







图的数据结构
https://blog.csdn.net/weixin_43093501/article/details/89840219
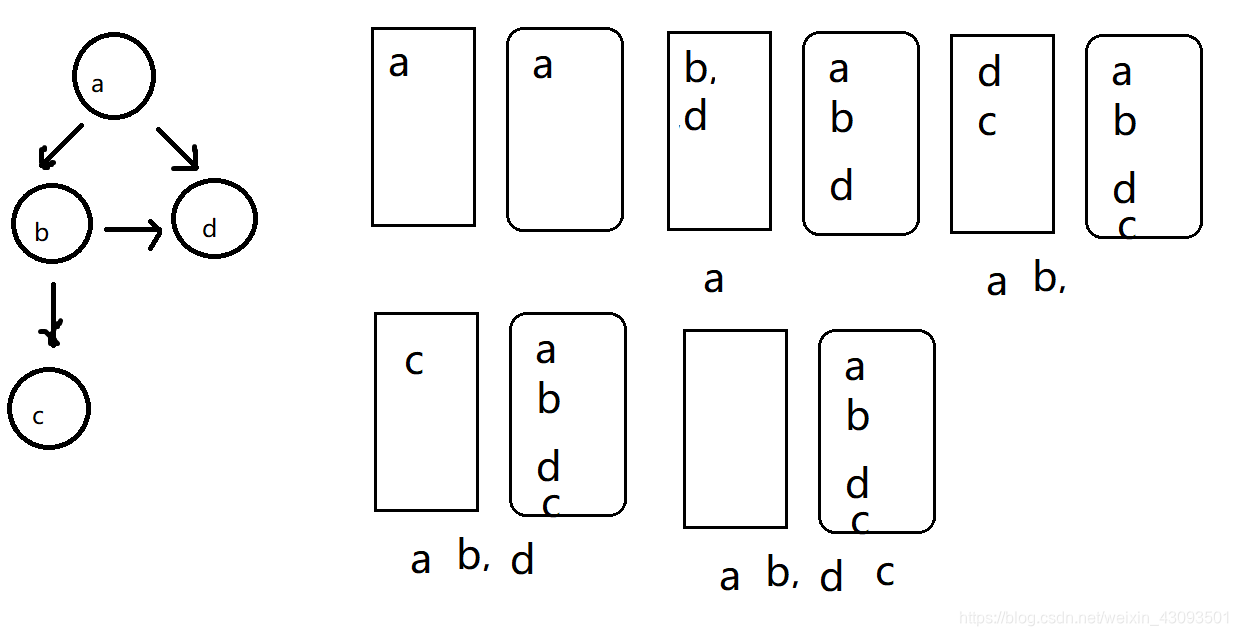
广度优先遍历
思路
准备:队列、set:查重
1.将图的起始节点添加到队列中,同时加到set中
2.只要队列中有元素,就执行代码
3.弹出队列中的元素,并打印,
4.将该元素的邻居节点集合全部加入到队列中(重复的不加)
代码
public static void bfs(Node node) {
if (node == null) {
return;
}
Queue<Node> queue = new LinkedList<>();
HashSet<Node> map = new HashSet<>();
queue.add(node);
map.add(node);
while (!queue.isEmpty()) {
Node cur = queue.poll();
System.out.println(cur.value);
for (Node next : cur.nexts) {
if (!map.contains(next)) {
map.add(next);
queue.add(next);
}
}
}
}
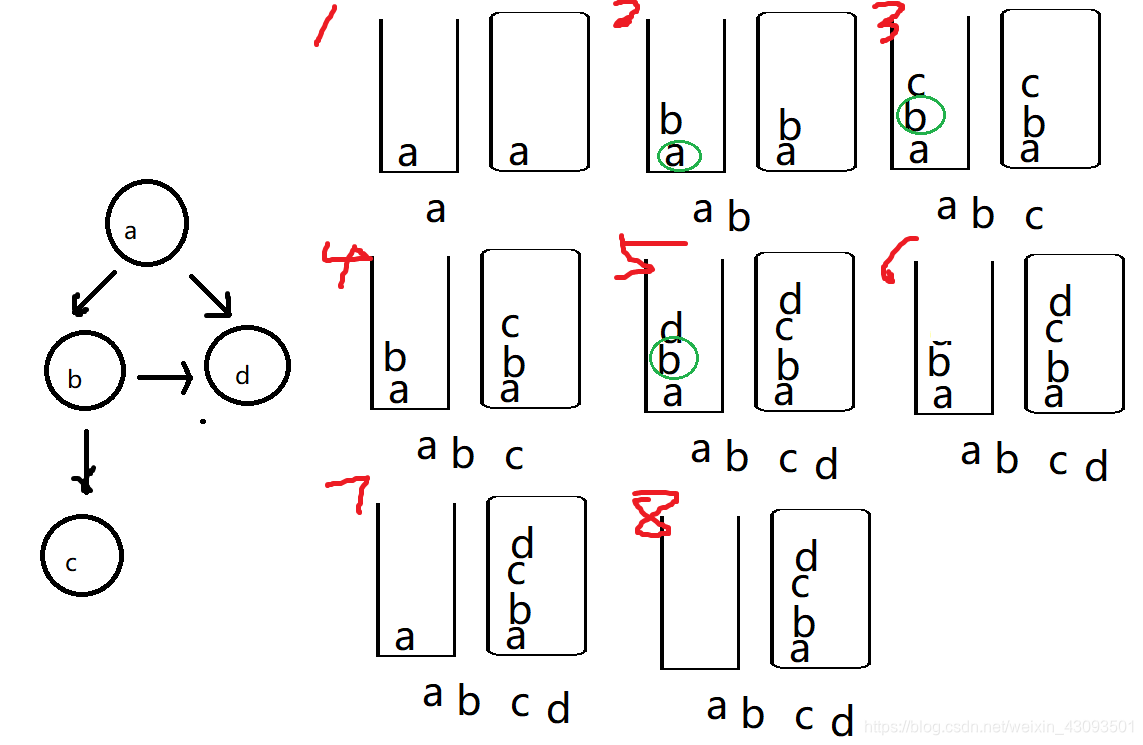
深度优先遍历
思路
准备:栈,set(查重)
1.将图的起始节点添加到栈中,同时加到set中
2.只要队列中有元素,就执行代码
3.弹出栈顶元素
4.遍历元素的邻居集合
5.如果邻居节点不重复(不在set中),则:
- 将刚弹出的栈顶元素加入栈中,
- 邻居节点加入栈中,
- 邻居节点加入set中,
- 打印邻居节点。
代码
public static void dfs(Node node) {
if (node == null) {
return;
}
Stack<Node> stack = new Stack<>();
HashSet<Node> set = new HashSet<>();
stack.add(node);
set.add(node);
System.out.println(node.value);
while (!stack.isEmpty()) {
Node cur = stack.pop();
for (Node next : cur.nexts) {
if (!set.contains(next)) {
stack.push(cur);
stack.push(next);
set.add(next);
System.out.println(next.value);
break;
}
}
}
}














 197
197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









