










神经网络的反向传播是什么
神经网络的反向传播,实际上就是逐层计算梯度下降所需要的
w
w
w向量的“变化量”(代价函数
J
(
w
1
,
b
1
,
w
2
,
b
2
,
w
3
,
b
3...
w
n
,
b
n
)
J(w1,b1,w2,b2,w3,b3...wn,bn)
J(w1,b1,w2,b2,w3,b3...wn,bn)对于
w
,
b
w,b
w,b向量各个分量(w1,w2,w3,w4…)(b1,b2,b3…)的微分)。以便进行梯度下降算法更新参数优化模型。反向传播就是适用链式法则(如果学过矩阵论可以认为也用到了矩阵论的知识),将这个求微分过程可以通过迭代来进行完成。
本人在之前的学习机器学习系列课程中就对这段知识点懵懵懂懂,这次花费很多时间一举攻下,所以一定要做详细解释使得每一个读者,包括未来的自己对这部分知识一目了然。因为毕竟说白了不过是几个矩阵求个导数罢了。我向您保证,您只需要会简单求导,以及向量乘法,当然还有耐心,因为我举了大量由浅入深的例子和不厌其烦的细节重述,那么你就足够看懂本文,学会神经网络的反向传递
本部分内容,有意义,却又不尽只是满足一份好奇心,因为对于足够复杂的系统,对于其整体的把握远远比对于细节来得重要。很多时候复杂系统的细节,是我们硬要解释也解释不来的,请交给数学罢。
心得,思维与攻克方法
在我学习的过程中,我认为bp这是一块比较难克服的地方(几个公式花费了我近两天时间),总结主要有若干几点原因:
1)深度学习课程中的矩阵规模表达模糊。2)如
w
,
∗
w,*
w,∗等在不同版本数学教材中含义混淆,而其未给予任何提示和声明,使得一一对应的复现较为困难。3)丝毫没有任何推导地给予公式,这对于小白可能是好事,但对于多大多数当今的好奇一代,这等于杀人。
所以我将对上述不足的地方给予额外的详细说明。
我尝试了并且建议大家可以通过两种思路理解其过程。
1)深入学习矩阵求导相关知识
这里推荐一本哈工大数学系的朋友推荐的参考书:《矩阵理论与应用》上海交通大学出版社,看完这本书的矩阵求导部分,应该就可以直接上手推导反向传播过程的公式。不会有什么障碍了。
2)从每层都只有一个神经元这种简单情况开始,逐渐扩展
这也就是我在本文中要介绍的方法。(就是有从求单个的到整合在一起的这么一个过程)您只需要会求导和矩阵乘法。
希望大家能够在看完本文之后,能够彻底读懂神经网络。
从一个简单的神经元讲起(形态1)
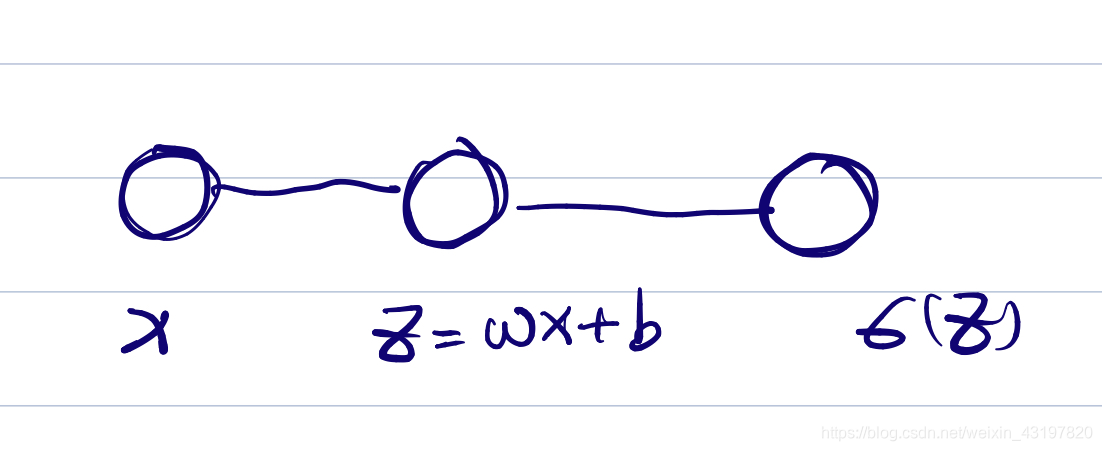 我们先引入一个简单的神经元,理清一些概念。
我们先引入一个简单的神经元,理清一些概念。
比如我上面举的例子,第一个球(第一层)x作为输入,经过一层前向传导
z
=
w
x
+
b
z=wx+b
z=wx+b,变成了
z
z
z(第二个球,第二层),然后再经过
s
i
g
m
o
i
d
(
z
)
sigmoid(z)
sigmoid(z)传导到第三个球(第三层)。然后就没了,就很简单。
我们来看如何对于神经网络模型图的东西赋予意义加深理解记忆,实际上一个球就是一个变量,当我们将其放在特定的情况下进行传播时,每一个球就是一个确定的数字罢了;而每一条线,就相当于一个神经元(球)传递的权重,如果想象力够好大可以将每条线的粗细和其数值大小对应上脑补出来。(我们在这里面只关注左边的线,右边的线相当于一个一一对应的激活函数,在实际使用中是将后两个球粘合在一起的,不外露的,我们便不讨论它)
这时候的反向传播很简单,假设我们设置了一个代价函数
J
J
J,并且得到了其对于
s
i
g
m
o
i
d
(
z
)
sigmoid(z)
sigmoid(z)的导数,那么我们可以使用链式法则一层层续链子,将链子延展到每一个需要修正的变量,在本例就是一步步向左传递得出
z
,
b
,
w
,
x
z,b,w,x
z,b,w,x的导数。
具体操作就是我们先对于sigmoid求z的导数
那么
d
J
d
z
\frac{d J}{d z}
dzdJ=
d
J
d
s
i
g
m
o
i
d
(
z
)
\frac{d J}{d sigmoid(z)}
dsigmoid(z)dJ×
d
s
i
g
m
o
i
d
(
z
)
d
z
\frac{d sigmoid (z)}{d z}
dzdsigmoid(z)。那么以后为了简单起见,我们和吴老师一样,把这个意思的函数写成微分形式,即
d
z
dz
dz=
d
s
i
g
m
o
i
d
(
z
)
×
s
i
g
m
o
i
d
′
(
z
)
d ~sigmoid(z)×sigmoid ~'(z)
d sigmoid(z)×sigmoid ′(z),那么这“层”(实际意义上这不算做一层)就完事了,我们就可以继续往前搞下一层。我们继续求b的导数,那很简单,即
d
b
=
d
z
db=dz
db=dz,我们尝试在这里塑造一个直观的理解,为了以后在更复杂的时候也能理解,即事实上,b的修正变化和z的变化是同步的,
d
b
=
d
z
db=dz
db=dz;再求w的导数,
d
w
=
d
z
×
x
dw=dz×x
dw=dz×x,我们尝试在这里塑造一个直观的理解,即w的修正,和线段的另一端其传递过来的x是成正相关的,那一边的x占有重要地位,那么你修正的力度也就要更大;然后是x本身,求导易得
d
x
=
d
z
×
w
dx=dz×w
dx=dz×w,直观理解就是,对于线粗的另一端的
x
x
x,我们的修正要更加猛烈一些。
我们先在将x变化成为一个多神经元输入(多变量),变化成向量X(形态2)
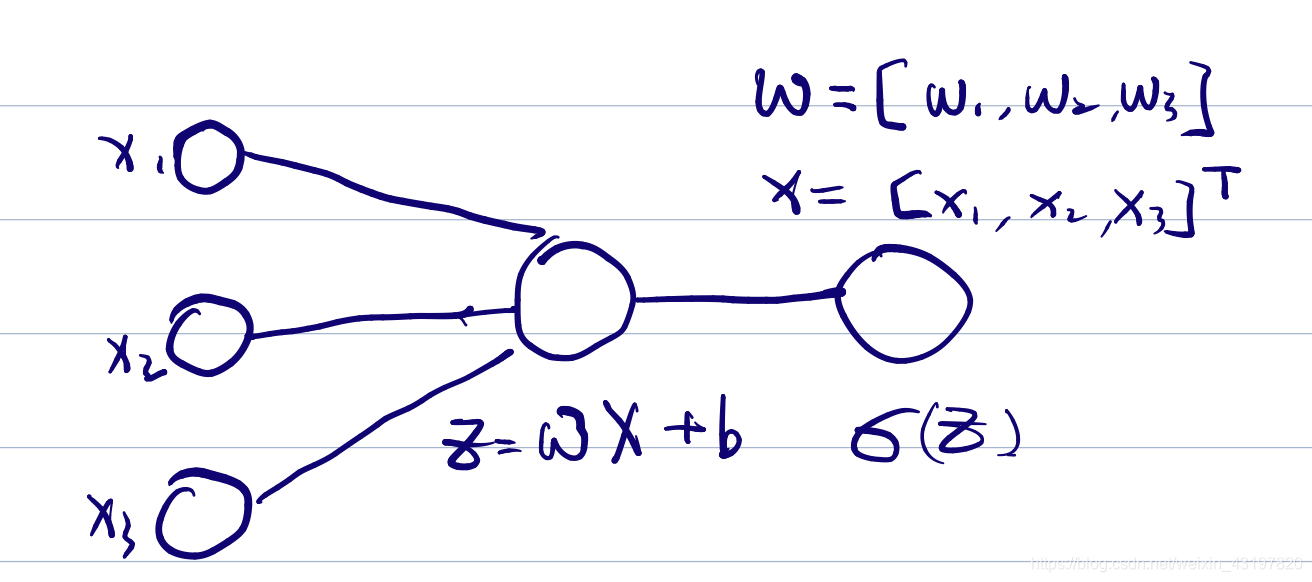
现在我们将x扩充成一个X向量,看看需要补充什么样的说明。
首先我们要说明一下,我们定义的
w
w
w,和吴恩达深度学习的课程一样,是行向量,(在不同教材中可能也是列向量,这和在不同教材中b的所属位置不同是一样的,因地制宜地看就好了)
我们将本例子中的
w
w
w指定为[
w
w
w1,
w
w
w2,
w
w
w3],将
X
X
X指定为[
x
x
x1,
x
x
x2,
x
x
x3].很显然这里暗含着一种线(权重)和球(神经元)之间的对应关系。正向传播依旧是
z
=
w
x
+
b
,
o
u
t
p
u
t
=
s
i
g
m
o
i
d
(
z
)
z=wx+b,output=sigmoid(z)
z=wx+b,output=sigmoid(z)。反向传播,最右侧源头输入,
s
i
g
m
o
i
d
sigmoid
sigmoid第一次链乘照旧,得到
d
z
dz
dz。
然后,我们来聚焦于刚刚变化的部分,首先是
d
b
db
db,很显然b的变化只和z相关,仍然是
d
b
=
d
z
db=dz
db=dz
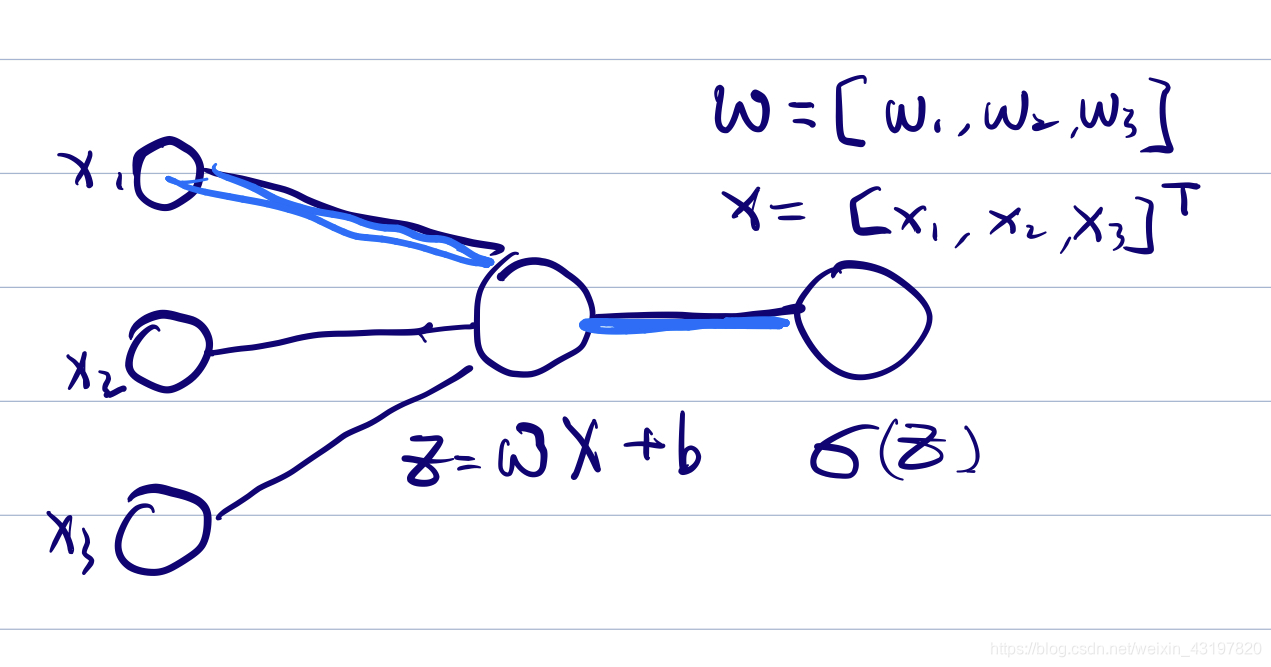
再来看
d
w
dw
dw,我们将这左侧的三条线(权重)一条条看(依次计算
d
w
dw
dw),(因为他们变化都是从中间的球变化得出的,而且之间不存在联系),我们使用之前的结论(有式子,但是用直觉更好:原有的x数值越大,惩罚越大,谁让你那么支持的,这锅肯定要背的)得到
d
w
dw
dw1=
d
z
dz
dz×
d
x
dx
dx1,
d
w
dw
dw2=
d
z
dz
dz×
d
x
dx
dx2,
d
w
dw
dw3=
d
z
dz
dz×
d
x
dx
dx3,用向量化的角度思考就是
d
w
dw
dw…(1,3)=
d
z
dz
dz…(1,1)×
x
x
xT…(3,1)–>(1,3)。简要写下来就是
d
w
=
d
z
×
x
dw=dz×x
dw=dz×xT
这里我要吐槽几点,第一点就是我一开始不理解莫名奇妙有一个转置导致想了很多时间,实际上就是忘记了
w
w
w在这一部分是一个行向量,这个事太诡异了,因为我们太熟悉
y
=
w
y=w
y=wT
x
+
b
x+b
x+b,很容易转不过来弯直接脑补。
第二点,吴专门挑一堂课梳理规模,然而那时候我已经乱了,整理我也听不懂了有木有!!咱能稍微放一起讲不要卖关子,让大家一次行动好不好!!所以这也时刻提醒我在重复记录下来的时候,要备注矩阵的规模。。
好,我们继续,接下来是
d
x
dx
dx,我们继续一条条看,根据之前简单情况推好了的式子可以得到,(直觉上的解释是线越粗,我们对于x的惩罚也就要越大,谁让你乱顶了,这锅肯定要背的),那么和
w
w
w那部分一样,我们整理一下并且向量化,便可以得到
d
x
=
w
dx=w
dx=wT
×
d
z
×dz
×dz
从“星崩”到正经的神经网络(形态3)
其实,前面的都是铺垫于排雷,现在开始要集中精神哟。

当我们将神经元扩展为3,2的两层时,权重
w
.
.
.
(
2
,
3
)
w...(2,3)
w...(2,3),和
b
.
.
.
(
2
,
1
)
b...(2,1)
b...(2,1)也发生了变化。这时候我们首先将修改一下符号满足相关的标准,左侧
a
a
a(i),中间为
z
z
z(i+1),右侧
a
a
a(i+1)。我们每一次的正向传递也就是从
a
a
a(i)到
z
z
z(i+1),再从
z
z
z(i+1)到
a
a
a(i+1)。由于第二步是一个一一对应过程,我们之后在的概念图中可以将其合并。
首先一件很重要的事情对于这时的
w
w
w建立一个直观理解。这时的
w
w
w,是一个权重矩阵,其每一行都是一个原来的
w
w
w,相当于在正向传播时,每一行都可以将之前所有的神经元加权加和下一层给一个神经元赋值。有多少列,就会向下一层传递多少个数值,也就是说
w
w
w矩阵的行列是和上下两层的神经元对应的,在脑子里要脑补充这个对应
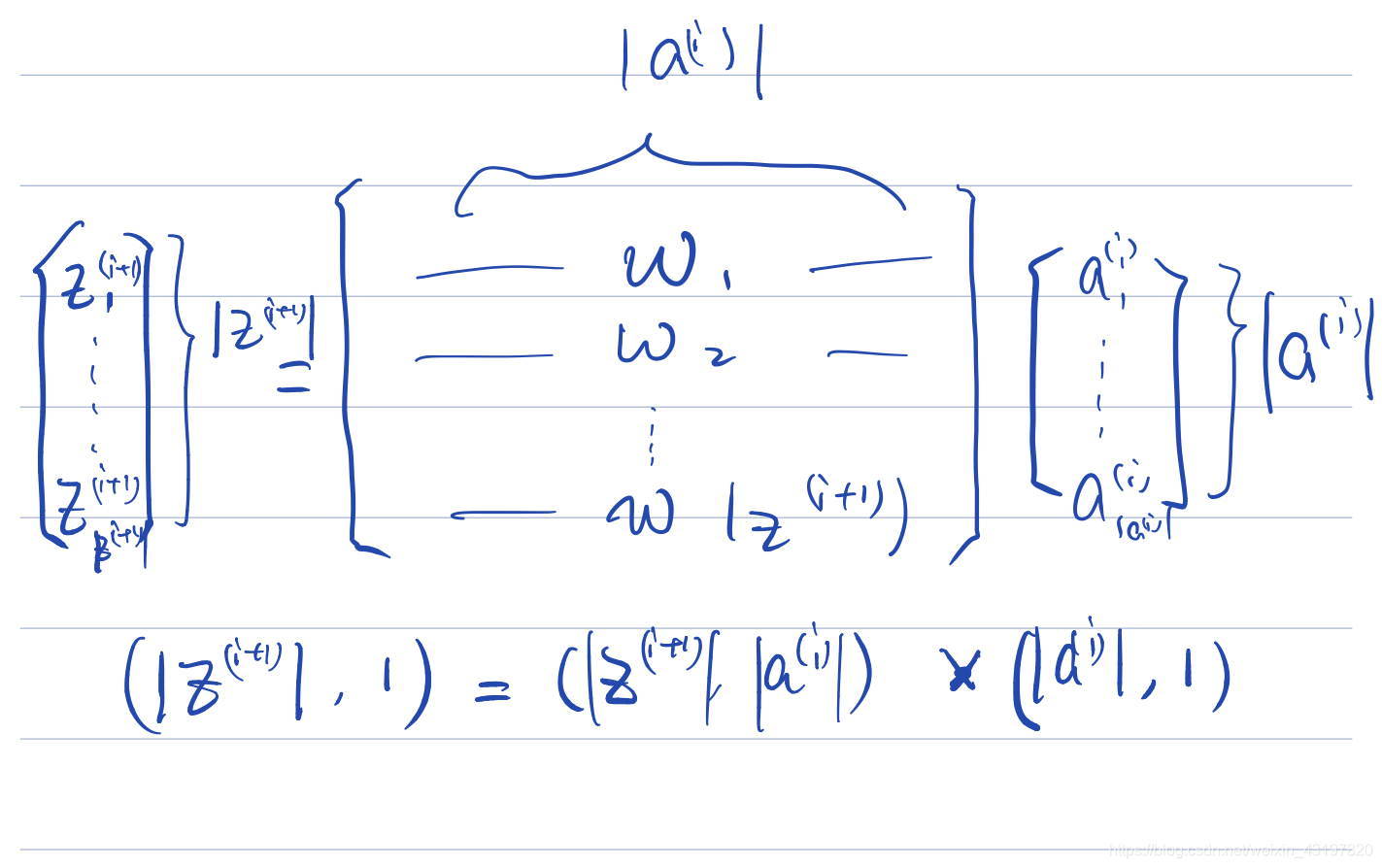
之后来谈其反向传播过程,还是拆成一部分一部分看。我们不妨,先抽出上半部分。
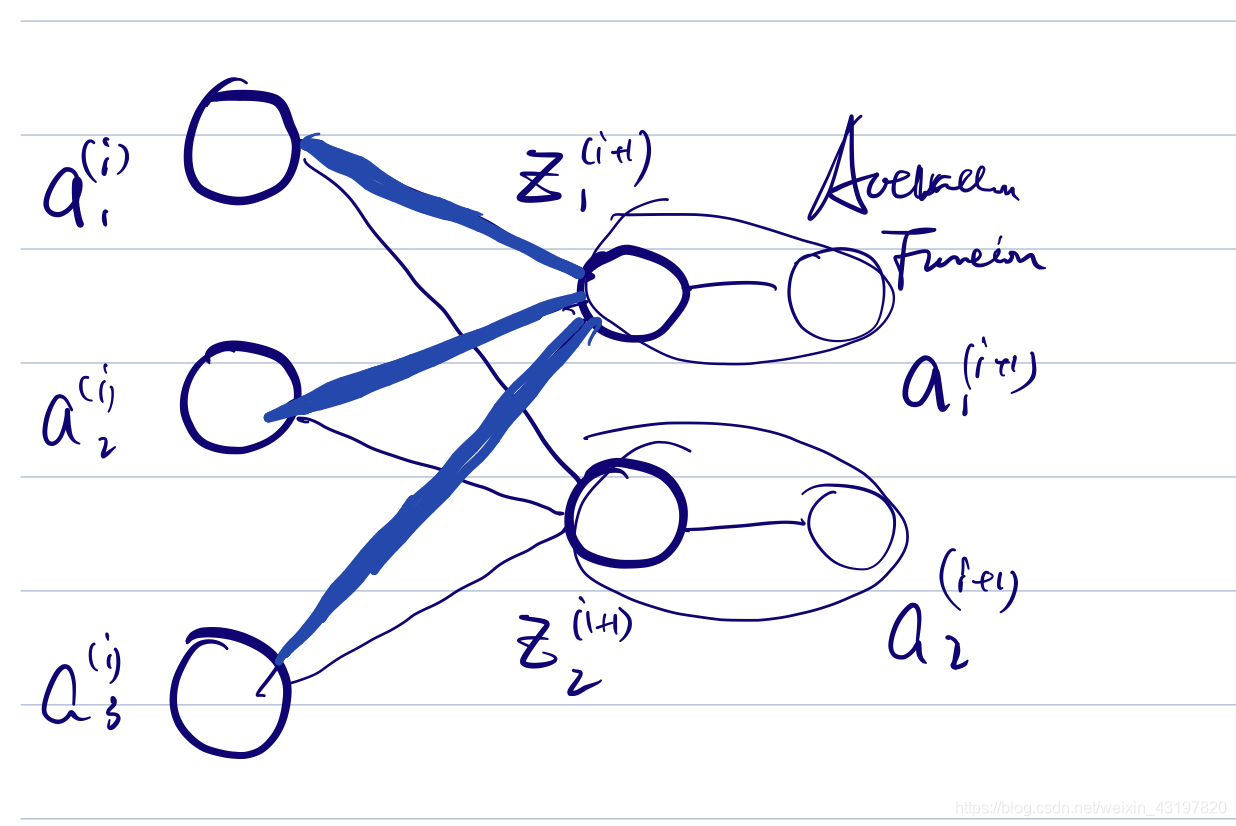 很显然,其符合我们的形态2的结论。可以直接得到由于权重,也就是线的粗细,只与
z
z
zi+11,
z
z
zi+12这两个中层神经元有关,进而
d
w
dw
dw对于这些先来讲也只由其对应的dz1(单个的)和
a
a
a(i)(在这里面是3×1矩阵)共同确定(还记得直观吧,x越大dw越大,那么结论是
d
w
=
d
z
×
x
dw=dz×x
dw=dz×xT),而对于整体的
w
w
w矩阵,我们要求其(在这里面是2×3矩阵)的
d
w
dw
dw,那么我们要拆成若干行形态2来看的话,很快就可以理解出来,实际上我们是要得到两个形态2的(3×1)矩阵放到两行上。这时就还是
d
w
=
d
z
×
x
dw=dz×x
dw=dz×xT,只不过现在的dz是一个2×1列向量,x也变成了
a
a
a(i),那么也就是
d
w
=
d
z
×
a
dw=dz×a
dw=dz×a(i)T。理解的话在脑子脑补一下矩阵乘法的原理,我们要把
d
z
dz
dz的第一个数(变化量)乘上
a
a
a(i)行向量放在
d
w
dw
dw的第一行,再把
d
z
dz
dz的第二个数(变化量)乘上
a
a
a(i)行向量,以此类推。其实就是一样的啦。
很显然,其符合我们的形态2的结论。可以直接得到由于权重,也就是线的粗细,只与
z
z
zi+11,
z
z
zi+12这两个中层神经元有关,进而
d
w
dw
dw对于这些先来讲也只由其对应的dz1(单个的)和
a
a
a(i)(在这里面是3×1矩阵)共同确定(还记得直观吧,x越大dw越大,那么结论是
d
w
=
d
z
×
x
dw=dz×x
dw=dz×xT),而对于整体的
w
w
w矩阵,我们要求其(在这里面是2×3矩阵)的
d
w
dw
dw,那么我们要拆成若干行形态2来看的话,很快就可以理解出来,实际上我们是要得到两个形态2的(3×1)矩阵放到两行上。这时就还是
d
w
=
d
z
×
x
dw=dz×x
dw=dz×xT,只不过现在的dz是一个2×1列向量,x也变成了
a
a
a(i),那么也就是
d
w
=
d
z
×
a
dw=dz×a
dw=dz×a(i)T。理解的话在脑子脑补一下矩阵乘法的原理,我们要把
d
z
dz
dz的第一个数(变化量)乘上
a
a
a(i)行向量放在
d
w
dw
dw的第一行,再把
d
z
dz
dz的第二个数(变化量)乘上
a
a
a(i)行向量,以此类推。其实就是一样的啦。
然后我们来看这时候的
d
x
dx
dx是怎么变化的。我们也还是将神经网络先拆成两个形态2,那么我们就可以想到,因为我们要修改的是每一个x,而反向过程中一个x会被多个线段所指向,那么不同的权重也会影响我们的修改,实际上我们得到的dai(在本例子中是一个3×1的列向量),是一个“多列累加的结果”,即反向传播过来的每一个形态2,都会造成一个dai,由w的某一列决定,而我们要将其列加dz的权重之后加到一起。
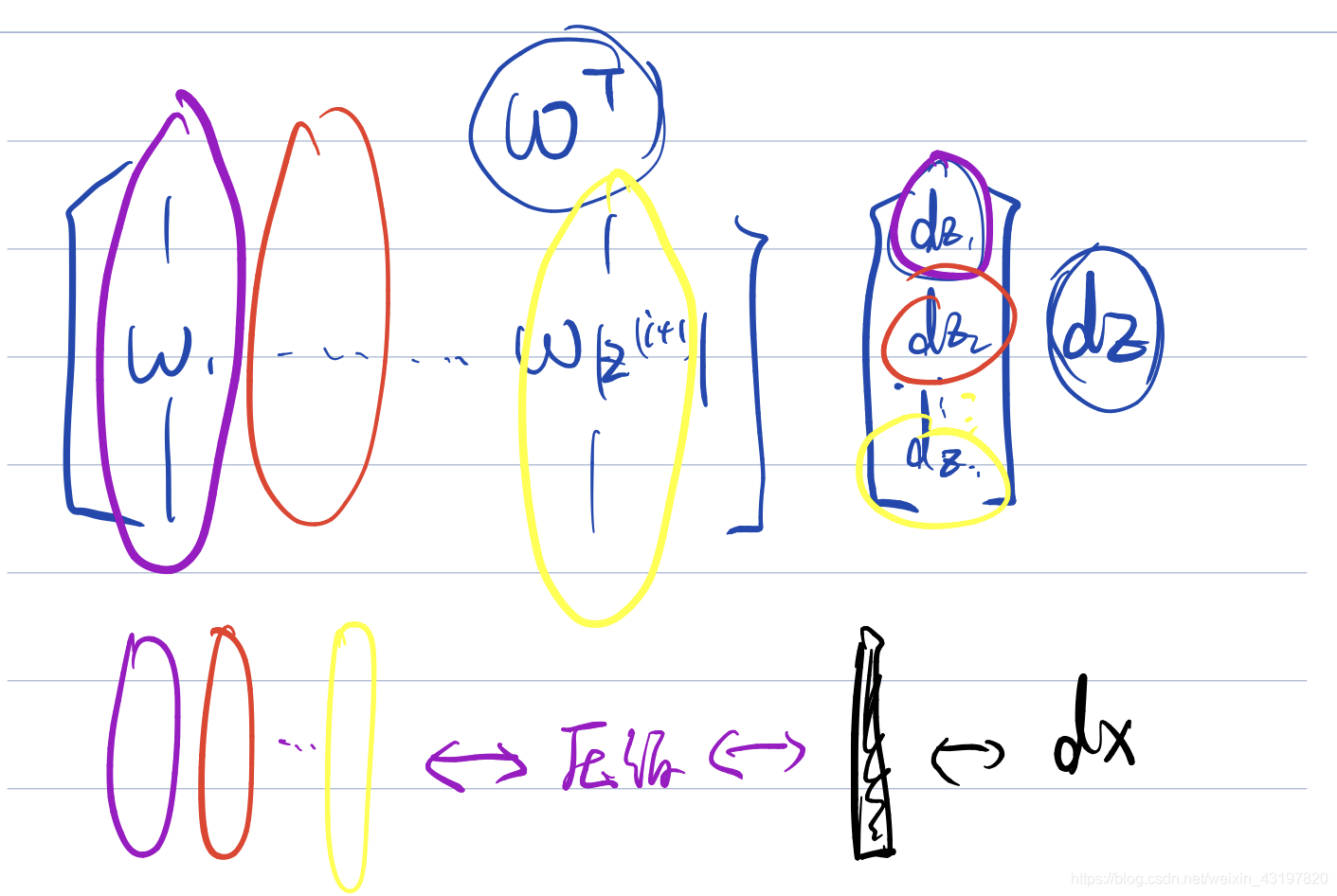
上面的图希望能够帮助大家直观理解。那么实际上使用
d
x
=
w
dx=w
dx=wT×
d
z
dz
dz就是矩阵的公式体现。图画的很明白了,这里面就不赘述了。
至于
d
b
db
db,不加解释,过于显然的是其一定恒等于dz。
补充说明一下符号 ∗ * ∗
在吴课程中, ∗ * ∗的意思是内积(e.g.(1,2,3) ∗ * ∗(4,5,6)=(4,10,18))。他只有在需要说明内积的时候才用 ∗ * ∗。比如我们每一次反向传播,实际上第一个过程走的是从 a a a向量到 z z z向量。那么这时候由于是一个一一映射,那么微分的传递实际上是一个内积。就每一项对应位置相乘。
训练集升级之后的向量化
我们之前讨论的情况都是对于一个数据的输入的正向传播和反向传播,对于整个训练集,我们对于X进行相应的列方向上的扩充。这一部分的向量化我们在这里就不讲了,使用本文的方法很快可以推导出来。
现在再看这些公式,是不是就很显然了呢?
(备注一下,它里面少了个转置,我用红色画出来了)

吴恩达,深度学习课程第一课
上海交通大学,矩阵理论与应用
3blue1brown,神经网络相关可视化视频














 1267
1267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









