






这篇文章讲述:
1.LlamaIndex 的特点和基本用法
2. 了解 LlamaIndex 内置的工具
3. 如何用好 SDK 简化基于 LLM 的应用开发
1、大语言模型开发框架的价值是什么?
SDK:Software Development Kit,它是一组软件工具和资源的集合,旨在帮助开发者创建、测试、部署和维护应用程序或软件。
所有开发框架(SDK)的核心价值,都是降低开发、维护成本。
大语言模型开发框架的价值,是让开发者可以更方便地开发基于大语言模型的应用。主要提供两类帮助:
- 第三方能力抽象。比如 LLM、向量数据库、搜索接口等
- 常用工具、方案封装
- 底层实现封装。比如流式接口、超时重连、异步与并行等
好的开发框架,需要具备以下特点:
- 可靠性、鲁棒性高
- 可维护性高
- 可扩展性高
- 学习成本低
举些通俗的例子:
- 与外部功能解依赖
- 比如可以随意更换 LLM 而不用大量重构代码
- 更换三方工具也同理
- 经常变的部分要在外部维护而不是放在代码里
- 比如 Prompt 模板
- 各种环境下都适用
- 比如线程安全
- 方便调试和测试
- 至少要能感觉到用了比不用方便吧
- 合法的输入不会引发框架内部的报错
划重点:选对了框架,事半功倍;反之,事倍功半。
什么是 SDK? 什么是 SDK?- SDK 详解 - AWS
SDK 和 API 的区别是什么? https://aws.amazon.com/cn/compare/the-difference-between-sdk-and-api/
!pip install --upgrade llama-indexfrom llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()response = query_engine.query("llama2有多少参数")
print(response)2、LlamaIndex 介绍
「 LlamaIndex is a framework for building context-augmented LLM applications. Context augmentation refers to any use case that applies LLMs on top of your private or domain-specific data. 」
LlamaIndex 是一个为开发「上下文增强」的大语言模型应用的框架(也就是 SDK)。上下文增强,泛指任何在私有或特定领域数据基础上应用大语言模型的情况。例如: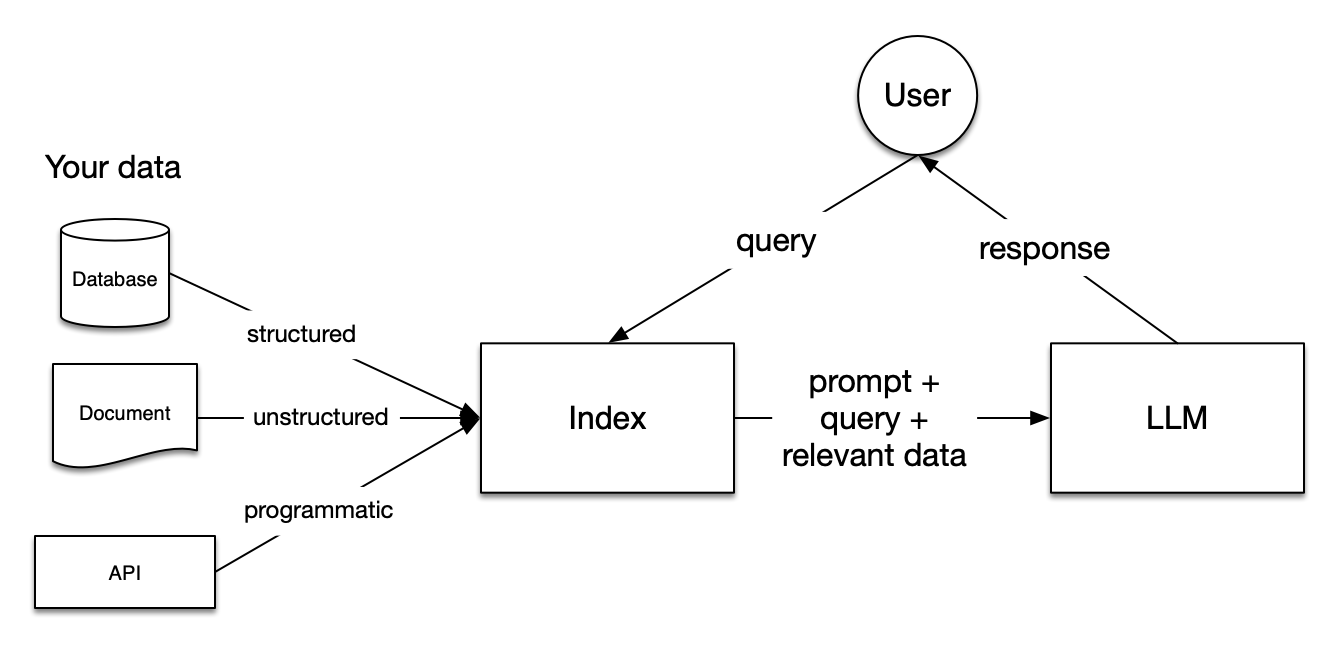
-
Question-Answering Chatbots (也就是 RAG)
-
Document Understanding and Extraction (文档理解与信息抽取)
-
Autonomous Agents that can perform research and take actions (智能体应用)
LlamaIndex 有 Python 和 Typescript 两个版本,Python 版的文档相对更完善。
-
Python 文档地址:LlamaIndex - LlamaIndex
-
Python API 接口文档:API Reference - LlamaIndex
-
TS 文档地址:StackBlitz
-
TS API 接口文档:https://ts.llamaindex.ai/api/
LlamaIndex 是一个开源框架,Github 链接:LlamaIndex · GitHub
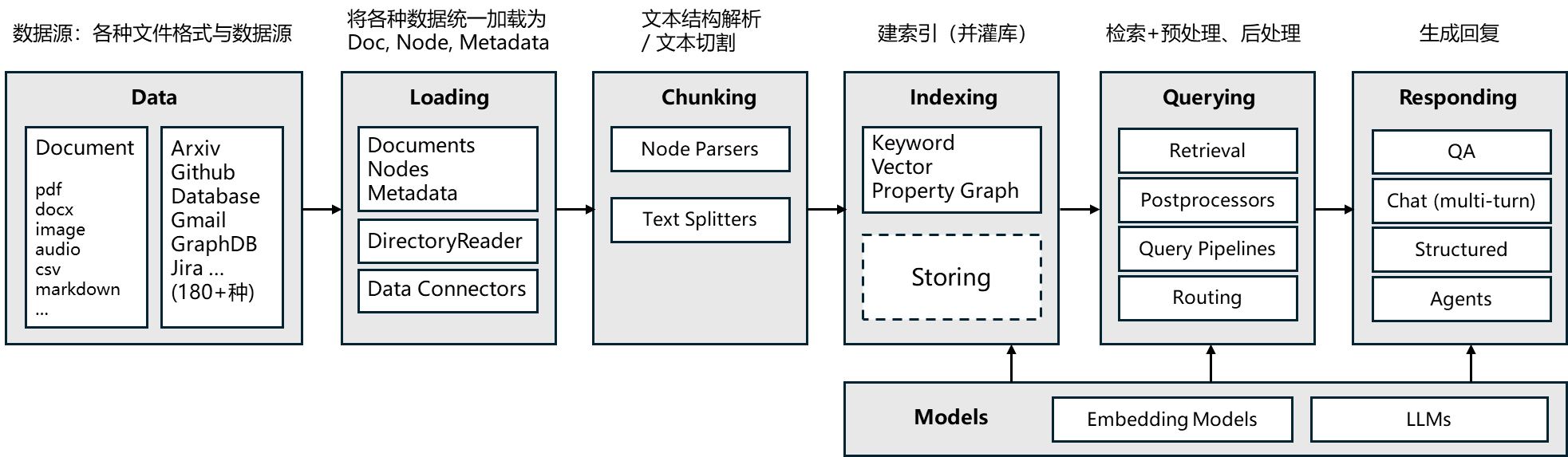
LlamaIndex 的核心模块
安装 LlamaIndex
pip install llama-indexTypescript
# 通过 npm 安装
npm install llamaindex
# 通过 yarn 安装
yarn add llamaindex
# 通过 pnpm 安装
pnpm add llamaindex3、数据加载(Loading)
3.1、加载本地数据
SimpleDirectoryReader 是一个简单的本地文件加载器。它会遍历指定目录,并根据文件扩展名自动加载文件(文本内容)。
支持的文件类型:
.csv- comma-separated values.docx- Microsoft Word.epub- EPUB ebook format.hwp- Hangul Word Processor.ipynb- Jupyter Notebook.jpeg,.jpg- JPEG image.mbox- MBOX email archive.md- Markdown.mp3,.mp4- audio and video.pdf- Portable Document Format.png- Portable Network Graphics.ppt,.pptm,.pptx- Microsoft PowerPoint
import json
from pydantic.v1 import BaseModel
def show_json(data):
"""用于展示json数据"""
if isinstance(data, str):
obj = json.loads(data)
print(json.dumps(obj, indent=4))
elif isinstance(data, dict) or isinstance(data, list):
print(json.dumps(data, indent=4))
elif issubclass(type(data), BaseModel):
print(json.dumps(data.dict(), indent=4, ensure_ascii=False))
def show_list_obj(data):
"""用于展示一组对象"""
if isinstance(data, list):
for item in data:
show_json(item)
else:
raise ValueError("Input is not a list")from llama_index.core import SimpleDirectoryReader
reader = SimpleDirectoryReader(
input_dir="./data", # 目标目录
recursive=False, # 是否递归遍历子目录
required_exts=[".pdf"] # (可选)只读取指定后缀的文件
)
documents = reader.load_data()show_json(documents[0])
print(documents[0].text)注意:对图像、视频、语音类文件,默认不会自动提取其中文字。如需提取,参考下面介绍的 Data Connectors。
默认的 PDFReader 效果并不理想,我们可以更换文件加载器
# !pip install pymupdfrom llama_index.core import SimpleDirectoryReader
from llama_index.readers.file import PyMuPDFReader
reader = SimpleDirectoryReader(
input_dir="./data", # 目标目录
recursive=False, # 是否递归遍历子目录
required_exts=[".pdf"], # (可选)只读取指定后缀的文件
file_extractor={".pdf": PyMuPDFReader()} # 指定特定的文件加载器
)
documents = reader.load_data()
print(documents[0].text)更多的 PDF 加载器还有 SmartPDFLoader 和 LlamaParse, 二者都提供了更丰富的解析能力,包括解析章节与段落结构等。但不是 100%准确,偶有文字丢失或错位情况,建议根据自身需求详细测试评估。
3.2、Data Connectors
用于处理更丰富的数据类型,并将其读取为 Document 的形式(text + metadata)。
例如:加载一个飞书文档。(飞书文档 API 访问权限申请,请参考此说明文档)
# !pip install llama-index-readers-feishu-docsfrom llama_index.readers.feishu_docs import FeishuDocsReader
# 见说明文档
app_id = ""
app_secret = ""
# https://agiclass.feishu.cn/docx/FULadzkWmovlfkxSgLPcE4oWnPf
# 链接最后的 "FULadzkWmovlfkxSgLPcE4oWnPf" 为文档 ID
doc_ids = ["FULadzkWmovlfkxSgLPcE4oWnPf"]
# 定义飞书文档加载器
loader = FeishuDocsReader(app_id, app_secret)
# 加载文档
documents = loader.load_data(document_ids=doc_ids)
# 显示前1000字符
print(documents[0].text[:1000])更多 Data Connectors
4、文本切分与解析(Chunking)
为方便检索,我们通常把 Document 切分为 Node。
在 LlamaIndex 中,Node 被定义为一个文本的「chunk」。
4.1、使用 TextSplitters 对文本做切分
例如:TokenTextSplitter 按指定 token 数切分文本
from llama_index.core import Document
from llama_index.core.node_parser import TokenTextSplitter
node_parser = TokenTextSplitter(
chunk_size=100, # 每个 chunk 的最大长度
chunk_overlap=50 # chunk 之间重叠长度
)
nodes = node_parser.get_nodes_from_documents(
documents, show_progress=False
)show_json(nodes[0])
show_json(nodes[1])LlamaIndex 提供了丰富的 TextSplitter,例如:
- SentenceSplitter:在切分指定长度的 chunk 同时尽量保证句子边界不被切断;
- CodeSplitter:根据 AST(编译器的抽象句法树)切分代码,保证代码功能片段完整;
- SemanticSplitterNodeParser:根据语义相关性对将文本切分为片段。
4.2、使用 NodeParsers 对有结构的文档做解析
例如:MarkdownNodeParser解析 markdown 文档
from llama_index.readers.file import FlatReader
from llama_index.core.node_parser import MarkdownNodeParser
from pathlib import Path
md_docs = FlatReader().load_data(Path("./data/ChatALL.md"))
parser = MarkdownNodeParser()
nodes = parser.get_nodes_from_documents(md_docs)show_json(nodes[2])
show_json(nodes[3])5、索引(Indexing)与检索(Retrieval)
基础概念:在「检索」相关的上下文中,「索引」即index, 通常是指为了实现快速检索而设计的特定「数据结构」。
索引的具体原理与实现可以参考这两个来了解,感兴趣的同学可以参考:传统索引、向量索引
5.1、向量检索
SimpleVectorStore直接在内存中构建一个 Vector Store 并建索引
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.node_parser import TokenTextSplitter
from llama_index.readers.file import PyMuPDFReader
# 加载 pdf 文档
documents = SimpleDirectoryReader(
"./data",
required_exts=[".pdf"],
file_extractor={".pdf": PyMuPDFReader()}
).load_data()
# 定义 Node Parser
node_parser = TokenTextSplitter(chunk_size=300, chunk_overlap=100)
# 切分文档
nodes = node_parser.get_nodes_from_documents(documents)
# 构建 index
index = VectorStoreIndex(nodes)
# 获取 retriever
vector_retriever = index.as_retriever(
similarity_top_k=2 # 返回前两个结果
)
# 检索
results = vector_retriever.retrieve("Llama2有多少参数")
show_list_obj(results)2.使用自定义的 Vector Store,以 Chroma 为例:
# !pip install llama-index-vector-stores-chromaimport os
if os.environ.get('CUR_ENV_IS_STUDENT','false')=='true':
__import__('pysqlite3')
import sys
sys.modules['sqlite3']= sys.modules.pop('pysqlite3')import chromadb
from chromadb.config import Settings
# 创建 Chroma Client
# EphemeralClient 在内存创建;如果需要存盘,可以使用 PersistentClient
chroma_client = chromadb.EphemeralClient(settings=Settings(allow_reset=True))from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import VectorStoreIndex
from llama_index.core import StorageContext
chroma_client.reset() # 为演示方便,实际不用每次 reset
chroma_collection = chroma_client.create_collection("demo")
# 创建 Vector Store
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
# Storage Context 是 Vector Store 的存储容器,用于存储文本、index、向量等数据
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 创建 index:通过 Storage Context 关联到自定义的 Vector Store
index = VectorStoreIndex(nodes, storage_context=storage_context)
# 获取 retriever
vector_retriever = index.as_retriever(similarity_top_k=2)
# 检索
results = vector_retriever.retrieve("Llama2有多少参数")
show_list_obj(results)5.2、更多索引与检索方式
LlamaIndex 内置了丰富的检索机制,例如:
-
关键字检索
- BM25Retriever:基于 tokenizer 实现的 BM25 经典检索算法
- KeywordTableGPTRetriever:使用 GPT 提取检索关键字
- KeywordTableSimpleRetriever:使用正则表达式提取检索关键字
- KeywordTableRAKERetriever:使用RAKE算法提取检索关键字(有语言限制)
-
RAG-Fusion QueryFusionRetriever
-
还支持 KnowledgeGraph、SQL、Text-to-SQL 等等
5.3、Ingestion Pipeline 自定义数据处理流程
LlamaIndex 通过 Transformations 定义一个数据(Documents)的多步处理的流程(Pipeline)。 这个 Pipeline 的一个显著特点是,它的每个子步骤是可以缓存(cache)的,即如果该子步骤的输入与处理方法不变,重复调用时会直接从缓存中获取结果,而无需重新执行该子步骤,这样即节省时间也会节省 token (如果子步骤涉及大模型调用)。
import time
class Timer:
def __enter__(self):
self.start = time.time()
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.end = time.time()
self.interval = self.end - self.start
print(f"耗时 {self.interval*1000} ms")rom llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import StorageContext
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.extractors import TitleExtractor
from llama_index.core.ingestion import IngestionPipeline
from llama_index.core import VectorStoreIndex
from llama_index.readers.file import PyMuPDFReader
import nest_asyncio
nest_asyncio.apply() # 只在Jupyter笔记环境中需要此操作,否则会报错
chroma_client.reset() # 为演示方便,实际不用每次 reset
chroma_collection = chroma_client.create_collection("ingestion_demo")
# 创建 Vector Store
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=300, chunk_overlap=100), # 按句子切分
TitleExtractor(), # 利用 LLM 对文本生成标题
OpenAIEmbedding(), # 将文本向量化
],
vector_store=vector_store,
)
documents = SimpleDirectoryReader(
"./data",
required_exts=[".pdf"],
file_extractor={".pdf": PyMuPDFReader()}
).load_data()
# 计时
with Timer():
# Ingest directly into a vector db
pipeline.run(documents=documents)
# 创建索引
index = VectorStoreIndex.from_vector_store(vector_store)
# 获取 retriever
vector_retriever = index.as_retriever(similarity_top_k=1)
# 检索
results = vector_retriever.retrieve("Llama2有多少参数")
show_list_obj(results[:1])本地保存 IngestionPipeline 的缓存
pipeline.persist("./pipeline_storage")new_pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=300, chunk_overlap=100),
TitleExtractor(),
OpenAIEmbedding()
],
)
# 加载缓存
new_pipeline.load("./pipeline_storage")
with Timer():
nodes = new_pipeline.run(documents=documents)此外,也可以用远程的 Redis 或 MongoDB 等存储 IngestionPipeline 的缓存,具体参考官方文档:Remote Cache Management。
IngestionPipeline 也支持异步和并发调用,请参考官方文档:Async Support、Parallel Processing。
5.4、检索后处理
LlamaIndex 的 Node Postprocessors 提供了一系列检索后处理模块。
例如:我们可以用不同模型对检索后的 Nodes 做重排序
# 获取 retriever
vector_retriever = index.as_retriever(similarity_top_k=5)
# 检索
nodes = vector_retriever.retrieve("Llama2 有商用许可吗?")
for i, node in enumerate(nodes):
print(f"[{i}] {node.text}\n") 以下代码不要在服务器上运行,会死机!
可下载下方代码 rag_demo.py 的完整例子在自己本地运行。
import chromadb
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.ingestion import IngestionPipeline
from llama_index.readers.file import PyMuPDFReader
from llama_index.core import Settings
from llama_index.core import StorageContext
from llama_index.core.postprocessor import SentenceTransformerRerank
from llama_index.core.retrievers import QueryFusionRetriever
# from llama_index.retrievers.bm25 import BM25Retriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.chat_engine import CondenseQuestionChatEngine
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
import nest_asyncio
import time
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
nest_asyncio.apply() # 只在Jupyter笔记环境中需要此操作,否则会报错
# 创建 ChromaDB 向量数据库,并持久化到本地
chroma_client = chromadb.PersistentClient(path="./chroma_db")
# 指定全局llm与embedding模型
Settings.llm = OpenAI(temperature=0, model="gpt-4o")
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small", dimensions=512)
splitter = SentenceSplitter(chunk_size=300, chunk_overlap=100)
# 加载 pdf 文档
documents = SimpleDirectoryReader("./data", file_extractor={".pdf": PyMuPDFReader()}).load_data()
# 切分nodes
nodes = splitter.get_nodes_from_documents(documents)
# 新建 collection
collection_name = hex(int(time.time()))
chroma_collection = chroma_client.get_or_create_collection(collection_name)
# 创建 Vector Store
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
# 指定 Vector Store 用于 index
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex(
nodes, storage_context=storage_context
)
# bm25_retriever = BM25Retriever.from_defaults(nodes=nodes)
# 检索后排序模型
reranker = SentenceTransformerRerank(
model="BAAI/bge-reranker-large", top_n=2
)
# RAG Fusion
fusion_retriever = QueryFusionRetriever(
[
index.as_retriever(),
# bm25_retriever
],
similarity_top_k=5,
num_queries=3, # 生成 query 数
use_async=True,
# query_gen_prompt="...", # 可以自定义 query 生成的 prompt 模板
)
# 构建单轮 query engine
query_engine = RetrieverQueryEngine.from_args(
fusion_retriever,
node_postprocessors=[reranker]
)
# 对话引擎
chat_engine = CondenseQuestionChatEngine.from_defaults(
query_engine=query_engine,
# condense_question_prompt=... # 可以自定义 chat message prompt 模板
)
while True:
question=input("User:")
if question.strip() == "":
break
response = chat_engine.chat(question)
print(f"AI: {response}")
from llama_index.core.postprocessor import SentenceTransformerRerank
# 检索后排序模型
postprocessor = SentenceTransformerRerank(
model="BAAI/bge-reranker-large", top_n=2
)
nodes = postprocessor.postprocess_nodes(nodes, query_str="Llama2 有商用许可吗?")
for i, node in enumerate(nodes):
print(f"[{i}] {node.text}")更多的 Rerank 及其它后处理方法,参考官方文档:Node Postprocessor Modules
6、生成回复(QA & Chat)
6.1、单轮问答(Query Engine)
qa_engine = index.as_query_engine()
response = qa_engine.query("Llama2 有多少参数?")
print(response)流式输出
qa_engine = index.as_query_engine(streaming=True)
response = qa_engine.query("Llama2 有多少参数?")
response.print_response_stream()6.2、多轮对话(Chat Engine)
chat_engine = index.as_chat_engine()
response = chat_engine.chat("Llama2 有多少参数?")
print(response)response = chat_engine.chat("How many at most?")
print(response)流式输出
chat_engine = index.as_chat_engine()
streaming_response = chat_engine.stream_chat("Llama 2有多少参数?")
# streaming_response.print_response_stream()
for token in streaming_response.response_gen:
print(token, end="", flush=True)7、底层接口:Prompt、LLM 与 Embedding
7.1、Prompt 模板
PromptTemplate 定义提示词模板
from llama_index.core import PromptTemplate
prompt = PromptTemplate("写一个关于{topic}的笑话")
prompt.format(topic="小明") ChatPromptTemplate 定义多轮消息模板
from llama_index.core.llms import ChatMessage, MessageRole
from llama_index.core import ChatPromptTemplate
chat_text_qa_msgs = [
ChatMessage(
role=MessageRole.SYSTEM,
content="你叫{name},你必须根据用户提供的上下文回答问题。",
),
ChatMessage(
role=MessageRole.USER,
content=(
"已知上下文:\n" \
"{context}\n\n" \
"问题:{question}"
)
),
]
text_qa_template = ChatPromptTemplate(chat_text_qa_msgs)
print(
text_qa_template.format(
name="瓜瓜",
context="这是一个测试",
question="这是什么"
)
)7.2、语言模型
from llama_index.llms.openai import OpenAI
llm = OpenAI(temperature=0, model="gpt-4o")response = llm.complete(prompt.format(topic="小明"))
print(response.text)response = llm.complete(
text_qa_template.format(
name="西西",
context="这是一个测试",
question="你是谁,我们在干嘛"
)
)
print(response.text)设置全局使用的语言模型
from llama_index.core import Settings
Settings.llm = OpenAI(temperature=0, model="gpt-4o")除 OpenAI 外,LlamaIndex 已集成多个大语言模型,包括云服务 API 和本地部署 API,详见官方文档:Available LLM integrations
7.3、Embedding 模型
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core import Settings
# 全局设定
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small", dimensions=512)LlamaIndex 同样集成了多种 Embedding 模型,包括云服务 API 和开源模型(HuggingFace)等,详见官方文档。
8、基于 LlamaIndex 实现一个功能较完整的 RAG 系统
功能要求:
加载指定目录的文件
支持 RAG-Fusion
使用 ChromaDB 向量数据库,并持久化到本地
支持检索后排序
支持多轮对话
以下代码不要在服务器上运行,会死机!可下载下方 rag_demo.py 在自己本地运行。
import chromadb
# 创建 ChromaDB 向量数据库,并持久化到本地
chroma_client = chromadb.PersistentClient(path="./chroma_db")from llama_index.core import VectorStoreIndex, KeywordTableIndex, SimpleDirectoryReader
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.ingestion import IngestionPipeline
from llama_index.readers.file import PyMuPDFReader
from llama_index.core import Settings
from llama_index.core import StorageContext
from llama_index.core.postprocessor import SentenceTransformerRerank
from llama_index.core.retrievers import QueryFusionRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.chat_engine import CondenseQuestionChatEngine
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
import time
import nest_asyncio
nest_asyncio.apply() # 只在Jupyter笔记环境中需要此操作,否则会报错
# 1. 指定全局llm与embedding模型
Settings.llm = OpenAI(temperature=0, model="gpt-4o")
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small", dimensions=512)
# 2. 指定全局文档处理的 Ingestion Pipeline
Settings.transformations = [SentenceSplitter(chunk_size=300, chunk_overlap=100)]
# 3. 加载本地文档
documents = SimpleDirectoryReader("./data", file_extractor={".pdf": PyMuPDFReader()}).load_data()
# 4. 新建 collection
collection_name = hex(int(time.time()))
chroma_collection = chroma_client.get_or_create_collection(collection_name)
# 5. 创建 Vector Store
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
# 6. 指定 Vector Store 的 Storage 用于 index
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)
# 7. 定义检索后排序模型
reranker = SentenceTransformerRerank(
model="BAAI/bge-reranker-large", top_n=2
)
# 8. 定义 RAG Fusion 检索器
fusion_retriever = QueryFusionRetriever(
[index.as_retriever()],
similarity_top_k=5, # 检索召回 top k 结果
num_queries=3, # 生成 query 数
use_async=True,
# query_gen_prompt="...", # 可以自定义 query 生成的 prompt 模板
)
# 9. 构建单轮 query engine
query_engine = RetrieverQueryEngine.from_args(
fusion_retriever,
node_postprocessors=[reranker]
)
# 10. 对话引擎
chat_engine = CondenseQuestionChatEngine.from_defaults(
query_engine=query_engine,
# condense_question_prompt=... # 可以自定义 chat message prompt 模板
)while True:
question=input("User:")
if question.strip() == "":
break
response = chat_engine.chat(question)
print(f"AI: {response}")LlamaIndex 的更多功能
- 智能体(Agent)开发框架:Agents - LlamaIndex
- RAG 的评测:Evaluating - LlamaIndex
- 过程监控:Observability - LlamaIndex
以上内容涉及较多背景知识,暂时不在本篇展开,相关知识有机会的话会在后面文章中逐一详细讲解。
此外,LlamaIndex 针对生产级的 RAG 系统中遇到的各个方面的细节问题,总结了很多高端技巧(Advanced Topics),对实战很有参考价值,非常推荐有能力的人阅读。

















 2104
2104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









