







 文章讲述了在K8S集群中遇到的Pod持续pending问题,原因在于节点资源不足。通过排查发现集群没有资源限制配置,解决方法包括限制现有Pod的资源使用、创建全局LimitRange配置以及修改sidecar容器配置。最终验证了这些措施的有效性。
文章讲述了在K8S集群中遇到的Pod持续pending问题,原因在于节点资源不足。通过排查发现集群没有资源限制配置,解决方法包括限制现有Pod的资源使用、创建全局LimitRange配置以及修改sidecar容器配置。最终验证了这些措施的有效性。
问题
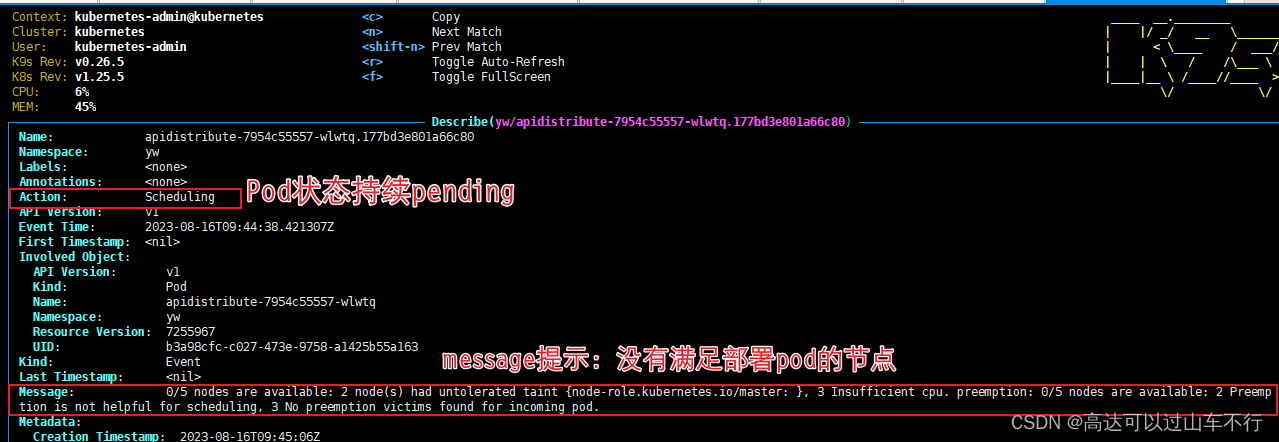
K8S节点CPU资源不足导致容器部署失败,Pod持续Pending。具体报错如下:
Message: 0/5 nodes are available: 2 node(s) had untolerated taint {node-role.kubernetes.io/master: }, 3 Insufficient cpu. preemption: 0/5 nodes are available: 2 Preemption is not helpful for scheduling, 3 No preemption victims found for incoming pod.
背景描述
K8S集群已投入测试使用,除了kubes-ystem命名空间内的系统容器之外,已正常运行着70余个Pod。今日开发突然告知:新部署的Pod持续Pending,多次重新部署也无法解决。
- 集群信息
– 5节点集群:2主3从 ,主节点8C16G,从节点8C24G ,使用docker,运行在KylinOSV10-SP2上。 - 资源使用情况:
–CPU使用率7%,内存使用率49%

- 推断:实际资源仍有盈余,但可能存在类似于VMware虚拟机资源分配的机制,在不允许超分的情况下,CPU资源被已有容器已经分配完。导致新创建的容器没有足够的CPU资源使用。
参考文章
【OpenStack论坛的解决:Pod in pending state due to Insufficient CPU [closed]】
【利用limitrange限制容器资源,增加可部署的Pod数量:kubernetes中LimitRange的理解】
问题排查及原因
问题表现
- Pod持续pending,不管重新部署deployment,还是重建Pod,也都持续pending。
- K8S日志显示节点不可用: 2 node(s) had untolerated taint {node-role.kubernetes.io/master: }, 3 Insufficient cpu. (此处报错符合集群情况,2个主节点带有taint因此不可用,3个从节点被划分了太多cpu因此不可用)。
- 删除已有的某个Pod后,新部署的pod从pending状态变为正常running状态。说明node上运行的pod已经到达某个阈值,只有释放部分资源才能保证新的pod正常运行。印证了上文中的推断。
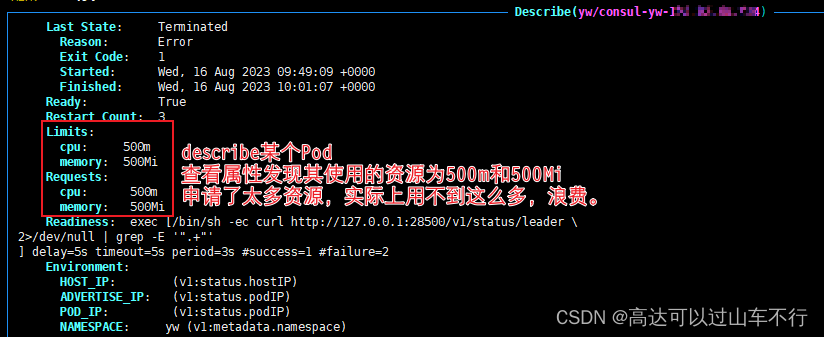
- 检查Pod内容器对资源的使用情况:分别检查“仅包含1个容器的Pod”和“使用了sidecar容器的Pod”,查看容器的资源使用情况。

- 查看K8S集群是否存在资源限制配置:是否存在limitrange
[sysma@prod-k8s-0001 ~]$ kubectl get limits
No resources found in default namespace.
[sysma@prod-k8s-0001 ~]$ kubectl get limits -A
No resources found
[sysma@prod-k8s-0001 ~]$ kubectl get limitrange -o=yaml
apiVersion: v1
items: []
kind: List
metadata:
resourceVersion: ""
[sysma@prod-k8s-0001 ~]$
在K8Smaster节点上运行上述命令,此处结果显示当前K8S集群没有对资源使用做出任何限制。因此容器的资源限制均以对应的deploy控制器中的配置为主。
解决
根本解决:要么减少已有Pod使用的计算资源(CPU和memory),要么新增K8S节点和计算资源。此处选择前者,双管齐下解决问题。
创建全局limitrange配置文件,限制容器使用的计算资源。
全局limitrange可以限制未来新创建的容器,或重新创建的容器,但不能限制正在运行的容器(如果不是生产业务,重启一下Pod就能被限制)。
参考【利用limitrange限制容器资源,增加可部署的Pod数量:kubernetes中LimitRange的理解】先理解limitrange然后再创建。
基本操作顺序:
- 检查是否存在全局limitrange配置文件,有则修改,无则创建。
- 根据实际情况编写全局limitrange配置文件limit.yml。
- 在K8S-master节点上应用配置文件:kubectl apply -f limit.yml
- 新建Pod验证资源使用情况。
- 重启已有Pod验证资源使用情况。
此处我是用的limitrange配置文件为:
apiVersion: v1
kind: LimitRange
metadata:
name: limits-all
spec:
limits:
- max:
cpu: "600m"
memory: 400Mi
min:
cpu: 200m
memory: 200Mi
maxLimitRequestRatio:
cpu: 3
memory: 2
type: Pod
- default:
cpu: 200m
memory: 100Mi
defaultRequest:
cpu: 200m
memory: 100Mi
max:
cpu: "200m"
memory: 200Mi
min:
cpu: 100m
memory: 100Mi
maxLimitRequestRatio:
cpu: 2
memory: 2
type: Container
修改自定义对象sidecar配置,限制sidecar容器使用的计算资源
全局limitrange配置文件不会对自定义对象sidecar容器生效,需单独修改sidecar容器的配置。
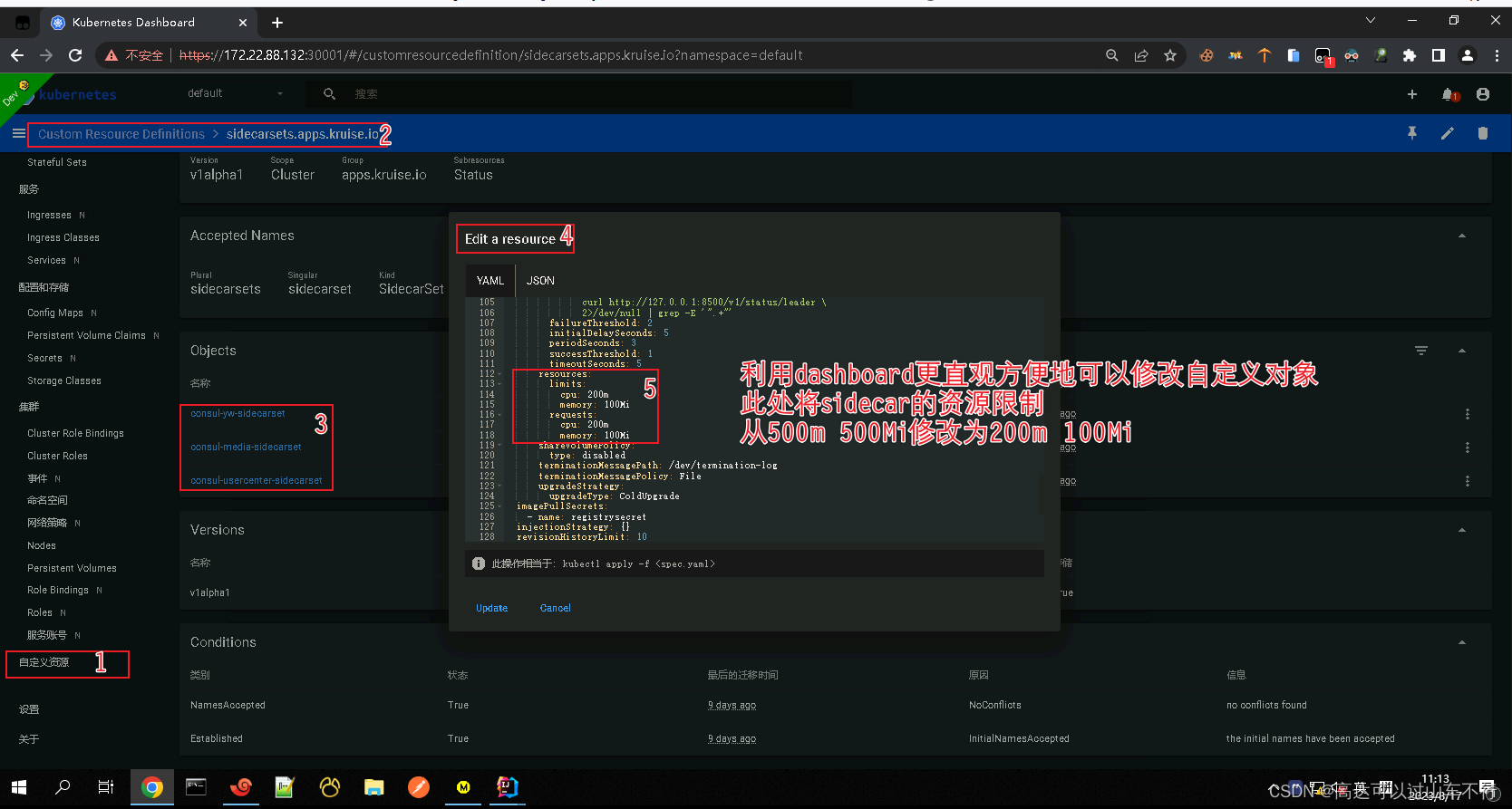
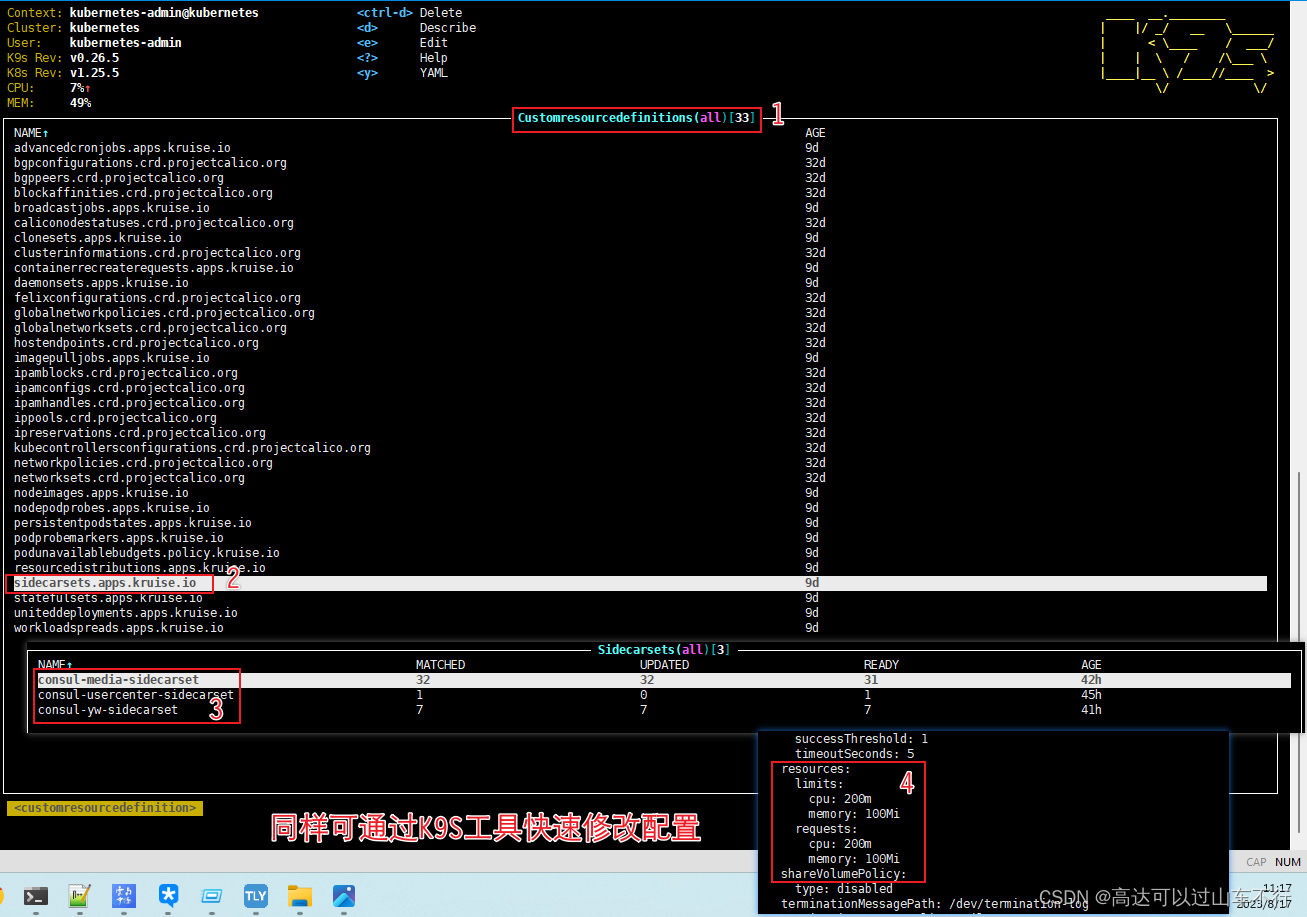
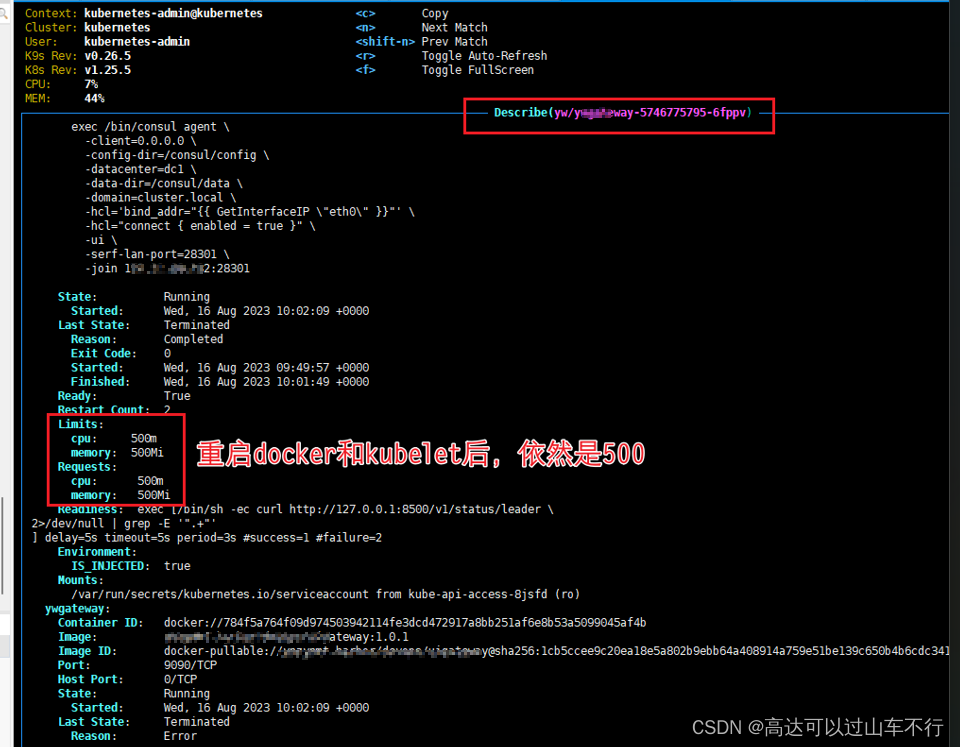
注意:上述修改的配置需要重启Pod后才能生效。重启docker服务、重启kubelet服务并不会让sidercar容器配置生效。
解决的验证
完成上述操作后验证了以下结果:
- 仅新增了limitrange配置后,新部署的Pod可以成功running。但部署更多Pod时,仍然出现了相同问题(原因是sidecar容器划分了过多资源)。
- 在limitrange基础上修改了sidecar容器配置后,新部署的Pod不再pending,可成功running。此时重启前后的Pod,其中用到的sidecar容器的计算资源从500m 500Mi变成了200m 100Mi。
其它相关截图



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









