







一、bthread
std::vector<bthread_t> bids;
bids.resize(repeated_ops.size());
std::vector<ItemFeaturesProcessInfo> infos;
infos.reserve(repeated_ops.size());
for (auto& p : repeated_ops) {
ItemFeaturesProcessInfo info(p.second);
info.start_ = start;
info.end_ = end;
info.context_ = context;
info.features_ = features;
infos.emplace_back(info);
}
for (int i = 0; i < repeated_ops.size(); i++) {
if (bthread_start_background(&bids[i], NULL, GenerateItemFeatures, &infos[i]) != 0) {
LOG_ERROR(-1, "Failed to create generate item features bthread");
continue;
}
}
for (int i = 0; i < bids.size(); i++) {
bthread_join(bids[i], NULL);
}
// 执行函数
void* XgbFeatureGenerator::GenerateItemFeatures(void* arg) {
ItemFeaturesProcessInfo* info = (ItemFeaturesProcessInfo*)arg;
int start = info->start_;
int end = info->end_;
auto* context = info->context_;
std::vector<int> time_recorder(info->ops_.size(), 0);
for (int i = start; i < end; i++) {
for (int j = 0; j < info->ops_.size(); j++) {
int64_t begin_time = ckit::time::GetCurrentUs();
Operator* op = info->ops_[j];
std::vector<float> value = op->ComputeXgbFeature(context, i);
if (value.size() != op->feature_map_.size()) {
LOG_ERROR(-1,
"The number of features and names produced by the operator [%s] is not equal",
op->feature_name_.c_str());
continue;
}
for (auto& f : op->feature_map_) {
if (f.second.xgb_index != -1) {
context->SetXgbFeature(i - start, f.second.xgb_index, value[f.second.inner_index],
info->features_);
}
context->SetOutputFeature(i - start, f.second.output_index, value[f.second.inner_index],
info->features_);
}
time_recorder[j] += (ckit::time::GetCurrentUs() - begin_time);
}
}
for (int i = 0; i < info->ops_.size(); i++) {
info->ops_[i]->op_rt_->RecordTimer(time_recorder[i]);
}
}
btread 使用
bthread是百度开源的一种轻量级高可靠线程库,常用于替代pthread进行线程编程。以下是bthread使用的基本流程:
- 引入bthread头文件
#include “bthread.h” - 定义线程函数
void* thread_func(void* arg) {
// 线程执行的代码
}
- 创建线程
其中,attr是一个结构体类型的参数,可以设定线程的属性,如线程的栈大小、优先级等。
bthread_t thread;
bthread_attr_t attr;
bthread_attr_init(&attr);
bthread_create(&thread, &attr, thread_func, arg);
- 等待线程结束
bthread_join(thread, NULL);
此函数会等待线程执行完成,并回收线程资源。
bthread也提供了其他一些常用的函数,如互斥锁(bthread_mutex_t)、信号量(bthread_sem_t)等等,可以根据需要进行使用。需要注意的是,bthread只能在Linux环境下运行。
总的来说,bthread具有编程简单、高可靠性、高性能等特点,适合于对线程编程有一定了解的开发者进行使用。
二、重点组件:
TaskControl
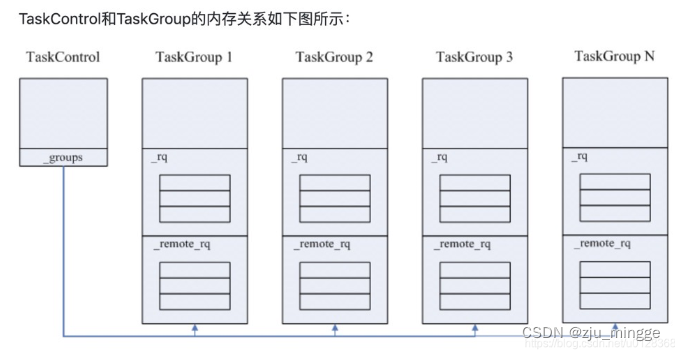
TaskControl用来管理整个进程的所有TaskGroup.
class TaskControl {
friend class TaskGroup;
public:
TaskControl();
~TaskControl();
int init(int nconcurrency);
TaskGroup* create_group();
bool steal_task(bthread_t* tid, size_t* seed, size_t offset);
void signal_task(int num_task);
void stop_and_join();
int concurrency() const
{ return _concurrency.load(butil::memory_order_acquire); }
void print_rq_sizes(std::ostream& os);
double get_cumulated_worker_time();
int64_t get_cumulated_switch_count();
int64_t get_cumulated_signal_count();
int add_workers(int num);
TaskGroup* choose_one_group();
private:
// Add/Remove a TaskGroup.
// Returns 0 on success, -1 otherwise.
int _add_group(TaskGroup*);
int _destroy_group(TaskGroup*);
static void delete_task_group(void* arg);
static void* worker_thread(void* task_control);
std::atomic<size_t> _ngroup;
TaskGroup** _groups;
butil::Mutex _modify_group_mutex;
bool _stop;
std::atomic<int> _concurrency;
std::vector<pthread_t> _workers;
butil::Mutex _pending_time_mutex;
static const int PARKING_LOT_NUM = 4;
ParkingLot _pl[PARKING_LOT_NUM];
};
初始化
通过指定线程的数量进行初始化
int TaskControl::init(int concurrency) {
if (_concurrency != 0) {
LOG(ERROR) << "Already initialized";
return -1;
}
if (concurrency <= 0) {
LOG(ERROR) << "Invalid concurrency=" << concurrency;
return -1;
}
_concurrency = concurrency;
if (get_or_create_global_timer_thread() == NULL) {
LOG(ERROR) << "Fail to get global_timer_thread";
return -1;
}
_workers.resize(_concurrency);
for (int i = 0; i < _concurrency; ++i) {
const int rc = pthread_create(&_workers[i], NULL, worker_thread, this);
if (rc) {
LOG(ERROR) << "Fail to create _workers[" << i << "], " << berror(rc);
return -1;
}
}
_worker_usage_second.expose("bthread_worker_usage");
_switch_per_second.expose("bthread_switch_second");
_signal_per_second.expose("bthread_signal_second");
_status.expose("bthread_group_status");
while (_ngroup == 0) {
usleep(100); // TODO: Elaborate
}
return 0;
}
worker_thread
void* TaskControl::worker_thread(void* arg) {
TaskControl* c = static_cast<TaskControl*>(arg);
TaskGroup* g = c->create_group();
TaskStatistics stat;
tls_task_group = g;
c->_nworkers << 1;
g->run_main_task();
stat = g->main_stat();
tls_task_group = NULL;
g->destroy_self();
c->_nworkers << -1;
return NULL;
}
create_group
TaskGroup* TaskControl::create_group() {
TaskGroup* g = new (std::nothrow) TaskGroup(this);
if (NULL == g) {
LOG(FATAL) << "Fail to new TaskGroup";
return NULL;
}
if (g->init(FLAGS_task_group_runqueue_capacity) != 0) {
LOG(ERROR) << "Fail to init TaskGroup";
delete g;
return NULL;
}
if (_add_group(g) != 0) {
delete g;
return NULL;
}
return g;
}
_add_group
int TaskControl::_add_group(TaskGroup* g) {
if (__builtin_expect(NULL == g, 0)) {
return -1;
}
std::unique_lock<butil::Mutex> mu(_modify_group_mutex);
if (_stop) {
return -1;
}
size_t ngroup = _ngroup.load(butil::memory_order_relaxed);
if (ngroup < (size_t)BTHREAD_MAX_CONCURRENCY) {
_groups[ngroup] = g;
_ngroup.store(ngroup + 1, butil::memory_order_release);
}
mu.unlock();
return 0;
}
从随机线程获取任务
steal_task()随机从一个TaskGroup的两种队列(优先本地队列)中偷取任务。
bool TaskControl::steal_task(bthread_t* tid, size_t* seed, size_t offset) {
const size_t ngroup = _ngroup.load(butil::memory_order_acquire/*1*/);
if (0 == ngroup) {
return false;
}
bool stolen = false;
size_t s = *seed;
for (size_t i = 0; i < ngroup; ++i, s += offset) {
TaskGroup* g = _groups[s % ngroup];
// g is possibly NULL because of concurrent _destroy_group
if (g) {
if (g->_rq.steal(tid)) {
stolen = true;
break;
}
if (g->_remote_rq.pop(tid)) {
stolen = true;
break;
}
}
}
*seed = s;
return stolen;
}
唤醒worker线程
signal_task()随机唤醒至多2个工作线程,实际上是随机选取一个ParkingLot然后从它开始尝试从其中唤醒一个线程。
如果没有成功唤醒到足够数量的线程且当前线程数小于最大数,将调用add_workers()创建一个工作线程。
void TaskControl::signal_task(int num_task) {
if (num_task <= 0) {
return;
}
if (num_task > 2) {
num_task = 2;
}
int start_index = butil::fmix64(pthread_numeric_id()) % PARKING_LOT_NUM;
num_task -= _pl[start_index].signal(1);
if (num_task > 0) {
for (int i = 1; i < PARKING_LOT_NUM && num_task > 0; ++i) {
if (++start_index >= PARKING_LOT_NUM) {
start_index = 0;
}
num_task -= _pl[start_index].signal(1);
}
}
if (num_task > 0 &&
FLAGS_bthread_min_concurrency > 0 && // test min_concurrency for performance
_concurrency.load(butil::memory_order_relaxed) < FLAGS_bthread_concurrency) {
// TODO: Reduce this lock
BAIDU_SCOPED_LOCK(g_task_control_mutex);
if (_concurrency.load(butil::memory_order_acquire) < FLAGS_bthread_concurrency) {
add_workers(1);
}
}
}
销毁
首先将TaskGroup数组清空,然后向每个ParkingLot设置stop标记位。然后调用interrupt_pthread()
interrupt_pthread()实质上是先设置为SIGURG设置为什么都不做的handler,然后调用pthread_kill向各线程发送信号以唤醒各个线程。
void TaskControl::stop_and_join() {
// Stop workers
{
BAIDU_SCOPED_LOCK(_modify_group_mutex);
_stop = true;
_ngroup.exchange(0, butil::memory_order_relaxed);
}
for (int i = 0; i < PARKING_LOT_NUM; ++i) {
_pl[i].stop();
}
// Interrupt blocking operations.
for (size_t i = 0; i < _workers.size(); ++i) {
interrupt_pthread(_workers[i]);
}
// Join workers
for (size_t i = 0; i < _workers.size(); ++i) {
pthread_join(_workers[i], NULL);
}
}
void do_nothing_handler(int) {}
static pthread_once_t register_sigurg_once = PTHREAD_ONCE_INIT;
static void register_sigurg() {
signal(SIGURG, do_nothing_handler);
}
int interrupt_pthread(pthread_t th) {
pthread_once(®ister_sigurg_once, register_sigurg);
return pthread_kill(th, SIGURG);
}
TaskGroup:
TaskGroup为每个pthread持有一个单例,用来管理和运行任务。
结构
class TaskGroup {
public:
static int start_foreground(TaskGroup** pg,
bthread_t* __restrict tid,
const bthread_attr_t* __restrict attr,
void * (*fn)(void*),
void* __restrict arg);
// Create task `fn(arg)' with attributes `attr' in this TaskGroup, put the
// identifier into `tid'. Schedule the new thread to run.
// Called from worker: start_background<false>
// Called from non-worker: start_background<true>
// Return 0 on success, errno otherwise.
template <bool REMOTE>
int start_background(bthread_t* __restrict tid,
const bthread_attr_t* __restrict attr,
void * (*fn)(void*),
void* __restrict arg);
// Suspend caller and run next bthread in TaskGroup *pg.
static void sched(TaskGroup** pg);
static void ending_sched(TaskGroup** pg);
// Suspend caller and run bthread `next_tid' in TaskGroup *pg.
// Purpose of this function is to avoid pushing `next_tid' to _rq and
// then being popped by sched(pg), which is not necessary.
static void sched_to(TaskGroup** pg, TaskMeta* next_meta);
static void sched_to(TaskGroup** pg, bthread_t next_tid);
static void exchange(TaskGroup** pg, bthread_t next_tid);
private:
TaskMeta* _cur_meta;
// the control that this group belongs to
TaskControl* _control;
int _num_nosignal;
int _nsignaled;
// last scheduling time
int64_t _last_run_ns;
int64_t _cumulated_cputime_ns;
size_t _nswitch;
RemainedFn _last_context_remained;
void* _last_context_remained_arg;
ParkingLot* _pl; // 使用ParkingLot来管理闲置worker线程,我们进程总共设立了4个ParkingLot减少竞争
ParkingLot::State _last_pl_state;
size_t _steal_seed;
size_t _steal_offset;
ContextualStack* _main_stack;
bthread_t _main_tid;
WorkStealingQueue<bthread_t> _rq;
RemoteTaskQueue _remote_rq;
int _remote_num_nosignal;
int _remote_nsignaled;
int _sched_recursive_guard;
};
本地任务队列
WorkingStealingQueue是个固定大小的无锁循环队列,采用它来实现本地任务队列,只有该线程会向其中push和pop任务,其他线程调用的是steal()方法。
远程任务队列
由于远程任务队列不会那么频繁被本地线程访问,且更多的是被其他线程访问,所以采用一个加锁的有界循环队列实现远程任务队列。
worker线程的主循环
void TaskGroup::run_main_task() {
TaskGroup* dummy = this;
bthread_t tid;
while (wait_task(&tid)) {
TaskGroup::sched_to(&dummy, tid);
DCHECK_EQ(this, dummy);
DCHECK_EQ(_cur_meta->stack, _main_stack);
if (_cur_meta->tid != _main_tid) {
TaskGroup::task_runner(1/*skip remained*/);
}
}
// Don't forget to add elapse of last wait_task.
current_task()->stat.cputime_ns += butil::cpuwide_time_ns() - _last_run_ns;
}
bool TaskGroup::wait_task(bthread_t* tid) {
do {
if (_last_pl_state.stopped()) {
return false;
}
_pl->wait(_last_pl_state);//1
if (steal_task(tid)) {
return true;
}
} while (true);
}
bool steal_task(bthread_t* tid) {
if (_remote_rq.pop(tid)) {
return true;
}
_last_pl_state = _pl->get_state();
return _control->steal_task(tid, &_steal_seed, _steal_offset);
}
last_pl_state初始为0,而_pl._pending_signal初始也为0,_last_pl_state.value的最后一位表示是否结束主循环。wait_task()中的1处,_last_pl_state.value必须等于_pl.pending_signal才会wait成功。从wait中返回时,实际上是其他线程调用相应ParkingLot中的signal唤醒了线程,尝试从_rq中获取一个任务。
紧接着,将调用sched_to切换至获取的bthread中执行。联想一下,最初的main_stack的f_context指针为NULL,调用jump_stack()后会保存上下文,同时把当前栈指针保存在第一个参数中。需要注意的是,由于TaskMeta在各个线程中可能跳来跳去,所以切换回他们(非_main_meta)需要重新设置TaskGroup指针。这一点在后面的函数中也是同样的,后面就不加说明了。注意在点用jump_stack()之前会首先检查栈是否相同,因为end_sched()中对相同的栈类型的任务进行了栈复用,这时便不需要进行切换。tls_bls用来保存任务产生的数据的,任务之间的交互需要他们,详细的管理留待后面章节讲述。额外的步骤是每次切换需要保存和更新tls_bls。从切换的任务切换回来后,可能有待执行的指令,于是执行他们。
sched_to
inline void TaskGroup::sched_to(TaskGroup** pg, bthread_t next_tid) {
TaskMeta* next_meta = address_meta(next_tid); // 获取meta
if (next_meta->stack == NULL) {
ContextualStack* stk = get_stack(next_meta->stack_type(), task_runner); // 获取stack
if (stk) {
next_meta->set_stack(stk);
} else {
// stack_type is BTHREAD_STACKTYPE_PTHREAD or out of memory,
// In latter case, attr is forced to be BTHREAD_STACKTYPE_PTHREAD.
// This basically means that if we can't allocate stack, run
// the task in pthread directly.
next_meta->attr.stack_type = BTHREAD_STACKTYPE_PTHREAD;
next_meta->set_stack((*pg)->_main_stack);
}
}
// Update now_ns only when wait_task did yield.
sched_to(pg, next_meta); // 调度
}
TaskGroup Interface(基本函数,用户不可见)
切线程相关
sched:
放队列相关
ready_to_run(bth):第1个动作把bth放到_rq,第2个动作调signal_task去唤醒一个任务去执行该bth
ready_to_run_remote:第1个动作加锁,第2个动作把bth放到_remote_rq,第3个动作调signal_task去唤醒一个任务去执行该bth
补充:上述两个函数都有个参数signal,当新push一个bth时,会判断是否需要signal去提醒其他worker去偷,比如当前_rq很忙,我就希望别的赶紧来偷
TaskMeta:表征bthread上下文的真实结构体。
bthread用户接口和代码执行路径
bthread_t(类似pthread_t):64位int,前32位版本号防止ABA问题(释放后又重新被分配了,歧义),后32位为资源池(无全局竞争可O(1)访问的数组)中下标,可以很快地找到TaskMeta
bthread_start_urgent & bthread_start_background 里面都是先判断g是否为空(是否运行在worker里),是的话运行start_xxx,不是运行start_from_non_worker(直接调用start_background)
start_foreground:如果当前在bthread内,就在当前worker内原地启动(调ready_to_run或ready_to_run_remote)保证locality,把当前bth加到_rq队尾,再去跑新bthread,实现:set_remained(ready_to_run(current_bth)) + sched_to(new_bth)
start_background:后台起,但是不希望立刻跑这个bthread,将来有时间跑就行,直接调ready_to_run把新bth加到_rq队尾,如果是在start_from_non_worker里起就加到_remote_rq,实现:ready_to_run_remote
// 让出当前worker立即执行新bthread,当前bthread随后调度
int bthread_start_urgent(bthread_t* __restrict tid,
const bthread_attr_t* __restrict attr,
void * (*fn)(void*),
void* __restrict arg) __THROW {
bthread::TaskGroup* g = bthread::tls_task_group;
if (g) {
// 从worker里起的bthread,调ready_to_run,再主动调一遍sched_to去执行这个tid
return bthread::TaskGroup::start_foreground(&g, tid, attr, fn, arg);
}
// 一些初始化的工作,最后会创建1个TC、4个PL、9个pthread、9个TG
return bthread::start_from_non_worker(tid, attr, fn, arg);
}
// 放到队列里,不急着切线程(sched_to)
int bthread_start_background(bthread_t* __restrict tid,
const bthread_attr_t* __restrict attr,
void * (*fn)(void*),
void* __restrict arg) __THROW {
bthread::TaskGroup* g = bthread::tls_task_group;
if (g) {
// 从worker里起的bthread,调ready_to_run
return g->start_background<false>(tid, attr, fn, arg);
}
// 同上
return bthread::start_from_non_worker(tid, attr, fn, arg);
}
start_from_non_worker(bthread_t* __restrict tid,
const bthread_attr_t* __restrict attr,
void * (*fn)(void*),
void* __restrict arg) {
// 核心函数:创建TaskGroup,见下
TaskControl* c = get_or_new_task_control();
...
// 选择一个TaskGroup执行start_background<true>,调ready_to_run_remote
return c->choose_one_group()->start_background<true>(
tid, attr, fn, arg);
}
inline TaskControl* get_or_new_task_control() {
// 全局变量TC(g_task_control)初始化原子变量
butil::atomic<TaskControl*>* p = (butil::atomic<TaskControl*>*)&g_task_control;
// 通过原子变量进行load,取出TC指针,如果不为空,直接返回
TaskControl* c = p->load(butil::memory_order_consume);
if (c != NULL) {
return c;
}
...
// 走到这,说明TC确实为NULL,开始new一个
c = new (std::nothrow) TaskControl;
if (NULL == c) {
return NULL;
}
// 用并发度concurrency来初始化全局TC
int concurrency = FLAGS_bthread_min_concurrency > 0 ?
FLAGS_bthread_min_concurrency :
FLAGS_bthread_concurrency;
// init函数核心见下
if (c->init(concurrency) != 0) {
LOG(ERROR) << "Fail to init g_task_control";
delete c;
return NULL;
}
// 4. 将全局TC存入原子变量中
p->store(c, butil::memory_order_release);
return c;
}
// TaskControl的init函数
for (int i = 0; i < _concurrency; ++i) {
const int rc = pthread_create(&_workers[i], NULL, worker_thread, this);
if (rc) {
LOG(ERROR) << "Fail to create _workers[" << i << "], " << berror(rc);
return -1;
}
}
// worker_thread之前有过说明
若TaskGroup为空,证明当前是跑在pthread上,调用start_from_non_worker检查是否已经创建了TackControl单例,已经创建就无所谓了,没有就new TaskControl去创建,new后会执行TackControl的init,核心就是用pthread启动指定数量的worker。得到TackControl单例后,用TackControl选取一个TackGroup,新建bthread进行调度;TaskGroup不为空,表明此bthread就是在worker内被创建的,在对应TackGroup(worker)执行新bthread的启动即可。
TC创建后会pthread_create 9个线程去初始化TG,避免全局变量加锁处理,效率低,也要避免惊群。一旦出现某一个bthread可以被偷了会唤醒很多worker,会发生惊群,要处理。
void* TaskControl::worker_thread(void* arg) {
// 获取TC指针
TaskControl* c = static_cast<TaskControl*>(arg);
// 创建一个task_group
TaskGroup* g = c->create_group();
TaskStatistics stat;
if (NULL == g) {
LOG(ERROR) << "Fail to create TaskGroup in pthread=" << pthread_self();
return NULL;
}
// 重要变量,定义BAIDU_THREAD_LOCAL TaskGroup* tls_task_group;
// tls_task_group是一个thread_local变量,且只有由TaskControl启动的worker线程所拥有的task_group tls_task_group非null
tls_task_group = g;
// 计数+1
c->_nworkers << 1;
// 当前线程主要运行的任务,即死循环中等待唤醒
g->run_main_task();
// ...
// 销毁
tls_task_group = NULL;
g->destroy_self();
c->_nworkers << -1;
return NULL;
}
TaskControl::create_group()
这里我们先创建了一个TG,然后用TaskGroup::init进行初始化大小。然后用_add_group判断非工作线程,如果是则delete,这里我们先看到TaskGroup::init函数。
TaskGroup* TaskControl::create_group() {
TaskGroup* g = new (std::nothrow) TaskGroup(this);
if (NULL == g) {
LOG(FATAL) << "Fail to new TaskGroup";
return NULL;
}
if (g->init(FLAGS_task_group_runqueue_capacity) != 0) {
LOG(ERROR) << "Fail to init TaskGroup";
delete g;
return NULL;
}
if (_add_group(g) != 0) {
delete g;
return NULL;
}
return g;
}
TaskGroup::init
这里我们可以看到这个函数用runqueue_capacity来控制这rq和remote_rq队列的大小。而这个数值的默认值为4096,然后进行get_stack()操作。进行完get_stack()操作之后,然后建立资源池slot,然后从资源池中获取TM。
int TaskGroup::init(size_t runqueue_capacity) {
if (_rq.init(runqueue_capacity) != 0) {
LOG(FATAL) << "Fail to init _rq";
return -1;
}
if (_remote_rq.init(runqueue_capacity / 2) != 0) {
LOG(FATAL) << "Fail to init _remote_rq";
return -1;
}
ContextualStack* stk = get_stack(STACK_TYPE_MAIN, NULL);
if (NULL == stk) {
LOG(FATAL) << "Fail to get main stack container";
return -1;
}
butil::ResourceId<TaskMeta> slot;
TaskMeta* m = butil::get_resource<TaskMeta>(&slot);
if (NULL == m) {
LOG(FATAL) << "Fail to get TaskMeta";
return -1;
}
m->stop = false;
m->interrupted = false;
m->about_to_quit = false;
m->fn = NULL;
m->arg = NULL;
m->local_storage = LOCAL_STORAGE_INIT;
m->cpuwide_start_ns = butil::cpuwide_time_ns();
m->stat = EMPTY_STAT;
m->attr = BTHREAD_ATTR_TASKGROUP;
m->tid = make_tid(*m->version_butex, slot);
m->set_stack(stk);
_cur_meta = m;
_main_tid = m->tid;
_main_stack = stk;
_last_run_ns = butil::cpuwide_time_ns();
return 0;
}
get_stack
inline ContextualStack* get_stack(StackType type, void (*entry)(intptr_t)) {
switch (type) {
case STACK_TYPE_PTHREAD:
return NULL;
case STACK_TYPE_SMALL:
return StackFactory<SmallStackClass>::get_stack(entry);
case STACK_TYPE_NORMAL:
return StackFactory<NormalStackClass>::get_stack(entry);
case STACK_TYPE_LARGE:
return StackFactory<LargeStackClass>::get_stack(entry);
case STACK_TYPE_MAIN:
return StackFactory<MainStackClass>::get_stack(entry);
}
return NULL;
}
template <typename StackClass> struct StackFactory {
struct Wrapper : public ContextualStack {
explicit Wrapper(void (*entry)(intptr_t)) {
if (allocate_stack_storage(&storage, *StackClass::stack_size_flag,
FLAGS_guard_page_size) != 0) {
storage.zeroize();
context = NULL;
return;
}
context = bthread_make_fcontext(storage.bottom, storage.stacksize, entry);
stacktype = (StackType)StackClass::stacktype;
}
~Wrapper() {
if (context) {
context = NULL;
deallocate_stack_storage(&storage);
storage.zeroize();
}
}
};
static ContextualStack* get_stack(void (*entry)(intptr_t)) {
return butil::get_object<Wrapper>(entry);
}
static void return_stack(ContextualStack* sc) {
butil::return_object(static_cast<Wrapper*>(sc));
}
};
每个TG创建后会创建后当前线程的各种变量,然后去调 run_main_task 去循环等待是否有可处理的bthread。
run_main_task
void TaskGroup::run_main_task() {
bvar::PassiveStatus<double> cumulated_cputime(
get_cumulated_cputime_from_this, this);
std::unique_ptr<bvar::PerSecond<bvar::PassiveStatus<double> > > usage_bvar;
TaskGroup* dummy = this;
bthread_t tid;
while (wait_task(&tid)) {
TaskGroup::sched_to(&dummy, tid);
DCHECK_EQ(this, dummy);
DCHECK_EQ(_cur_meta->stack, _main_stack);
if (_cur_meta->tid != _main_tid) {
TaskGroup::task_runner(1/*skip remained*/);
}
if (FLAGS_show_per_worker_usage_in_vars && !usage_bvar) {
char name[32];
#if defined(OS_MACOSX)
snprintf(name, sizeof(name), "bthread_worker_usage_%" PRIu64,
pthread_numeric_id());
#else
snprintf(name, sizeof(name), "bthread_worker_usage_%ld",
(long)syscall(SYS_gettid));
#endif
usage_bvar.reset(new bvar::PerSecond<bvar::PassiveStatus<double> >
(name, &cumulated_cputime, 1));
}
}
// Don't forget to add elapse of last wait_task.
current_task()->stat.cputime_ns += butil::cpuwide_time_ns() - _last_run_ns;
}
TaskGroup::sched_to 切换栈
首先先通过传入的参数next_tid找到TM,next_meta,和对应的ContextualStack信息:stk。然后给next_meta设置栈stk。然后调用重载的sched_to函数。
// 2 用内核调用实现上下文的切换
inline void TaskGroup::sched_to(TaskGroup** pg, bthread_t next_tid) {
// 根据tid找TaskMeta
TaskMeta* next_meta = address_meta(next_tid);
// 给stk用next_meta赋一些值
if (next_meta->stack == NULL) {
ContextualStack* stk = get_stack(next_meta->stack_type(), task_runner);
// ...
}
// 重载的sched_to会判断next_meta和cur_meta是否为同一个不是同一个需要调jump_stack去切栈
// 这其中直接嵌入了汇编代码模拟pthread切栈操作
sched_to(pg, next_meta);
}
TaskGroup::sched_to
显示记录一些数据,判断下一个TM和当前TM是否相等,如果不相等,则去切换栈。tls_bls是当前TM的局部存储,先做还原,然后赋值成下一个TM的局部存储,然后jump_stack()去切换栈。至于jump_stack()涉及到汇编知识
在这里插入代码片
// 3 执行用户实际的func并找下一个
void TaskGroup::task_runner() {
TaskMeta* const m = g->_cur_meta;
// 执行应用程序设置的任务函数,在任务函数中可能yield让出cpu,也可能产生新的bthread
m->fn(m->arg);
// 任务函数执行完成后,需要唤起等待该任务函数执行结束的pthread/bthread
butex_wake_except(m->version_butex, 0);
// ending_sched函数本意:将pthread线程执行流转入下一个可执行的bthread(普通bthread或“调度bthread”)
// 在ending_sched()内会尝试从本地TaskGroup的rq队列中找出下一个bthread
// 或者调steal_task从其他pthread的TaskGroup上steal一个bthread(当然也是先看_remote_rq,再偷)
// 如果没有bthread可用则下一个被执行的就是pthread的“调度bthread”
// 然后通过sched_to()将pthread的执行流转入下一个bthread的任务函数
ending_sched(&g);
}
wait_task
wait_task就是等待找到任务,而这里就会涉及到工作窃取
bool TaskGroup::wait_task(bthread_t* tid) {
do {
#ifndef BTHREAD_DONT_SAVE_PARKING_STATE
if (_last_pl_state.stopped()) {
return false;
}
_pl->wait(_last_pl_state);
if (steal_task(tid)) {
return true;
}
} while (true);
}
steal_task
首先是_remote_rq队列中的任务出队,如果没有则全局TC来窃取任务。
bool steal_task(bthread_t* tid) {
if (_remote_rq.pop(tid)) {
return true;
}
#ifndef BTHREAD_DONT_SAVE_PARKING_STATE
_last_pl_state = _pl->get_state();
#endif
return _control->steal_task(tid, &_steal_seed, _steal_offset);
}
TaskControl::steal_task
先随机找一个TG,先从它的rq队列窃取任务,如果失败则从remote_rq队列窃取任务。所以说,rq比remote_rq的优先级更高。这里疑问就来了,为啥是这么个顺序?这里是为了避免资源竞态,避免多个TG等待任务的时候,当前TG从rq中取任务,与其他TG过来自己这边窃取任务造成竞态。
bool TaskControl::steal_task(bthread_t* tid, size_t* seed, size_t offset) {
// 1: Acquiring fence is paired with releasing fence in _add_group to
// avoid accessing uninitialized slot of _groups.
const size_t ngroup = _ngroup.load(butil::memory_order_acquire/*1*/);
if (0 == ngroup) {
return false;
}
// NOTE: Don't return inside `for' iteration since we need to update |seed|
bool stolen = false;
size_t s = *seed;
for (size_t i = 0; i < ngroup; ++i, s += offset) {
TaskGroup* g = _groups[s % ngroup];
// g is possibly NULL because of concurrent _destroy_group
if (g) {
if (g->_rq.steal(tid)) {
stolen = true;
break;
}
if (g->_remote_rq.pop(tid)) {
stolen = true;
break;
}
}
}
*seed = s;
return stolen;
}
以proxy为例首先在mixer-framework里已经调用过了bthread_start_background初始化一些必要的东西(TC、TG等),然后在send_minibs_request_impl函数中用bthread_start_background则是相当于在bthread内启动了一个新的bthread,想要执行函数func,由于这个新bth不是在pthread内起的,所以肯定会被放在该TaskGroup的_remote_rq中,然后,这个阻塞在wait_task上的TaskGroup会被唤醒,进入以下步骤取出tid来:
首先从本TaskGroup的_remote_rq队列中pop出一个tid(_remote_rq.pop(tid)),pop成功就直接返回
如果pop失败了,调用steal_task从其它TaskGroup中去偷一个tid,偷的顺序在上面
无论如何拿到tid后,进入TaskGroup::sched_to去切栈,具体栈跳跃步骤为:
1、调用jump_stack进入新的bthread栈,由于这时新的bthread还没有分配栈,会首先为它创建一个栈new_stack
2、新的bthread创建完后,利用bthread_jump_fcontext修改栈顶指针、各寄存器进入新栈new_stack,并记录跳转前的旧栈stack_main的相关内容
3、新栈的执行函数fn为TaskGroup::task_runner(注意这个就是用户的func,层层函数指针传入),这个task_runner主要会干3个事儿
执行用户实际的回调函数func(用户想让bthread干的事)
唤起等待该任务函数执行结束的pthread/bthread
ending_sched:尝试再pop出一个bthread来,如果现在没有新的bthread,就把_main_meta作为下一次的跳转对象(相当于返回去继续执行原来的代码),再次调用jump_stack由new_stack跳转入stack_main,相当于又拿到了一个tid继续运行
4、都运行完了继续下一次wait_task中的do while死循环,重新阻塞在_pl→wait(...)上















 1012
1012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









