






R10000是一个动态的、超标量的微处理器,它实现64位Mips 4指令集结构。它在每个周期中获取并解码4个指令,并动态地将它们发送到5个全流水线、低延迟执行单元。指令可以通过分支以外的方式获取和执行。指示按顺序排列。
通过推测性的执行,它可以计算内存地址,并在早期启动缓存重新填充。它的层次结构,非阻塞的内存系统(hierarchical, nonblocking memory system)有助于隐藏内存延迟与两级设置相关,write back cache.
为了处理无序的超标量处理器的复杂性,R10000使用了一种模块化设计,这种设计使用规则结构来定位大部分控制逻辑,包括活动列表、寄存器映射表和指令队列。
内存带宽和延迟限制了许多程序的性能。由于包装和系统成本限制了这些资源,处理器必须有效地使用它们。R10000实现了寄存器映射和非阻塞缓存,它们相互组合以重叠缓存填充操作。因此,如果一条指令在缓存中丢失,它必须等待它的操作数被重新填充,但是其他指令可以不按顺序继续执行。这增加了内存的使用并减少了有效的延迟,因为重新充值很早就开始了,并且在处理器执行其他指令时并行地进行四次充值,这种缓存设计称为“非阻塞”,因为cache refills 不会阻塞对其他缓存行的后续访问。
处理器依赖编译器来优化指令序列,不过,对于许多整数应用程序的标量值,编译器优化的效率较低,因为编译器很难预测哪些指令将生成cache misses。
R10000设计包括复杂的硬件,可以根据操作数的可用性动态地重新排序安装执行当缓存丢失延迟指令时,这个硬件会立即进行调整,处理器会预先查找32个指令,以找到可能的并行性。这个指令窗口足够大,可以隐藏从二级缓存中重新填充的大部分延迟,但是,它只能隐藏主内存延迟的一小部分,而主内存延迟通常要长得多。
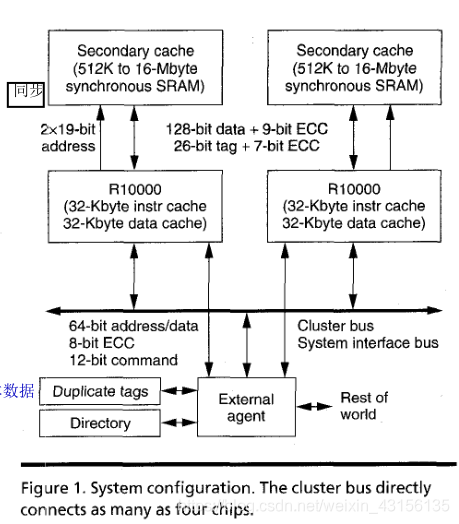
处理器特点:
1.每个时钟周期fetch ,decode 四条指令
2.分支推测执行,4个entry的分支栈
3.使用动态乱序执行
4.使用映射表实现寄存器重命名
5.实现精确异常的有序级配
五个独立的管道执行单元包括:
1.非阻塞的load/stored单元
2.双64-bit 整数ALUs
3.64-bit IEEE std 754-1985 浮点单元
3.具有两周期延迟的流水线加法器
4.具有两周期延迟的流水线乘法器
分层的、非阻塞的内存子系统包括:
1.二相联的一级缓存—32Kb icache ,32Kb ,
2.二级缓存–128-bit 同步SDRAM
3.64-bit 多处理器系统接口
系统使用snoopy或基于目录的协议来保持缓存的一致性。
指令获取管道占用了阶段1到3。在阶段1中,R10000获取并对齐接下来的4条指令。在第二阶段,它对这些指令进行解码和重命名,并计算跳转和分支指令的目标地址。在阶段3中,它将重命名的c写到队列中,并在操作数开始忙碌时读取忙碌位表来进行探测。指令在队列中等待,直到所有操作数都准备好。
当队列发出阶段3中的一条指令时,五个执行管道开始。处理器在第3阶段的后半部分从寄存器文件中读取操作数,execution从第4阶段开始。整数管道占用一个阶段,load管道占用两个阶段,浮点管道占用三个阶段。处理器在下一阶段的前半段将结果写入寄存器文件。
***整型和浮点型部分有单独的指令队列、寄存器文件和数据路径。***这种隔离减少了最大的\线路长度,并允许完全并行操作。这两个寄存器文件加在一起需要比合并后的单元更多的空闲寄存器文件,但是它们在物理上更小,因为每个寄存器的读和写端口更少。
取指令
指令缓存包含地址标签和数据部分。为了实现双向集的结合性,每个部分都有两个并行数组。处理器将两个标记地址与转换后的物理地址进行比较,以从正确的方式选择数据。小的、八个入口的指令转译后备缓冲区(TLB)在主TLB中包含一个子集合的翻译。
处理器在16字指令高速缓存线内的任何字对齐处并行获取4条指令。我们通过对缓存的感知放大器进行简单修改来实现这个特性,如图4所示。每个读出放大器的宽度相当于存储器阵列中的4位列,一个4对1的多路复用器选择一个列(它代表一条指令)进行提取。R10000为每条指令使用单独的选择信号来获取未对齐的指令。如果有必要,这些指令会旋转,以便按顺序进行解码。这种排序减少了依赖逻辑的数量.通常,除非队列或活动列表已满,否则处理器在下一个周期中对所有4条指令进行解码。没有立即解码的指令仍然保留在8个字的指令缓冲区中,从而简化了顺序获取的时间安排。
分支单元
分支指令频繁出现,必须快速执行。然而,处理器通常在解码分支之后的几个甚至多个周期才能确定分支的方向。
因此,处理器预测一个条件分支将接受的指令,并推测地沿着预测的路径获取指令。该预测使用了一个基于512项分支历史表的2位算法。这个表是根据分支指令地址的第11:3编索引的。仿真结果表明,对Spec92整数程序的预测精度达到87%。
在Mips体系结构中,处理器在执行目标地址的指令之前,在跳转或分支之后立即执行指令。在流水线标量处理器中,可以免费执行延迟槽指令,接着从缓存中读取目标指令。这种技术提高了早期RISC微处理器的分支效率。然而,对于超标量设计,它没有性能优势,但是为了兼容性,我们保留了RlOOOO中的特性。
当程序执行发生跳转或分支时,处理器丢弃已经获取的超出延迟时隙的任何指令。它将跳转的目标地址加载到程序计数器中,并在一个周期的延迟后从缓存中获取新的指令。这引入了一个“分支buble”循环,在此期间R10000不解码任何指令。
Branch stack:当它解码一个分支时,处理器将它的状态保存在一个四条目的分支堆栈中。它包含备用的分支地址、整数和浮点映射表的完整副本以及其他控制位。尽管堆栈作为单个逻辑实体运行,但它在物理上分布在它所复制的信息附近。
当分支堆栈已满时,处理器将继续解码,直到遇到下一个分支指令。然后解码就会停止,直到其中一个分支被解析为止。
Branch verification:如果预测不正确,处理器将立即中止沿错误预测路径获取的所有指令,并从分支堆栈中恢复其状态。
沿着错误预测的路径进行抓取可能会导致不必要的缓存重新填充。在这种情况下,指令缓存是非阻塞的,并且处理器在这些重新填充完成时获取正确的路径。由于程序执行可能很快会转向分支的另一个方向,例如在循环的末尾,因此完成这样的重新填充会更容易,也更可取。
Decode logic :
Register mapping:
有33个逻辑寄存器(数字1到31、Hi和Lo)和64个物理整数寄存器。(没有整数寄存器0。零操作数字段表示零值;零目标字段表示未存储的结果。)有32个逻辑(从0到31)和64个物理浮点寄存器
***Register map tables:***单独的寄存器文件存储整数和浮点寄存器,处理器独立地重命名它们。整数和浮点映射表包含当前逻辑寄存器对物理寄存器的映射。这些映射表有16个读端口和4个写端口,它们并行地映射4条指令。每条指令读取三个操作数寄存器和一个目标寄存器的映射。处理器将当前的操作数映射和新的目标映射写入指令队列,而活动列表则保存以前的目标映射。RlOOOO使用24个5位比较器来检测并行解码的4条指令之间的差异。这些交换器控制旁路多路复用器,它们用空闲列表中的新赋值替换依赖操作数。
***Free lists***整数和浮点自由列表包含当前未分配的物理寄存器的列表。因为处理器并行地解码和输出多达4条指令,这些列表由四个平行的,深度为8的,循环的fifo组成。
Active list:活动列表记录处理器中当前活动的所有指令,附加每个指令作为处理器解码。当指令解析错误或异常导致异常终止时,该列表将删除这些指令。由于最多32条指令可以是活动的,所以活动列表由4个并行的、8层的、循环的fifo组成。每个指令由5位标记标识,它等于active list中的一个地址。当一个执行单元完成了一个,指令,它发送它的标签到活动列表,设置它的完成位


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









