




 本文探讨了爬虫技术如Selenium、Appium与API接口寻找的难点,Python中文件操作、docker问题、MongoDB去重与pymongo,以及使用代理IP、Elasticsearch部署与连接问题。重点涉及Docker、Scrapy、MongoDB和网络抓取策略。
本文探讨了爬虫技术如Selenium、Appium与API接口寻找的难点,Python中文件操作、docker问题、MongoDB去重与pymongo,以及使用代理IP、Elasticsearch部署与连接问题。重点涉及Docker、Scrapy、MongoDB和网络抓取策略。
资源下载
MovieRecommenderSystem.zip
京东爬虫 – docker mongodb redis scrapy
考研帮Python爬虫 – appium + mitmdump实现
保存
python中 对文件的读写操作 以及如何边写入 边保存flush()
学习
现推荐看电脑里面的千峰的教程笔记
资料
看看浏览器的收藏夹:
iframe的xpath
import不了自己的文件

怎么也解决不了,搜了好多办法
然后我发现这个是可以用的,它只是有波浪线而已,先将就着用吧
selenium设置等待
class3,滑块
试过了,但是好像都行不通
python爬虫小白升仙_7-----selenium模拟登录豆瓣网+opencv破解滑块验证码
爬虫高级案例(1):使用selenium+OpenCV破解滑块验证码
作业三
Python3爬虫实战【点触验证码】 — 模拟登陆bilibili
python读取图片获得的不同的长和宽
这个用的不是超级鹰
爬虫模拟登陆哔哩哔哩(bilibili)并突破点选验证码
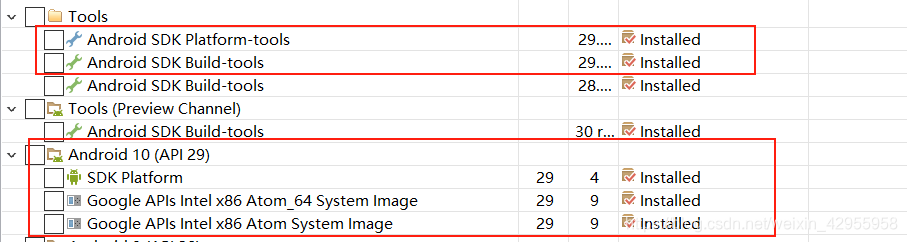
android sdk安装
Android SDK 安装及环境配置教程
安装的时候,每组都点下 accept license
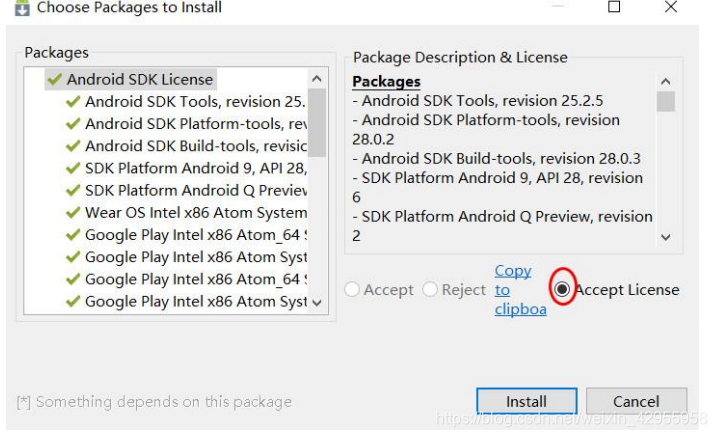
adb连接夜神模拟器提示adb server version (36) doesn‘t match this client (40); killing…
夜神模拟器安装xposed以后重启就一直启动不了
最后只能重置了
51job
老师给的那个代码不行,因为现在51job的结果信息根据xpath根本找不到,它把数据放在了js里面,所以通过以下方式实现了
scrapy爬取51job职位信息(针对新的反爬虫机制)!
appium
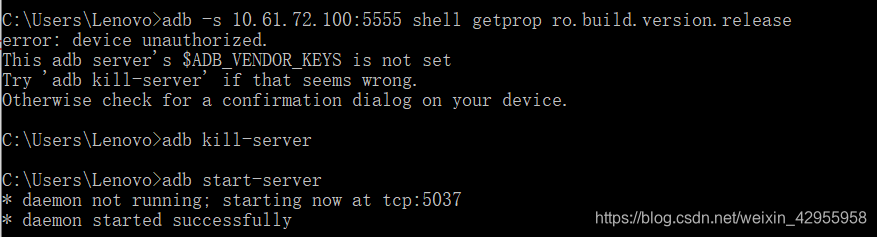
在start session的时候会报错,解决不了。。

我已经不知道怎么解决的了,首先把sdk manager的最新的又下载了下,但是期间也有问题
后来出现这个:
Error: Error getting device platform version.
我就这样做了,不知为啥启动appium的时候又出现新问题,这期间又打开关闭usb调试
Java Runtime (class file version 53.0), this version of the Java
Runtime only recognizes class file versions up to 52.0
解决方法:解决Appium启动报错Java Runtime (class file version 53.0), this version of the Java Runtime only recognizes class file versions up to 52.0问题
滑动:
Appium_swipe针对app模拟手机屏幕上下左右滑动操作方法
注意:
find_element_by_id和find_elements_by_id
docker
今天突然就打不开虚拟机了,报这个错,百度,google都解决不了,气死
Failed to open/create the internal network
‘HostInterfaceNetworking-Qualcomm Atheros QCA9377 Wireless Network
Adapter’ (VERR_SUPDRV_COMPONENT_NOT_FOUND). Failed to attach the
network LUN (VERR_SUPDRV_COMPONENT_NOT_FOUND).
最后更新了virtualbox就可以了,简直莫名其妙,每节课都一个难以解决的bug,恶心
1、联网:nat模式+自动(DHCP)
sudo docker version任务:pycharm连上docker
mongodb
去重
pandas数据处理(一)pymongo数据库量大插入时去重速度慢
pymongo超百万数据时,插入数据时去重
mongo批量插入,并去重
mongodb的查重与pymongo插入数据去重
import pymongo
class handle_mongo(object):
def __init__(self):
# 创建mongo客户端
self.client = pymongo.MongoClient('localhost', 27017)
# 创建数据库实例
self.mg = self.client['sheep']
def insert_item(self, item):
# 创建表
dougo = self.mg['豆果美食']
print("开始插入")
# dougo.create_index([("菜单id",1)], unique=True)
# try:
# dougo.insert_many(item)
# except:
# pass
# 根据 “菜谱id” 去重,插入的数据为 item
dougo.update_one({'菜谱id': item['菜谱id']}, {'$set': item}, True)
# 会将所有符合条件的数据都更新
# dougo.update_many({'菜单id': item['菜单id']}, {'$set': item}, True)
douguo_mongo = handle_mongo()
# x = [{
# "菜单id": 8,
# "b": 2,
# },{
# "菜单id": 8,
# "b": 2,
# },{
# "菜单id": 9,
# "b": 2,
# },{
# "菜单id": 11,
# "b": 2,
# }]
# douguo_mongo.insert_item(x)
代理ip
在网络爬虫抓取信息的过程中,如果抓取频率高过了网站的设置阀值,将会被禁止访问。所以出现了代理ip
fiddler
pycharm配置docker
sudo sh -c 'echo "export DOCKER_HOST=tcp://0.0.0.0:2376" >> /etc/profile'
这里之前一直连接不了,后来我发现,我ping虚拟机失败,但是虚拟机ping主机可以。就查解决方法,如下:
主机ping虚拟机失败。虚拟机ping主机,可以ping通。
但是还是不可以,我猜测可能是我用的是virtualbox的原因,之前virtualbox也出了好多错
主机ping不通virtualbox虚拟机的解决办法
VirtualBox 主机ping不通虚拟机的解决办法
桥接的网卡,一定要全部允许,要不然这个网卡就没有ip
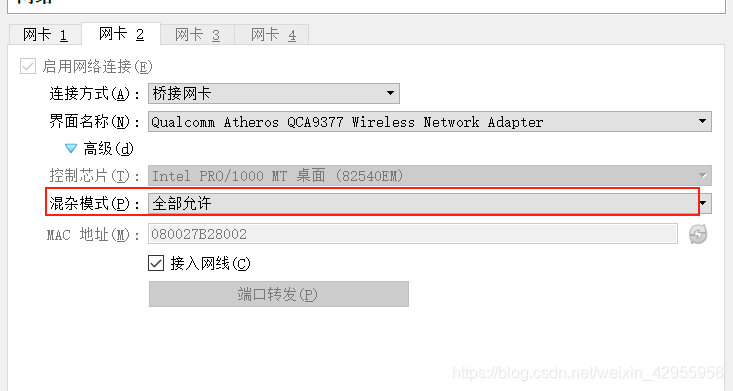
还有不知道为什么,只有自己的手机热点才连的上,学校的网就不可以
大作业一
资源下载:
考研帮Python爬虫 – appium + mitmdump实现
爬取考研帮
现在找到的代码可以爬取 朋友的信息,按理说只要找到api接口就可以爬取信息。但是我找不到研讯的 api接口
思路一:
采取类似selenium的方式去爬取数据,不需知道接口是什么,只需获取每次返回的请求就可以爬取到数据,此种方式一般什么数据都可爬取到,但是效率不快。
我看网上的教程,移动端的爬取都是appium+mitmdump的,先不考虑此法
另辟蹊径,appium抓取app应用数据了解一下!
思路二:
想办法获取到考研帮接口
我现在安装了新版本的考研帮app就可以找到接口了,问题是它的请求header一直有变化,之前的豆果美食可以成功是因为header不怎么变
python的docker爬虫技术-mitmproxy之安卓模拟器mitmdump(11)
每次运行action执行都要这个
mitmdump -p 8888 -s script.py
待解决:
如何左移
大作业二
爬取京东全站
资源下载:
京东爬虫 – docker mongodb redis scrapy
参考:
Python3网络爬虫开发实战
jdSpider
python爬虫热点项目
爬虫基础篇之Scrapy抓取京东
[爬虫]使用python抓取京东全站数据(商品,店铺,分类,评论)
Scrapy 2.4.1 - no active project 解决方法
代理
代理池:
失败:
proxy_pool
Scrapy ip代理池
启动代理池
docker run -d --env DB_CONN=redis://192.168.56.101:6379/0 -p 5010:5010 jhao104/proxy_pool
docker
虚拟机上的docker的命令记得加上 sudo
利用这个可以生成 requirements.txt
pipreqs ./ --encoding=utf8 --force
Ubuntu下安装docker和docker-compose
爬虫部署到Docker
利用docker和docker-compose 数据库 构建简单爬虫系统
安装Python和pip可能下载依赖不成功,可能是没更新pip的原因
Command “python setup.py egg_info” failed with error code 1 in /tmp/pip-build-*解决办法
我开了8个一起爬,爽
创建镜像
docker build -t jd:v1.7 .
创建后台容器
docker run -d --name jd2 jd:v1.7
docker run --name jd1 jd:v1.7
挂载目录,但是好像因为一启动就要运行该目录,所以好像这样挂载会启动失败
docker run -v /jd/jd:/code/jd/jd -d --name jd1 jd:v2.0
拷贝文件至容器
docker cp jd/jd/settings.py jd1:/code/jd/jd/
将修改的容器保存为新的镜像:
docker commit -m "更新ip" jd1 jd:v2.1
docker镜像怎么修改,我经常改docker里面的文件,项目文件会变更
可能是利用pycharm
scrapy-redis
scrapy-redis 采集失败如何将url移出DupeFilter
ubuntu
用的是pip3
VirtualBox主机和虚拟机互相通信
我用的是法3
VirtualBox问题解决合集 - [drm:vmw_host_log [vmwgfx]] ERROR Failed to send host log message
redis
错误redis.exceptions.AuthenticationError: Client sent AUTH, but no password is set
redis cli 常用命令
最详细的docker中安装并配置redis
Windows系统下配置允许Redis远程访问
del 要删除的key (相当于表)
keys * (查看所有key)
mongodb
Windows下配置MongoDB远程连接
MongoDB 在windows服务器安装部署与远程访问配置
pymongo的基本操作
Python操作MongoDB看这一篇就够了
NoSQL Manager for MongoDB 教程(基础篇)
存在评论数据没解析成功,直接return导致错误,所以修改代码,不管如何都要执行到yield item
整个项目的变量就是:redis和mongodb的地址,ip可能会变
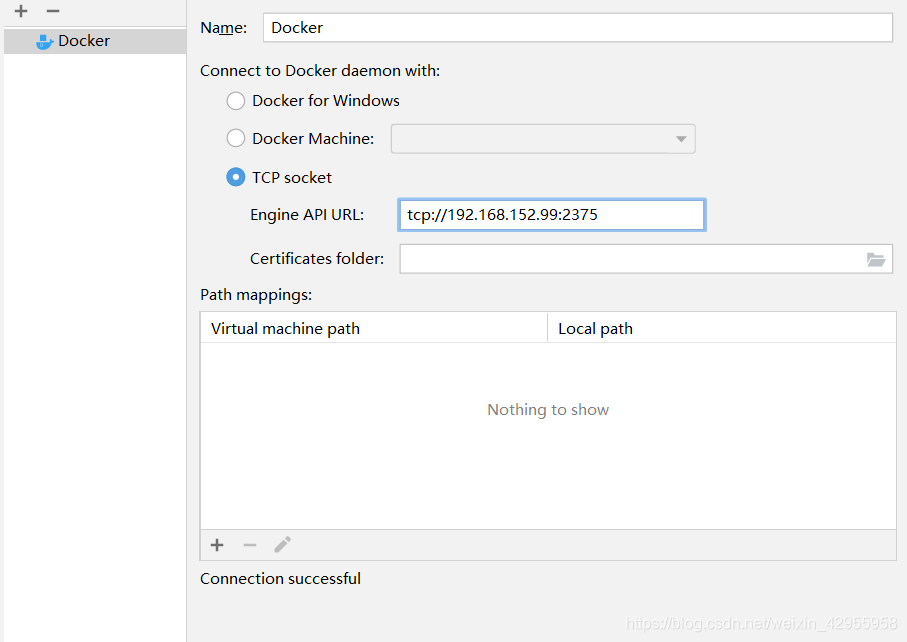
通过pycharm连远程docker
每次运行都要打开redis,容器是myredis
问题
经常改 redis和mongodb的ip,镜像怎么搞?
爬不到 id+url+名称+品牌
主要是ip受限
1、代理池(时好时坏)
2、寻求接口(试过了,找不到)
6.4使用代理ip可以访问京东,但是运行scrapy就出错,可能是没配置好
大作业三
资源下载:
MovieRecommenderSystem.zip
Elasticsearch集群安装部署过程中遇到的问题
Ubuntu中安装Elasticsearch
ubuntu 安装elasticsearch
su root
hostname
spark里我连不上hadoop1
hadoop1: ssh: connect to host hadoop1 port 22: Connection timed out
因为hosts的配置原因
本机的ip已经变了
192.168.38.129 hadoop1
192.168.38.130 hadoop2
192.168.38.131 hadoop3
127.0.0.1 localhost
127.0.1.1 yyh-VirtualBox
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
Linux系统下Spark启动出现 failed to launch: nice -n 0 spark-class org.apache.spark.deploy.worker.Worker
mongodb
sudo service mongodb start
sudo service mongodb stop
elasticsearch
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
bin/elasticsearch -d (后台)
zookeeper、kafka
vim config/server.properties
这里面的host.name用自己的hostname,我的是hadoop1
运行:
先启动zookeeper
bin/zkServer.sh start
查看状态
bin/zkServer.sh status
cd kafka/
确保这步什么都不返回
./bin/kafka-topics.sh --zookeeper 192.168.56.101:2181 --list
./bin/kafka-server-start.sh -daemon ./config/server.properties
查看是否启动
jps
./bin/kafka-console-producer.sh --broker-list 192.168.56.101:9092 --topic recommender
1|1271|4.5|1554276432
1|2066|4.5|1554276432
2066要这个存在才不会报错。。。
StreamingRecommender是成功的
15863 Kafka
13034 Elasticsearch
15900 Jps
23997 QuorumPeerMain
StreamingRecommender
StatisticsRecommender
OfflineRecommender
ContentRecommend都做好了
KafkaStreaming忘记有没有做好了
现在做到了这里:冷启动问题
flume
./bin/flume-ng agent -c ./conf/ -f ./conf/log-kafka.properties -n agent -Dflume.root.logger=INFO,console
错误: 找不到或无法加载主类 org.apache.flume.tools.GetJavaProperty
log4j的日志一直写不进去,反复查询发现,并不支持中文的路径
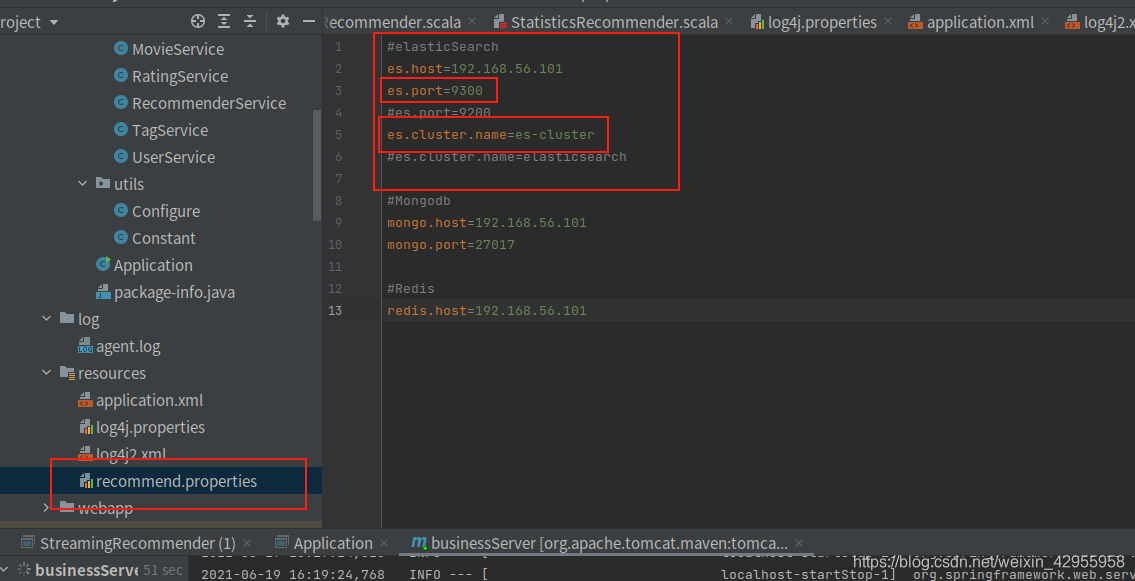
实时推荐总是不成功,原因如下:
[Elasticsearch编程中,NoNodeAvailableExceptionNone of the configured nodes are available 报错的一次解决
运行流程:
1、启动redis、elasticsearch、streamingRecommender
bin/elasticsearch -d
2、启动zookeeper
bin/zkServer.sh start
3、启动kafka
./bin/kafka-server-start.sh -daemon ./config/server.properties
4、启动flume
./bin/flume-ng agent -c ./conf/ -f ./conf/log-kafka.properties -n agent -Dflume.root.logger=INFO,console
5、启动Applicantion
6、启动业务系统


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











