






论文名:PRIMAL: Pathfinding via Reinforcement and Imitation Multi-Agent Learning
Journal:IEEE Robotics and Automation Letters
Date:2019-7
Citations:197
DOI:10.1109/lra.2019.2903261
本文提出了primal,一个结合深度强化学习和模仿学习的、用于MAPF问题的新框架。
1策略Policy
1.1 观察空间Observation Space
智能体的观察是以自身为中心的有限FOV,属于部分可观察。
此外,智能体始终可以访问指向其目标的单位向量和到其目标的欧几里得距离。
将可用信息分成不同的通道来简化agent的学习任务。
每个观察空间都由表示障碍物、其他智能体的位置、智能体自己的目标位置(如果在FOV内)以及其他可观察智能体的目标位置的二进制矩阵组成。
1.2 行动空间Action Space
离散的行动。
在每个时间步长,沿四个基本方向之一移动一个单元格或保持静止。
与障碍物或者其他智能体碰撞都是无效动作。
在训练期间,仅从有效动作中采样动作,并且使用额外的损失函数来学习有效动作防止无效动作。这比对选择无效动作的智能体给予负面奖励更加稳定。
在训练期间,防止智能体返回其在上一个时间步长所在的位置,这可以鼓励探索和学习有效的政策。
如果在测试期间的行动是无效行动,那么这个时间步它将保持静止。
1.3 奖励结构Reward Structure

1.4 Actor-Critic Network
依赖于asynchronous advantage actorcritic (A3C) 算法。
使用深度神经网络近似agent的策略。它将当前对其周围环境的观察映射到要采取的下一个行动。这个深度神经网络有多个输出,其中一个是实际策略,其他仅用于训练网络。
使用了一个6层卷积网络,在每个max-pooling layer之间使用几个小的3×3的kernels。
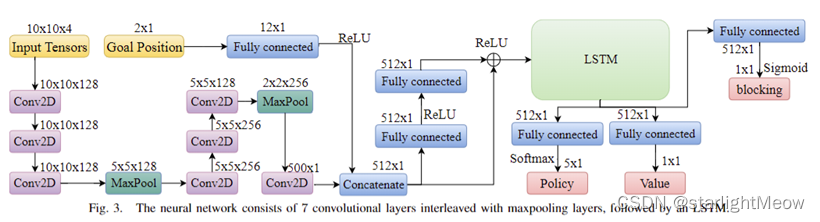
如图所示神经网络有两个输入,分别是局部观察(Input Tensor)和目标方向/距离(Goal Position)。
两个输入在被神经网络连接前会被独立预处理。
Input Tensor是一个四通道矩阵(10×10×4张量)。它会首先经过两个阶段,每个阶段中有三个卷积层和一个最大池化层。然后进入最后一个卷积层。
同时,Goal Position向量及其大小通过一个全连接层。
然后这两个预处理后的输入将会经过Concatenate操作合并在一起,再经过两个全连接层,最后输入到大小为512的长短时记忆(LSTM)单元中。残差网络的跳跃连接(residual shortcut)将合并后的输入也连接到LSTM的输入层。
输出层由具有softmax激活函数的策略(policy)神经元、值(value)输出和用于训练每个智能体以了解自己是否阻碍其他智能体到达其目标(the blocking prediction)的特征层组成。
在训练期间,策略、值和是否阻碍其他智能体的输出会在每256个steps或在一个episode结束时批量更新。
通常,值为了和the total discounted return 匹配上,会通过最小化函数来更新。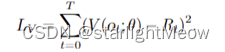
通过使用值函数Value Function V(ot; θ)来估计优势函数Advantage Function A(ot, at; θ)并依据优势函数来更新策略。
此外,还在策略损失中添加了一个熵项 H(π(o)),它已被证明可以通过惩罚总是选择相同行动的政策来鼓励探索并阻止过早收敛。
还依赖两个损失函数来帮助规划和稳定训练。首先是最小化的Lblocking函数,用于更新the blocking prediction output。另一个是损失函数Lvalid,用于最小化选择无效行动。
2 协调学习Coordination Learning
解决自私问题。
包括以下三种方法。对鼓励其他智能体运动进行惩罚(称为“阻塞惩罚,Blocking Penalty”),在训练期间使用专家演示,以及在训练期间定制随机环境以使智能体面临更困难的环境。
2.1 Blocking Penalty
场景为一个智能体决定停留在目标位置上,同时这个行为妨碍了另一个智能体达到其目标。
调整奖励函数,使这个智能体将会受到严厉的惩罚,实际上是-2。这样可以更好地激励智能体的协作行为,促使智能体离开其目标,以抵消它们在达到目标后可能产生的一种自私的局部最优行为。
阻塞的定义不仅包括直接阻止另一个智能体达到目标的情况,也包括显著延迟另一个智能体到达目标的情况(比如实际中延迟10步或更多,与智能体的视野(FOV)大小相匹配)。
由于智能体的视野很小,因此即使存在绕过其他智能体的替代路径,如果这些替代路径不在智能体的视野内,智能体也就不确定是否存在这样的路径。即使在大地图中可能存在绕行的路径,但如果能通过协调实现更短的路径,智能体应该寻求协作而不是选择绕路。
判断方法:使用标准A*算法来确定智能体从当前位置到目标的路径长度,以及当将其他智能体从大地图中移除时的路径长度,如果第二条路径比第一条路径短10步以上,则认为其他智能体正在阻塞。
在系统中,“block”输出是预测一个智能体何时会阻塞其他智能体。这种预测为智能体在出现阻塞行为时将要承担的额外惩罚提供了依据。
2.2 结合RL(强化学习)和IL(模仿学习)
研究发现,将RL与IL结合可以加快训练速度,稳定训练过程,并且获得更高质量的解决方案。IL能够快速指导智能体找到高质量的状态-动作空间区域,而RL能够通过自由探索这些区域来进一步改善策略。
在Priaml中,每个训练周期开始时都随机选择使用RL或IL,依靠中心化规划器ODrM*(折扣因子 ε = 2),动态生成用于学习的示例。
通过与中心规划器生成的专家轨迹的对比来引导学习过程,每个智能体都获得了一系列观察和动作的轨迹 T ∈ (O × A)n,并最小化行为克隆损失。
Primal结合了离线策略的**行为克隆(Behavior Cloning)和在线策略的演员-评论家(Actor-Critic)**方法。行为克隆是一种模仿学习策略,其中学习算法尝试直接克隆专家的行为。在离线策略的行为克隆中,模型通常是通过分析预先收集的专家轨迹(专家的决策序列)来训练的。这种训练是“离线”的,因为它不需要与环境实时交互,而是依赖于已经存在的数据。
中心化规划器ODrM*依据启发式原则生成与奖励结构相匹配的高质量路径,这些路径旨在最快速地让智能体达到目标并避免碰撞。
RL/IL比例对训练策略的性能影响不大。
2.3 环境采样Environment Sampling
在训练过程中,在每个episode开始时随机化世界的大小和障碍物密度。
从有利于更小和更密集环境的分布中对障碍物的大小和密度进行采样,迫使智能体学习协调,因为这样可以使智能体更频繁地经历与其他智能体之间的交互。














 3300
3300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









