







视频演示地址:https://www.bilibili.com/video/BV1bg411c7W7/
一、准备工作
在VMware官网下载虚拟机

本文使用到的centos为7.8 2003
Apache开源网站上下载hadoop,版本根据自己需要下载,本文采用2.7.7版本
ssh远程工具,本文使用到的有xshell,xftp。
hadoop需要Java的环境,本文使用jdk1.8
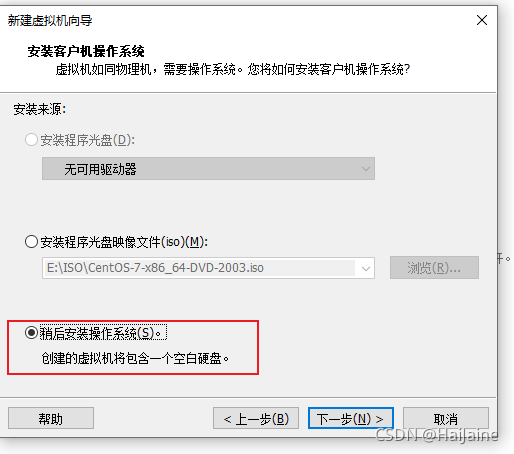
二、虚拟机里安装centos
注意:安装后如果提示
大部分原因是BIOS里面未开启,这里每种品牌的电脑的开启有所不同,如果不是很懂,点这询问度娘

安装步骤
不是很清楚虚拟机配置的小伙伴,这里就选典型。


输入虚拟机名称与安装路径。

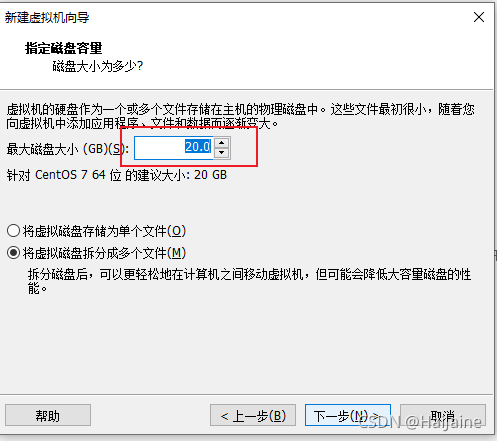
本地硬盘空间不大的小伙伴,这里就默认就行,也可以根据自己电脑配置,调整大一点。
现在我们开始选择centos镜像。


接下来就是开启虚拟机,进行centos的系统安装啦!
将鼠标定位到这个界面,按下enter键即可开始安装。
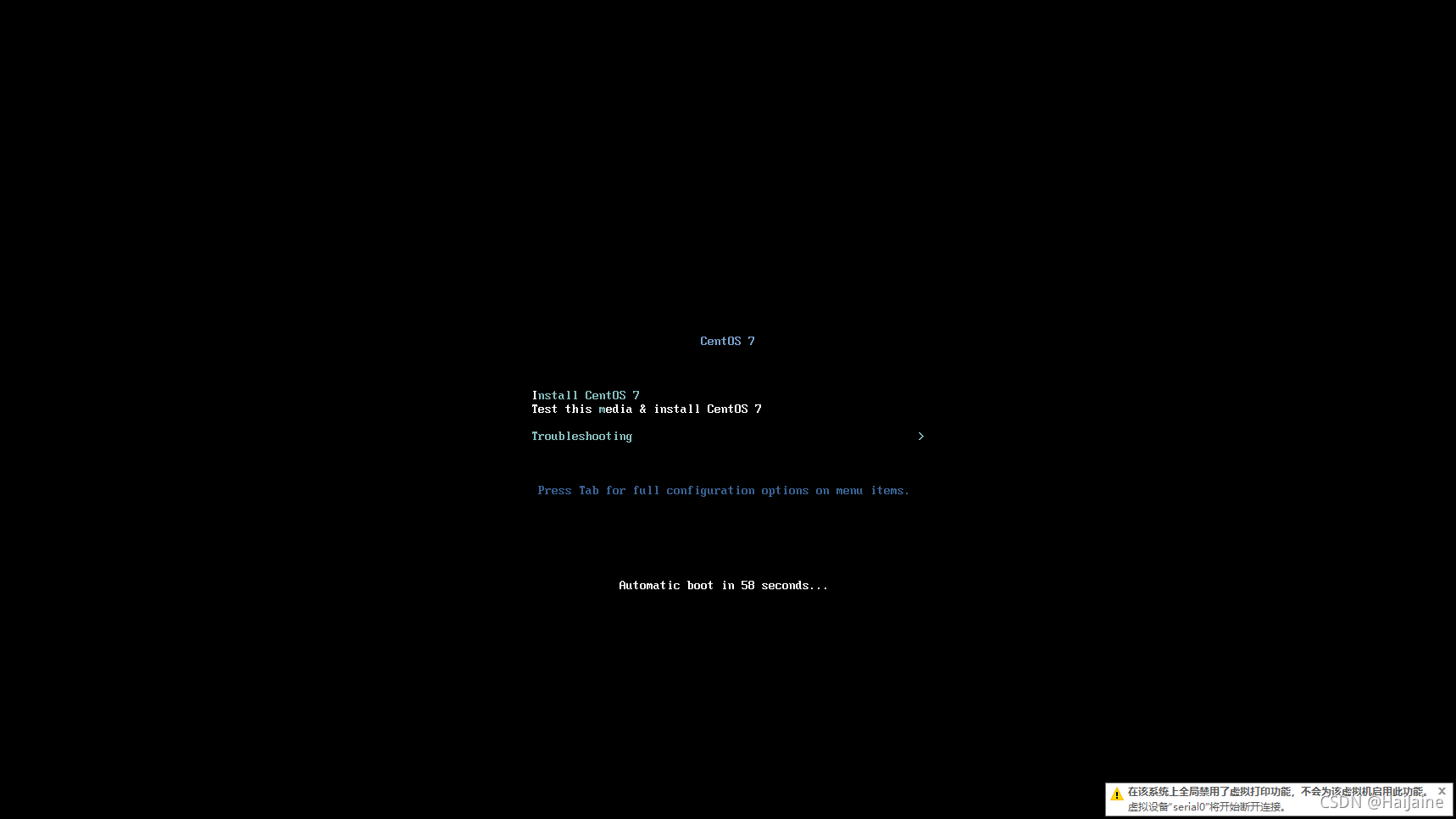
这个检测需要花费一定时间,我们可以按ESC键
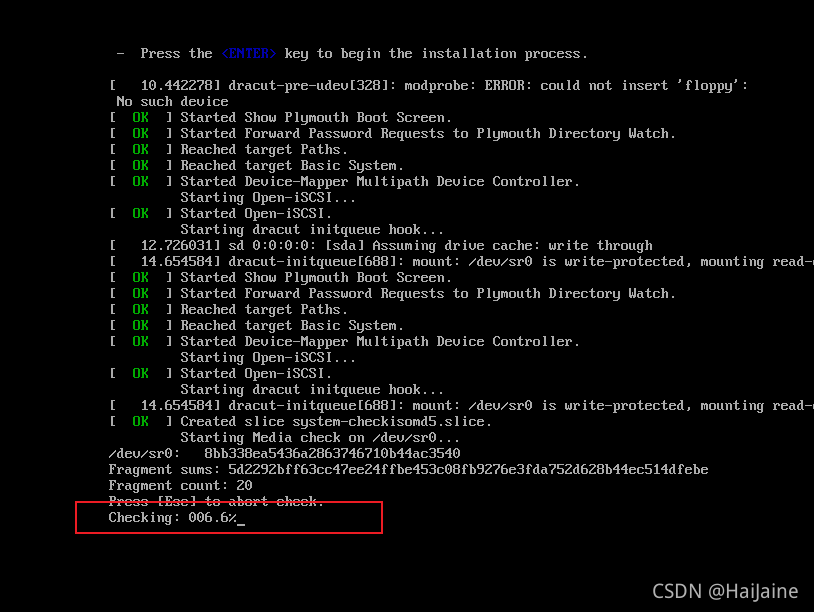
选择安装过程中的语言,我这里选择中文,英文好的小伙伴,可以选择英文进行安装。

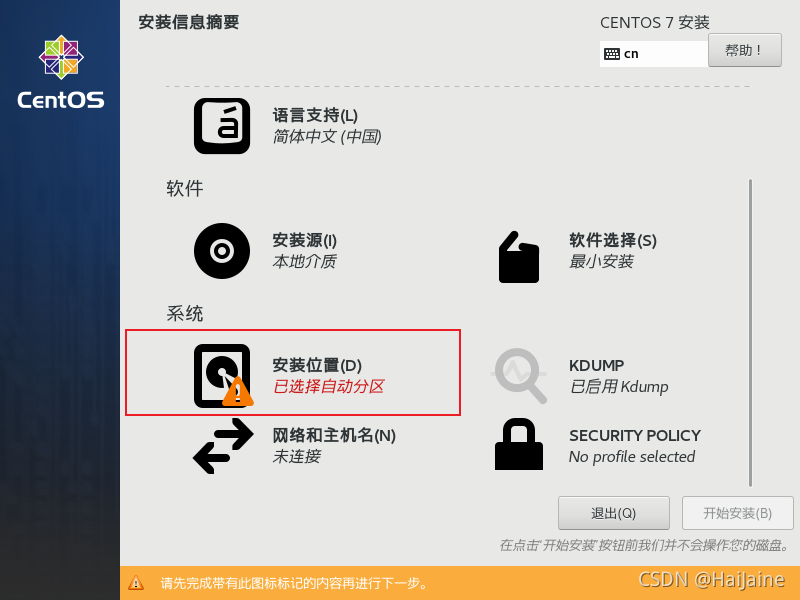
这里系统安装位置是需要我们手动选择的。

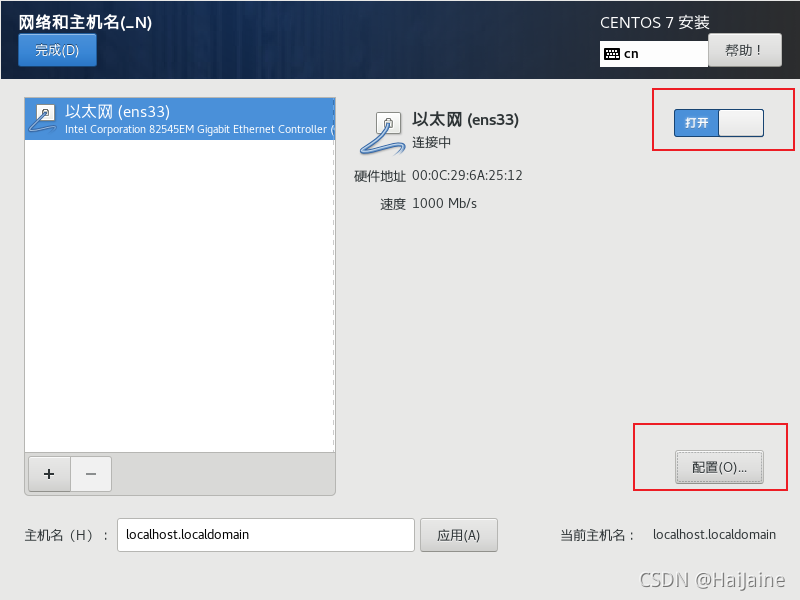
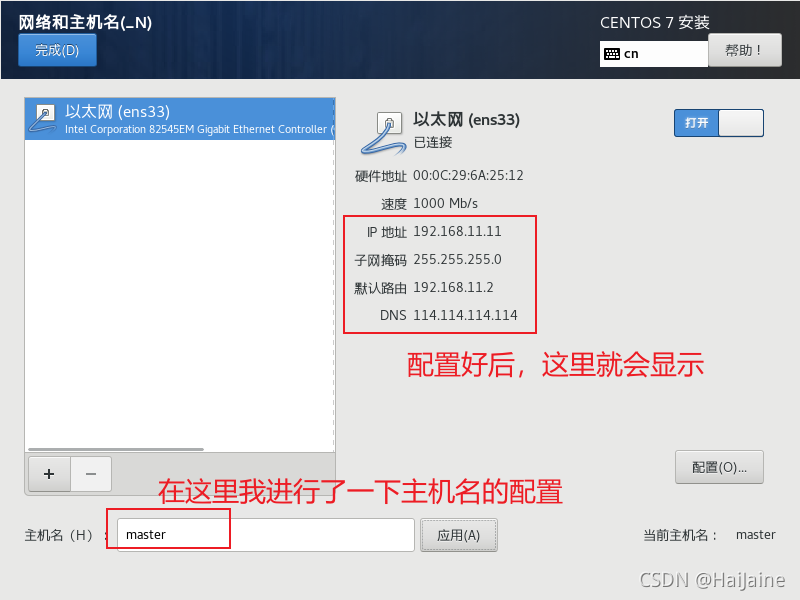
因为后面需要用ssh远程软件连接这个centos,这里我就进行一下网络的选择。也可以在安装完成后进行网络配置。

下图中,ipv4设置下方法选择手动,ip地址需要在虚拟机中查看虚拟机所在的子网,再进行设置,网关也需要在虚拟机网络设置中查看。
这里查看虚拟机的网络配置,需要注意,手动配置的网关需要和这里面的一样才可以。

注意:这里查看网卡一定要是VMnet8这个

下图框选出的就是Linux中需要设置的网关

我这里的网关是192.168.11.2,所有我刚才就设置的这个网关,每个虚拟机的网关可能不一致,安装时注意查看自己的网关。
注意:(一般情况下,可以跳过这部分,网络按照上面配置不生效时,可以参考一下修改方式)
刚才查看的虚拟机网络配置,实际上就是本地虚拟网卡的配置,如果本地虚拟网卡的配置与刚才的配置不一致,需要进行手动配置一下本地的虚拟网卡,否则,有可能会导致虚拟机上不了网。
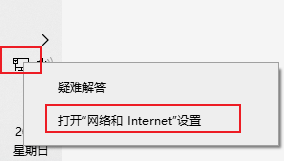
这里以win10电脑为例,查看本地虚拟网卡。查看方式许多,这里我使用我常用的方式。在任务栏找到网络图标,右键 打开网络设置
找到这个网卡,右键查看属性
双击ipv4这点
如不是下图这样,建议手动配置一下,与虚拟机保持一致,若不一致,可能导致虚拟机上不了网。这里的IP地址可以向我这样,最后一位设置为1。




继续回到虚拟机中,进行网络配置。

后面我们使用ssh来操作,这里我就选择最小安装。也可以选择图像化安装。
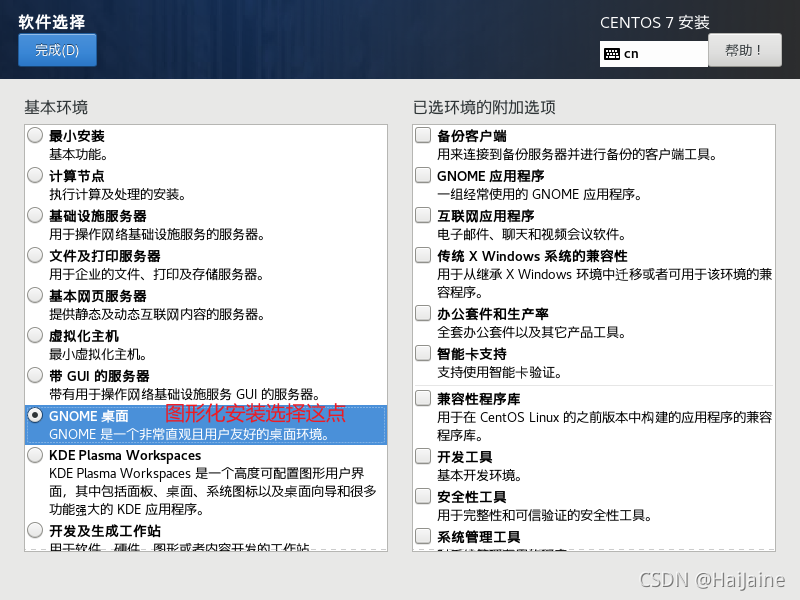
图形化安装可以看下面这张图,最小安装可跳过下一张图。
点击开始安装后,我们需要设置一下root账户的密码,最小安装可以不用创建用户,图形化安装必须创建用户。

接下来,就是等待安装完成啦!
我们是使用虚拟机安装来配置hadoop,另外的结点系统,我们可以采用虚拟机克隆的方式来操作。也可以在等待的时间里进行手动安装。手动安装步骤与上面一致。克隆的计算机,我们需要修改网络配置。后面的hadoop从机,我将采用克隆的方式进行。
hadoop主机master配置
登录上刚才安装的系统。我们先测试一下网络是否连接,可以ping一下百度,ping www.baidu.com,ping命令操作后,按下Ctrl + C键进行停止ping测试
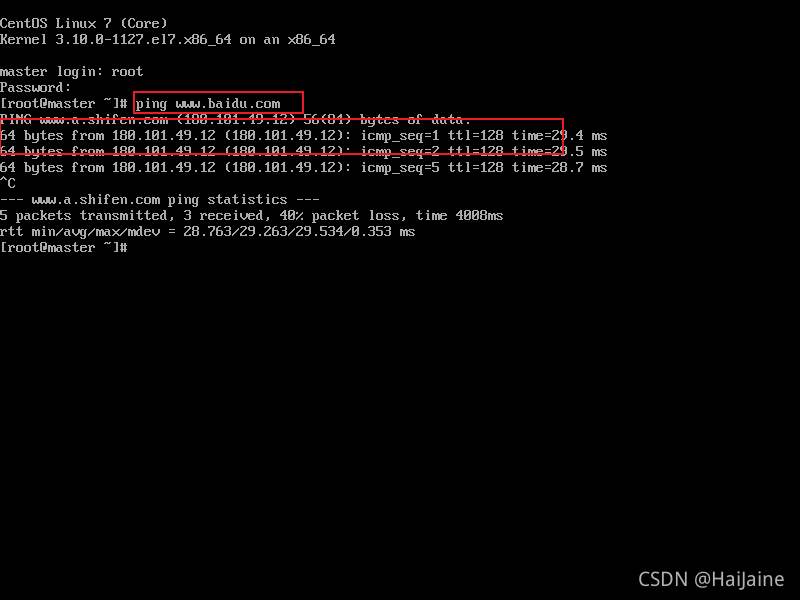
出现上图所示,则表示网络正常连接。
对yum进行升级yum update -y。不进行升级也可以进行后面的操作。
我们先使用yum安装vim编辑器yum install vim -y,系统默认是vi编辑器,vi与vim功能差不多,vim多了语法高亮。
使用命令 ip addr查看当前网络
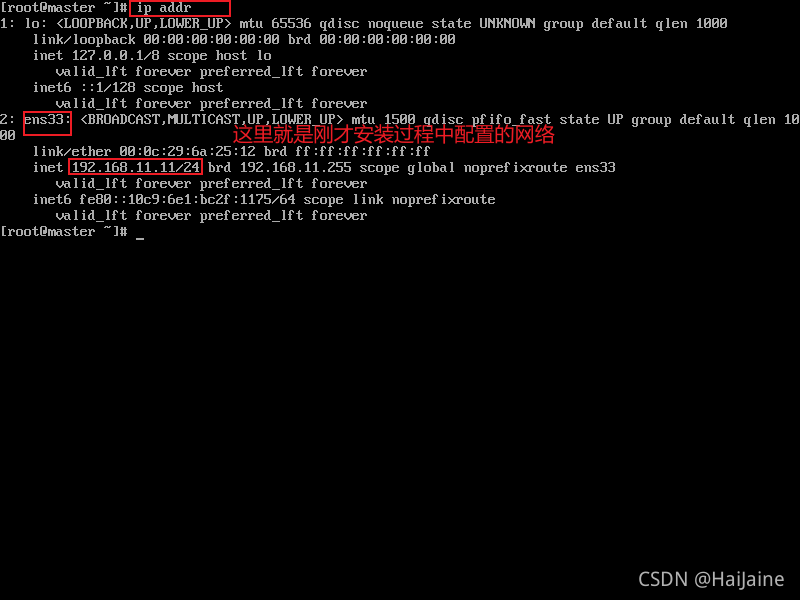
我们需要对网络进行静态配置(安装时,未进行网络配置,也可以直接在这里进行网络配置,效果一样)
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="70d3d71f-be8b-4d47-aa48-0783f94c498a"
DEVICE="ens33"
ONBOOT="yes"
IPADDR="192.168.11.11"
PREFIX="24" # 也可以是 NETMASK=255.255.255.0
GATEWAY="192.168.11.2"
DNS1="114.114.114.114"
IPV6_PRIVACY="no"
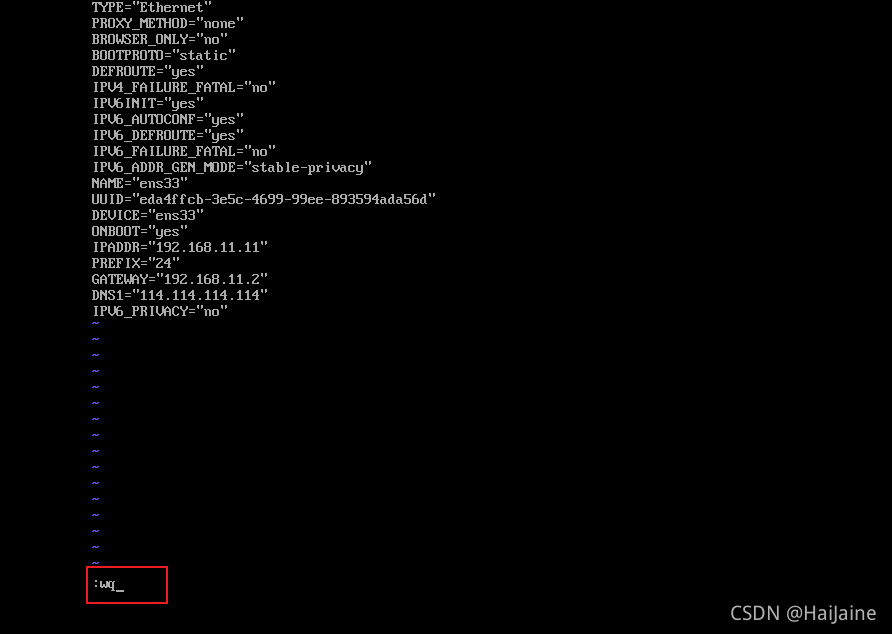
输入命令vim /etc/sysconfig/network-scripts/ifcfg-ens33未安装vim可以使用vi编辑。打开文件后,我们按一下键盘上的i键,进入输入模式,按照我截图地方进行配置即可。IP根据自己实际情况配置。

按下ESC键退出编辑模式,英文状态下输入:wq回车 进行保存退出,具体命令查看Linux手册。
配置好之后,需要重启网卡服务。systemctl restart network 或 service network restart 通过ip addr确认IP。

修改hosts文件
vim /etc/hosts添加一下内容。

再次进行重启网络systemctl restart network。
在windows系统下测试访问Linux是否成功。
Windows系统下,按下win+R–>输入cmd–>回车打开

可以ping通就说明本地与Linux之间的网络是可以互通的。
进行到这里,我们就可以使用ssh工具来进行操作啦!
xshell连接Linux
打开xshell软件,新建一个连接。
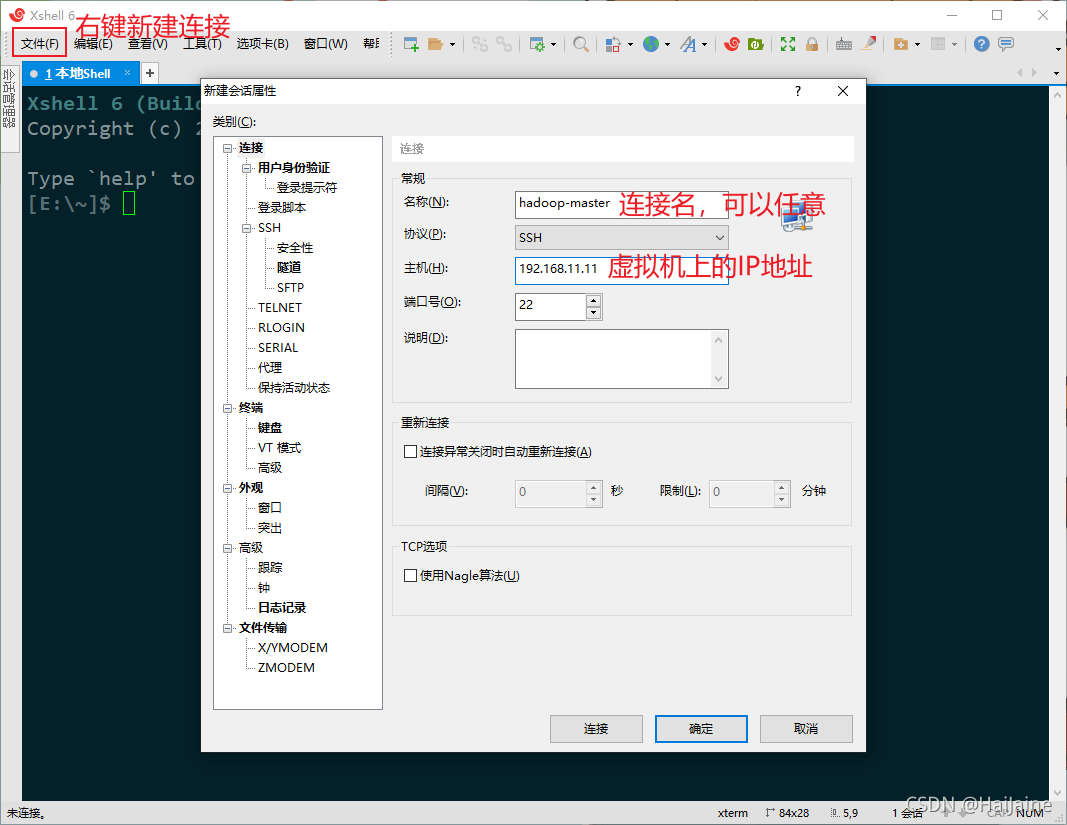
点击 连接后 输入用户名和密码 这里我没有创建用户,则使用root账户登录。
我这里安装了xftp,可以在xshell里直接将本地的文件上传的centos中。

可以直接将需要上传的文件拖动到里面即可上传。

我这点上传的位置为/root下,上传完成后,我们在xshell里进行查看并解压上传的文件。

tar.gz格式 解压命令tar -zxvf 包名其中参数v可以不要,加上v则可以在解压时输出信息。

这样就表示解压成功了。
我们先对jdk重命名一下mv jdk8u265-b01/ jdk1.8。声明一下,里面操作的路径不一定非要和我的一致,也可以选择其他的路径操作。
配置jdk环境变量
Linux下环境变量的配置方式不唯一,这里只使用一种方式配置。
输入命令vim /etc/profile。在文件的末尾加上以下语句。
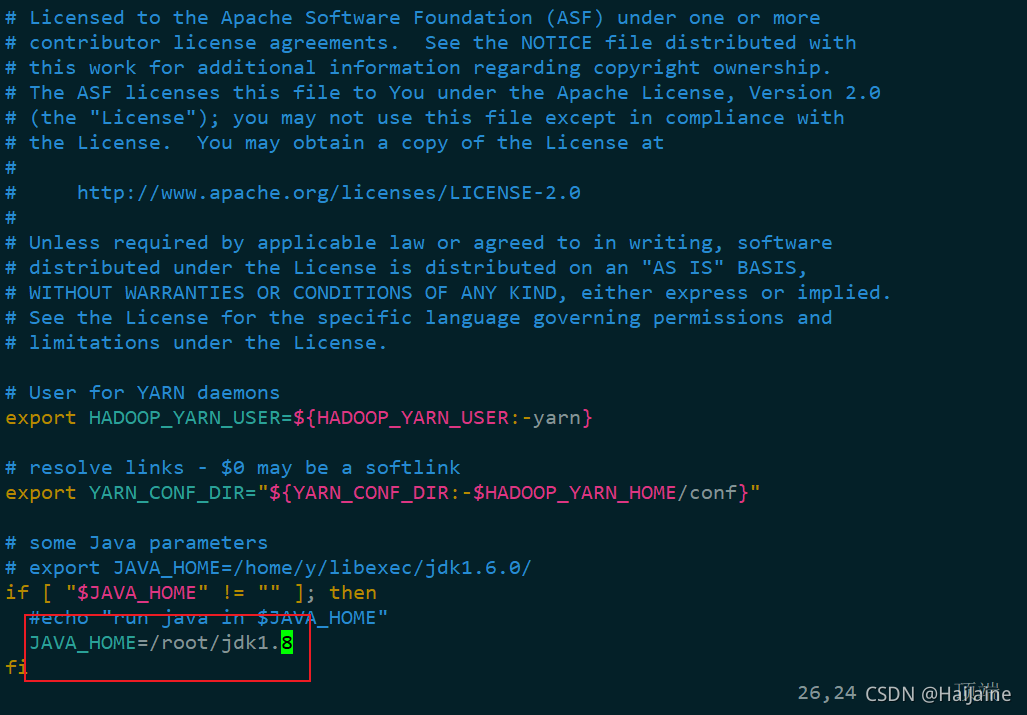
export JAVA_HOME=/root/jdk1.8
export PATH=$JAVA_HOME/bin:$PATH

# 配置环境变量后需要source一下
source /etc/profile
# 查看Java环境是否安装成功
java -version

到这里,Java环境就安装好了。
关闭系统防火墙
这里是本地搭建,三个系统都关闭防火墙。线上模式搭建时,防火墙按需配置。
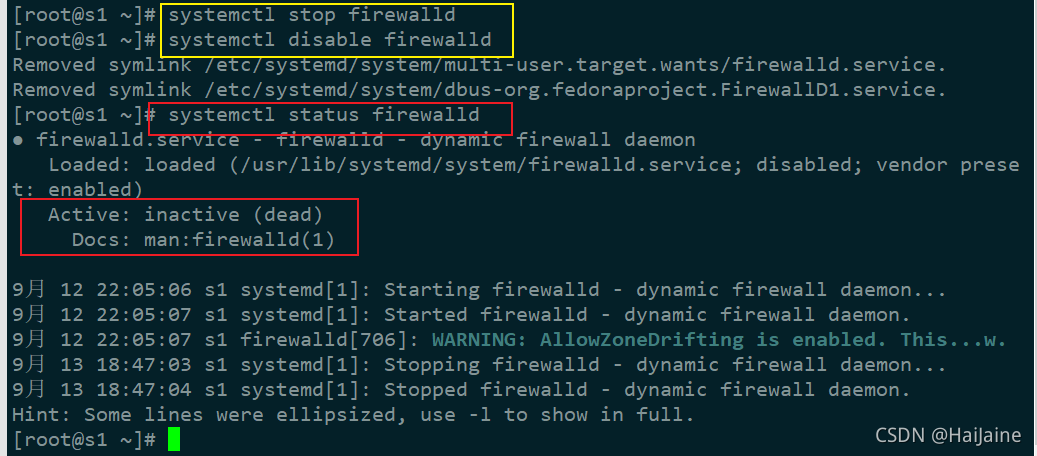
# 先停止防火墙
systemctl stop firewalld
# 关闭防火墙
systemctl disable firewalld
# 查看防火墙状态
systemctl status firewalld
自动时间同步
# 安装ntp服务
yum install ntp -y
# 在root账户下创建定时任务
crontab -e
# 在打开的文件中输入以下内容,保存退出即可。
0 1 * * * /usr/sbin/ntpdate ntp1.aliyun.com
crontab命令使用教程,可以参考这篇博文。
hadoop配置
# 进入hadoop目录下etc/hadoop里
cd hadoop-2.7.7/etc/hadoop/
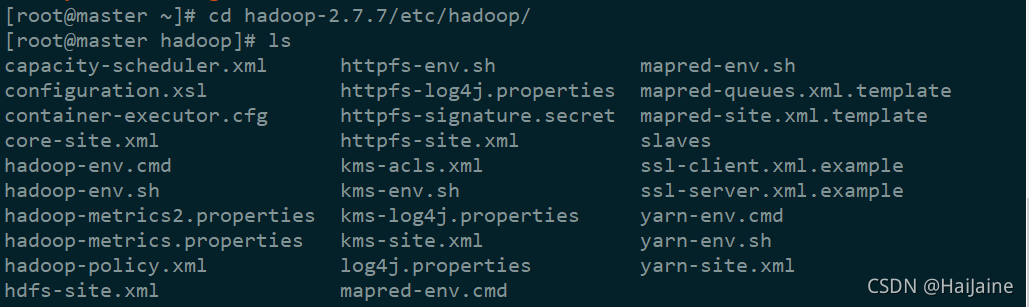
修改hadoop配置文件
修改hadoop-env.sh、yarn-env.sh
vim hadoop-env.sh


vim yarn-env.sh

同样的修改Java的路径
配置core-site.xml
vim core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.11.11:9000</value>
<description>192.168.11.11为服务器IP地址,其实也可以使用主机名</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop-2.7.7/hadoopDatas/tempDatas</value>
<description>hadoop临时文件目录,若指定目录不存在,则需要手动创建目录</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
<description>缓冲区大小</description>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
<description>开启hdfs回收站功能,value单位为分钟,这里设置为24小时候清理回收站</description>
</property>
</configuration>
配置文件中,我们用了自定义路径,现在将设置好的路径创建出来
# 创建目录
mkdir -p /root/hadoop-2.7.7/hadoopDatas/tempDatas
mkdir -p /root/hadoop-2.7.7/hadoopDatas/namenodeDatas
mkdir -p /root/hadoop-2.7.7/hadoopDatas/datanodeDatas
mkdir -p /root/hadoop-2.7.7/hadoopDatas/snnName
mkdir -p /root/hadoop-2.7.7/hadoopDatas/snnEdits
mkdir -p /root/hadoop-2.7.7/hadoopDatas/nnEdits

配置hdfs-site.xml
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
<description>secondary NameNode web管理端口</description>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
<description>NameNode web管理端口</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///root/hadoop-2.7.7/hadoopDatas/namenodeDatas</value>
<description>namenode元数据的存放位置</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///root/hadoop-2.7.7/hadoopDatas/datanodeDatas</value>
<description>datanode元数据的存放位置</description>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///root/hadoop-2.7.7/hadoopDatas/snnName</value>
<description>secondary NameNode节点合并临时镜像的存放目前录</description>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///root/hadoop-2.7.7/hadoopDatas/snnEdits</value>
<description>secondary NameNode节点合并临时操作的存放目前录</description>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///root/hadoop-2.7.7/hadoopDatas/nnEdits</value>
<description>namenode日志文件的存放位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
<description>分片数量,伪分布式将其配置成1即可</description>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>s1, s2</value>
<description>s1, s2分别对应DataNode所在服务器主机名</description>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
<description>大文件系统HDFS块大小默认值为128M</description>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
<description>更多的NameNode服务器线程处理来自DataNodes的RPCS</description>
</property>
</configuration>
配置mapred-site.xml
安装后没有mapred-site.xml,我们需要复制一份出来使用cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>执行框架设置为Hadoop YARN</description>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
<description>开启MapReduce小任务模式</description>
</property>
</configuration>
配置yarn-site.xml
vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
<description>可以写主机名,也可以写主机IP地址</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>以逗号分隔的服务列表,其中服务名称只能包含A-Z a-z 0-9,不能以数字开头</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>开启日志聚合功能</description>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>6004800</value>
<description>设置聚合日志在hdfs上的保存时间,单位为秒</description>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
<description>设置yarn集群内存分配方案,单位为字节</description>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
<description>设置yarn集群内存分配方案,单位为字节</description>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
<description>设置yarn集群内存分配方案</description>
</property>
</configuration>
配置slaves
vim slaves
数据节点DN的机器名称,可以包含主机master,一行一个主机名
master
s1
s2
hadoop系统变量的配置
# 编辑环境变量
vim /etc/profile
#在配置文件的末尾加上以下内容
export HADOOP_HOME=/root/hadoop-2.7.7
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
# 保存退出后,需要source一下
source /etc/profile

克隆两个从机
可以先将hadoop的配置完成后,再进行克隆,最后进行免密操作。
克隆操作前,需要先把克隆主机进行关机。
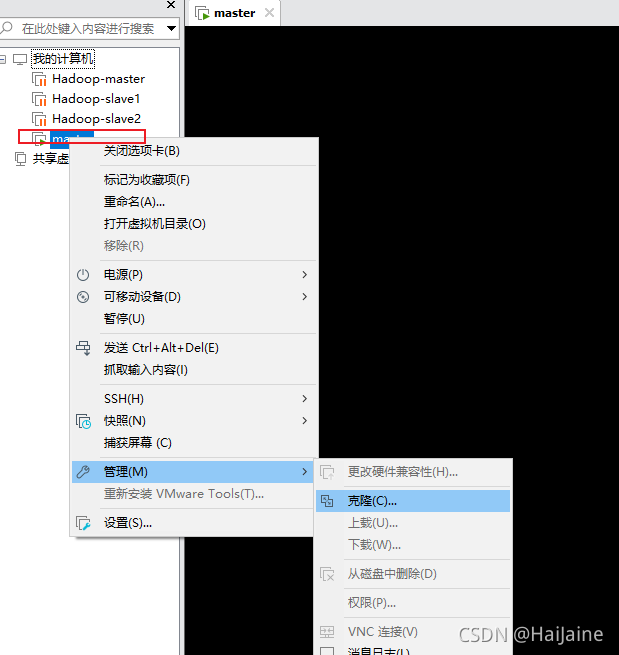

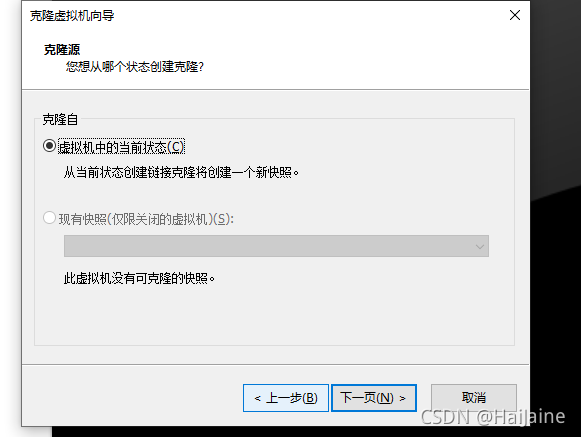
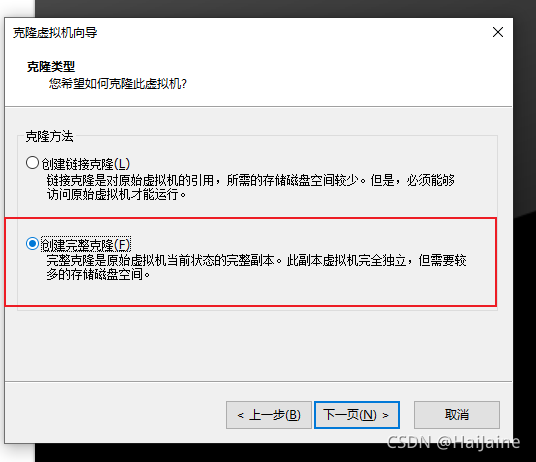
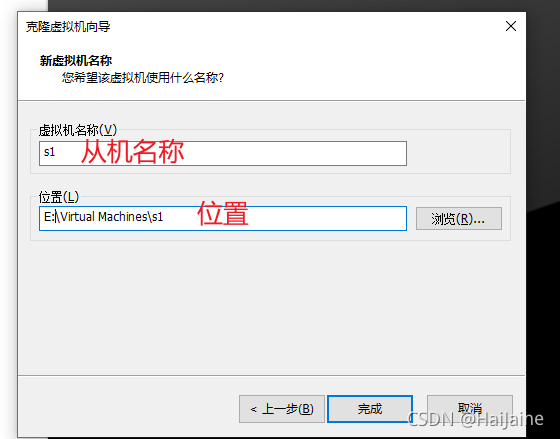
另外一台从机与上面操作一致。
克隆完成后,在vm里打开从机。从机1与从机2操作类似,这里只留下从机1的操作。
这里需要
修改网卡的UUID,由于UUID比较长且vm中不能复制,则这一步留到IP配置后,使用工具连接,再进行操作。
修改IPvim /etc/sysconfig/network-scripts/ifcfg-ens33,与主机不同即可

重启网络服务,命令与前文提到的一致

测试网络是否畅通,ping百度测试

- 修改主机名(
hostnamectl set-hostname s1s1表示修改后的主机名)
需要重启系统生效。

使用xshell连接上从机,与主机连接方式相同。
生成网卡的UUID


保存,重启网络systemctl restart network
从机2同样操作。
免密操作
需在克隆完成后进行操作。
操作流程(建议多阅读几次,理解一下流程):
免密需要将每个系统ssh生成的公钥保存在authorized_keys这个文件中,我们分别在主机maser与从机s1、s2上生成秘钥。进入到主机master通过ssh-keygen生成秘钥后的目录,利用cp命令,将id_rsa.pub这个公钥文件复制一份,命名为authorized_keys,然后将带有主机master公钥的authorized_keys文件复制到从机s1中。在从机s1中,将从机s1的公钥追加到带有主机master公钥的authorized_keys文件中。到这里,authorized_keys这个文件就包含了主机master与从机s1的公钥,我们把带有公钥的authorized_keys这个文件复制到从机s2中。继续将从机s2的公钥追加到已经带有两个公钥的authorized_keys文件中,这样从机s2的authorized_keys这个文件就包含了主机master、从机s1、s2的公钥。把带有3个公钥的authorized_keys这个文件复制到主机master、从机s1上,这样主机master、从机s1、s2就都拥有了3个系统的公钥,就可以实现免密操作了。
注意:这些操作在ssh-keygen生成的.ssh目录下进行。复制也是需要复制到.ssh这个目录下。
scp远程命令
Linux中scp命令用于Linux之间复制文件和目录。
语法:scp [可选参数] file_source file_target
file_source :带路径的源文件或文件目录
file_target :带路径的目标文件目录
参数说明:
-1: 强制scp命令使用协议ssh1
-2: 强制scp命令使用协议ssh2
-4: 强制scp命令只使用IPv4寻址
-6: 强制scp命令只使用IPv6寻址
-B: 使用批处理模式(传输过程中不询问传输口令或短语)
-C: 允许压缩。(将-C标志传递给ssh,从而打开压缩功能)
-p:保留原文件的修改时间,访问时间和访问权限。
-q: 不显示传输进度条。
-r: 递归复制整个目录。
-v:详细方式显示输出。scp和ssh(1)会显示出整个过程的调试信息。这些信息用于调试连接,验证和配置问题。
-c cipher: 以cipher将数据传输进行加密,这个选项将直接传递给ssh。
-F ssh_config: 指定一个替代的ssh配置文件,此参数直接传递给ssh。
-i identity_file: 从指定文件中读取传输时使用的密钥文件,此参数直接传递给ssh。
-l limit: 限定用户所能使用的带宽,以Kbit/s为单位。
-o ssh_option: 如果习惯于使用ssh_config(5)中的参数传递方式,
-P port:注意是大写的P, port是指定数据传输用到的端口号
-S program: 指定加密传输时所使用的程序。此程序必须能够理解ssh(1)的选项。
scp是 secure copy的缩写, scp是linux系统下基于ssh登陆进行安全的远程文件拷贝命令。
# 分别在主机、从机上生成秘钥
ssh-keygen -t rsa
# 会在当前目录下生成一个.ssh文件
# 将生成文件目录下的id_rsa.pub复制到authorized_keys
cp id_rsa.pub authorized_keys
# 将authorized_keys文件复制到从机s1中(需要从机中先执行生成秘钥的命令,即ssh-keygen -t rsa)
scp authorized_keys root@s1:/root/.ssh
# 在从机s1上把authorized_keys中追加上s1的公钥
cat id_rsa.pub >> authorized_keys
# 将authorized_keys文件复制到从机s2中(需要从机中先执行生成秘钥的命令,即ssh-keygen -t rsa)
scp authorized_keys root@s2:/root/.ssh
# 在从机s2上把authorized_keys中追加上s2的公钥
cat id_rsa.pub >> authorized_keys
# 把s2上的authorized_keys分别复制到主机master、从机s1上去,这样就可以实现主机与两台从机的免密操作了
scp authorized_keys root@master:/root/.ssh
scp authorized_keys root@s1:/root/.ssh
主机master操作步骤截图

需要进入到.ssh目录下进行复制文件操作


从机生成秘钥与主机类似,这里不赘述。
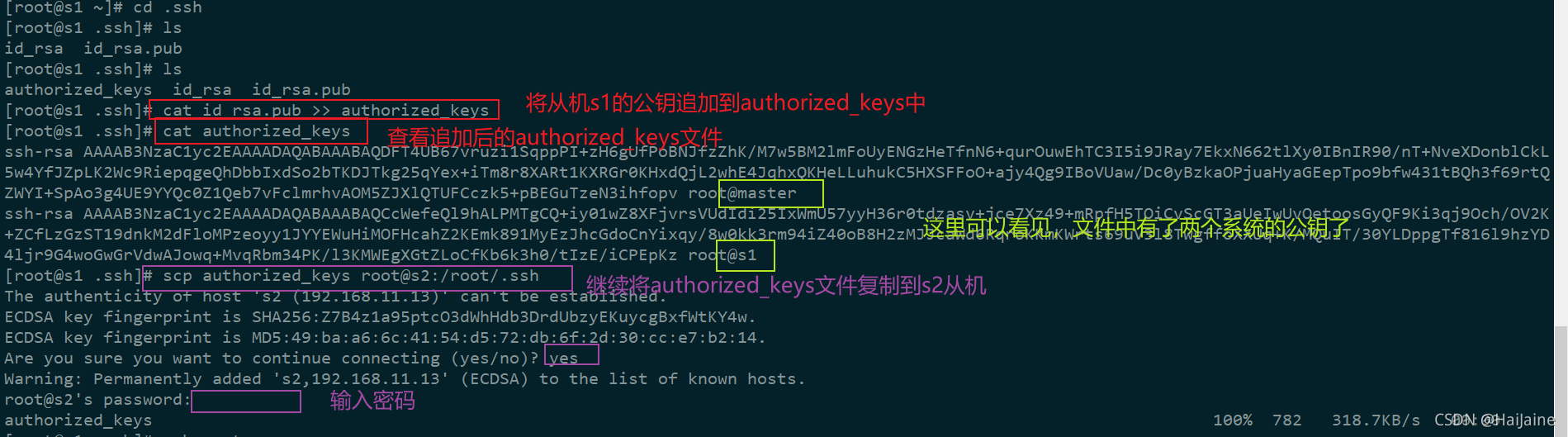
从机s2继续将公钥追加到authorized_keys文件中
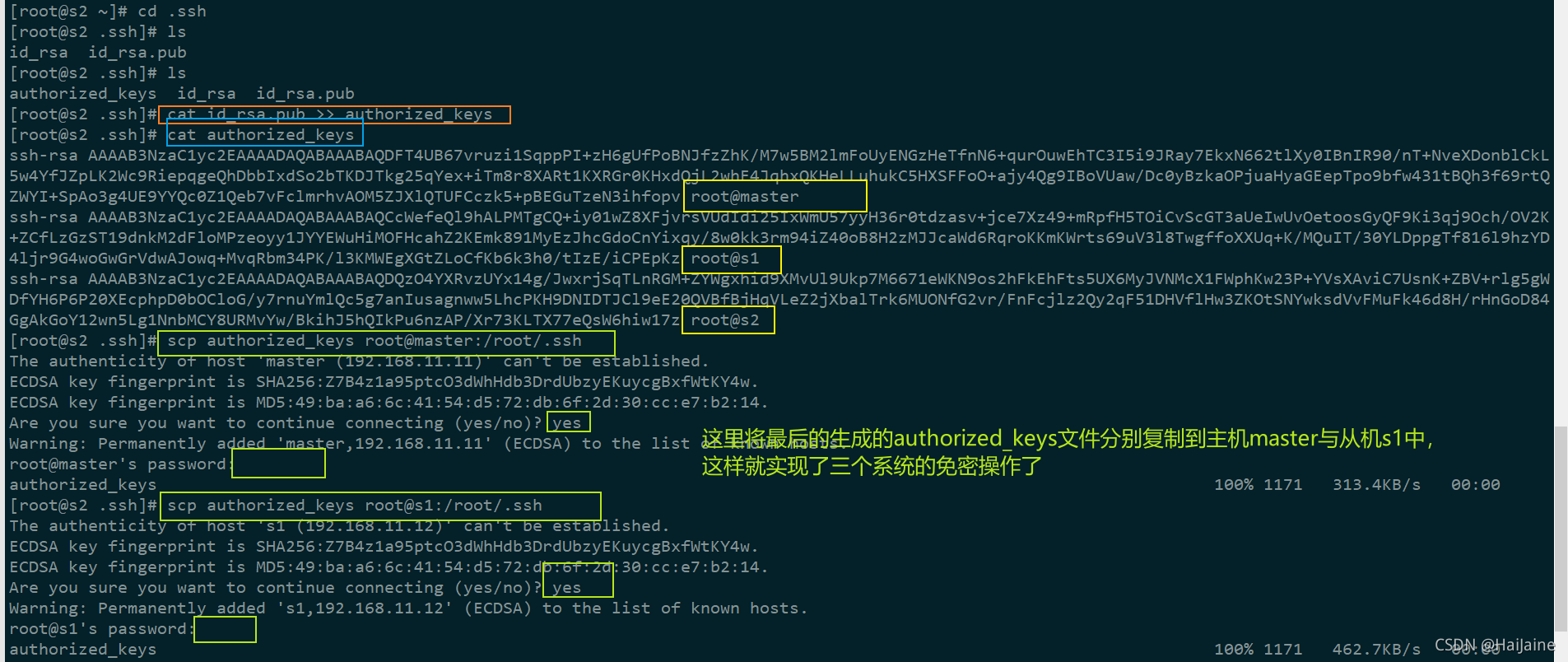
验证免密是否成功
主机master ssh登录s1与s2
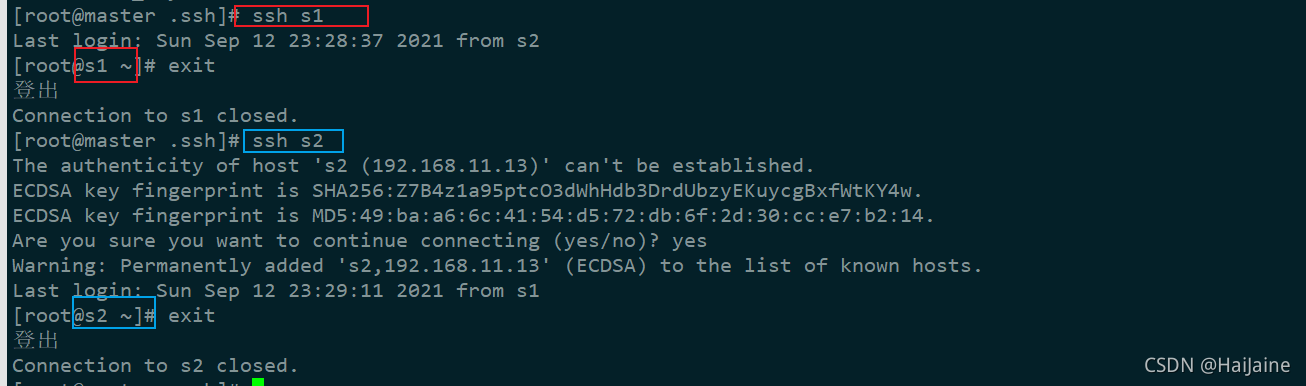
图中未输入密码,免密成功
从机s1与s2的验证与master主机验证相似,小伙伴自行验证。
启动hadoop
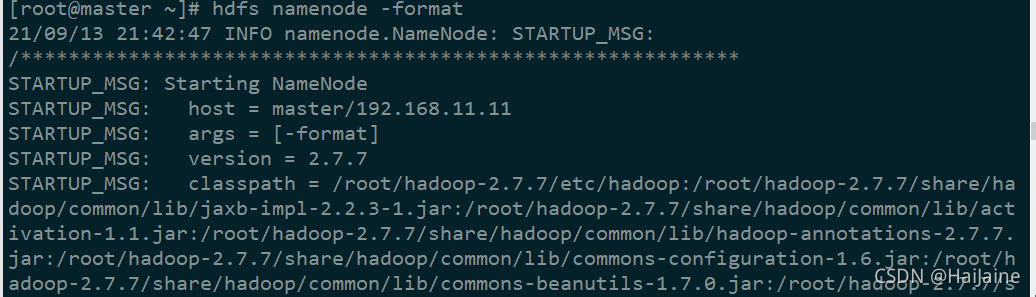
第一次启动前需要进行初始化操作(主机master上操作)。
hdfs namenode -format
主机master上启动hadoop
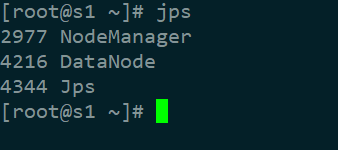
start-all.sh

从机上再输入jps验证
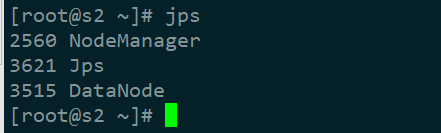
现在我们可以通过主机master的ip地址加上端口(默认的是50070)查看hadoop的一些相关信息。


到这里,hadoop的搭建就结束啦!觉得本文有用的,点个赞呗!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









