







一、快速排序算法描述
基本思想:
1.每一轮排序选择一个基准点(pivot)进行分区
1.让小于基准点的元素的进入一个分区,大于基准点的元素的进入另一个分区
2.当分区完成时,基准点元素的位置就是其最终位置
2.在子分区内重复以上过程,直至子分区元素个数少于等于 1,这体现的是分而治之的思想 (divide-and-conquer)
不同的版本:
1.单边循环快排(lomuto 洛穆托分区方案)
①选择最右元素作为基准点元素
②j 指针负责找到比基准点小的元素,一旦找到则与 i 进行交换
③i 指针维护小于基准点元素的边界,也是每次交换的目标索引
④最后基准点与 i 交换, i 即为分区位置
2.双边循环快排(并不完全等价于 hoare 霍尔分区方案)
①选择最左元素作为基准点元素
②j 指针负责从右向左找比基准点小的元素,i 指针负责从左向右找比基准点大的元素,一旦找到二者交换,直至 i,j 相交
③最后基准点与 i(此时 i 与 j 相等)交换,i 即为分区位置
3.双边循环几个要点
1.基准点在左边,并且要先 j 后 i
2.while( i < j && a[j] > pv ) j--
3.while ( i < j && a[i] <= pv ) i++
二、单边快排图形演示
1、选择4为基准点,i>j,ij交换,然后i前进

2、25交换

3、17交换

4、pv和i交换

5、最后递归遍历左半边和右半边元素,最终排序完成
三、单边快排的代码
import java.util.Arrays;
// 单边循环法 (lomuto)
public class QuickSort1 {
public static void main(String[] args) {
int[] a = {5, 3, 7, 2, 9, 8, 1, 4};
System.out.println(Arrays.toString(a));
quick(a, 0, a.length - 1);
}
public static void quick(int[] a, int l, int h) {
if (l >= h) {
return;
}
int p = partition(a, l, h); // p 索引值
quick(a, l, p - 1); // 左边分区的范围确定
quick(a, p + 1, h); // 左边分区的范围确定
}
private static int partition(int[] a, int l, int h) {
int pv = a[h]; // 基准点元素
int i = l;
for (int j = l; j < h; j++) {
if (a[j] < pv) {
if (i != j) {
swap(a, i, j);
}
i++;
}
}
if (i != h) {
swap(a, h, i);
}
System.out.println(Arrays.toString(a) + " i=" + i);
// 返回值代表了基准点元素所在的正确索引,用它确定下一轮分区的边界
return i;
}
public static void swap(int []a,int i,int j){
int t=a[i];
a[i]=a[j];
a[j]=t;
}
}
四、双边循环图形演示
1、选取左边为基准点,j往左找比基准点小的,i往右找比基准点大的,两者交换
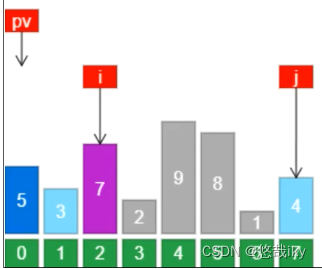
2、19交换

3、左右分区分好,基准点元素和中间元素交换

4、左区间和右区间递归即可完整排序
五、双边循环代码
import java.util.Arrays;
// 双边循环法
public class QuickSort2 {
public static void main(String[] args) {
int[] a = {5, 3, 7, 2, 9, 8, 1, 4};
System.out.println(Arrays.toString(a));
quick(a, 0, a.length - 1);
}
private static void quick(int[] a, int l, int h) {
if (l >= h) {
return;
}
int p = partition(a, l, h);
quick(a, l, p - 1);
quick(a, p + 1, h);
}
private static int partition(int[] a, int l, int h) {
int pv = a[l];
int i = l;
int j = h;
while (i < j) {
// j 从右找小的
while (i < j && a[j] > pv) {//i必须小于j,不然i可能往前走,停不下来
j--;
}
// i 从左找大的
while (i < j && a[i] <= pv) {//i一开始指向pv,故必须要=号
i++;
}
swap(a, i, j);
}
swap(a, l, j);
System.out.println(Arrays.toString(a) + " j=" + j);
return j;
}
public static void swap(int []a,int i,int j){
int t=a[i];
a[i]=a[j];
a[j]=t;
}
}















 8709
8709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











