







1. 概要
1.0 前言
最近刚写完AI Reasoning & Decision Making的Coursework,占这门课总成绩的20%。因为不要求写Report,所以在这里单独做一个记录和总结。从CW放出到ddl大概有一个月的时间,工作量不大,难度也较低,在Github上有很多Pacman基于MDP的代码可以参考借鉴。个人认为难点是在于调整项目中的各类参数,如Reward,和制定策略来优化游戏结果(胜率、得分)。
1.1 游戏
1.1.1 原版
原版是需要玩家手动控制,而我们这门课叫’AI Reasoning & Decision Making’,那自然是要编写AI来自动决策的。
1.1.2 小地图

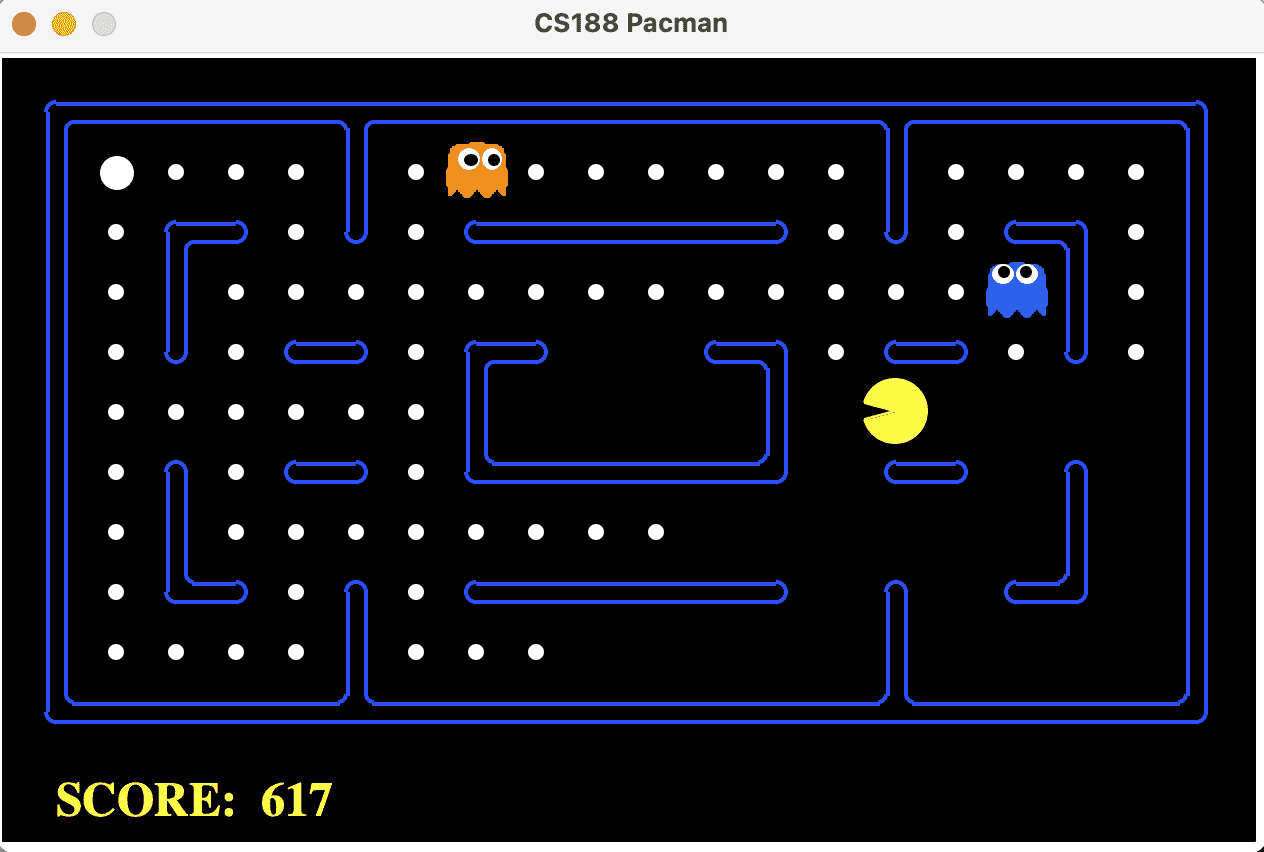
1.1.3 中地图
1.2 要求
-
要求0:整个Coursework拿到时是可运行的,无需重构或实现除了Pacman外的任何功能。
-
要求1:为Pacman编写代码,使得Pacman可以基于MDP来做出决策,躲避Ghost,并成功完成游戏。
-
要求2:不可以显式地告诉Pacman要往哪走,即不可以直接修改utility来影响Pacman的决策,或直接控制Pacman的移动。
-
要求3:只得通过Pacman项目提供的api来获取数据和信息,不得访问除该方式外获得的数据或修改任何除mdpAgents.py外的文件。不得使用除了MDP外的算法完成游戏,如Reinforcement Learning中的Q-Learning。
-
Your code must be based on solvin g the Pacman environment as an MDP. If y ou don’t submit a p ro g ram that contains a reco g nisable MDP solver, y ou will lose marks.
The onl y MDP solvers we will allow are the ones p resented in the lecture, i.e., Value iteration, Polic y iteration and Modified p olic y iteration. In p articular, Q -Learnin g is unacce p table.
Your code must only use the results of the MDP solver to decide what to do. If y ou submit code which makes decisions about what to do that uses other information in addition to what the MDP-solver g enerates ( like ad-hoc g host avoidin g code, for exam p le ) , y ou will lose marks. This is to ensure that y our MDP-solver is
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 295
295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









