







使用了惰性计算分段,和表达式求值的编程方式
在尽量保证效率的同时
基本上保证了代码初步的健壮度可复用性以及拓展性
create_char_map 可以继续拓展语言或者编码范围
from itertools import permutations
import re
def create_char_map(str_range = 'lowercase',chinese_path = False):
iter_range = lambda char_range : map(lambda x : chr(x),char_range)
func_dict = {'lowercase':iter_range(range(97,122))
,'uppercase':iter_range(range(65,90))
,'numbers':iter_range(range(48,57))}
if chinese_path:
func_dict.update({'chinese':(char for char in open(chinese_path).readlines())})
return func_dict["chinese"]
else:
return func_dict[str_range]
def collate_char_iterator(itertools_perm):
return map(lambda x:"".join(x),itertools_perm)
def chargen(language="lowercase",n=1):
return collate_char_iterator(permutations(create_char_map('lowercase'),n))
def add_char(input_char,language="lowercase",n=2,forward=True):
return ("{}{}".format(char,input_char)
if forward==True else "{}{}".format(input_char,char)
for char in chargen(language=language,n=n))
def replace_char(input_char,language="lowercase",n=2):
m = len(input_char)
S = chargen(language=language,n=n)
for create_str in S:
for i in range(m):
result = yield input_char.replace(input_char[i:i+n],create_str)
symbles=''':,"{[}](>)</\n。● ,、的 啊 好 和
并 与 及 对 错 你 我 我们 她 他 它:: ; ;《 》
1 2 3 4 5 6 7 8 9 0 ‘ “ ” ’ + - * / ` ~
\( \ [ \ { \ } ] ) ( )【 \xa0 】理想 愿景
工 不管 只要 一员 大家庭 当成 作 帅哥 美女 年轻
佛系
'''
def delete_element(strings,symbles=symbles):
srcrep = {i:'' for i in symbles }
rep = dict((re.escape(k), v) for k, v in srcrep.items())
pattern = re.compile("|".join(rep.keys()))
return pattern.sub(lambda m: rep[re.escape(m.group(0))], strings)
def delete_char(input_char,language="lowercase",n=2):
return (delete_element(input_char,"".join(chars)) for chars in permutations(input_char,n))
def translation_str(input_char,language="lowercase",n=2):
del_ = delete_char(input_char,language=language,n=n)
replace_ = replace_char(input_char,language=language,n=n)
add_forward = add_char(input_char,language=language,n=n,forward=True)
add_backward = add_char(input_char,language=language,n=n,forward=False)
return tuple(list(del_)+list(replace_)+list(add_forward)+list(add_backward))
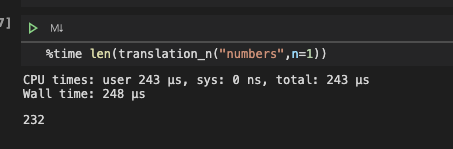
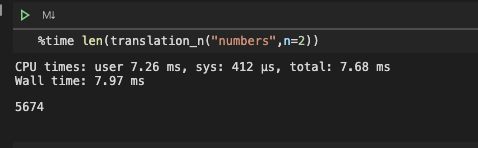
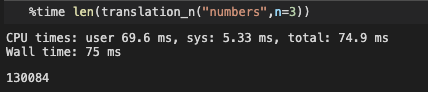
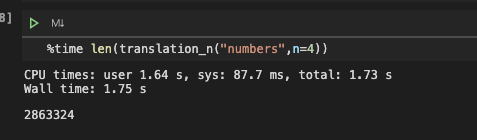
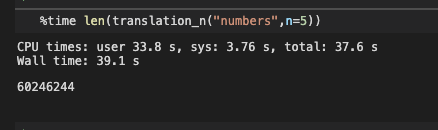
def translation_n(input_char,language="lowercase",n=2):
result = []
for i in range(1,n+1):
result += list(translation_str(input_char,language=language,n=i))
return result















 20万+
20万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









