







0. 关于Hystrix
Hystrix是Netflix的一个组件,其本身已经处于维护状态;Hystrix的仪表盘Hystrix Dashboard已经停止维护,处于启用状态,对于服务熔断,可以使用sentinel组件。本篇主要介绍微服务中的一些重要概念,以及Hystrix组件的基本使用。
1. 微服务中的重要概念
1.1 服务雪崩
在微服务之间进行服务调用是由于某一个服务故障,导致级联服务故障的现象,称为雪崩效应。雪崩效应描述的是提供方不可用,导致消费方不可用并将不可用逐渐放大的过程。
图解:
如存在如下调用链路:

而此时,Service A的流量波动很大,流量经常会突然性增加!那么在这种情况下,就算Service A能扛得住请求,Service B和Service C未必能扛得住这突发的请求。此时,如果Service C因为抗不住请求,变得不可用。那么Service B的请求也会阻塞,慢慢耗尽Service B的线程资源,Service B就会变得不可用。紧接着,Service A也会不可用,最终导致整个调用链路不可用,这一过程如下图所示
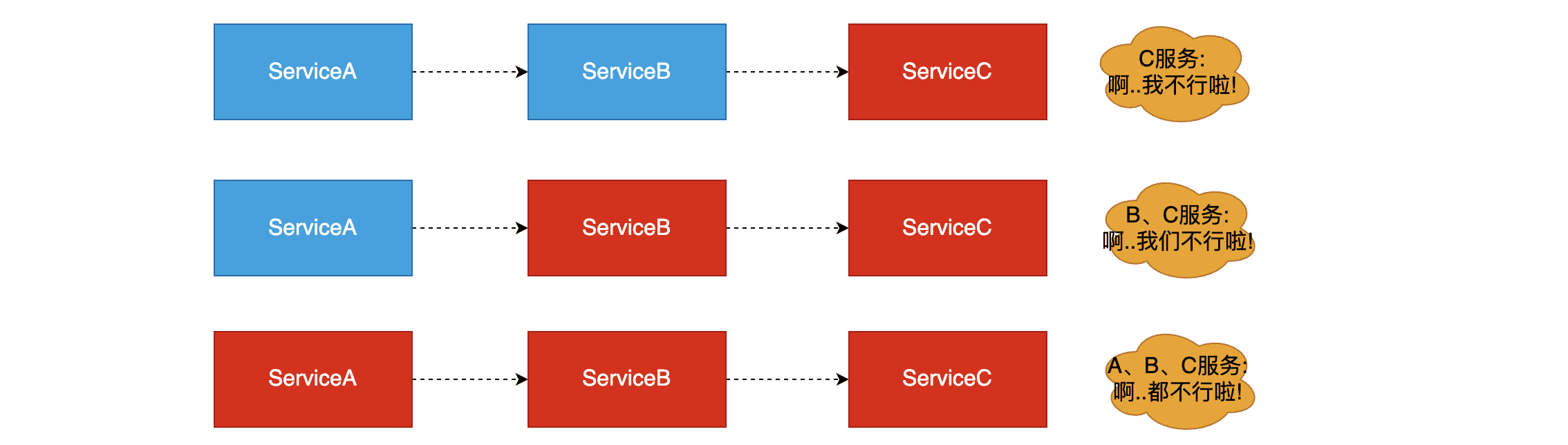
在集群部署的情况下,一个节点不可用,由于负载均衡,之后的请求会被分发到剩余可用的节点,导致他们负担加重,进而可能导致整个服务都不可用。
1.2 服务熔断
如何解决微服务系统的服务雪崩问题?——服务熔断
服务熔断——Hystrix——保险丝/熔断器/断路器/监控器
作用:用来在微服务系统中防止服务雪崩现象出现的
熔断机制:所有微服务中必须引入Hystrix组件(不同微服务有自己的Hystrix)
“熔断器”本身是一种开关装置,当某个服务单元发生故障之后,通过断路器(hystrix)的故障监控,某个异常条件被触发,直接熔断整个服务(集群中的一个节点)。向调用方法返回一个符合预期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方法无法处理的异常,就保证了服务调用方的线程不会被长时间占用,避免故障在分布式系统中蔓延,乃至雪崩。如果目标服务情况好转则恢复调用。服务熔断是解决服务雪崩的重要手段。
注意:服务熔断,熔断的是微服务间的调用(外部访问),而不是关闭/停止该服务本身运行。熔断一定时间,使得该服务有时间处理自身堆积的请求。
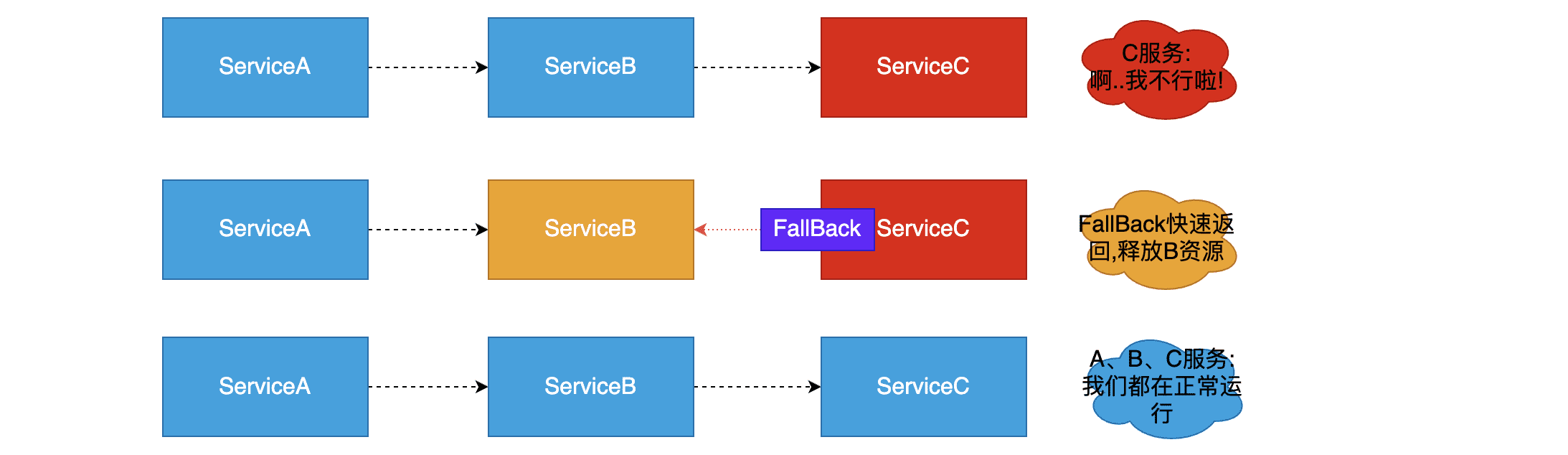
断路器
打开
- 当满足一定的阀值的时候(默认10秒内超过20个请求次数)
- 当失败率达到一定的时候(默认10秒内超过50%的请求失败)
到达以上阀值(同时满足条件1和2),断路器将会开启;当断路器开启的时候,所有请求都不会进行转发
关闭
- 一段时间之后(默认是5秒),这个时候断路器是半开状态,会让其中一个请求进行转发。如果成功,断路器会关闭,若失败,继续开启。重复4和5。
面试
面试重点问题: 断路器流程
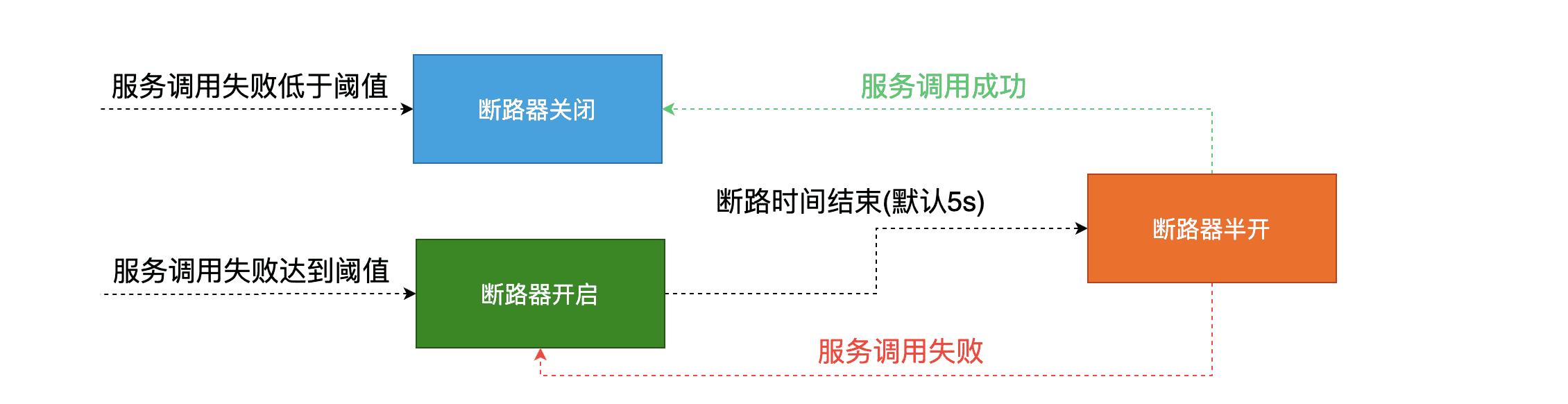
1.3 服务降级
服务压力剧增的时候根据当前的业务情况及流量对一些服务(边缘)和页面有策略的降级,以此缓解服务器的压力,以保证核心任务的进行。同时保证部分甚至大部分任务客户能得到正确的响应。也就是当前的请求处理不了了或者出错了,给一个默认的返回。
服务降级是站在整个系统架构的角度,对服务的保护;服务熔断是站在服务调用链,对链路中服务的保护。
举例:双十一的时候订单量特别大,订单服务可能负荷非常大,我们可以有策略地关闭一些订单相关的边缘服务的,比如:修改查询所有订单为只查询前100条;关闭订单评价功能…来保证下单服务可以正常运作。
1.4 降级和熔断总结
共同点
- 目的很一致,都是从可用性可靠性着想,为防止系统的整体缓慢甚至崩溃,采用的技术手段;
- 最终表现类似,对于两者来说,最终让用户体验到的是某些功能暂时不可达或不可用;
- 粒度一般都是服务级别,当然,业界也有不少更细粒度的做法,比如做到数据持久层(允许查询,不允许增删改);
- 自治性要求很高,熔断模式一般都是服务基于策略的自动触发,降级虽说可人工干预,但在微服务架构下,完全靠人显然不可能,开关预置、配置中心都是必要手段;sentinel
不同点
- 触发原因不太一样,服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑;
- 管理目标的层次不太一样,熔断其实是一个框架级的处理,每个微服务都需要(无层级之分),而降级一般需要对业务有层级之分(比如降级一般是从最外围服务边缘服务开始)
总结
- 熔断必会触发降级,所以熔断也是降级一种,区别在于熔断是对调用链路的保护,而降级是对系统过载的一种保护处理
2. Hystrix(维护状态)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8cerWCZG-1649011570669)(https://cdn.jsdelivr.net/gh/zewei94yomi/ImageLoader@master/uPic/pkNXi7.jpg)]
2.1 简介
在分布式环境中,许多服务依赖项不可避免地会失败。Hystrix是一个库,它通过添加延迟容忍和容错逻辑来帮助您控制这些分布式服务之间的交互。Hystrix通过隔离服务之间的访问点、停止它们之间的级联故障以及提供后备选项来实现这一点,所有这些都可以提高系统的整体弹性。
通俗定义: Hystrix是一个用于处理分布式系统的延迟和容错的开源库,在分布式系统中,许多依赖不可避免的会调用失败,超时、异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整体服务失败,避免级联故障(服务雪崩现象),提高分布式系统的弹性。
作用:用来防止微服务系统中服务雪崩现象,实现服务熔断
2.2 使用
服务端
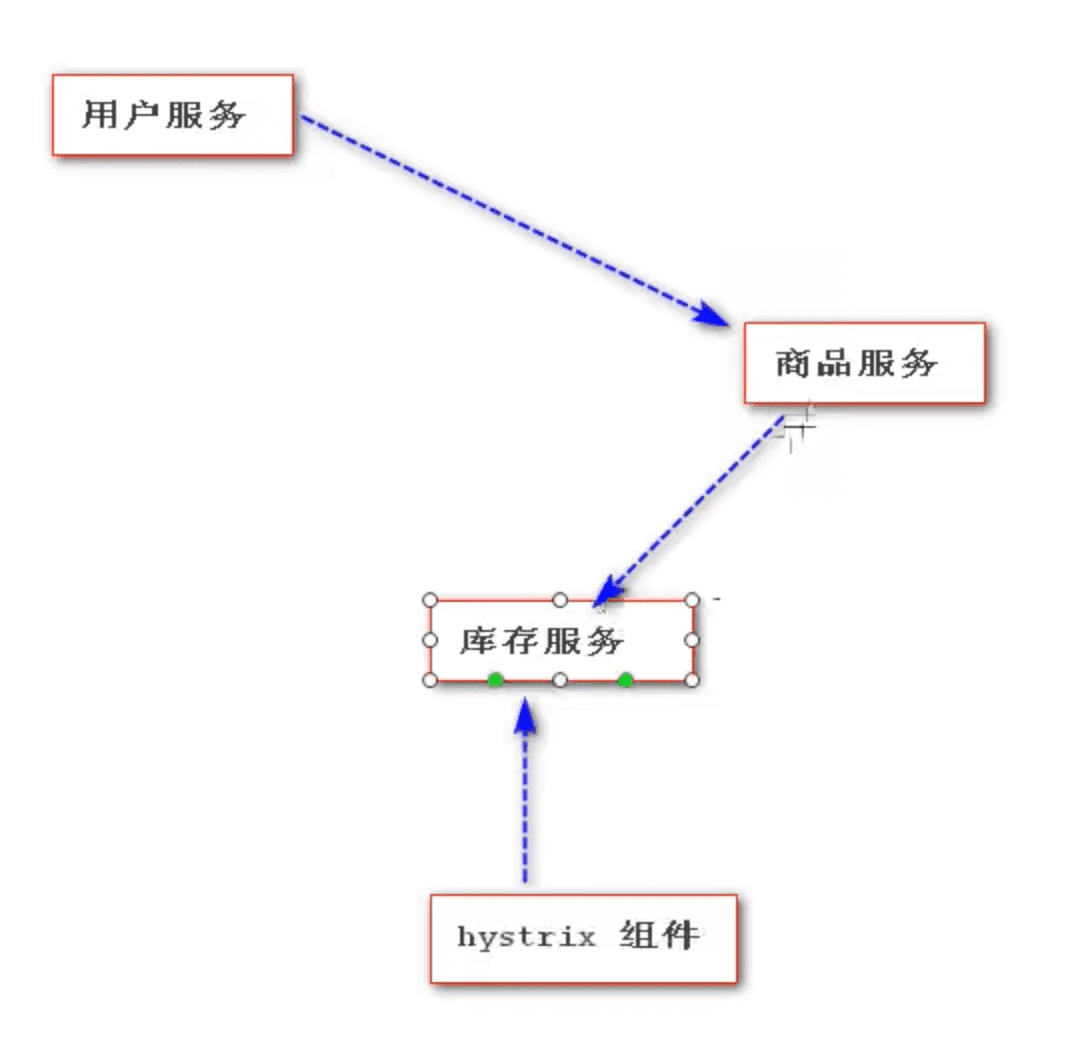
假设现在有这样一个场景:“用户服务”会调用“商品服务”,“商品服务”会调用“库存服务”。我们希望给“库存服务”添加一个Hystrix组件来监控并实现服务熔断功能。
-
这里出于演示目的,创建一个单独项目
springcloud_08_hystrix -
引入Hystrix依赖(希望哪个服务被监控,就引入该依赖;注意是netflix下的hystrix)
<dependencies> <!--springboot--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--consul--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-consul-discovery</artifactId> </dependency> <!--actuator--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <!--Hystrix--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix</artifactId> </dependency> </dependencies> -
配置文件
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 218
218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









