






2023-03-31 16:21:27,122 WARN [org.apache.hadoop.mapred.MapTask] - Unable to initialize MapOutputCollector org.apache.hadoop.mapred.MapTask$MapOutputBuffer
java.lang.NullPointerException
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.init(MapTask.java:1020)
at org.apache.hadoop.mapred.MapTask.createSortingCollector(MapTask.java:403)
at org.apache.hadoop.mapred.MapTask.access$100(MapTask.java:81)
at org.apache.hadoop.mapred.MapTask$NewOutputCollector.<init>(MapTask.java:705)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:777)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:342)
at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:271)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run$$$capture(FutureTask.java:266)
at java.util.concurrent.FutureTask.run(FutureTask.java)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
2023-03-31 16:21:27,126 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1110209601_0001_m_000001_0
2023-03-31 16:21:27,132 INFO [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] - File Output Committer Algorithm version is 2
2023-03-31 16:21:27,132 INFO [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] - FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
2023-03-31 16:21:27,132 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2023-03-31 16:21:27,320 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@186d33bc
2023-03-31 16:21:27,322 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: file:/D:/flow2.txt:0+1141
2023-03-31 16:21:27,366 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2023-03-31 16:21:27,366 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2023-03-31 16:21:27,366 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2023-03-31 16:21:27,366 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2023-03-31 16:21:27,366 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2023-03-31 16:21:27,367 WARN [org.apache.hadoop.mapred.MapTask] - Unable to initialize MapOutputCollector org.apache.hadoop.mapred.MapTask$MapOutputBuffer
java.lang.NullPointerException
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.init(MapTask.java:1020)
at org.apache.hadoop.mapred.MapTask.createSortingCollector(MapTask.java:403)
at org.apache.hadoop.mapred.MapTask.access$100(MapTask.java:81)
at org.apache.hadoop.mapred.MapTask$NewOutputCollector.<init>(MapTask.java:705)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:777)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:342)
at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:271)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run$$$capture(FutureTask.java:266)
at java.util.concurrent.FutureTask.run(FutureTask.java)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
2023-03-31 16:21:27,367 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map task executor complete.
2023-03-31 16:21:27,370 WARN [org.apache.hadoop.mapred.LocalJobRunner] - job_local1110209601_0001
java.lang.Exception: java.io.IOException: Initialization of all the collectors failed. Error in last collector was:java.lang.NullPointerException
at org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:492)
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:552)
Caused by: java.io.IOException: Initialization of all the collectors failed. Error in last collector was:java.lang.NullPointerException
at org.apache.hadoop.mapred.MapTask.createSortingCollector(MapTask.java:418)
at org.apache.hadoop.mapred.MapTask.access$100(MapTask.java:81)
at org.apache.hadoop.mapred.MapTask$NewOutputCollector.<init>(MapTask.java:705)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:777)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:342)
at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:271)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run$$$capture(FutureTask.java:266)
at java.util.concurrent.FutureTask.run(FutureTask.java)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.NullPointerException
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.init(MapTask.java:1020)
at org.apache.hadoop.mapred.MapTask.createSortingCollector(MapTask.java:403)
... 11 more
2023-03-31 16:21:27,807 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local1110209601_0001 running in uber mode : false
2023-03-31 16:21:27,809 INFO [org.apache.hadoop.mapreduce.Job] - map 0% reduce 0%
2023-03-31 16:21:27,813 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local1110209601_0001 failed with state FAILED due to: NA
2023-03-31 16:21:27,830 INFO [org.apache.hadoop.mapreduce.Job] - Counters: 0
Disconnected from the target VM, address: '127.0.0.1:52620', transport: 'socket'
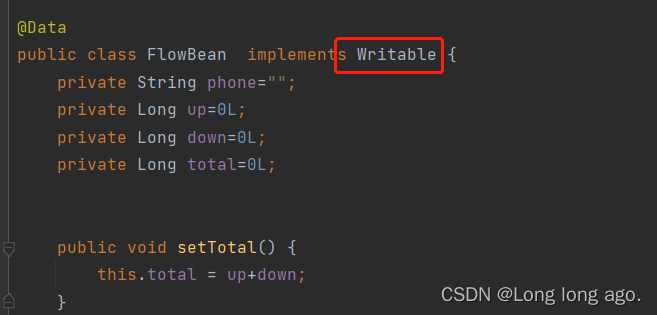
要注意你的bean类是否有实现Writable接口和重写write,readFields方法
package longer.mapreduce.writable;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 1、定义类实现writanle接口
* 2、重写序列化和反序列化方法
* 3、重写空参构造
* 4、toString方法
*/
public class FlowBean implements Writable {
private long upFlow; //上行流量
private long downFlow;//下行流量
private long sumFlow;//总流量
//空参构造
public FlowBean() {
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow() {
this.sumFlow = this.upFlow + this.downFlow;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
//放序列化顺序一定要和write 序列化一致
@Override
public void readFields(DataInput in) throws IOException {
this.upFlow = in.readLong();
this.downFlow = in.readLong();
this.sumFlow = in.readLong();
}
@Override
public String toString() {
return "\t" + upFlow +
"\t" + downFlow +
"\t" + sumFlow;
}
}
















 2497
2497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









