







 本文探讨了条件模仿学习在复杂城市驾驶中的应用,通过结合专家意图的表示来解决仅依赖感官输入的模糊性问题。模型在训练时接收观察、控制信号和专家意图,测试时可以通过指令影响控制器行为,实现更可控的驾驶策略。通过对比实验,证明了使用命令分支架构的网络优于直接将命令作为输入的架构,提高了模型的性能和鲁棒性。
本文探讨了条件模仿学习在复杂城市驾驶中的应用,通过结合专家意图的表示来解决仅依赖感官输入的模糊性问题。模型在训练时接收观察、控制信号和专家意图,测试时可以通过指令影响控制器行为,实现更可控的驾驶策略。通过对比实验,证明了使用命令分支架构的网络优于直接将命令作为输入的架构,提高了模型的性能和鲁棒性。
End-to-end Driving via Conditional Imitation Learning
模仿学习的一个假设: 最优的动作可以由观察推断出来。但是实际显然是不成立的,就好比在面对十字路口时,单凭摄像头图像不足以得出汽车改左转、右转还是直行。从数学函数的角度来说,输入的图像到输出的控制不再是一一映射了。所以单单使用神经网络处理会遇到困难,导致震荡。就算神经网络可以解决一些模糊性,但也可能得不到人类想要的结果。
本文采用一个条件模仿学习来解决这个问题。在训练时,模型不仅给出了感官输入和控制信号,而且给出了“专家意图”的表示。测试阶段,把一个“指令”传给网络,从而解决神经网络映射的模糊性(这个指令由司机或者是乘客给出)。通过这种方式,就可以把网络和具体任务解耦,从而使得网络的表达能力专注于决策上。
本文开发一个命令条件式的模仿学习,使模仿学习能够应用于更复杂的城市驾驶。模型不仅学会了控制方向盘,还学会了加速和刹车。
在强化学习中,层次方法旨在构造多个层次的时间扩展子策略。options框架就是这种层次分解的一个突出例子。在这个框架中学习的基本运动控制可以在不同的任务之间转换。分层方法也与深度学习相结合,并应用于原始的感官输入。这些都是单纯地从经验中学习,自动发现层次结构。这是一个困难、开放的问题,特别是对于复杂的感觉运动控制。本文关注的是模仿学习,在演示过程中提供专家意图的信息。这个过程使学习问题更容易处理,并产生人为可控的策略。
在每个时间步t,控制器接收到一个观察 O 并采取动作 a 。模仿学习的基本思想是:训练一个能够模仿专家的控制器。训练数据是由专家生成的action-observation-pairs
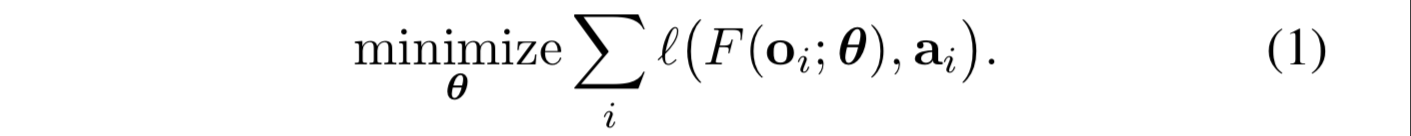
这背后隐含的假设是:专家的行动可以完全由observation解释——即存在一个:将Ot 映射到action的函数
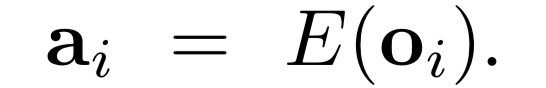
如果这个假设成立&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









