






目录
定义
为了验证一个新策略的效果,准备原策略A和新策略B两种方案。 随后在总体用户中取出一小部分,将这部分用户完全随机地分在两个组中,使两组用户在统计角度无差别。将原策略A和新策略B分别展示给不同的用户组,一段时间后,结合统计方法分析数据,得到两种策略生效后指标的变化结果,并以此判断新策略B是否符合预期
相关概念
1. 白名单
实验正式开启之前,通常需要先选择几名用户进入测试阶段,观察实验是否能够正常获取想要收集的数据,或客户端是否有bug等。参与这一步的用户被称为“白名单用户
2. 流量正交&正交实验
互斥组=互斥层=实验层
每个独立实验为一层,一份流量穿越每层实验时,都会随机打散再重组,保证每层流量数量相同。
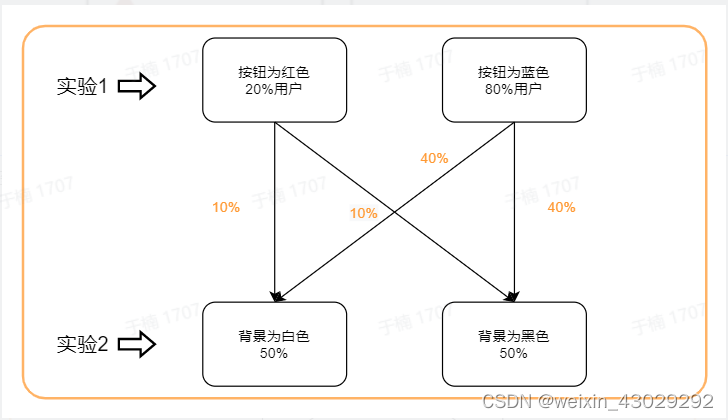
举个例子。假设我现在有2个实验。
- 实验A(实验组标记为A1,对照组标记为A2)分布于实验层1,取用该层100%的流量;
- 实验B(实验组标记为B1,对照组标记为B2)分布于实验层2,也取用该层100%的流量。
要注意,实验层1和实验层2实际上是同一批用户,实验层2只是复用了实验层1的流量 。
如果把A1组的流量分成2半,一份放进B1组,一份放进B2组;
再把A2组的流量也分成2半,一份放进B1组,一份放进B2组。
那么两个实验对于流量的调用就会如下图所示。此时实验A和实验B之间,就形成了流量“正交”。
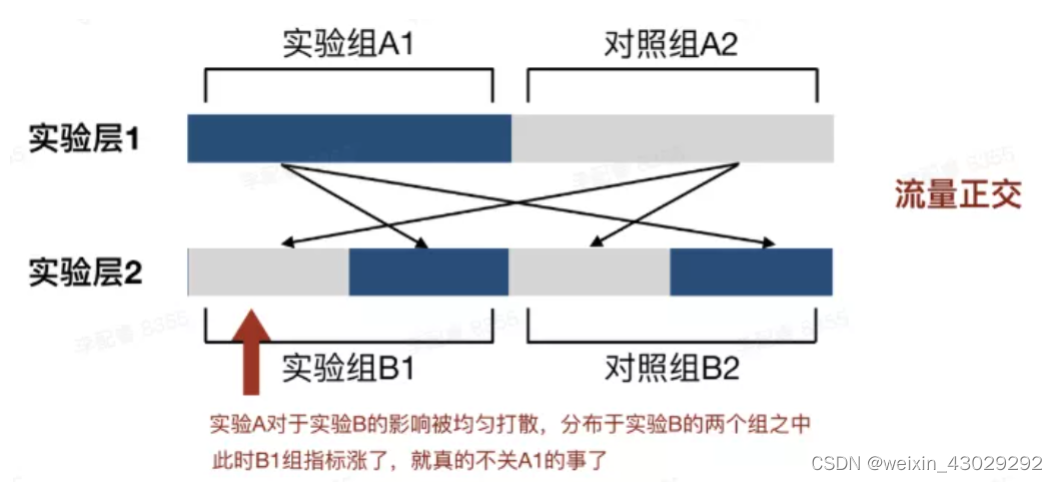
流量正交有什么意义呢?
我们可以发现,因为A1组的一半流量在B1中,另一半流量在B2中,因此即使A1的策略会对实验B产生影响,那么这种影响也均匀的分布在了实验B的两个组之中;
在这种情况下,如果B1组的指标上涨了,那么就可以排除B1是受A1影响才形成上涨。这就是流量正交存在的意义。
对与分层实验有个很重要的点就是每一层用完的流量进入下一层时,一定均匀的重新分配。
3. 灰度发布
是指在黑与白之间,能够平滑过渡的一种发布方式。AB test就是一种灰度发布方式,让一部分用户继续用A,一部分用户开始用B,如果用户对B没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到B上面来。
4.检验灵敏度
MDE是什么:Minimum Detectable Effect (MDE),最小可检测单位,即检验灵敏度,是实验在当前条件下能有效检测的指标diff幅度。有效检测,指检出概率大于等于80%(type II error小于等于20%)。
通过比较指标MDE与指标的目标提升率,以避免实验在灵敏度不足的情况下被过早作出非显著结论 而结束,错失有潜力的feature。
AB Test 完整的实验流程
1. 流程
-
确定需要对比的两个方案及试验目标-确定目标以及创建辩题
-
生成假设
-
确定评估指标:确定衡量优化效果的指标(如:CTR,停留时长等)
-
确定实验用户群体和最小实验的样本数
- 分配流量:确定实验分层分流方案,以及实验需要切分多少流量,一般根据最小样本量确定
- 确定实验有效天数:实验的有效天数即为实验进行多少天能达到流量的最小样本量。
- 上线实验
- 收集数据
- 分析AB test 结果评估,采用t、z和f检验计算相关统计量和p值,p小于
,则拒绝原假设。
2. 注意事项
- 保证变量单一(实验组和对照组只有一个变量不同,控制变量)
- 保证样本量合适、实验时长合适
- 用户分流分层合适
- 指标确定合理(统计功效方面)
3. 假设检验
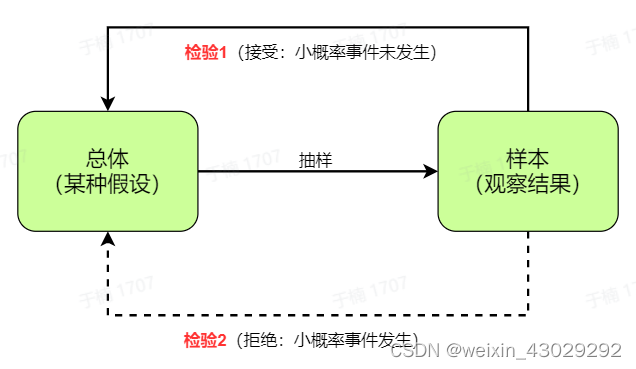
- 假设检验是用来判断样本与样本,样本与总体的差异是由抽样误差引起,还是有本质差别造成的统计推断方法。
- 假设检验是先对总体的参数提出某种假设,然后利用样本数据判断假设是否成立的过程。逻辑上运用反证法,统计上依据小概率思想。
小概率思想是指小概率事件(显著性水平 p < 0.05)在一次试验中基本上不会发生
具体到AB Testing,就是假设实验版本的总体参数(优化指标均值)等于对照版本的总体参数,然后利用这两个版本的样本数据来判断这个假设是否成立。
- 原假设H0:这项改动不会对核心指标有显著的影响
- 备选假设H1:这项改动会对核心指标有显著影响
假设检验工具:Evans awesome AB Tools
4. 实验
- 正交实验:如果实验之间共享同一份流量实验效果之间不干扰,这样的实验我们叫正交实验,这种情况下,流经两个实验的流量是可以共享的,流经实验一的流量也可以流经实验二
- 互斥实验:如果分层共享同一份流量就有可能出现实验效果之间相互干扰的问题,这样的实验叫互斥实验,也就是如果实验一和实验二是互斥关系,那么经过实验一的流量就不能进入到实验二
5. 分流
- 实验有了,怎么分流也很重要。分流指的是根据分流算法策略为每层的每个实验分配相应的流量,从请求角度来说,是让每个请求都能在各层能准确稳定的命中到相应实验。
- 每一层的每个实验的实验组和对照组就是一个分组,每层的流量一共是100,假设这一层有两个实验分别是实验一和实验二,流量配比各为50%,每个实验各有一实验组和对照组,实验组和对照组平分流量各得25%,那么这里每层实验就有4个分组。
- 整体流量按分组划分,从0开始编号的话,可以认为,实验一组一的分组装的是0~24的编号,实验一组二的分组装的是25~49编号,类推,实验二组二的分组装的是75~99的编号。一个流量请求在每一层中只能命中到一个实验组,也就是说只能被分到一个分组内。
- 一般我们会选择用用户id和实验层id哈希取模(mod=f(uid, layer)%100),得到的值在哪个分组内,该请求就命中哪个实验的那个组,这样 保证了用户在每层命中的实验是随机且是稳定的
6. 确定最小样本量
- 每一个实验组所需的样本量计算公式如下:
置信水平:
统计功效:
,
为样本标准差,
为组间预期差值
- 当观测指标为绝对值类指标时:
其中:n为样本数量,
为样本均值
当观测指标为比率类指标时:
其中
分别为对照组和实验组的观测数据
计算样本量比较常见且好用的在线计算工具:Evans awesome AB Tool
7. 确定实验时长
- 试验进行多少天能达到流量的最小样本量
- 同时还要考虑到用户的行为周期和适应期
- 试验结果的置信区间的收敛速度。如果置信区间达到3%-5%已经可以决策了,就可以停止试验
8. Z检验
-
一般要求总体方差已知,或者方差未知但是样本量足够大(一般需要大于30,可以用样本的方差代替总体方差)
-
用于检验一个样本的均值是否与某个固定值有显著性差异,或者两个样本的均值是否有显著性差异
9. T检验
-
当总体方差未知并且样本个数比较少(少于30)时,一般用t检验。
-
t检验需要样本满足正态分布,用于正态分布总体均值的显著性检验问题。
不显著现象及解决
- 统计显著!= 实际显著
可能的原因是我们在AB测试当中所选取的样本量过大,导致和总体数据量差异很小,这样的话即使我们发现一个细微的差别,它在统计上来说是显著的,在实际的案例当中可能会变得不显著了。
对应到我们的互联网产品实践当中,我们做了一个改动,APP的启动时间的优化了0.001秒,这个数字可能在统计学上对应的P值很小,也就是说统计学上是显著的,但是在实际中用户0.01秒的差异是感知不出来的。
- AB测试效果统计上不显著,就直接放弃?
对于这种情况,我们所选取的一种通用的方式是将这个指标去拆分成每一天去观察。
如果指标的变化曲线每一天实验组都高于对照组,即使他在统计上来说是不显著的,我们也认为在这样一个观测周期内,实验组的关键指标表现是优于对照组的,那么结合这样一个观测,我们最终也可以得出这个优化可以上线的结论。
-
实验组优于对照组就能上线?
不一定。举个例子,比如说有的时候我们想要提升产品的视觉展现效果。但是这种优化可能是以用户等待内容展现的时间作为代价来进行提升的。
所以一个方面的优化可能会导致另一个方面的劣化。在做这个优化的时候,可能会对其他部门产生一些负向的影响,进而导致公司收入的下降。
所以我们在进行AB测试的时候,必须要综合评估所有方面的一些指标变动,同时对于收益和损失来做一个评估,才能确认这个优化可以最终上线。
-
AB测试是必须的么?
如果只是验证一个小按钮或者一个小改动,我们可以在界面上去设置一个开关,用户可以通过开关的形式自行决定采用哪一种方式。
那么我们最后就可以通过这个开关的相关指标去判断用户对于哪一种形式又有更大的倾向性。
或者有的时候我们可以去做一些用户调研,比如说通过访谈或者说是设计问卷的形式,去收集一些用户的反馈。或者他们关于这些小变动的体验,所以并不是绝对的。
后续会更新:假设检验原理,其它必要统计学知识。
点个赞再走,这次一定~~

















 1616
1616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









