






MySQL语句小全
记录一些sql语句,为了偷懒,没有特意建表结,所以不要说这样写不合理啥的,写这文章单纯只是为了记录用法。
商品表结构:自增id,class_id(商品分类),product_name,product_price,user_id(用户id),…
文章目录
1. AS 修改查询结果列标题
select id, product_name as '商品名', product_price as '价格', status from product;

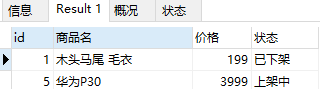
2. CASE 替换查询结果数据(1)
-- 替换查询结果数据
select id, product_name as '商品名', product_price as '价格',
CASE status
WHEN 0 THEN '上架中'
WHEN 1 THEN '已下架'
ELSE '异常'
END as 状态
from product
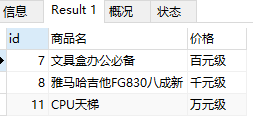
2. CASE 替换查询结果数据(2)
–适用于显示分数段ABCD或者是否合格等场景
select id, product_name as '商品名',
CASE
WHEN product_price < 1000 THEN '百元级'
WHEN product_price > 1000 and product_price < 10000 THEN '千元级'
ELSE '万元级'
END as '价格'
from product
where id in (7,8,11)
3. DISTINCT 消除结果集中的重复行
对于关系型数据库来说, 表中的每一行都必须是不相同的,但当只选择表中的某些字段时,就可能会出现重复行。
-- 不写all关键字,默认也会是all
select all class_id, user_id from product ORDER BY class_id ASC
-- 消除结果集中的重复行
select DISTINCT class_id, user_id from product ORDER BY class_id ASC
-- 查询共有几个用户出售了闲置商品
select count(DISTINCT user_id)
from product

4. limit 限制结果集的返回行数:
按照价格的倒序排序 从第n=0条开始取出前m=3条(默认是倒叙排序)
select id, product_price from product
order by product_price desc limit 0,3
4. LIKE 字符匹配(模糊查询)
%:百分号代表任意长度的字符串,_:下划线代表任意一个字符(强调是长度为1的单个字符)
select product_name, product_price
from product
where product_name like '%车%'
-- like '_小%' --查询表中第二个字为小的结果
5. group by
GROUP BY 语句根据一个或多个列对结果集进行分组。
在分组的列上我们可以使用 COUNT, SUM, AVG,等函数。
select class_id, COUNT(*) as '该品类商品数'
from product
GROUP BY class_id
select class_id, COUNT(*) as '该品类商品数', sum(product_price) as '该品类总值'
from product
GROUP BY class_id
WITH ROLLUP
-- with rollup 就是对数据再做一次归纳

group by 注意事项
是由于默认的 MySQL8.0的 配置中 sql_mode 配置了 only_full_group_by,需要 GROUP BY 中包含所有在 SELECT 中出现的字段。
使用这个就是使用和oracle一样的group 规则, select的列都要在group中,或者本身是聚合列(SUM,AVG,MAX,MIN) 才行。如果查找出其他列会报错:
1055 - Expression #2 of SELECT list is not in GROUP BY clause and contains nonaggregated column ‘lianfeng.product.product_name’ which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
例如上面的group by语句中随便加入一个字段,就会抛出上面的错误。
6. Having
having字句可以让我们筛选成组后的各种数据,where字句在聚合前先筛选记录,也就是说作用在group by和having字句前。而 having子句在聚合后对组记录进行筛选。我的理解是生成临时的数据后,再通过having进一步对数据进行筛选。
select class_id, COUNT(id) as '该品类商品数'
from product
GROUP BY class_id
HAVING COUNT(id) > 5
--选出各品类下商品数量大于5的商品类型
having和where的区别:
Select city FROM weather WHERE temp_lo = (SELECT max(temp_lo) FROM weather);
作用的对象不同。WHERE 子句作用于表和视图,HAVING 子句作用于组。
WHERE 在分组和聚集计算之前选取输入行(因此,它控制哪些行进入聚集计算),而 HAVING 在分组和聚集之后选取分组的行。因此,WHERE 子句不能包含聚集函数; 因为试图用聚集函数判断那些行输入给聚集运算是没有意义的。 相反,HAVING 子句总是包含聚集函数。(严格说来,你可以写不使用聚集的 HAVING 子句, 但这样做只是白费劲。同样的条件可以更有效地用于 WHERE 阶段。)
在前面的例子里,我们可以在 WHERE 里应用城市名称限制,因为它不需要聚集。 这样比在 HAVING 里增加限制更加高效,因为我们避免了为那些未通过 WHERE 检查的行进行分组和聚集计算
综上所述:
having一般跟在group by之后,执行记录组选择的一部分来工作的。
where则是执行所有数据来工作的。
再者having可以用聚合函数,如having sum(qty)>1000
此处参考:https://www.cnblogs.com/lmaster/p/6373045.html
待续…














 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









