







1. 为什么要使用kafka集群
单机服务下,Kafka已经具备了非常高的性能。TPS能够达到百万级别。但是,在实际工作中使用时,单机搭建的Kafka会有很大的局限性。
- 消息太多,需要分开保存。Kafka是面向海量消息设计的,一个Topic下的消息会非常多,单机服务很难存得下来。这些消息就需要分成不同的Partition,分布到多个不同的Broker上。这样每个Broker就只需要保存一部分数据。这些分区的个数就称为分区数。
- 服务不稳定,数据容易丢失。单机服务下,如果服务崩溃,数据就丢失了。为了保证数据安全,就需要给每个Partition配置一个或多个备份,保证数据不丢失。Kafka的集群模式下,每个Partition都有一个或多个备份。Kafka会通过一个统一的Zookeeper集群作为选举中心,给每个Partition选举出一个主节点Leader,其他节点就是从节点Follower。主节点负责响应客户端的具体业务请求,并保存消息。而从节点则负责同步主节点的数据。当主节点发生故障时,Kafka会选举出一个从节点成为新的主节点。
- Kafka集群中的这些Broker信息,包括Partition的选举信息,都会保存在额外部署的Zookeeper集群当中,这样,kafka集群就不会因为某一些Broker服务崩溃而中断。
2. kafka的集群架构
由章节1中对kafka集群特点的描述,我们可以大致画出kafka的集群架构图大致如下:
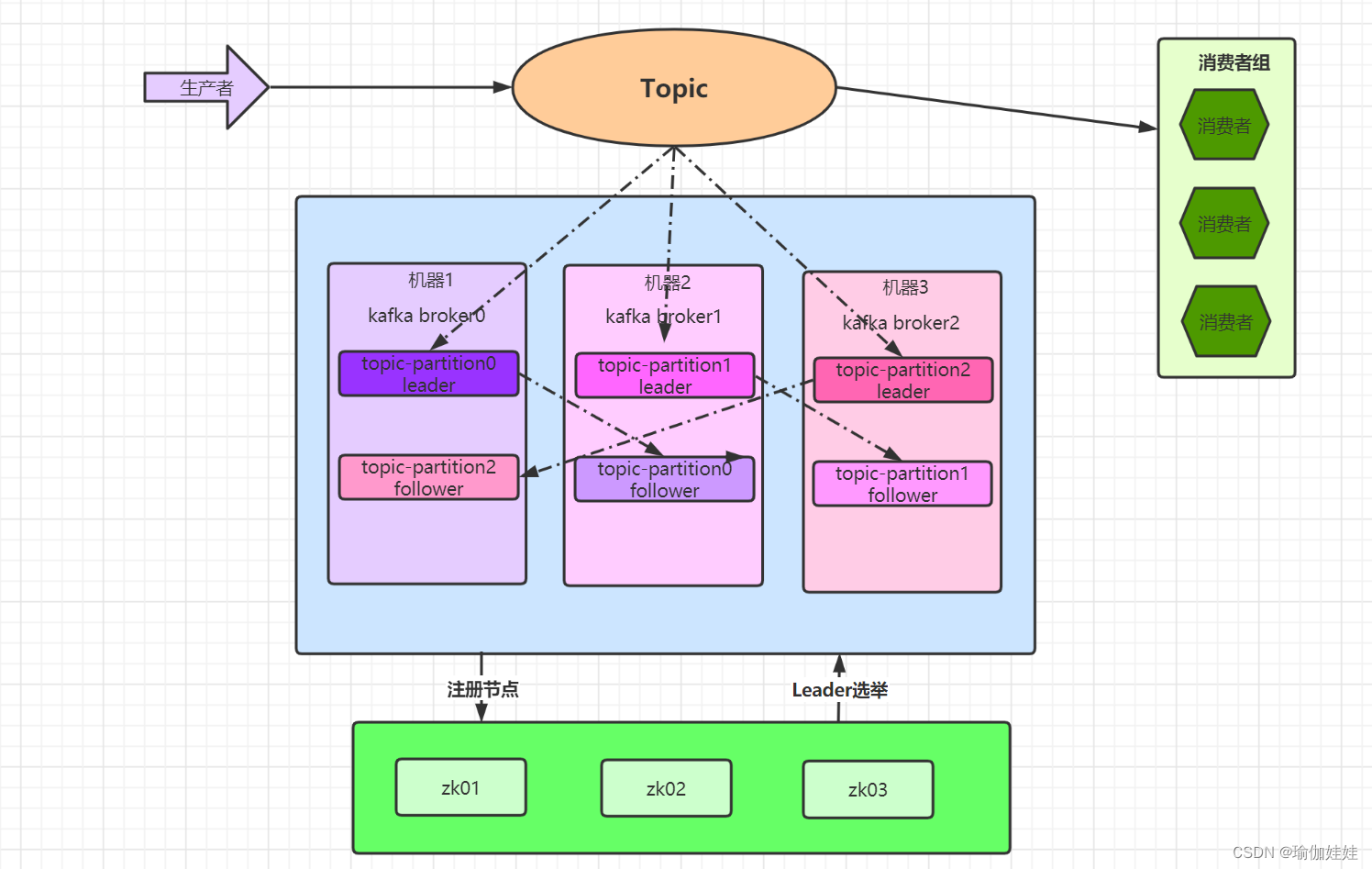
3. kafka集群搭建
接下来我们就动手部署一个Kafka集群,来体验一下Kafka是如何面向海量数据进行横向扩展的。
3.1 搭建kafka集群
搭建环境:
1. 准备3台虚拟机
2. 安装jdk
jdk安装可参考Linux环境下安装JDK-CSDN博客
3. 关闭防火墙(实验版本关闭防火墙,生产环境开启对应端口即可)
firewall-cmd --state 查看防火墙状态 systemctl stop firewalld.service 关闭防火墙
第一步: zookeeper 集群搭建
kafka依赖于zookeeper,虽然kafka内部自带了一个zookeeper,为了保证服务之间的独立性,不建议使用其内部的zookeeper,所以我们先搭建一个独立的zookeeper集群。Zookeeper是一种多数同意的选举机制,允许集群中少数节点出现故障。因此,在搭建集群时,通常都是采用3,5,7这样的奇数节点,这样可以最大化集群的高可用特性。
zk集群搭建参考:zookeeper之集群搭建-CSDN博客
根据上述文章搭建完成之后,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1225
1225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











