







生成器和判别器本质是两个独立的网络,因此训练的时候交替独立训练。(既“交替”又“独立”)

其训练机理为:生成器和判别器单独交替训练(先训练判别器 --> 再训练生成器 --> 再训练判别器... )。步骤如下:
首先你要知道:损失函数就是为了将两者的距离拉进,例如loss(A, 1):就是为了将A通过反向传播后更接近于1
1. 训练判别器(最大化鉴别器的损失):
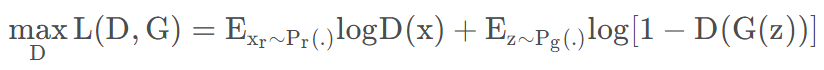
- 固定生成器的参数,真实图像x 输入判别器后输出的结果标签为1,【使D(x)为1】
代码为:loss_d_real = loss_func(d_real, torch.ones([batch_size, 1])) - 随机噪声 z 输入生成器得到假图像 G(z),再输入判别器后得到的输出结果标签为0,【使D(G(z))为0,也就是1-D(G(z))为1】
loss_d_fake = loss_func(d_fake, torch.zeros([batch_size, 1])) - 训练判别器到收敛。
2. 训练生成器(最小化生成器的损失):
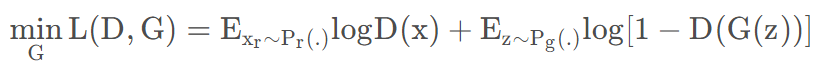
固定判别器的参数,随机噪声z输入生成器得到的假图像G(z),然后输入判别器得到的结果的标签为1,(使D(G(z))为1,看起来有驳常理,但是这是为了迷惑鉴别器)
loss_G = loss_func(d_g_fake, torch.ones([batch_size, 1]))
训练生成器到收敛。
3. 交替循环步骤1和2,当然也可以在不收敛的过程中交替训练。
代码进一步理解上述过程
以下为代码(代码和上面解释的部分对应着来看)
def train():
G_mean = []
G_std = [] # 用于记录生成器生成的数据的均值和方差
data_mean = 3
data_std = 1 # 目标分布的均值和方差
batch_size = 64
g_input_size = 16
g_output_size = 512
epochs = 1001
d_epoch = 1 # 每个epoch判别器的训练轮数
# 初始化网络
D = Discriminator()
G = Generator()
# 初始化优化器和损失函数
d_learning_rate = 0.01
g_learning_rate = 0.001
loss_func = nn.BCELoss() # - [p * log(q) + (1-p) * log(1-q)]
optimiser_D = optim.Adam(D.parameters(), lr=d_learning_rate)
optimiser_G = optim.Adam(G.parameters(), lr=g_learning_rate)
plt.ion()
for epoch in range(epochs):
G.train()
# 1 训练判别器d_steps次
for _ in range(d_epoch):
# 1.1 真实数据real_data输入D,得到d_real
real_data = torch.tensor(np.random.normal(data_mean, data_std, (batch_size, g_output_size)), dtype=torch.float)
d_real = D(real_data)
# 1.2 生成数据的输出fake_data输入D,得到d_fake
g_input = torch.rand(batch_size, g_input_size)
fake_data = G(g_input).detach() # detach:只更新判别器的参数
d_fake = D(fake_data)
# 1.3 计算损失值 ,判别器学习使得d_real->1、d_fake->0
loss_d_real = loss_func(d_real, torch.ones([batch_size, 1]))
loss_d_fake = loss_func(d_fake, torch.zeros([batch_size, 1]))
d_loss = loss_d_real + loss_d_fake
# 1.4 反向传播,优化
optimiser_D.zero_grad()
d_loss.backward()
optimiser_D.step()
# 2 训练生成器
# 2.1 G输入g_input,输出fake_data。fake_data输入D,得到d_g_fake
g_input = torch.rand(batch_size, g_input_size)
fake_data = G(g_input)
d_g_fake = D(fake_data)
# 2.2 计算损失值,生成器学习使得d_g_fake->1
loss_G = loss_func(d_g_fake, torch.ones([batch_size, 1]))
# 2.3 反向传播,优化
optimiser_G.zero_grad()
loss_G.backward()
optimiser_G.step()
# 2.4 记录生成器输出的均值和方差
G_mean.append(fake_data.mean().item())
G_std.append(fake_data.std().item())
if epoch % 10 == 0:
print("Epoch: {}, 生成数据的均值: {}, 生成数据的标准差: {}".format(epoch, G_mean[-1], G_std[-1]))
print('-' * 10)
G.eval()
draw(G, epoch, g_input_size)
plt.ioff()
plt.show()
plt.plot(G_mean)
plt.title('均值')
plt.savefig('gan_mean.jpg')
plt.show()
plt.plot(G_std)
plt.title('标准差')
plt.savefig('gan_std.jpg')
plt.show()
if __name__ == '__main__':
train()4. 总结
通过一个判别器而不是直接使用损失函数来进行逼近,更能够自顶向下地把握全局的信息。比如在图片中,虽然都是相差几像素点,但是这个像素点的位置如果在不同地方,那么他们之间的差别可能就非常之大。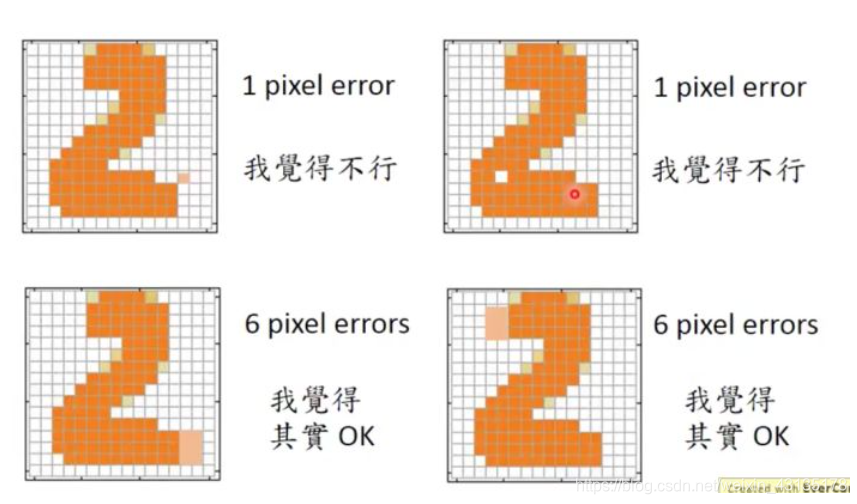
比如上图10中的两组生成样本,对应的目标为字体2,但是图中上面的两个样本虽然只相差一个像素点,但是这个像素点对于全局的影响是比较大的,但是单纯地去使用使用损失函数来判断,那么他们的误差都是相差一个像素点,而下面的两个虽然相差了六个像素点的差距(粉色部分的像素点为误差),但是实际上对于整体的判断来说,是没有太大影响的。但是直接使用损失函数的话,却会得到6个像素点的差距,比上面的两幅图差别更大。而如果使用判别器,则可以更好地判别出这种情况(不会拘束于具体像素的差距)。
总之GAN是一个非常有意思的东西,现在也有很多相关的利用GAN的应用,比如利用GAN来生成人物头像,用GAN来进行文字的图片说明等等。
引用:通俗理解生成对抗网络GAN - 知乎



















 7277
7277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











