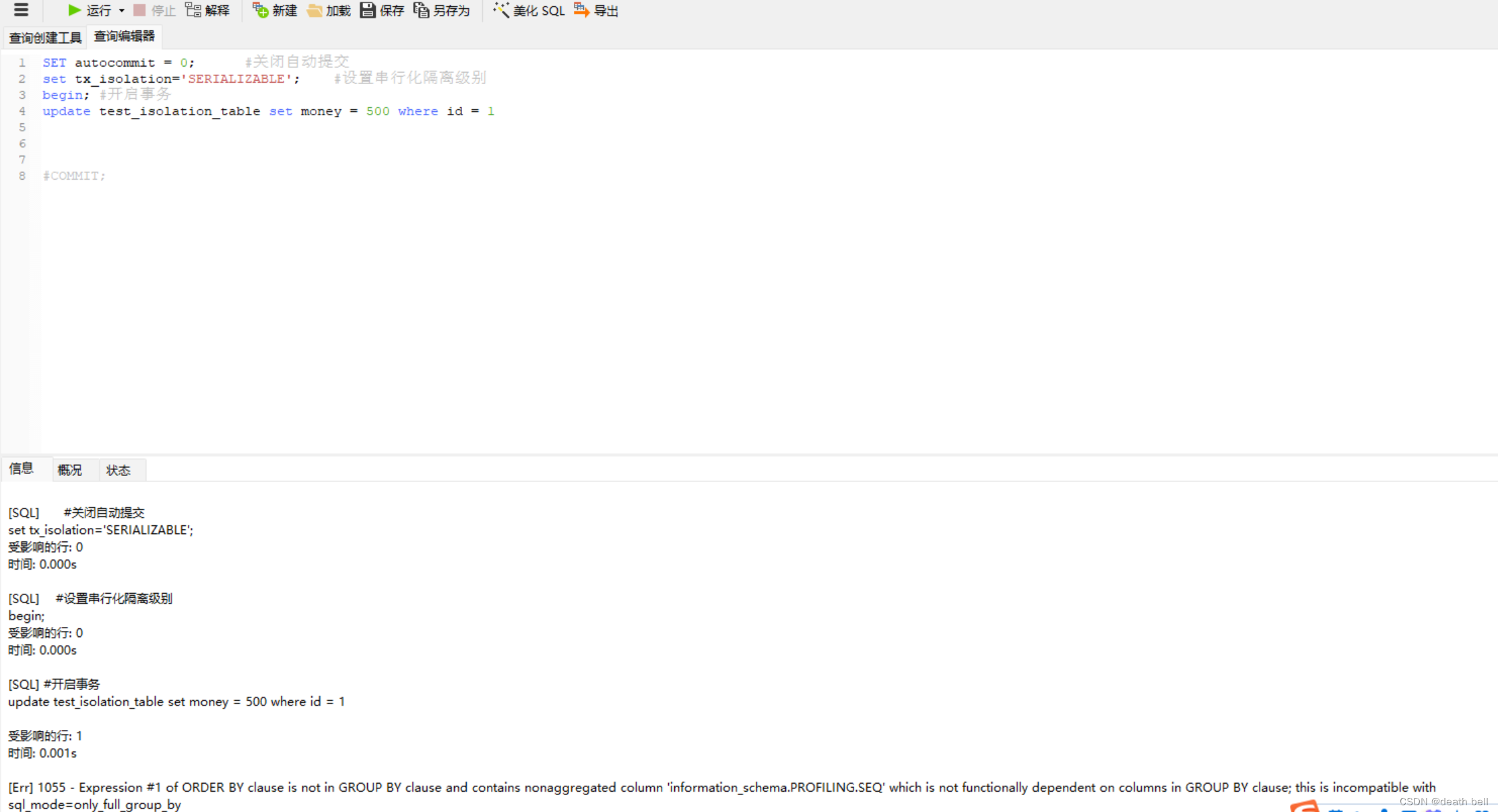
4.串行化-SR(SERIALIZABLE)
SET autocommit = 0; #关闭自动提交
set tx_isolation='SERIALIZABLE'; #设置串行化隔离级别
begin; #开启事务
update test_isolation_table set money = 500 where id = 1
#COMMIT;
事务1代码:
SET autocommit = 0; #关闭自动提交
set tx_isolation='SERIALIZABLE'; #设置串行化隔离级别
begin; #开启事务
select *from test_isolation_table;
#COMMIT;
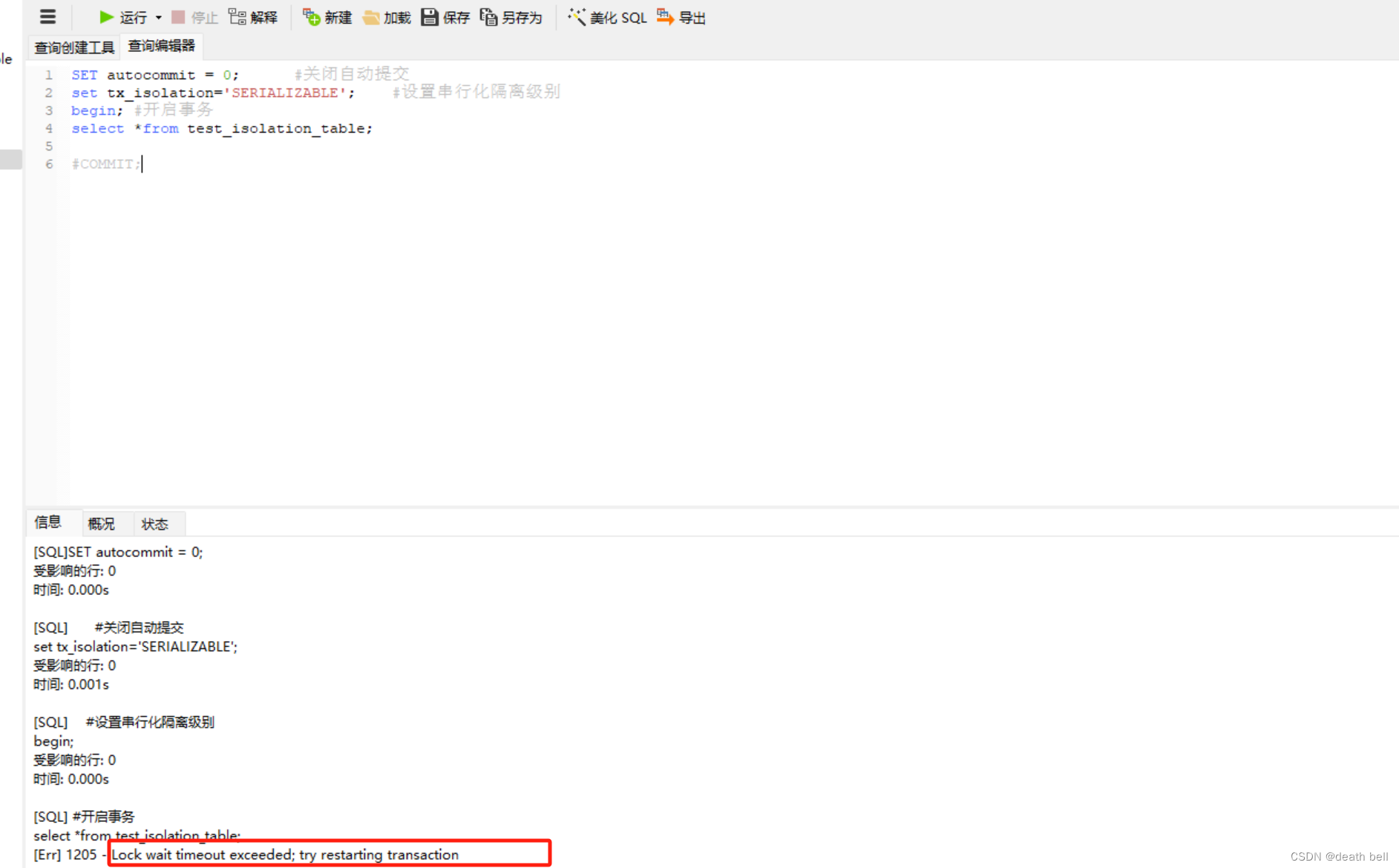
此时事务1正在等在事务2释放锁资源,此时查询不到数据
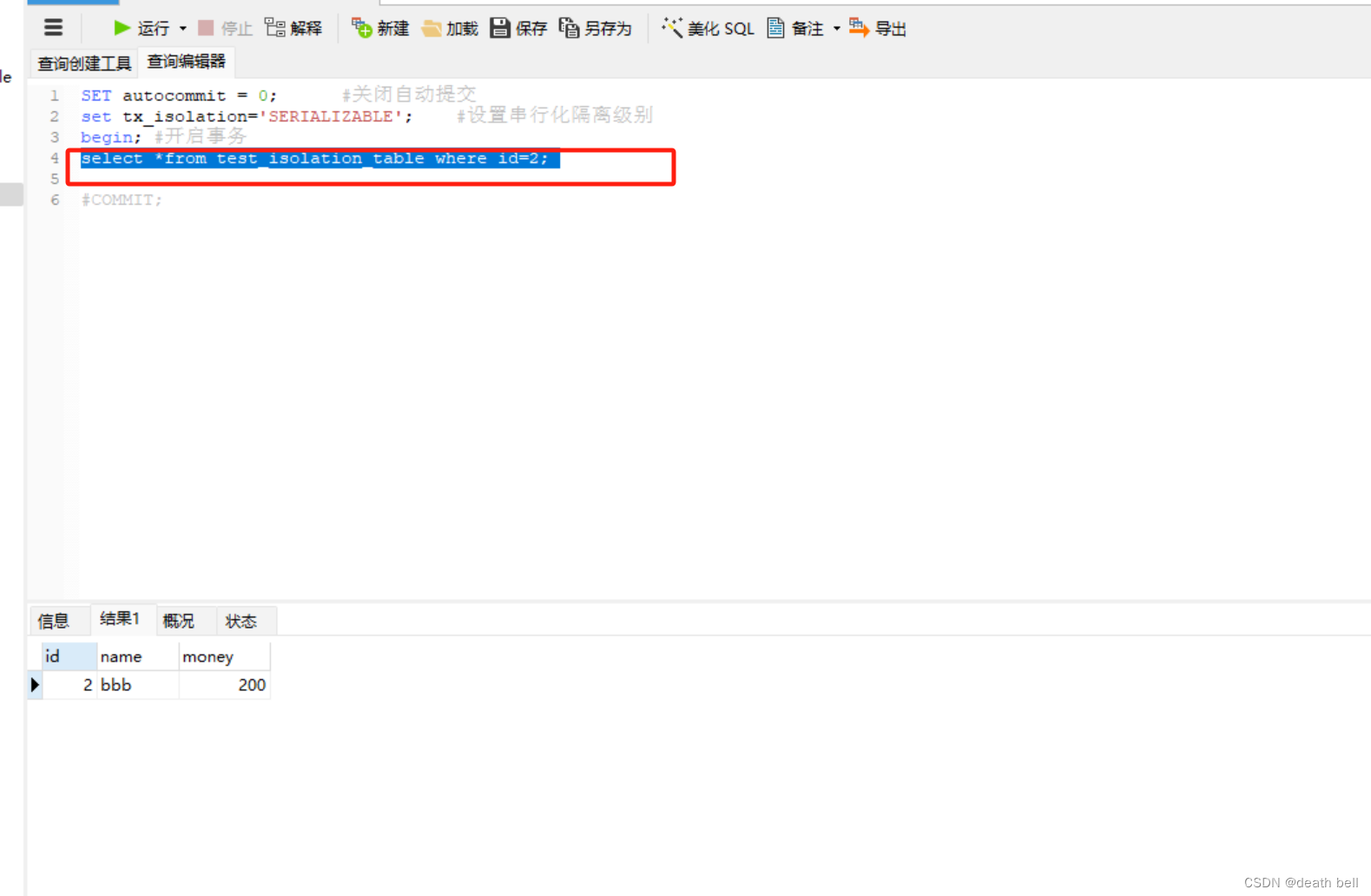
此时查询改成id为2的数据能查询出来,改成1仍等待锁,说明事务2给表上了一个行锁
该隔离级别是最高的隔离级别,确保事务串行执行,避免了脏读、不可重复读和幻读。
通过锁定数据的方式实现,性能开销较大,一般情况下不建议使用。
总结
提示:这里对文章进行总结:
上面的实验步骤,深入浅出感受了四个隔离级别各自的特性以及优缺点,实际要深入了解背后的机制原理,还需要了解MySql的数据库mvcc实现原理以及各种锁机制来规避实际日常工作的事务开发问题。MVCC机制以及各种锁类型会在后续博文持续更新














 5850
5850











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









