






边缘大模型(Large Models)包括Large Language Models (LLMs)和Large Vision Models (LVMs)。本文介绍清华大学和上海交通大学在边缘大模型推理加速相关的工作《SwapMoE: Efficient Memory-Constrained Serving of Large Sparse MoE Models via Dynamic Expert Pruning and Swapping》。
介绍
混合专家(Mixture of experts, MoE)是一种增加大模型能力的重要技术,例如在Mixtral-8x7B Large Language Model (LLM)中就用到了这种技术。研究团队发现MoE大模型在推理时具有很强的(1)稀疏性和(2)时间局部性。具体来说,每次进行推理时,MoE模型只有不到10%的参数参与了运算,而剩下的90%都处于闲置状态;并且这种稀疏性会在一定时间或者domain保持稳定。此外,研究团队还发现MoE模型中experts是(3)可以替换的,如果将MoE模型的Top1路由改为只用Second Top路由,模型的性能损失很小。因此利用(1)(2)(3)三种特性,可以大幅降低MoE模型的推理显存占用和推理时延。
实验
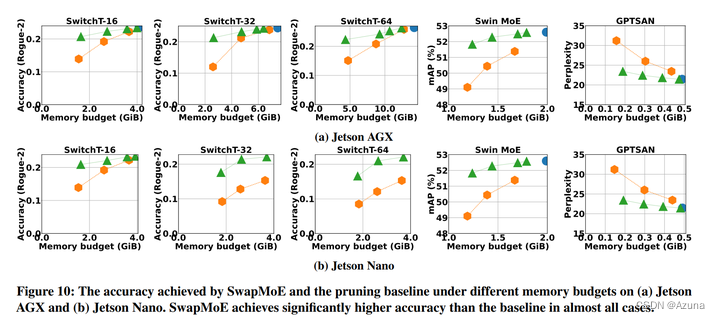
通过实验验证,论文所提方法可以大幅降低MoE大模型的推理显存占用,例如本来在Jetson Nano上无法运行的Switch Transformers Base - 32模型,通过优化后,可以减少到只用原来25%的显存,并且性能损失很小。















 1214
1214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









