







目录
3.1、elasticsearch.yml文件中设置启用验证
一、前言
搭建基于 Docker 的 Kibana 可以方便快捷地实现数据的可视化展示和分析,同时也方便其他系统的嵌套。本文将介绍如何使用 Docker 部署 Kibana,并重点介绍如何使用 Dashboard 和 iframe 实现数据的可视化展示。
二、准备工作
在部署 Kibana 前,需要安装 Docker 及其依赖。具体可以[官网](https://docs.docker.com/get-docker/)参考。
2.1、 下载并配置 Kibana 镜像
可以通过 Docker Hub 上的 [Kibana 镜像](https://hub.docker.com/_/kibana)来安装 Kibana。在安装时,可以指定 Kibana 的版本,例如:
```
docker pull docker.elastic.co/kibana/kibana:7.10.0
```
然后,在运行 Kibana 容器时,需要将 Elasticsearch 地址配置到 Kibana 的配置文件中,具体可以通过命令行参数或者挂载配置文件的方式实现。例如:
```
docker run --name kibana -p 5601:5601 -e "ELASTICSEARCH_HOSTS=http://[elasticsearch_ip]:9200" docker.elastic.co/kibana/kibana:7.10.0
```
这里将 Kibana 暴露在 5601 端口,并且将 Elasticsearch 的地址配置为 `[elasticsearch_ip]:9200`。
三、开启kibana自带登陆验证
如果您希望保护您的Kibana应用程序,并控制被允许访问应用程序的用户,请使用Kibana自带的登录页面及登录验证功能。
3.1、elasticsearch.yml文件中设置启用验证
在elasticsearch.yml文件中设置启用验证。打开elasticsearch.yml文件,找到下面的这行:
```
#xpack.security.enabled: false
```
去除注释并将其设置为true。
```
xpack.security.enabled: true
```
3.2、 为Kibana设置一个初始的用户名和密码。
在elasticsearch安装目录下的bin目录中,运行以下命令:
```
bin/elasticsearch-setup-passwords interactive
```
此命令将显示一个交互式的命令行界面,您可以使用它来设置Kibana和elasticsearch的密码。
3.3、设置elasticsearch访问密码
```
#elasticsearch.password: "pass"
```
去除注释并将其设置为您在第2步中设置的密码。
```
elasticsearch.password: "your_password"
```
3.4.、安装x-pack插件
```
./bin/kibana-plugin install x-pack
```
3.5、 重启elasticsearch和kibana
您应该会看到Kibana登录页面,它会显示“用户名”和“密码”字段。
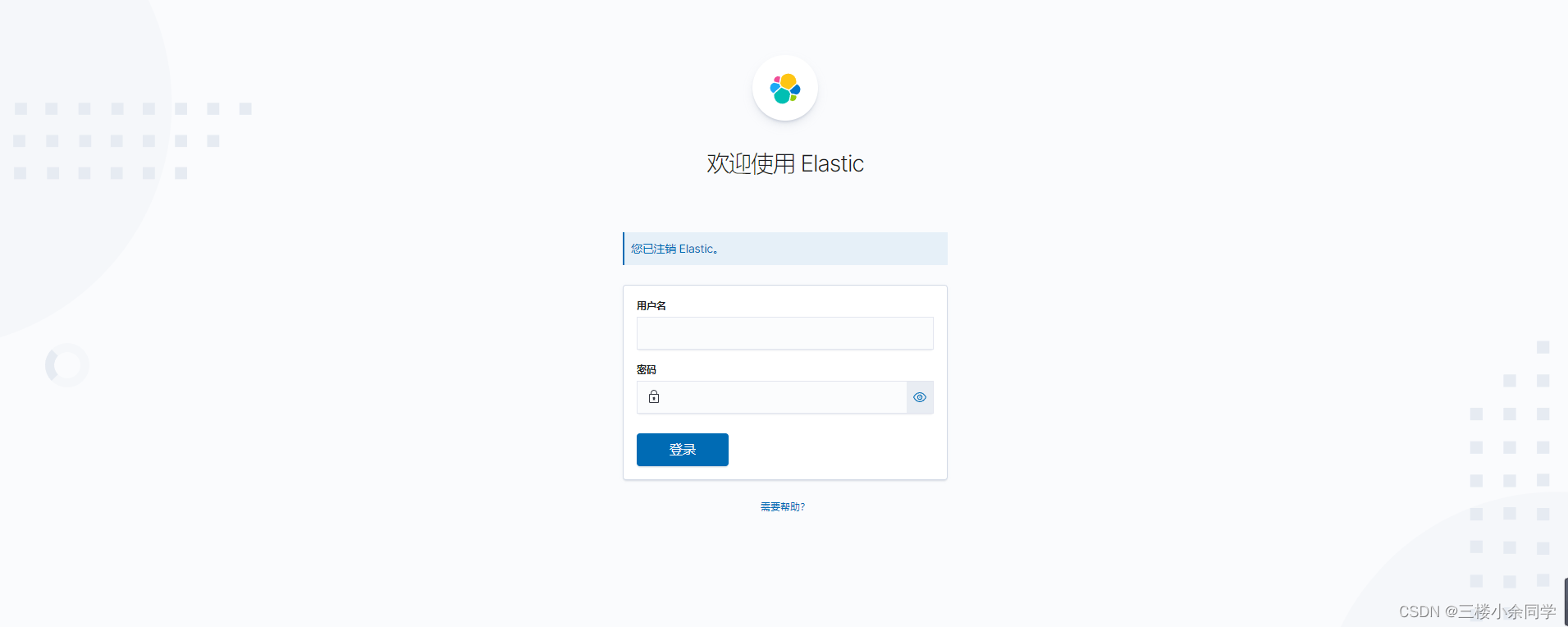
四、使用 Dashboard 和 iframe
4.1、Dashboard 的基本使用
Dashboard 是 Kibana 的一个重要功能,可以将多个视图整合为一个面板,方便数据的展示和分析。在 Kibana 中,可以通过“Dashboard”菜单进入到 Dashboard 界面。
在 Dashboard 界面,可以通过“Add”添加各种数据视图,例如表格、柱状图、饼图等,然后将它们布局到一个面板中,即可得到一个 Dashboard。此外,也可以通过菜单中的“Visualize”来创建一个可视化视图,并将其添加到 Dashboard 中。
4.2、 iframe 的使用
通过将 Dashboard 嵌套在其他系统中,可以方便地展示数据,同时也可以实现免登效果,这是很多业务系统都需要的功能。
在嵌套时,可以通过 iframe 标签嵌套 Kibana 的 Dashboard,从而实现 Dashboard 的展示。需要注意的是,在 Kibana 中有一些安全设置(比如 CORS),需要进行相应的设置才能允许其他系统嵌套 Kibana。可以通过在 Kibana 中设置 `server.cors` 选项来实现这些安全设置,具体可以参考 Kibana 的文档。
在嵌套时,需要在 iframe 中设置跨域访问的头信息,例如:
```
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Dashboard</title>
<script>
document.domain = 'example.com'; // 设置域名
</script>
</head>
<body>
<iframe src="http://kibana.example.com/app/dashboards#/view/xxx?embed=true" width="100%" height="100%" frameborder="0"></iframe>
</body>
```
在这里,我们通过 `src` 属性将 Dashboard 面板嵌套在 iframe 中,其中 `xxx` 是 Dashboard 的 ID。
除了设置设置域名和设置头信息外,还需要将 Kibana 的 cookie 带入 iframe 中,以实现免登效果。可以通过设置 `iframe` 的 `sandbox` 属性来实现。例如:
```
<iframe src="http://kibana.example.com/app/dashboards#/view/xxx?embed=true" width="100%" height="100%" frameborder="0" sandbox="allow-same-origin allow-scripts allow-popups allow-forms"></iframe>
```
在这里,设置了`sandbox` 属性,允许 iframe 访问同源(同域名的)文档、执行脚本、弹出窗口、向外部服务器提交表单。
五、总结
使用 Docker 部署 Kibana 可以方便快捷地实现数据的可视化展示和分析。Dashboard 和 iframe 是 Kibana 的两个重要功能,可以方便地展示数据、实现数据的嵌套和免登效果等功能。通过学习本文,相信您对于如何使用 Docker 部署 Kibana 并使用其功能已经有了一定的了解。
















 1267
1267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











