







 本文深入解析U-Net网络结构,详述其在医疗影像语义分割中的应用,以及其在处理小样本问题上的优势。文章介绍了U-Net的编码器-解码器结构,特别是Skip Connection和DoubleConv、Down、Up、OutConv模块的实现细节。此外,还提供了数据加载、模型选择、算法选择和预测流程的概述。
本文深入解析U-Net网络结构,详述其在医疗影像语义分割中的应用,以及其在处理小样本问题上的优势。文章介绍了U-Net的编码器-解码器结构,特别是Skip Connection和DoubleConv、Down、Up、OutConv模块的实现细节。此外,还提供了数据加载、模型选择、算法选择和预测流程的概述。
U-Net网络结构详解
在语义分割领域,基于深度学习的语义分割算法开山之作是FCN(Fully Convolutional Networks for Semantic Segmentation),而U-Net是遵循FCN的原理,并进行了相应的改进,使其适应小样本的简单分割问题。U-Net网络在医疗影像领域的应用十分广泛,成为了大多数医疗影像语义分割任务的baseline,同时基于U-Net网络改进网络也纷纷出现,本篇文章主要介绍U-NET网络。
由于医学图像往往包含噪声且边界模糊,仅靠低层次的图像特征难以进行目标检测。同时,由于缺乏图像的细节信息,仅靠图像语义特征无法得到准确的边界。而U-Net通过跳跃连接,将低分辨率和高分辨率的特征映射结合起来,有效地融合了低层次和高层次的图像特征,从而成为医学图像分割任务的一个理想解决方案。目前,U-Net已经成为了大多数医学图像分割任务的一个基准,并且激发了很多有意义的改进方法,其网络结构下图所示。
![![][pt_01]](https://i-blog.csdnimg.cn/blog_migrate/3c46eeec357f1147964179c9454af67f.png)
U-Net是一个全卷积神经网络,输入与输出都是图像,没有全连接层;并且由图可知,U-Net在宏观上是一个对称的网络结构,左侧为下采样,右侧为上采样,同时按照功能可以将左侧的一系列下采样操作称为encoder,将右侧的一系列上采样操作称为decoder,因此U-Net网络可以划分到Encoder-decoder基础模型类型中;该网络最主要的两个特点是:U型网络结构和Skip Connection跳层连接。
Skip Connection跳层连接中间四条灰色的箭头copy and crop,Skip Connection是在上采样的过程中,融合下采样过过程中的feature map。
Skip Connection跳层连接用到的融合的操作也很简单,就是将feature map的通道进行叠加,俗称Concat。例如,一个大小为256×256×64的feature map,即feature map的w(宽)为256,h(高)为256,c(通道数)为64;和一个大小为256×256×32的feature map进行Concat融合,就会得到一个大小为256×256×96的feature map。
在实际使用中,Concat融合的两个feature map的大小不一定相同,例如256×256×64的feature map和240×240×32的feature map进行Concat。解决这个问题有两种办法:
-
第一种:将大256×256×64的feature map进行裁剪,裁剪为240×240×64的feature map,比如上下左右,各舍弃8 pixel,裁剪后再进行Concat,得到240×240×96的feature map。
-
第二种:将小240×240×32的feature map进行padding操作,padding为256×256×32的feature map,比如上下左右,各补8 pixel,padding后再进行Concat,得到256×256×96的feature map。
U-Net网络核心思想:
- 不含全连接层(fc)的全卷积(fully conv)网络。可适应任意尺寸输入。
- 增大数据尺寸的反卷积(deconv)层。能够输出精细的结果。
- 结合不同深度层结果的跳级(skip)结构。同时确保鲁棒性和精确性。
这里使用1×1的卷积替代全连接层还有一个好处:输入的图片形状不再固定了。由于全连接层的输入必须固定形状的,所以输入模型的图片一般都要先resize到固定的shape,而使用1×1卷积代替全连接层之后变不在存在这一问题。在推理的时候,不需要再对图片进行resize,从而最好可能会导致输出的图片的失真。
这么一个不断加深网络并不断增加通道数来提取浅层信息和深层特征的过程就是编码器 (Encoder)。
U-Net未能解决的一些问题:
- 组织器官的顶层截面和底层截面与中部截面差异过大而不易识别;
- 不同扫描影像之间有较大的外观变异而不易识别;
- 磁场不均匀引起的伪影和畸变,导致不易识别。
U-Net网络架构实现代码解析
将U-Net网络中的架构分解为四个模块:
- 输入层的DoubleConv模块;
- 左侧分支从第二层开始的max_pool+DoubleConv,称为Down模块;
- 右侧分支的up_conv+copy_crop+DoubleConv,称为Up模块;
- 输出层的1x1卷积,称为OutConv模块。
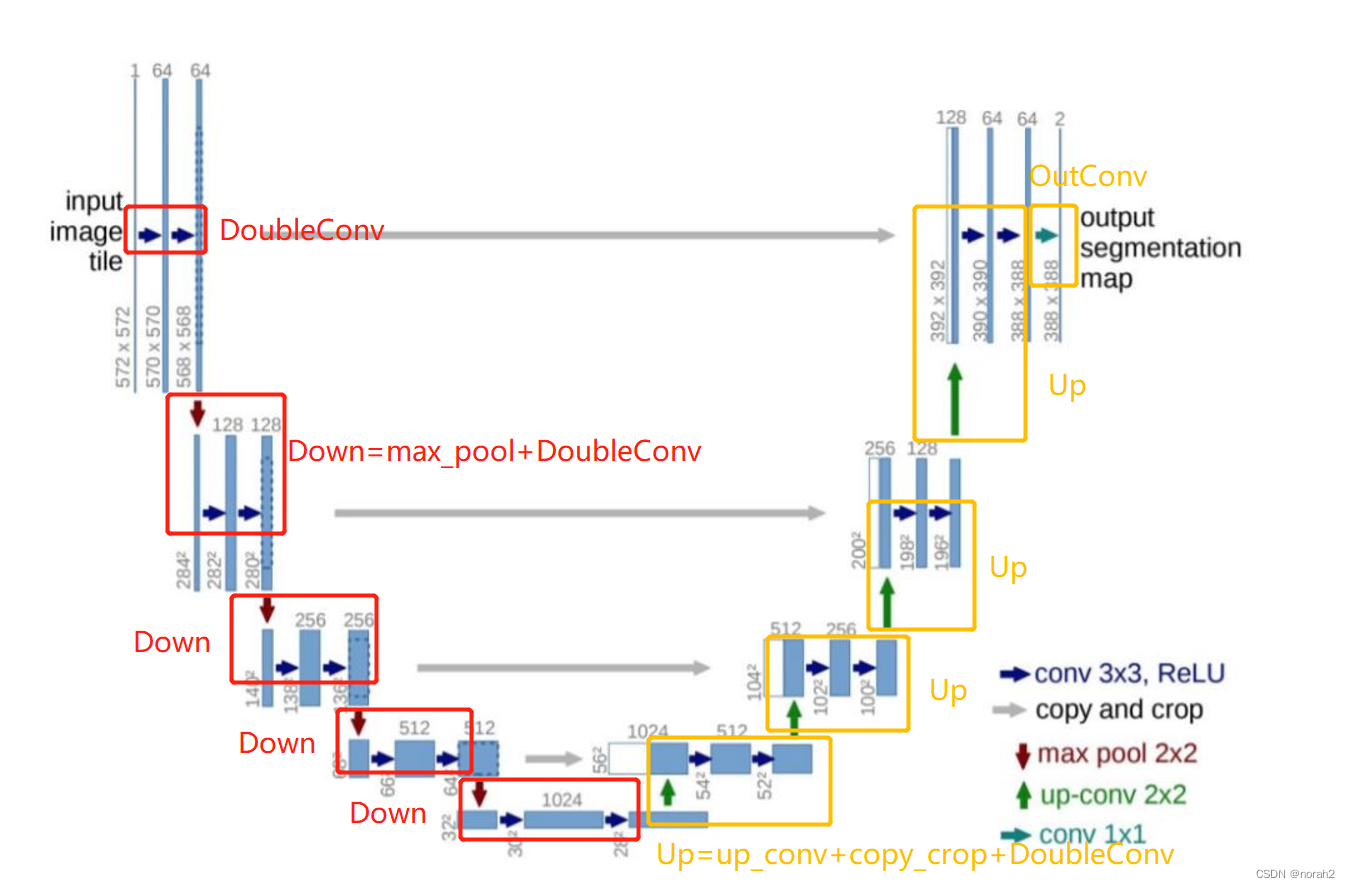
从上图可以看到,Unet网络的结构比较简单,左侧分支每一层包含两个重复的卷积,命名为DoubleConv;从第二层开始,都是max pool + DoubleConv;右侧分支每一层都是up conv + copy crop + DoubleConv;在最后输出层,有一个1x1 conv。
1. 模块实现
1.1 DoubleConv模块
DoubleConv模块由两个“Conv2d+NatchNorm2d+ReLU”组成:
# unet_parts.py
import torch
import torch.nn as nn
import torch.nn.functional as F
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
1.2 Down模块
Down模块由一个“MaxPool2d+DoubleConv”组成:
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
1.3 Up模块
右侧上行模块涉及到copy and crop,实现起来会略微复杂一些。首先经过一个上采样或转置卷积,然后从左侧路径的同一层feature map中截取相同的size(从图中很容易可以看出,左侧同一层中的feature map比右侧的size要大一些),与右侧feature map合并,最后再进行DoubleConv。代码如下:
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
else:
self.up = nn.ConvTranspose2d(in_channels // 2, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = torch.tensor([x2.size()[2] - x1.size()[2]])
diffX = torch.tensor([x2. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









