







视频资源:
0. Dubbo与Zookeeper的关系
Dubbo建议使用Zookeeper作为服务的注册中心。
Dubbo是一个框架,用于服务间的调度,服务程序编写使用dubbo做接口,dubbo实现了服务与服务之间还有zookeeper之间的通讯。
Zookeeper的作用:
zookeeper用来注册服务和进行负载均衡,哪一个服务由哪一个机器来提供必需让调用者知道,简单来说就是ip地址和服务名称的对应关系。当然也可以 通过硬编码的方式把这种对应关系放到调用方业务代码中实现,但是如果提供服务的机器宕机,调用者将无法知晓,此时如果不更改代码会继续请求挂掉的机器提供服务。 zookeeper通过心跳机制可以检测挂掉的机器并将挂掉机器的ip和服务对应关系从列表中删除。至于支持高并发,简单来说就是横向扩展,在不更改代码的情况下通过添加机器来提高运算能力。通过添加新的机器向zookeeper注册服务,服务的提供者多了能服务的客户就多了,于是便能支持更大的并发量。
dubbo的作用:
是管理中间层的工具,在业务层到数据仓库间有非常多服务的接入和服务提供者需要调度,dubbo提供一个框架解决这个问题。注意这里的dubbo只是一个框架,至于你架子上放什么是完全取决于你的,就像一个汽车骨架,你需要配你的轮子引擎。这个框架中要完成调度必须要有一个分布式的注册中心,储存所有服务的元数据,你可以用zk,也可以用别的,只是大家都用zk。
1. Zookeeper基础
- Dubbo框架、SpringCloud的框架,zk是作为
注册中心 - Hadoop、HBase组件,集群架构,zk是作为
集群管理者 - zk实现
分布式锁 - 是一个分布式应用程序的
协调服务,很少做业务实现
1. 1 概述
Zookeeper的工作机制:
Zookeeper从设计模式的角度理解:是一个基于观察者模式设计的分布式服务管理框架。它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出响应的反应。
Zookeeper = 文件系统 + 通知机制
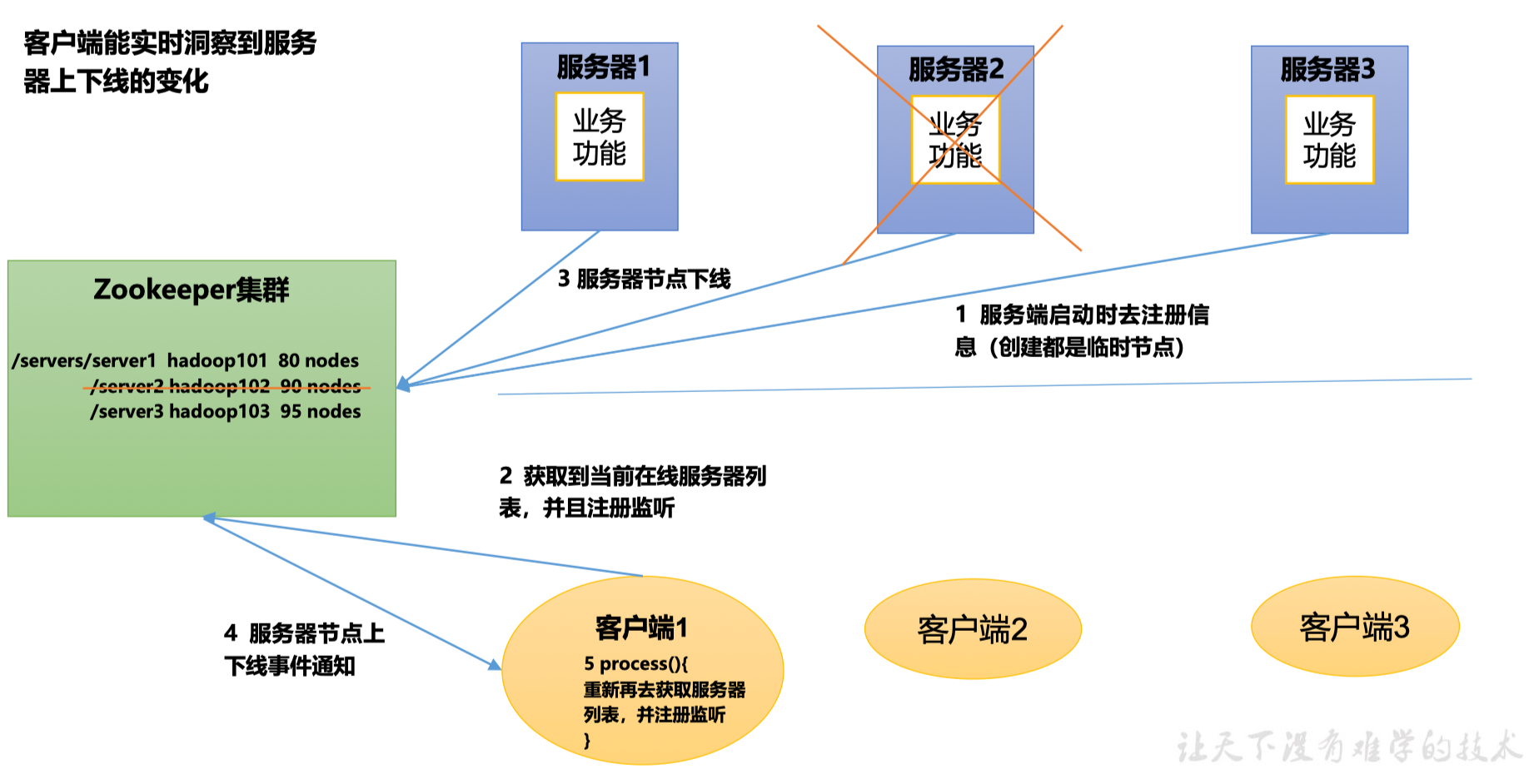
文件系统:服务端启动时去注册信息(创建的都是临时节点),Zookeeper集群存储的是各种服务器的上线信息
通知机制:客户端获取到当前服务器列表,并且注册监听;Zookeeper集群通知客户端(服务端上下线事件通知)
1.2 Zookeeper特点
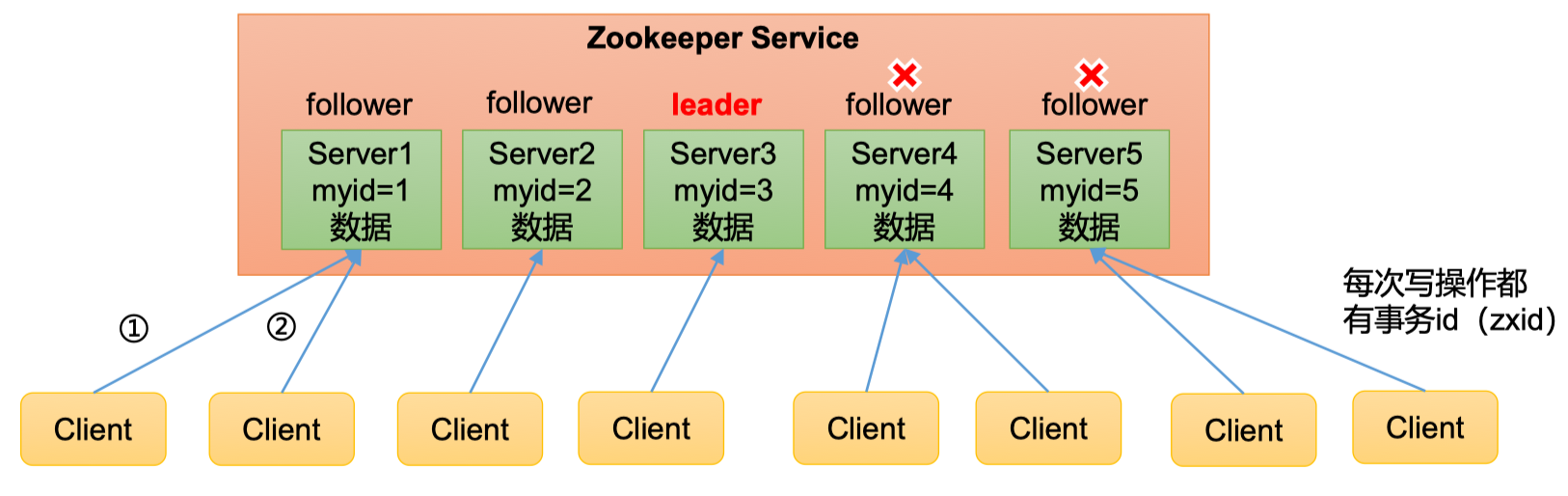
- Zookeeper:一个领导者(leader),多个跟随者(follower)组成的集群
- 集群中只要有半数以上节点(半数机制)存活,Zookeeper集群就能正常服务。所以Zookeeper适合安装奇数台服务器?(假如现在有5台服务器,挂了2台,集群依然能正常工作,但如果挂了3台就因为违背“半数以上节点存活”的规则而无法正常工作;假如现在有6台服务器,挂了2台依然能正常工作,但是挂了3台,因为3=(6/2),所以同样也不能正常工作。所以,5台和6台在提升集群健壮性上没有任何帮助,存在资源浪费)
- 全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个server,数据都是一致的
- 更新请求顺序执行,来自同一个client的更新请求按其发送顺序依次执行
- 数据更新原子性,一次数据更新,要么成功要么失败。(比如,每次写操作都有
事务id(zxid)) - 实时性,在一定时间范围内,client能读到最新数据(比如一个client向一个服务器写入数据,那其他client要拿到/读到这个数据,需要服务器之间同步数据,zookeeper的同步速度非常快)
1.3 内存/数据结构
之前提到过,Zookeeper = 文件系统 + 通知机制,Zookeeper数据模型的结构与Unix文件系统很相似,整体上可以看作是一棵树,每个节点称作是一个ZNode。每一个ZNode默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标识。
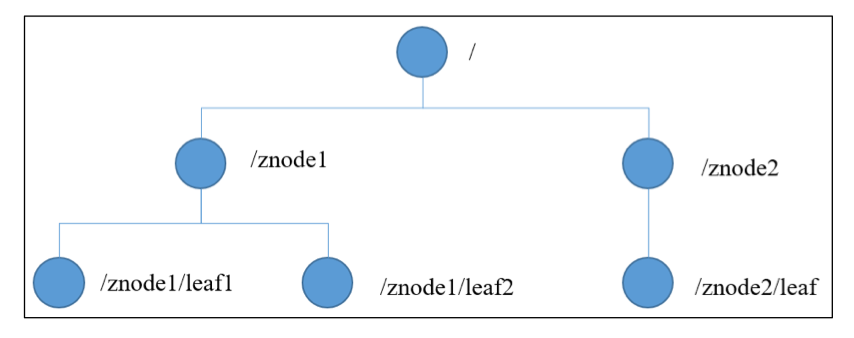
模型特点
- 每个子目录如
/znode1都被称作为一个znode(节点)。这个znode是被它所在的路径唯一标识 - znode可以有子节点目录,并且每个znode可以存储数据
- znode是有版本的,每个znode中存储的数据可以有多个版本,也就是一个访问路径中可以存储多分数据(如一个节点中的数据,每次对其修改,可对版本号递增1)
- znode可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化,一旦变化可以通知设置监控的客户端(如可以使用Java客户端去监控一个节点,如果修改,则zk会通知客户端)
问:能否用Zookeeper存储海量的数据?
答:不行,它只适合存储简单的配置信息。
1.4 节点的分类
1.4.1 持久节点(persistent)P
是指节点创建后,就一直存在,直到有删除操作来删除这个节点——不会因为创建该节点的客户端会话失效而消失。该节点会存储到服务器的磁盘上,无论宕机与否,都不会消失
1.4.2 持久顺序节点(persistent_sequential)PS
这类节点的基本特性和上述节点类型一致。额外的特性是,在ZK中,每个父节点会为它的第一级子节点维护一份时序,会记录每一个子节点的创建的先后顺序。基于这个特性,在创建子节点的时候,可以设置这个属性,那么在创建节点过程中,ZK会自动给节点名字加上一个数字后缀,作为新的节点名,这个数字后缀的范围是整型的最大值
1.4.3 临时节点(ephemeral)E
和持久节点不同,临时节点的生命周期和客户端会话绑定,也就是说,如果客户端会话失效,那么这个临时节点也将失效(被自动清除掉)。注意,这里提到的是会话失效,而非断开连接。另外,临时节点下面不能再创建子节点。
1.4.4. 临时顺序节点(ephemeral_sequential)ES
具备临时节点和顺序节点的特性。
1.5 应用场景
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡(从软件层面而非硬件层面,硬件非常贵,但是性能好)等
1.5.1 统一命名服务
在分布式环境下,经常需要对应用/服务进行统一命名,便于识别。例如ip地址不容易记住,而域名容易记住
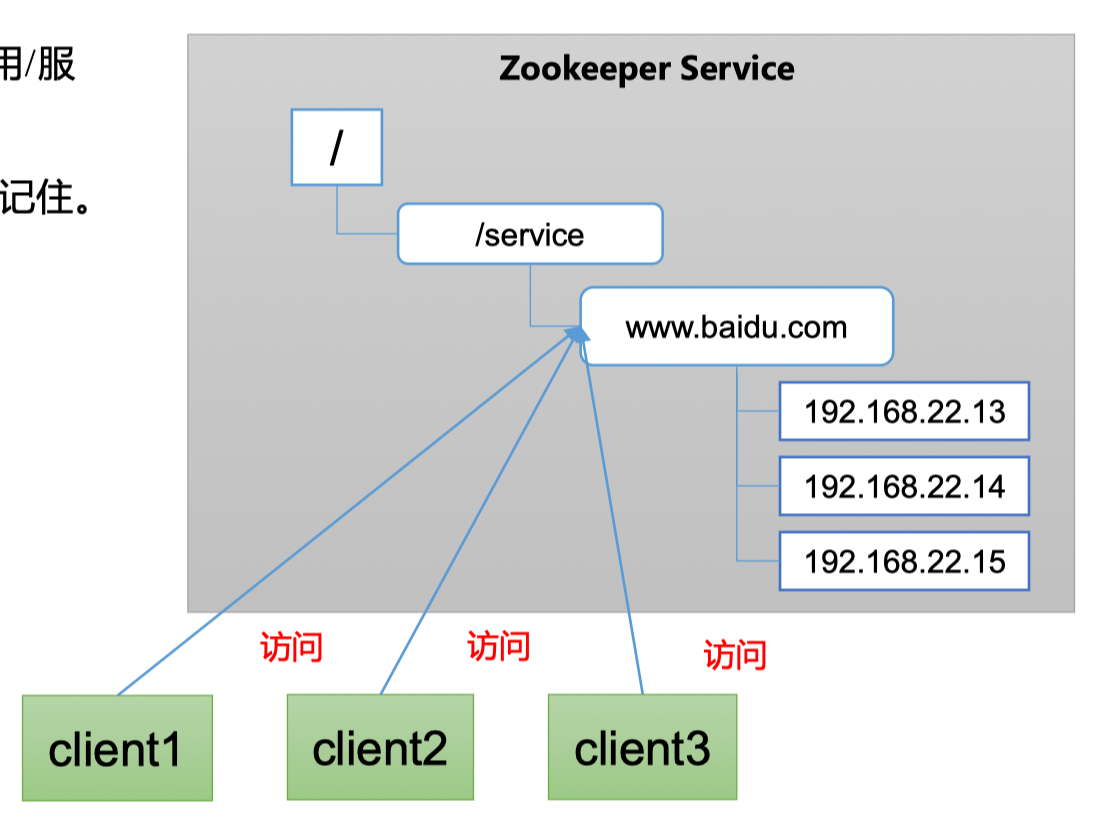
当client对一个域名访问的时候,会自动根据负载情况,去指定访问特定服务器,而不用client自己设定。Nginx等很多框架也同样能实现这个事情
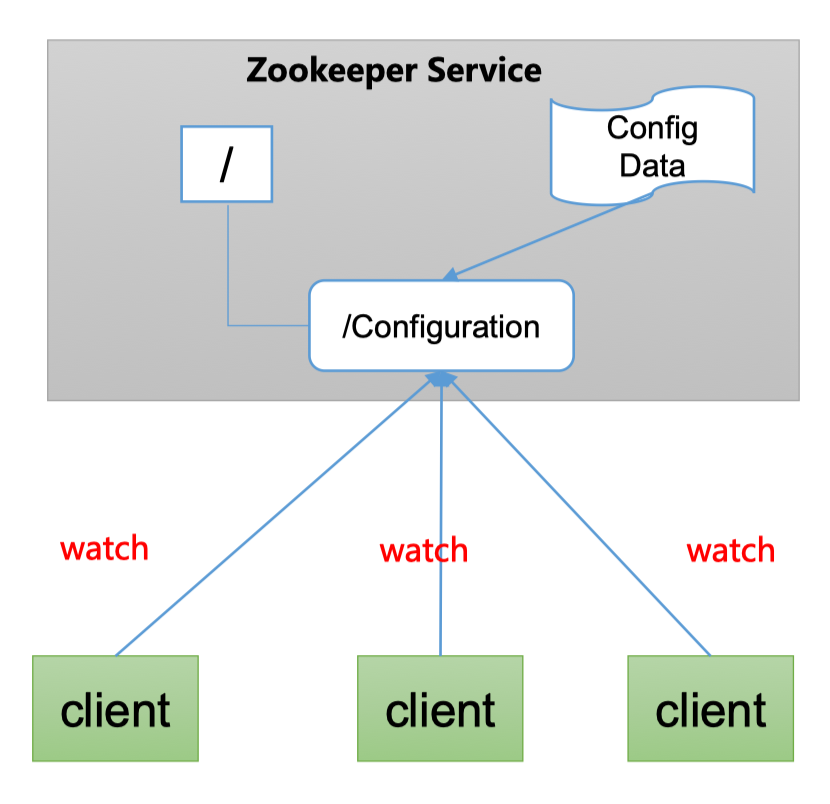
1.5.2 统一配置管理
- 分布式环境下,配置文件同步非常常见
- 一般要求一个集群中,所有节点的配置信息是一致的,比如Kafka集群或Hadoop集群
- 对配置文件修改后,希望能快速同步到各个节点上
- 配置管理可交给Zookeeper实现
- 可将配置信息写入Zookeeper上的一个ZNode
- 各个客户端服务监听这个ZNode
- 一旦这个ZNode中的数据发生修改,Zookeeper就通知所有监听这个ZNode的客户端
1.5.3 统一集群管理
- 分布式环境中,实时掌控每个节点的状态是必要的
- 可根据节点的状态实时做出一些调整
- Zookeeper可以实现实时监控节点状态变化
- 可将节点信息写入Zookeeper上的一个ZNode
- 监听这个ZNode可以获取它的实时状态变化
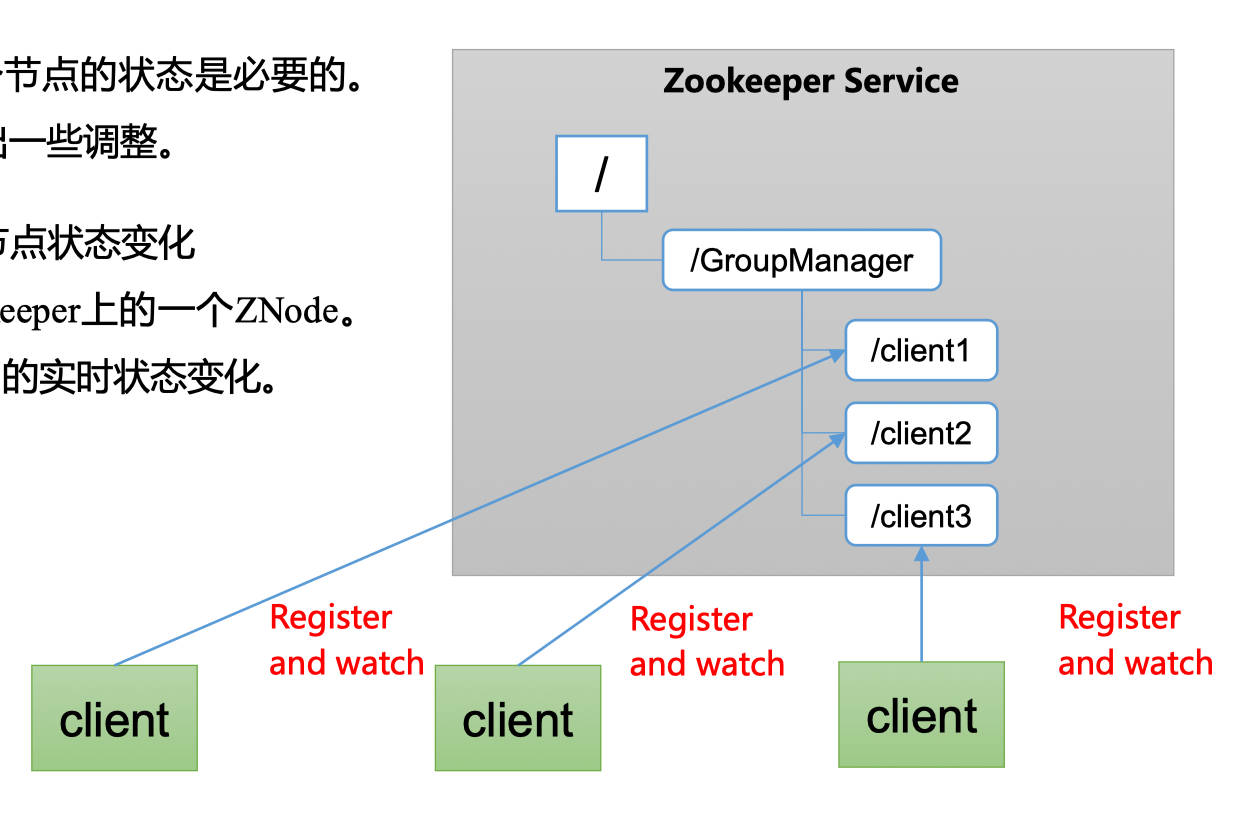
假如现在有一个Zookeeper集群,在/GroupManager下面有多个/clientX,每个客户端可以在/clientX下注册,/clientX中就可以存放这个客户端的相关运行信息(如服务几点上线、上线时运行状态如何)。而此时,别人(Zookeeper或者其他节点)监听这个节点,就能获取到它的实时状态变化,从而做出相应策略(如运维就可以根据服务器运行好坏做出策略)
1.5.4 服务器动态上下线
客户端能实时洞察到服务器上下线变化
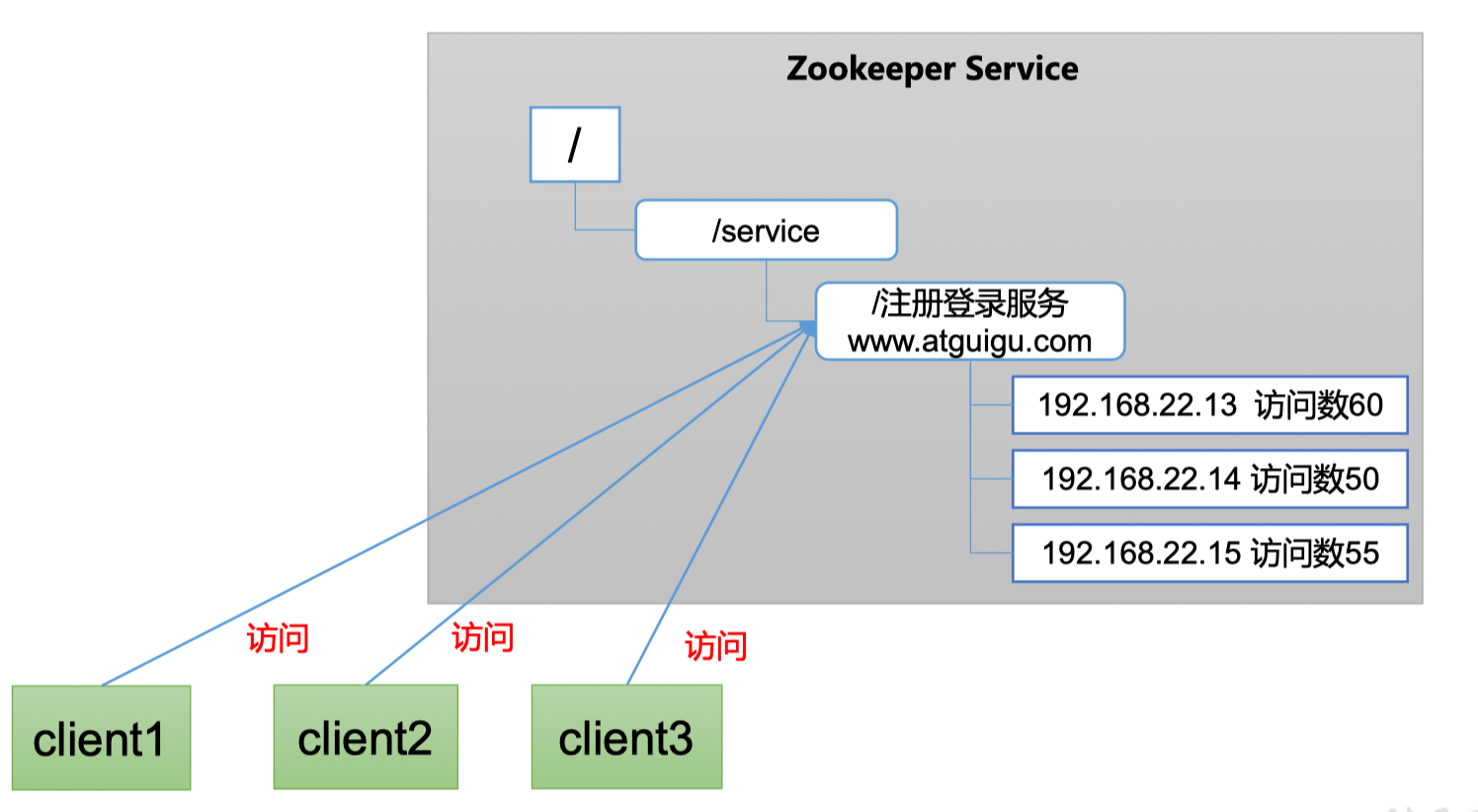
1.5.5 软负载均衡
在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端请求
当然其他框架也能做负载均衡,如Nginx
1.6 选举机制(面试重点)
Zookeeper的选举机制较为复杂,分为第一次启动和非第一次启动(第一次选举出来的Leader挂了,二次选举…三次选举…)。
第一次启动
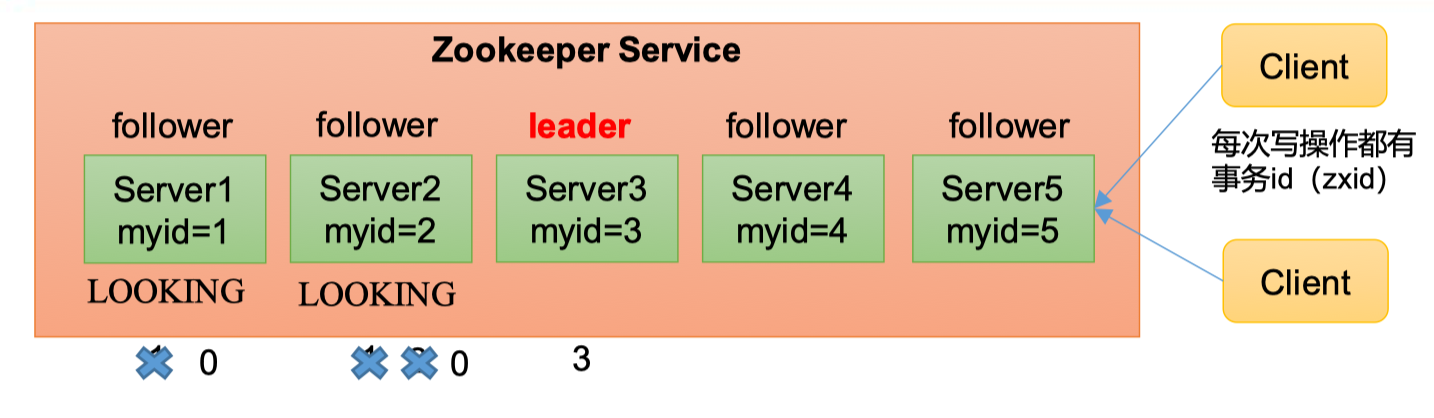
假设一个Zookeeper集群中有5台服务器,注意这里一开始就有5台,即想要成为leader必须有超过半数以上,即至少有3票。每一台集群中的服务器都有一个自己的唯一id,myid
服务器1启动,发起一次选举。每台服务器一开始都默认投给自己,服务器1投自己一票,接着需要判断自己手里的选票是否超过总集群数的一半以上,1票不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING,既不是Leader也不是Follower服务器2启动,所有启动的服务器再发起一次选举。服务器1和服务器2分别投自己一票并交换选票信息:此时服务器1发现服务器2的myid比自己投票推举的(服务器1的myid=1)大,更改选票为推举服务器2。此时,服务器1:0票,服务器2:2票,判断后发现仍没有半数以上的结果,选举无法完成,服务器1、2保持LOOKING状态服务器3启动,所有启动的服务器再发起一次选举,并且都投自己,然后交换选票信息后都改投服务器3。此次投票结果:服务器1:0票,服务器2:0票,服务器3:3票,判断后发现服务器3的投票已经达到3票,满足条件,服务器3当选Leader。服务器1、2更改状态为FOLLOWING,服务器3更改状态为LEADING。服务器4启动,再发起一次选举。此时服务器1、2、3已经不是LOOKING状态,不会更改选票信息。选举结果:服务器3:3票,服务器4:1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING。服务器5启动,与服务器4一样,状态改为了FOLLOWING
这里有几个概念:
SID:服务器ID。用来唯一标识一台Zookeeper集群中的机器,每一台机器不能重复,和myid一致
ZXID:事务ID。ZXID是一个事务ID,用来标识一次服务器状态的更新。在某一时刻,集群中的每一台服务器的ZXID值不一定完全一致,这和Zookeeper服务器对于客户端“更新请求”的处理逻辑有关
Epoch:每个Leader任期的代号。没有Leader时,同一轮投票过程中的逻辑时钟值是相同的,每投完一次票这个值会增加
非第一次选举
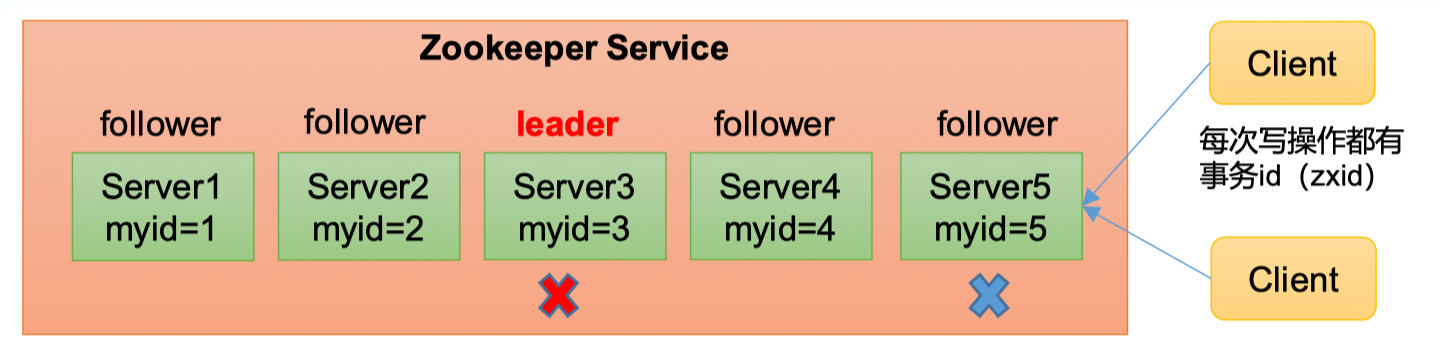
-
当Zookeeper集群中的一台服务器出现以下两种情况之一时,就会开始进入Leader选举
- 服务器初始化时(就是前面的启动时选举)
- 服务器运行期间无法和Leader保持连接(比如
服务器5在某一时刻与leader服务器无法保持连接,它可能认为leader服务器挂了,于是会开始进入leader选举,如下)
-
当一台机器进入leader选举流程时,当前集群也可能存在以下两种状态:
-
集群中本来就有一个leader(只是进入选举的服务器没有连接上)。此时该机器试图去选举Leader时,会被告知当前Leader信息,对于该机器来说,仅仅需要和Leader机器建立连接,并进行状态同步即可
-
集群中确实不存在leader。
假设:Zookeeper中有5台服务器,SID分别为1、2、3、4、5,ZXID分别为8、8、8、7、7,SID为3的服务器为leader,某一时刻,SID为3、5的服务器出现故障,因此开始选举Leader。选举的原则,关注
Epoch, ZXID, SID
所以SID为2的服务器会被选举为新的Leader
-
1.7 Zookeeper安装
1.7.1 本地模式安装
在Apache官网下载,安装,到/conf下将zoo_sample.cfg修改为zoo.cfg并修改其中dataDir
1.7.2 配置参数解读
Zookeeper中的的配置文件zoo.cfg中参数解读如下:
-
tickTime=2000:通信心跳时间,Zookeeper服务器与客户端心跳时间,单位是毫秒。注意不仅服务器与客户端之间有,服务器与服务器之间也有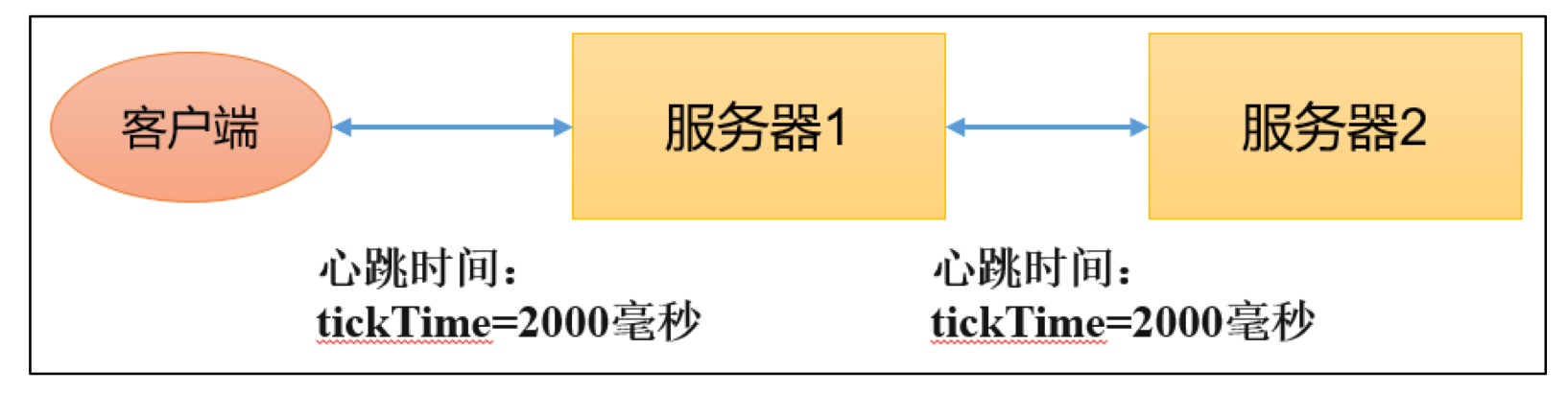
-
initLimit=10:LF初始通信时限("10"代表10个心跳,总时间 = 10 * 2s = 20s)
Leader和Follower初始连接时,能容忍的最多心跳数(tickTime的数量)
-
syncLimit=5:LF同步通信时限(“5”代表5个心跳,总时间= 5 * 2s = 10s)Leader和Follower之间通信时间如果超过
syncLimit * tickTime,Leader认为Follower死掉,从服务器列表删除Follower -
dataDir:保存Zookeeper中的数据注意:默认的
/tmp目录,容易被Linux系统定期删除,所以一般不用默认的tmp目录,建议修改至zk包下 -
clientPort=2181:客户端连接端口,通常不做修改 -
maxClientCnxns=60:最大客户连接数,即线程池线程数量。 -
autopurge.snapRetainCount=3:The number of snapshots to retain in dataDir,zk中的树形结构是存储在内存中,这也是为什么zk可以接受大规模的并发。这里快照就是用来做一个持久化的存储
3. Zookeeper集群与操作
3.1 集群(cluster)
定义:集合同一种软件服务的多个节点同时提供服务
解决的问题:
- 单节点并发访问的压力大
- 单节点故障问题(如硬件老化、自然灾害等)
Zookeeper中的集群:
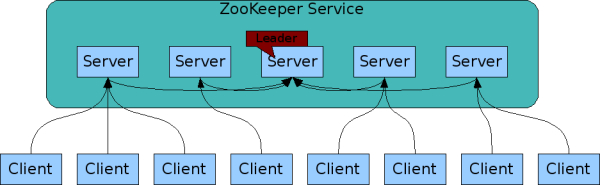
关于为什么客户端可以对任意zk节点进行读写并且zk能保证数据一致,请参考第七章节的ZAB协议(消息广播、崩溃恢复)
3.1.1 搭建集群
- MAC VMwave安装多个Linux(centos)虚拟机教程,教程里演示了如何在VMware Fusion中搭建多个centos虚拟机并进行简单的网络配置(可以ping得同),注意其中涉及到clone机器的操作需要Fusion Pro版本。然后可以用SecureCRT来通过ssh连接每一台虚拟机(这里如果是把虚拟机搭建在本地的话必须每次都启动每一台机器再用SecureCRT来ssh)
- Linux环境搭建(基础、网络配置、集群、hadoop前置课程)关闭防火墙,时间同步,集群搭建,JDK,ssh免密登录,权限管理…
3.2 客户端命令行操作
3.2.1 监听器原理
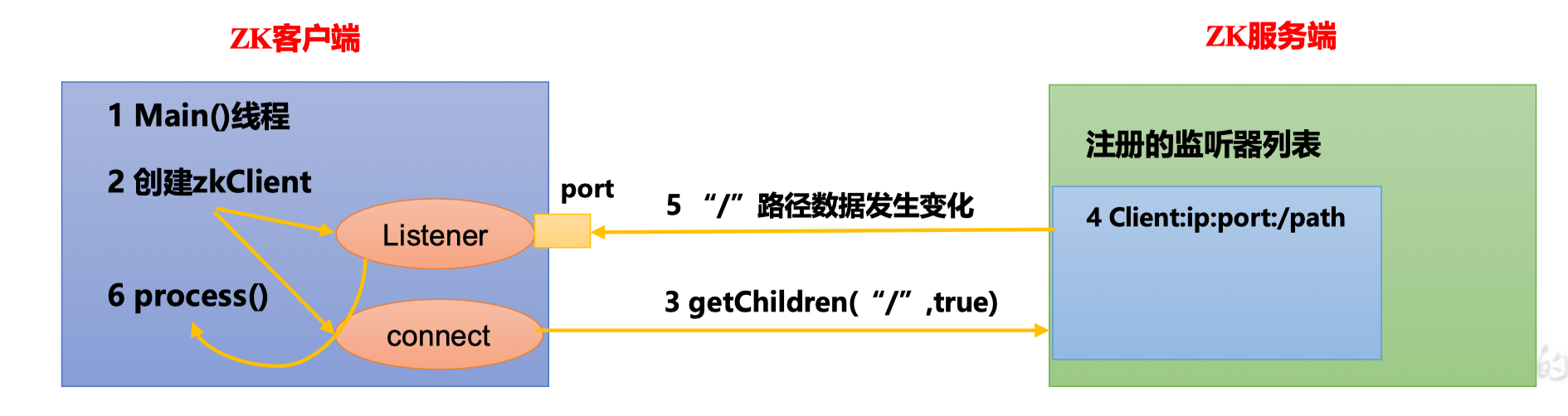
监听器原理详解
- 首先要有一个
main()线程 - 在
main()线程中创建Zookeeper客户端,这时就会创建两个线程,一个负责网络连接通信(connect),一个负责监听(listener) - 通过connect线程将注册的监听事件发送给Zookeeper服务端
- 在Zookeeper服务端的注册监听器列表中将注册的监听事件添加到列表中
- Zookeeper服务端监听到有数据或路径变化,就会将这个消息发送给listener线程
- listener线程内部调用
process()方法
常见的监听
-
监听节点数据的变化,注意:数据的变化,注册一次,只能监听一次;想要再次监听,就需要再次注册
get path [watch] -
监听子节点增删的变化,注意:路径的变化,注册一次,只能监听一次;想要再次监听,就需要再次注册
ls path [watch]
3.3 客户端API操作
3.3.1 创建maven项目
3.3.2 添加maven依赖
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.5.7</version>
</dependency>
</dependencies>
3.3.3 创建客户端
package com.zzw.zk;
import org.apache.zookeeper.*;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
public class zkClient {
private String connectString = "192.168.3.11:2181,192.168.3.22:2181,192.168.3.33:2181"; // 注意:这里的不同ip之间不能有空格
private Integer sessionTimeout = 2000;
private ZooKeeper zkClient;
// 初始化(连接一个Server或一个Server集群)
@Before
public void init() throws IOException {
zkClient = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1896
1896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









