







垃圾收集器
HotSpot虚拟机所包含的所有收集器如下(JDK1.7+)
新生代包含:Serial,Parnew,Parallel Scavenge ,G1
老年代包含:Serial Old,Parallel OLd,CMS,G1

- Serial收集器
是最基本,历史悠久的收集器(JDK1.3.1之前),特点:
- 单线程的收集器。
- 垃圾收集时,必须暂停所有的工作线程,直到它收集结束。
- 能与CMS收集器配合使用。

适用于运行在Client模式下的虚拟机。
- ParNew收集器
是Serial收集器的多线程版本。能与CMS收集器配合使用。
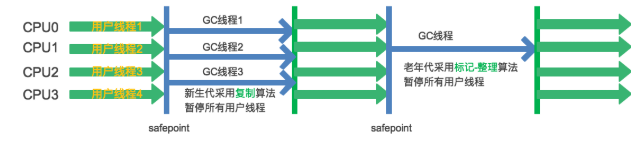
3. Parallel Scavenge收集器
在ParNew的基础上进一步提高系统吞吐量。
吞吐量=运行用户代码的时间/(运行用户代码的时间+垃圾收集的时间)
例如 虚拟机总共运行100分钟,其中垃圾收集花了1分钟,那吞吐量就是99%。
提供了两个参数控制吞吐量
- 最大垃圾收集停顿时间 -XX:MaxGCPauseMillis(>0)
- 直接设置吞吐量大小 -XX:GCTimeRatio(吞吐量的倒数 范围0-100)
如果不想手动设置这些参数,让虚拟机自适应调节,只需要把基本的内存数据设置好。
可以使用 -XX:+UseAdaptiveSizePolicy这个参数。
该收集器适用于后台运算不需要太多交互的任务。
-
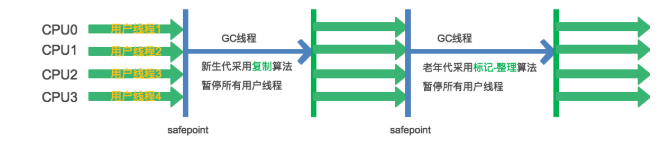
Serial Old收集器
Serial收集器的老年代版本,单线程。
-
Parallel Old收集器
Parallel Scavenge收集器的老年代版本,多线程。

-
CMS收集器
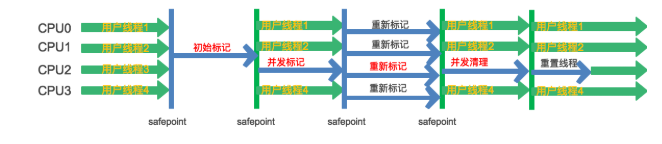
以最短时间为目标的收集器。基于“标记-清除”算法实现,整个过程分为四个步骤:
初始标记:标记一下GC Roots能直接关联到的对象,速度很快。
并发标记:进行GC RootsTracing 的过程。
重新标记:为了修正并发标记期间因用户程序继续运作而导致的新的垃圾
并发清除:用户程序和Gc 同时进行。清除掉标记的垃圾。
其中,初始标记和重新标记仍然需要“Stop the world”。
优点:并发收集,低停顿。
缺点:
CMS对CPU资源很敏感,可能会导致用户程序变慢。
CMS收集器无法处理浮动垃圾,可能出现“Concurrent Mode Failure”失败而导致Full GC。
CMS收集器会产生空间碎片。(标记-清除算法)
- G1收集器
特点:
- 并行与并发:充分利用多cpu多核环境下的硬件优势。缩短停顿时间。让java程序并发执行。
- 分代收集:对立管理整个堆,不需要跟其他收集器配合使用。
- 空间整合:不会产生内存空间碎片。
- 可预测的停顿:能建立可预测的时间模型。让使用者明确指定在一个长度为M毫秒的时间片段内,消耗在垃圾收集的时间不得超过N毫秒。
- Region 划分:将整个堆划分为多个大小相等的独立区域(Region),保留新生代和老年代的概念。但是不再是物理隔离。他们都是一部分Region的集合。
- Remembered Set:每个Region都有一个与之对应的Remembered Set来避免全堆扫描。
如果不计算维护Remembered Set的操作,G1收集器的运作可划分为一下几个步骤:
- 初始标记
- 并发标记
- 最终标记
- 帅选回收















 2189
2189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









