






1、主成分分析原理
主成分分析法是利用降维的思想,把多指标转化为少数几个综合指标(即主成分),其中每个主成分都能够反映原始变量的大部分信息,且所含信息互不重复。这种方法在引进多方面变量的同时将复杂因素归结为几个主成分,使问题简单化,同时得到的结果更加科学有效的数据信息。例如,做一件上衣需要测量很多尺寸,如身高,袖长,腰围,胸围,肩宽等十几项指标,但是厂家不可能把尺寸型号分这么多,而是从这十几种指标中综合成几个少数的综合指标作为分类型号,例如综合成反映身高,反映胖瘦和反应特体的三项指标,这就是主成分的思想。主要的方法有特征值分解,SVD(奇异值分解)和NMF(非负矩阵分解);
2、实际应用
在本次作业中,我以2017级广播电视工程大一的综测成绩为例,随机抽取了10位名次互相不靠近(为体现数据差异)的同学,按照总成绩从高到低排序,选取他们的
- R1(基础成绩,上限1150)
- R2(学习成绩,上限5000)
- R3(体育成绩,上限100)
- G项(活动加分,上限200)
成绩作为样本进行分析,并用主成分分析法来论证R2的名次对总成绩的贡献最高,参考价值最大。
3、实现
(注:由于本组案例各评价指标的性质相同,且具有相同的量纲和数量级,故不做标准化处理)
首先,导入现有数据,每一维的数据对应着R1,R2,R3,G项:
x=[1090 4699.5 82.2 125
1106 4395.5 87.1 70
1145 4227.0 84.1 70
1085 4248.5 71.2 50
1080 4109.5 82.6 90
1095 4083.0 68.2 60
1090 4000.0 76.0 60
1080 3896.5 79.2 70
1077 3828.0 73.0 50
1077 3024.0 82.2 90];
根据主成分分析方法,先求出协方差矩阵:
s=sum(x,1);
[nSmp,nFea] = size(x);
W=cov(x); %求出协方差矩阵
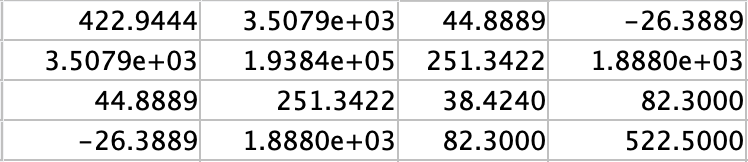
求出的协方差矩阵如图所示:
在这之后,求出特征值矩阵,并对特征值进行降序排序,运行代码如下:
fprintf(1,'Calculating generalized eigenxs and eigenvalues...\n');
[eig_xs, eig_values] = eig(W);
%eig_xs为特征向量组成的矩阵,eig_values为特征值组成的对角矩阵
fprintf(1,'Sorting eigenxs according to eigenvalues...\n');
d1=diag(eig_values);%返回对角矩阵上的值
[d2 index]=sort(d1); %以升序排序,d2为排列后的值,index为索引值
cols=size(eig_xs,2);% 特征向量矩阵的列数
for i=1:cols
vsort(:,i) = eig_xs(:, index(cols-i+1) ); % vsort 是一个M*col(注:col一般等于M)阶矩阵,保存的是按降序排列的特征向量,每一列构成一个特征向量
dsort(i) = d1( index(cols-i+1) ); % dsort 保存的是按降序排列的特征值,是一维行向量
end %完成降序排列
降序后的特征值矩阵(dsort)如下,按序排列为:R2,R1,R3,G

用explained表示每个特征值占比,字面上即每个特征值对系统有多少解释,用百分比表示
explained=100*dsort/sum(dsort);
求出的explained矩阵:

R2的贡献率竟达到了恐怖的99.5373%😨😨可见大家在综测评价的时候还是要牢牢抱紧分数的大腿
4、后续
主成分分析法是利用降维的思想,把多指标转化为少数几个综合指标(即主成分)。
在本案例中,由于R2的占比过大,而其他项的成绩贡献过小,可视R2为本案例中的主成分。
我们在平时分析一个人的综合测评成绩时,首先看他的R2(学习成绩),便可大概得知他处在一个什么样的水平,这也是符合情理的。
通过此方法的分析,我们也得以去除冗余项,实现了降维,简化了分析。














 1105
1105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









