







 本文详细介绍了如何使用EXPLAIN和EXPLAIN ANALYZE语句观察和优化SQL查询计划,解释了查询优化器的工作原理,以及如何解读EXPLAIN输出的查询计划和代价估计。
本文详细介绍了如何使用EXPLAIN和EXPLAIN ANALYZE语句观察和优化SQL查询计划,解释了查询优化器的工作原理,以及如何解读EXPLAIN输出的查询计划和代价估计。
通过explain观察执行计划,从而确定如何优化SQL
查询优化器使用数据库的数据统计信息来选择具有最小总代价的查询计划,查询代价通过磁盘I/O取得的磁盘页面数作为单位来度量。 可以使用EXPLAIN和EXPLAIN ANALYZE语句发现和改进查询计划。
EXPLAIN的语法如下:
1、EXPLAIN [ ANALYZE ] [ VERBOSE ] statement
- ANALYZE:执行命令并显示实际运行时间。
- VERBOSE:显示规划树完整的内部表现形式,而不仅是一个摘要。通常,这个选项只是在特殊的调试过程中有用。VERBOSE输出是否打印工整的,具体取决于配置参数 explain_pretty_print 的值。
- statement:查询执行计划的 SQL 语句,可以是任何
select、insert、update、delete、values、execute、declare 语句。
EXPLAIN展示查询优化器对该查询计划估计的代价,但是不执行该查询。例如:
EXPLAIN SELECT * FROM test WHERE id=2;

EXPLAIN ANALYZE不仅会显示查询计划,还会实际运行语句。EXPLAIN ANALYZE会丢掉任何来自SELECT语句的输出,但是该语句中的其他操作会被执行(例如INSERT、UPDATE或者DELETE)。要在DML语句上使用EXPLAIN ANALYZE却不让该命令影响数据,可以明确地把EXPLAIN ANALYZE用在一个事务中:
(BEGIN; EXPLAIN ANALYZE ...; ROLLBACK;)。
EXPLAIN ANALYZE运行语句后除了显示计划外,还有下列额外的信息:
1、运行该查询消耗的总时间(以毫秒计) 计划节点操作中涉及的工作者(Segment)数量
2、操作中产生最多行的Segment返回的最大行数(及其Segment ID) 操作所使用的内存
3、从产生最多行的Segment中检索到第一行所需的时间(以毫秒计),以及从该Segment中检索所有行花费的总时间。
例如:
EXPLAIN ANALYZE SELECT * FROM test WHERE id=2;
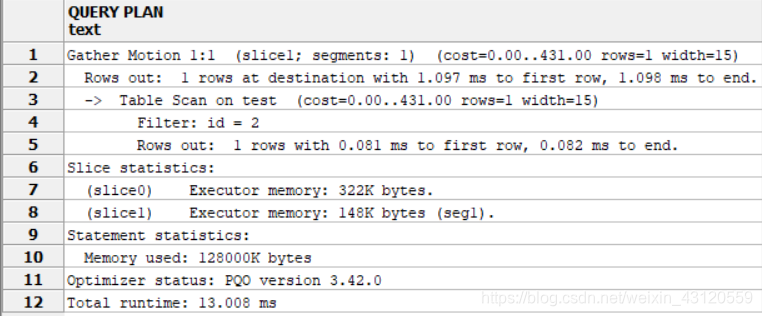
阅读EXPLAIN输出
查询计划类似于一棵有节点的树,执行和阅读的顺序是自底而上。计划中的每个节点表示一个操作,例如表扫描、表连接、聚集或者排序。阅读的顺序是从底向上:每个节点会把结果输出给直接在它上面的节点。一个计划中的底层节点通常是表扫描操作:顺序扫描表、通过索引或者位图索引扫描表等。如果该查询要求那些行上的连接、聚集、排序或者其他操作,就会有额外的节点在扫描节点上面负责执行这些操作。最顶层的计划节点通常是数据库的移动(MOTION)节点:重分布(REDISTRIBUTE)、广播(BROADCAST)或者收集(GATHER)节点。这些操作在查询处理时在实例节点之间移动数据。
EXPLAIN的输出对于查询计划中的每个节点都显示为一行并显示该节点类型和下面的执行的代价估计:
- cost:以磁盘页面获取为单位度量。1.0等于一次顺序磁盘页面读取。第一个估计是得到第一行的启动代价,第二个估计是得到所有行的总代价。
- rows:这个计划节点输出的总行数。这个数字根据条件的过滤因子会小于被该计划节点处理或者扫描的行数。最顶层节点的是估算的返回、更新或者删除的行数。
- width:这个计划节点输出的所有行的总字节数。
需要注意以下两点:
- 一个节点的代价包括其子节点的代价。最顶层计划节点有对于该计划估计的总执行代价。这是优化器估算出来的最小的数字。
- 代价只反映了在数据库中执行的时间,并没有计算在数据库执行之外的时间,例如将结果行传送到客户端花费的时间。
rows:根据统计信息估计SQL返回结果集的行数
width:返回的结果集的每一行的长度,这个长度值是根据pg_statistic表中的统计信息来计算的。
EXPLAIN举例
下面的例子描述了如何阅读一个查询的EXPLAIN查询代价:
EXPLAIN SELECT * FROM names WHERE name = 'Joelle';
QUERY PLAN--------------------------Gather Motion 4:1 (slice1) (cost=0.00…20.88 rows=1 width=13)
-> Seq Scan on ‘names’ (cost=0.00…20.88 rows=1 width=13)
Filter: name::text ~~ ‘Joelle’::text
查询优化器会顺序扫描names表,对每一行检查WHERE语句中的filter条件,只输出满足该条件的行。 扫描操作的结果被传递给一个Gather Motion操作。Gather Motion是Segment把所有行发送给Master节点。在这个例子中,有4个Segment节点会并行执行,并向Master节点发送数据。这个计划估计的启动代价是00.00(没有代价)而总代价是20.88次磁盘页面获取。优化器估计这个查询将返回一行数据。
EXPLAIN ANALYZE除了显示执行计划还会运行语句。EXPLAIN ANALYZE计划会把实际执行代价和优化器的估计一起显示,同时显示额外的下列信息:
- 查询执行的总运行时间(以毫秒为单位)。
- 查询计划每个Slice使用的内存,以及为整个查询语句保留的内存。
- 计划节点操作中涉及的Segment节点数量,其中只会统计返回行的Segment。
- 操作产生最多行的Segment节点返回的行最大数量。如果多个Segment节点产生了相等的行数,EXPLAIN ANALYZE会显示那个用了最长结束时间的Segment节点。
- 为一个操作产生最多行的Segment节点的ID。
- 相关操作使用的内存量(work_mem)。如果work_mem不足以在内存中执行该操作,计划会显示溢出到磁盘的数据量最少的Segment的溢出数据量。
例如:
Work_mem used: 64K bytes avg, 64K bytes max (seg0). Work_mem wanted:
90K bytes avg, 90K byes max (seg0) to lessen workfile I/O affecting 2
workers.
产生最多行的Segment节点检索到第一行的时间(以毫秒为单位)以及该Segment节点检索到所有行花掉的时间。
下面的例子用同一个查询描述了如何阅读一个EXPLAIN ANALYZE查询计划。这个计划中粗体部分展示了每一个计划节点的实际计时和返回行,以及整个查询的内存和时间统计信息。
EXPLAIN ANALYZE SELECT * FROM names WHERE name = 'Joelle';
QUERY PLAN------------------------------------------------------------ Gather Motion 2:1 (slice1; segments: 2) (cost=0.00…20.88 rows=1 width=13)
Rows out: 1 rows at destination with 0.305 ms to first row, 0.537 ms
to end, start offset by 0.289 ms.
-> Seq Scan on names (cost=0.00…20.88 rows=1 width=13) Rows out: Avg 1 rows x 2 workers. Max 1 rows (seg0) with 0.255 ms to first
row, 0.486 ms to end, start offset by 0.968 ms.
Filter: name = ‘Joelle’::text Slice statistics:
(slice0) Executor memory: 135K bytes.
(slice1) Executor memory: 151K bytes avg x 2 workers, 151K bytes max (seg0).Statement statistics: Memory used: 128000K bytes Total runtime: 22.548
ms

















 3654
3654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









