







前言
一般来说,导出pdf可以前端操作也可以后端操作,但是后端如果生成比较复杂的pdf还是比较麻烦的,所以我们可以看一下使用itextpdf和Adobe Acrobat 根据模板生成pdf的操作
一、准备工作
- 使用word先制作需要生成的pdf的模板样式

- 输出为pdf
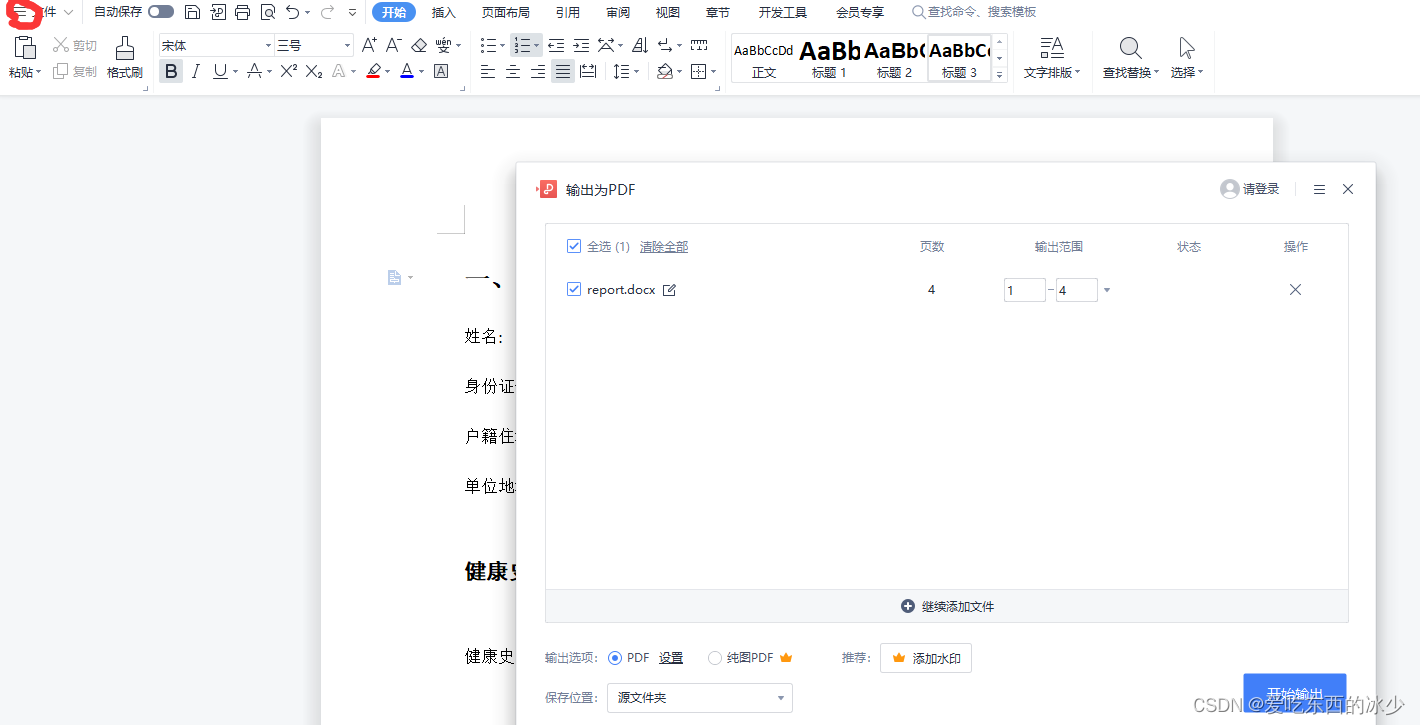
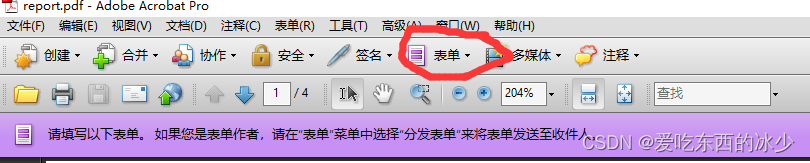
- 将生成的pdf模板拖进Adobe Acrobat点击表单的添加或编辑域
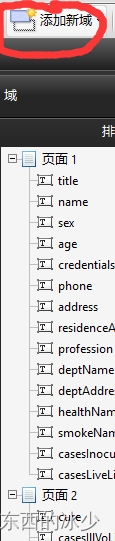
- 可能会自动检测到一些域但是不全,我们可以自己添加并且编辑相关的属性,如图:
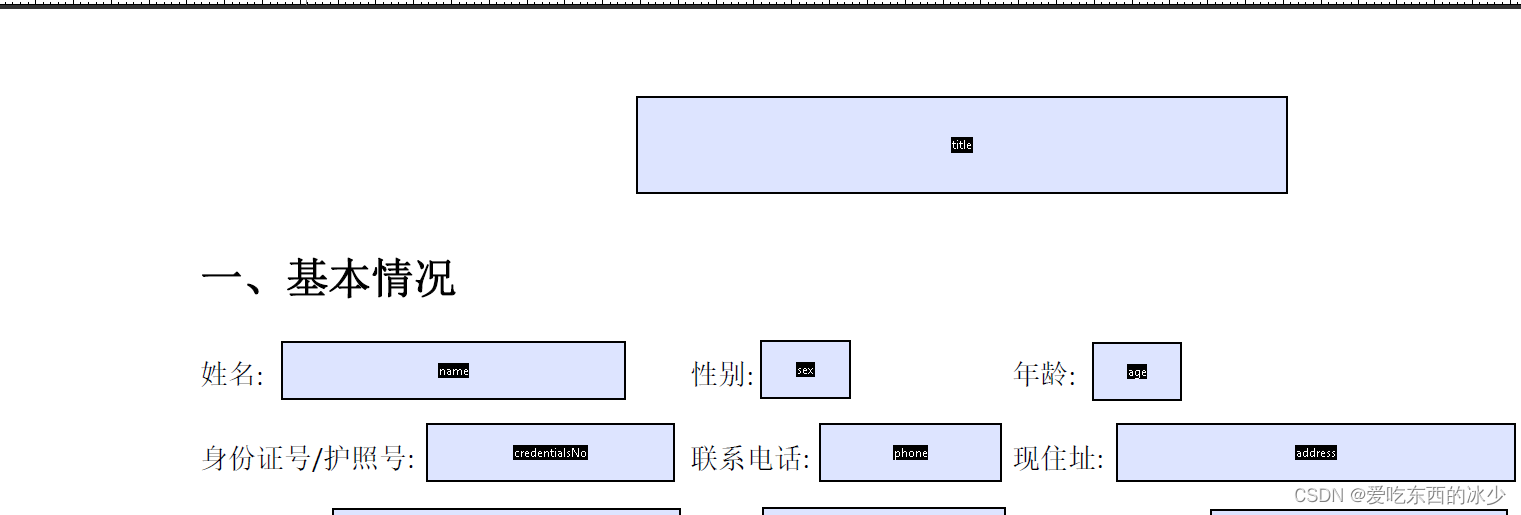
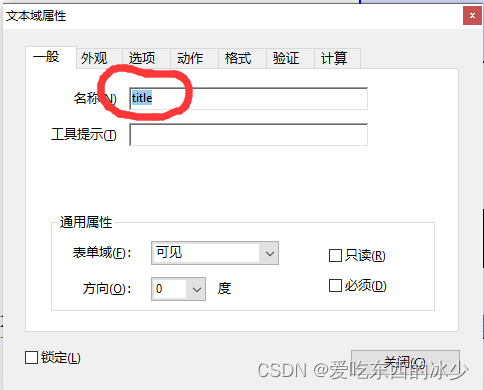
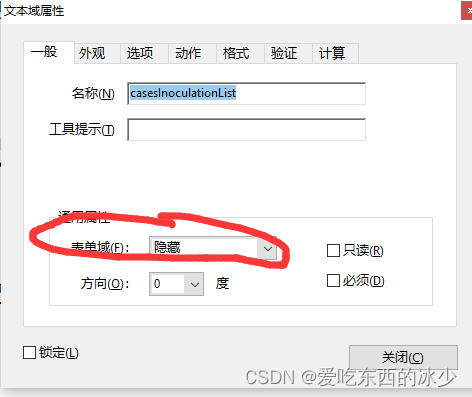
5. 如果想要写入集合,可以添加文本域也可以添加集合,但是要把文本域设为隐藏:
二、整合项目
1.添加相关依赖
如下(示例):
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.4.3</version>
</dependency>
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itext-asian</artifactId>
<version>5.2.0</version>
</dependency>
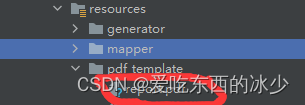
2.将准备好的模板pdf放入到项目中
如下(示例):
3.相关代码
- 读取模板以及设置字体
org.springframework.core.io.Resource resource = new ClassPathResource("pdf_template/report.pdf");
PdfReader reader = new PdfReader(resource.getInputStream());
BaseFont bf = BaseFont.createFont();
// Font FontChinese = new Font(bf, 5, Font.NORMAL);
ByteArrayOutputStream bos = new ByteArrayOutputStream();
PdfStamper stamper = new PdfStamper(reader, bos);
AcroFields form = stamper.getAcroFields();
form.addSubstitutionFont(bf);
BaseFont bfChinese = BaseFont.createFont("STSongStd-Light", "UniGB-UCS2-H", BaseFont.NOT_EMBEDDED);
float bigFontSize = 10;
// false可编辑
stamper.setFormFlattening(true);
- 普通数据的录入,即模板中文本域对应单字段的录入:
Map<String, String> map1 = new HashMap<>(32);
map1.put("title", jsonObject.get("name").toString());
map1.put("name", casesVo.getName());
map1.forEach((key, value) -> {
try {
if ("title".equals(key)) {
//设置这个表单域的字体
form.setFieldProperty(key, "textfont", bfChinese, null);
//设置这个表单域的字体大小
form.setFieldProperty(key, "textsize", 18, null);
form.setField(key, value);
} else {
//设置这个表单域的字体
form.setFieldProperty(key, "textfont", bfChinese, null);
//设置这个表单域的字体大小
form.setFieldProperty(key, "textsize", bigFontSize, null);
form.setField(key, value);
}
} catch (IOException e) {
e.printStackTrace();
} catch (DocumentException e) {
e.printStackTrace();
}
});
- 集合的录入:
不需要表头
Map<String, List<List<String>>> mapList = new HashMap<>(4);
// 业务获取的需要填充的集合/表单数据
List<CasesInoculationVo> casesInoculationVos = casesVo.getCasesInoculationVos();
List<List<String>> list = new LinkedList<>();
if (CollectionUtil.isNotEmpty(casesInoculationVos)) {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
casesInoculationVos.forEach(casesInoculationVo -> {
List<String> itemList = new LinkedList<>();
StringBuilder sb = new StringBuilder();
sb.append("第" + casesInoculationVo.getSequnce() + "剂次: " + sdf.format(casesInoculationVo.getInoculationTime()) + " 疫苗厂家: " + casesInoculationVo.getManufacturerName());
itemList.add(sb.toString());
list.add(itemList);
});
mapList.put("casesInoculationList", list);
}
需要表头
// 家庭成员或同住人
List<CasesLiveVo> casesLiveVos = casesVo.getCasesLiveVos();
List<List<String>> listCasesLiveVo = new LinkedList<>();
if (CollectionUtil.isNotEmpty(casesLiveVos)) {
List<String> itemListTitle = new LinkedList<>();
itemListTitle.add("姓名");
itemListTitle.add("性别");
itemListTitle.add("年龄");
itemListTitle.add("身份证/护照号");
itemListTitle.add("联系方式");
itemListTitle.add("现住址");
itemListTitle.add("户籍地址");
itemListTitle.add("工作/学习单位");
itemListTitle.add("单位地址");
listCasesLiveVo.add(itemListTitle);
casesLiveVos.forEach(casesLiveVo -> {
List<String> itemList = new LinkedList<>();
// add的顺序要和表头顺序一致,不然数据错乱
itemList.add(casesLiveVo.getName());
itemList.add("1".equals(casesLiveVo.getSex()) ? "男" : "女");
if (casesLiveVo.getAge() == null) {
itemList.add("");
} else {
itemList.add(String.valueOf(casesLiveVo.getAge()));
}
itemList.add(casesLiveVo.getIdCard());
itemList.add(casesLiveVo.getPhone());
itemList.add(casesLiveVo.getCurrentAddress());
itemList.add(casesLiveVo.getHomeAddress());
itemList.add(casesLiveVo.getOrg());
itemList.add(casesLiveVo.getOrgAddress());
listCasesLiveVo.add(itemList);
});
}
mapList.put("casesLiveList", listCasesLiveVo);
mapList.forEach((key, value) -> {
if (CollectionUtil.isNotEmpty(value)) {
int pageNo = form.getFieldPositions(key).get(0).page;
PdfContentByte pcb = stamper.getOverContent(pageNo);
Rectangle signRect = form.getFieldPositions(key).get(0).position;
//表格位置
int column = value.get(0).size();
int row = value.size();
PdfPTable table = new PdfPTable(column);
float totalWidth = signRect.getRight() - signRect.getLeft();
int size = value.get(0).size();
float[] width = new float[size];
for (int i = 0; i < size; i++) {
// if (i == 0) {
// width[i] = 60f;
// } else {
// width[i] = (totalWidth - 60) / (size - 1);
// }
width[i] = totalWidth / size;
}
try {
table.setTotalWidth(width);
} catch (DocumentException e) {
e.printStackTrace();
}
table.setLockedWidth(true);
table.setKeepTogether(true);
table.setSplitLate(false);
table.setSplitRows(true);
Font fontProve = new Font(bfChinese, 10, 0);
//表格数据填写
for (int i = 0; i < row; i++) {
List<String> itemListNew = value.get(i);
for (int j = 0; j < column; j++) {
// Paragraph paragraph = new Paragraph(String.valueOf(itemListNew.get(j)), bfChinese);
Phrase phrase = new Phrase(String.valueOf(itemListNew.get(j)), fontProve);
PdfPCell cell = new PdfPCell(phrase);
// 这里自己根据业务过滤,我这两个key是不需要进行显示出表格的边框的所以不设置边框并且左对齐
if (key.equals("casesInoculationList") || key.equals("casesTraceVoList")) {
cell.setBorderWidth(0);
cell.setHorizontalAlignment(Element.ALIGN_LEFT);
} else {
cell.setBorderWidth(1);
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
}
cell.setVerticalAlignment(Element.ALIGN_CENTER);
cell.setLeading((float) 3.0, (float) 1.0);
cell.setMinimumHeight(15f);
table.addCell(cell);
}
}
table.writeSelectedRows(0, -1, signRect.getLeft(), signRect.getTop(), pcb);
}
});
- 关闭工作
stamper.close();
response.setContentType("application/pdf");
response.setCharacterEncoding("utf-8");
response.setHeader("Content-Disposition", "attachment;filename=report.pdf");
OutputStream out = response.getOutputStream();
out.write(bos.toByteArray());
out.flush();
out.close();
bos.close();
- 导出效果


总结
提示:这里是在浏览器下载的示例,入参是有HttpServletResponse response 参数的,对应关闭工作的输出流的response:
以上就是今天要讲的内容,本文仅仅简单介绍了java根据模板导出pdf的使用














 1172
1172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









