







Beyond Part Models: Person Retrieval with Refined Part Pooling(阅读)
几个关于这篇文章的博客
http://www.mclover.cn/blog/index.php/archives/423.html(细)
http://www.jintiankansha.me/t/ba4B60tkVS
https://zhuanlan.zhihu.com/p/31947809
关于骨干网络resnet:骨干网络的各个输入输出

resnet详细解读
定义一个3*3的卷积模板,步长为1,并且使用大小为1的zeropadding。
定义基础模块BasicBlock:BasicBlock架构中,主要使用了两个3∗3的卷积,然后进行BN
定义Bottleneck模块:这三层分别使用1∗1,3∗3,1∗1的卷积模板,使用Bottleneck结构可以减少网络参数数量
定义整个残差网络:
第一层卷积使用7∗7大小的模板,步长为2,padding为3。之后进行BN,ReLU和maxpool。这些构成了第一部分卷积模块。之后的layer1到layer4分别是四个不同的模块,具体细节可以参考Table1
make_layer方法作用是生成多个卷积层,形成一个大的模块
输入图像:

针对网络不太理解的地方:
如果输入图片的大小改变,那么每层可能会改变,那么输出的计算等会受什么影响
本文:
显式的定位 local parts,但是也要忍受 transfer 过程由于 datasets bias 引入的误差。当然如果定位带来的提升大于引入误差导致的性能降低,整体也是可以接受的。这篇文章第一部分PCB模型使用得是均匀划分。对不同part用不同loss去训练。对于均匀分割或者其它统一的分割,不同图像在同一part可能因为没有对齐出现不同的语意信息。对此,作者提出了Refined Part Pooling 对统一分割进行提纯,增强 within-part 的一致性,这也是本文的一大亮点。


骨干网络
PCB可以采用任何没有用于图像最终分类的隐藏全连接层的网络作为主干,本文采用ResNet50,因为其富有竞争力的表现和相对简洁的架构。
从骨干网络到PCB
我们通过略微修改将骨干网接入到PCB,如图2所示。原全局平均池化层(GAP)之前的结构与骨干模型保持完全相同。不同之处在于删除了GAP层和后面的层。当图像通过骨干网络的所有层后,它变为激活的3D张量T。在本文中,我们将沿通道轴观察的激活矢量定义为列矢量。然后将T划分为p个水平条带,使用平均池化,将同一条带中的所有列向量平均池化为单个局部列向量g。之后,PCB采用卷积层来减小g的尺寸。 根据我们的初步实验,尺寸减小的列向量h被设置为256-dim。 最后,将每个h输入到分类器中,这是通过全连接(FC)层和后续Softmax函数实现的,用于预测输入所属的标识(ID)。
将平均池化删除后 ,如果输入是224输出应该是 1 2048(通道数) 7 7 (图片大小)
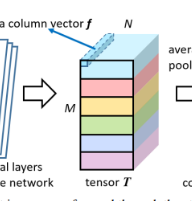
文中输入是384128 ,比例是 3:1(为什么是3:1呢)
T是最后平均池化出来的 文中是 248 具体怎么算的还要再研究一下
• 输入图像尺寸 384 × 128,高宽比 3:1,经过骨干网络后为12 x 4(32倍缩放,但作者在3.2中去除了骨干网络最后一层的pooling,所以输出也可能是24 x 8)
• T 的空间尺寸为 24 × 8.
• T 被分为6片
将最后一层feature map 分成 p个horizontal stripes。
分别对p个horizontal stripes做global average pooling就得到了p个局部特征。文中分了6块,p=6
最后一层应该是1 2048 24 8 吧。
M N = [24 ,8]
g应该是2048;(通道数) 最后一层的
因为 Resnet50 最后一层feature map的通道数为2048,作者又用1x1 conv将其降到256维。
现在特征向量h=256;(通道数)
前面都是特征处理;
最后,将每个h输入到分类器中,这是通过全连接(FC)层和后续Softmax函数实现的,用于预测输入所属的标识(ID)。(这是分别输入,还是一起)
接着用p个n(训练集ID数目)分类softmax作为分类器进行训练。损失函数使用交叉熵损失。
测试时分别串联向量g和h作为行人图像的特征表示。
对比了使用单损失和多损失的性能。使用单损失函数时,对 p 个 特征向量h 求平均作为图像的特征表示。
对比了 p 个 softmax 前一层 FC 共享参数的性能。
全连接层全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。在实际使用中,全连接层可由卷积操作实现:
对前层是全连接的全连接层可以转化为卷积核为1x1的卷积;而前层是卷积层的全连接层可以转化为卷积核为hxw的全局卷积,h和w分别为前层卷积结果的高和宽。
全连接的核心操作就是矩阵向量乘积 y = Wx
本质就是由一个特征空间线性变换到另一个特征空间。目标空间的任一维——也就是隐层的一个 cell——都认为会受到源空间的每一维的影响。不考虑严谨,可以说,目标向量是源向量的加权和。
在 CNN 中,全连接常出现在最后几层,用于对前面设计的特征做加权和。比如 mnist,前面的卷积和池化相当于做特征工程,后面的全连接相当于做特征加权。(卷积相当于全连接的有意弱化,按照局部视野的启发,把局部之外的弱影响直接抹为零影响;还做了一点强制,不同的局部所使用的参数居然一致。弱化使参数变少,节省计算量,又专攻局部不贪多求全;强制进一步减少参数。少即是多) 在 RNN 中,全连接用来把 embedding 空间拉到隐层空间,把隐层空间转回 label 空间等。
**在训练期间,**通过最小化p个预测ID的交叉熵损失之和来优化PCB。在测试过程中,将p个g或h连接起来形成最终描述符G或H,即 G=[g1,g2,…,gp] or H=[h1,h2,…,hp]。正如在我们的实验中观察到的那样,采用G实现了稍高的精度,但计算成本更高,这与[28]中的观察结果一致。
- 局部内部的不一致

作者将 average pooling 前后的向量做最近邻( f_{mn} 与 g_i ),注意到真实的边界并不和统一划分的边界重合,很显然这也是统一划分最大的弊端之一。(这个是怎么做的呢)

池化的相关内容 :average-pooling能减小第一种误差,更多的保留图像的背景信息,max-pooling能减小第二种误差,更多的保留纹理信息。average-pooling更强调对整体特征信息进行一层下采样,在减少参数维度的贡献上更大一点,更多的体现在信息的完整传递这个维度上,在一个很大很有代表性的模型中,比如说DenseNet中的模块之间的连接大多采用average-pooling,在减少维度的同时,更有利信息传递到下一个模块进行特征提取。
(在关注空间上划分的张量T时,我们对于局部内部的不一致的想法是:在T的同一个局部中的列向量f应该彼此相似并且与其他部分中的列向量不同; 否则会发生局部内部的不一致现象,这意味着局部分割不当。
在对PCB进行收敛训练之后,我们通过测量余弦距离来比较每个 f (直接输出的f)和 gi(即每个条带的平均池化合并列向量 i=1,2,…,p)之间的相似性。如果 f 最接近 gi,则相应地推断f最接近第i个部分。这样我们找到每个f最接近的部分,如图3所示。每个列向量用一个小矩形表示,并用其最接近部分的颜色绘制。)
(首先,同一水平条带中的大多数列向量都聚集在一起(尽管没有明确的约束来描述此效果)。其次,存在许多在训练期间指定到某水平条带的异常值,与另一部分水平条带更接近。这些异常值的存在表明它们本质上与另一部分中的列向量更加一致。)

自己的见解:
也就是f应该是1 2048 24 8
平均池化后的g应该是 1 2048 1 1
作者发现平均池化不好,所以采用策略
重新定位异常值
我们提出RPP以纠正局部内部不一致现象。我们的目标是根据它们与每个部分的相似性来分配所有列向量,以便重新分配异常值位置。参数记为 W
为此,我们需要在运行中对T中的所有列向量f进行分类。基于已经学习的T,我们使用线性层+Softmax激活器作为局部分类器。
soft的解释:在机器学习尤其是深度学习中,softmax是个非常常用而且比较重要的函数,尤其在多分类的场景中使用广泛。他把一些输入映射为0-1之间的实数,并且归一化保证和为1,因此多分类的概率之和也刚好为1。所以我们就应用到了soft的概念,即最后的输出是每个分类被取到的概率。


RPP的最终流程

通过这样做,RPP实现了soft和自适应分区以细化原始的hard和均匀分区,并且将源自固定分区的异常值重新分配。结合RPP后,PCB进一步变形如图4。RPP+采样操作取代了原始的平均池化。所有其他层的结构与图2中的结构完全相同。

训练T的时候是整个网络进行训练么,应该是吧 ,在均匀分割的情况下先收敛,然后再改池化层。
池化层采用局部分类器,局部分类器单独进行训练。
这部分是对不同的局部区域进行训练么 ?
对块的p进行训练(训练过程未理解,哎看看代码吧)5.2 实现细节
用于比较的IDE的实现
对原始版本进行了多次优化[40]的ResNet50:
在ResNet50中的“pool5”层之后,我们追加一个输出尺寸为256-dim的全连接层,再接Batch Normalization和ReLU;
虽然“pool5”层中没有可训练的参数,但有证据表明在其上应用dropout=0.5,输出2048d的高维特征向量,有效避免了过拟合并获得了相当大的改进;
参数分析
图片尺寸:更大的图像尺寸有益于学习到局部特征, mAP和rank-1准确度都随着图像尺寸的增加而增加,直到达到稳定。
tensor T 尺寸:较小的下采样率增强了网络能力,尤其是在使用相对小的图像作为输入时。建议在考虑计算效率的情况下将下采样率减半。
局部 p 的数量:随着p的增加,检索精度首先会提高之后下降,过度增加p使得有些局部可能会坍塌到空白,损害了局部特征的辨别能力
对于本文的总结:
作者主要认为局部细粒度特征很重要,并且局部细粒度特征需要准确的被定位,强调每个局部位置的内容一致性,学习有区别的特征。
PCB网络通过统一的分块策略。
统一分块会在局部产生异常值,异常值可能和其他的局部相似,重新分配到相似的局部,增强局部的一致性。
贡献:
首先,我们提出了一种基于部件的卷积基线(PCB)网络,它在卷积层上进行均匀划分,学习部件级特征。它没有显式地划分映像。PCB以整幅图像作为输入,输出一个卷积特征。作为一个分类网络,PCB的架构非常简洁,只是在主干网络上做了少许修改。
其次,我们提出一种自适应池方法来细化均匀划分。我们认为在每个部分的内容应该是一致的动机。我们观察到在均匀分割下,每个部分都存在异常值,实际上,这些异常值更接近于其他部分中的内容,这意味着部分内部不一致。因此,我们通过将这些离群点重新定位到离群点最近的部分来细化均匀划分,从而增强了局部一致性。
能有针对的对每块的信息进行分类(分块)
RPP是一个attention模型。6个部分对应的空间分布进行软权值的分配,进而对齐part
RPP解释
动机:PAR的目标是直接学习对齐的部分,而RPP的目标是细化预先分割的部分。
工作机制:PAR采用注意法,对零件分类器进行无监督训练,同时对RPP可以看作是一个半监督的过程。
训练过程:RPP首先训练一个均匀分割的身份分类模型,然后利用所学习的知识对零件分类器进行训练。
总结:
本文对解决行人检索问题有两点贡献。首先,我们提出了一个基于部件的卷积基线(PCB)来学习部件相关的特性。PCB采用简单的统一分区策略,并将部分信息的特性组装成卷积描述符。PCB将技术提升到一个新的水平,证明自己是学习部分功能的强大基线。均匀分区PCB虽然简单有效,但还有待改进。我们建议用改进的部分池来加强部分内的一致性。在细化后,将相似的列向量归纳成相同的部分,使每个部分在内部更加一致。















 412
412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









