






Many people may have some questions like:What is activation function? Why do we have so many activation function?Today,I will introduce the activation functions in neural network.
Convolutional neural network always consist of many neurons stacked in layers.Let’s consider a single neuron for simplicity.
What is Activation Function?
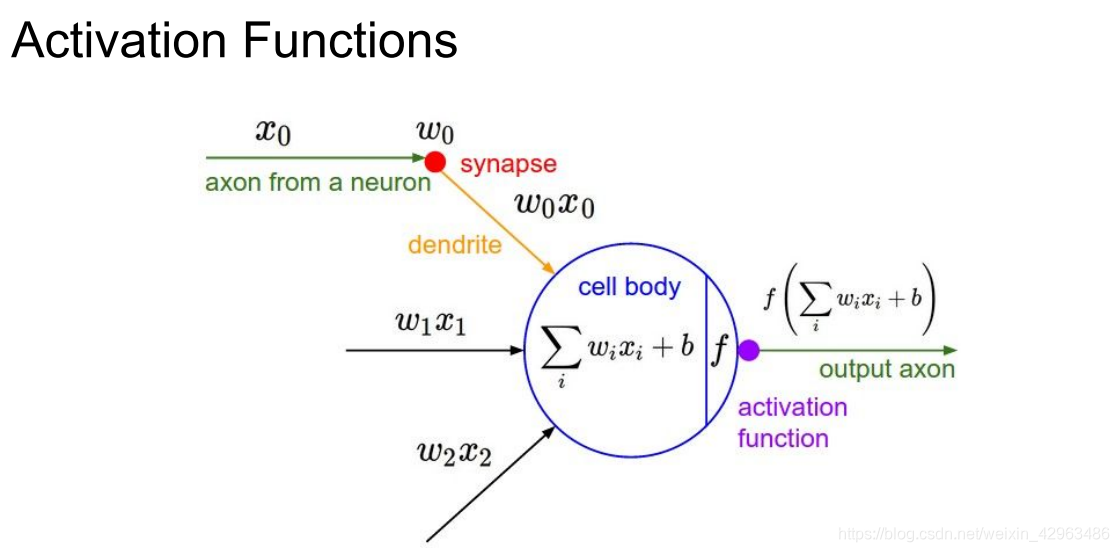
So what a simple artificial neuron do? The operations performed by a neuron basically involve multiplication and summation operations which are linear, and produce an output.
First of all,it calculate a “weighted sum” of its input, adds a bias.This makes the neuron only approximate linear functions.
Essentially, neural networks are constantly fitting data through updating the parameters.
Therefore,there has to be a way to add a non-linear property to the computation of results to make neural networks approximate non-linear or complex functions.
Then it is the activation functions that serves the purpose of introducing non-linearity into the model.,which makes it possible for the deep learning models to fit data well.
Common activation functions
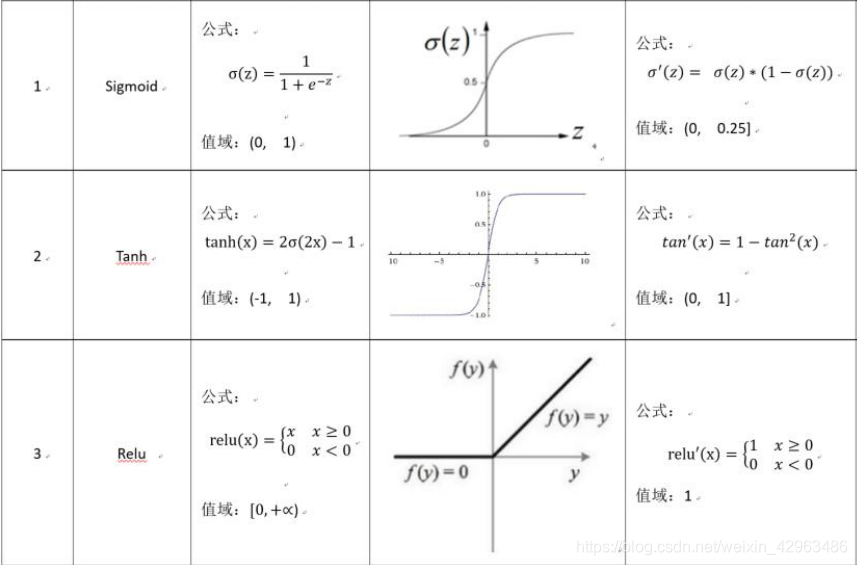
1.sigmoid
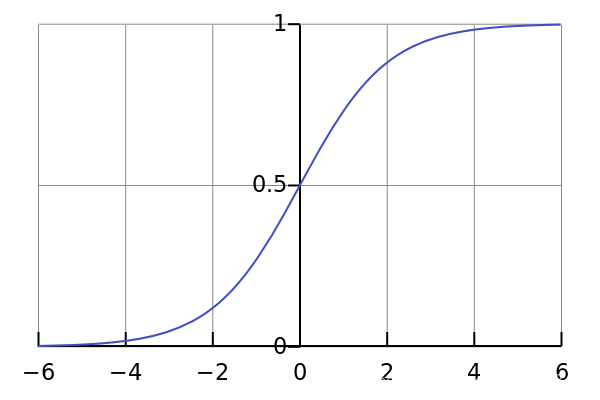
From the figure above,we can easily find that it squashes the input value to range zero to one,which makes data easier to converge during the process of transferring.While it have three drawbacks.
1.First,Saturation neurons will ‘kill’ the gradients.During back propagation, the gradient transmission decreases by at least 1/4 for each layer of neurons.it means that,the deeper the layer of the neural network,the more possibility the gradient will disappear.
2.The second problem is that sigmoid function output values are not zero-centered.if the data input of neuron are all positive,then the gradients coming back from the upstream on weight W are all positive or all negative,which gives very inefficient gradient update.
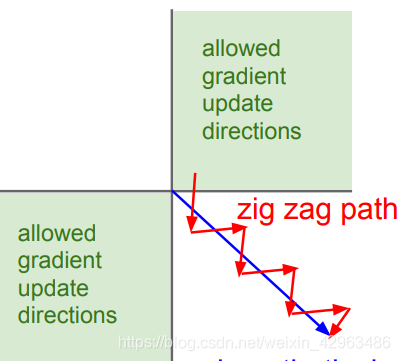
3.Another disadvantage is that the calculation of exponential function take more time to get the gradient .
2.tanh
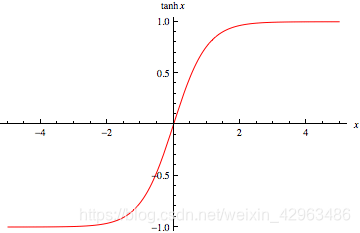
Compared to the sigmoid function ,tanh function squashes numbers to range [-1,1] and its output values are zero-centered.
Although the output value of this function get larger, the gradient decrease slowly during back propagation, which alleviates the problem of gradient disappearance, but the gradient is still lossy propagation, and the problem of gradient disappearance is still not solved.
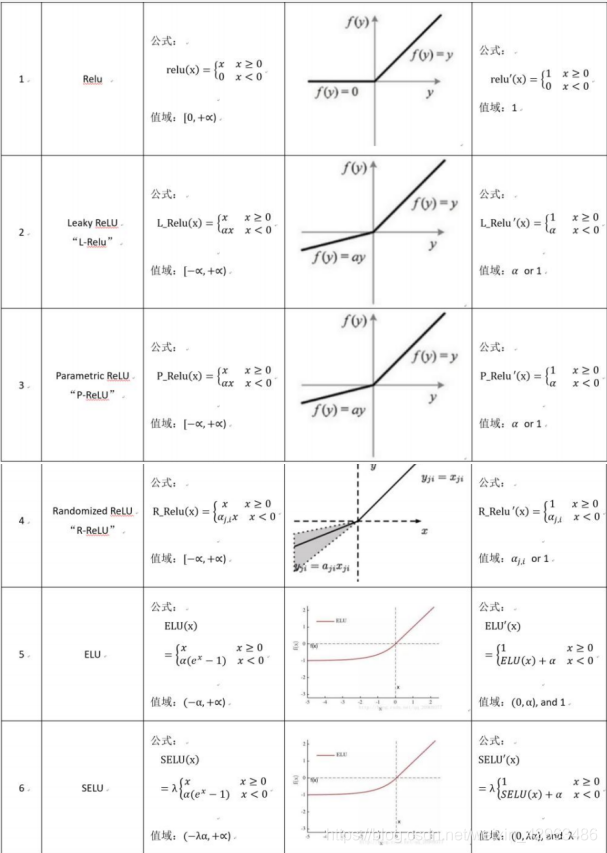
3.Relu
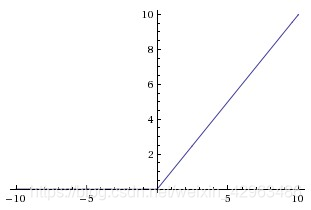
Currently, the most successful and widely-used activation function is the Rectified Linear Unit (ReLU) ,thanks to its simplicity and effectiveness.
Deep networks with ReLUs are more easily optimized and coverges much faster than networks with sigmoid or tanh units in practice, because gradients are able to flow and do not saturate when the input to the ReLU function is positive.What’s more, the Relu function is very computationally efficient.
Although the Relu function succefully solve the problem of gradient disappearanes,having bad initialization of weight and big learning rate will lead to a gradient explosion.And after updating the parameters,some neurons will be “dead” which means that it will never be activated.Also,the output value of Relu function is not zero-centered.
4.Leaky-Relu
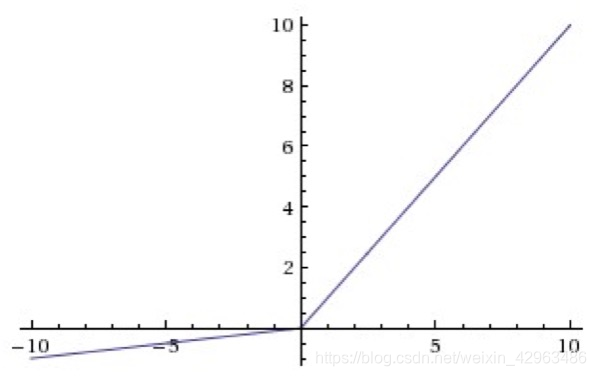
In order to settle the problem of “dead neuron”,when the input value is negative,the Leaky-Relu function adds a hyperparameter α,retains some values, and also corrects the data distribution,This parameter is usually set a small value, based on empirical values.
5.Randomized Relu

Compared to the leaky-relu function,the hyperparameter α in randomized relu is selected from a random distribution and then modified during the test process.
6.Parametric Relu
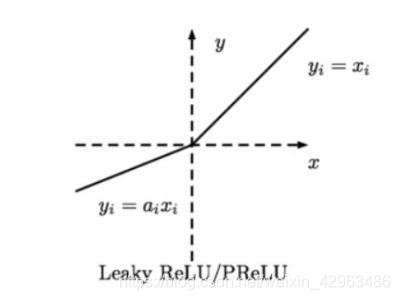
The parametric relu function converge faster than relu and leaky-relu function as the hyperparameter α can be trained and modified during train process.
7.Exponential Linear Unit(ELU)
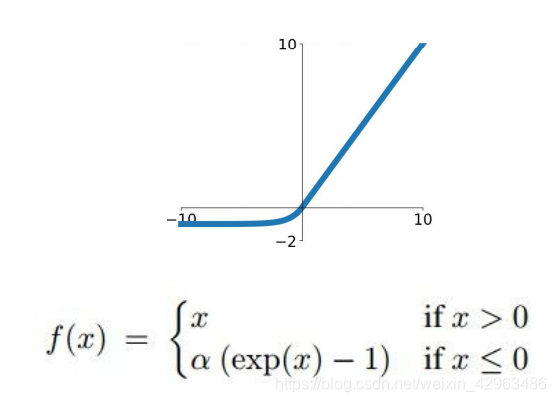
Exponential Linear Unit have all benefits of Relu and its output value is closer to zero-centered.Moreover,negative saturation status compared with Leaky-Relu adds some robustness to noise.But due to the operation of exponential function,it is a bit compute expensive.
Activation function table














 4277
4277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









