






1、爬取逻辑
import scrapy
#要主要这里的引用,不要scary_test.scary_test.items import ScaryTestItem会找不到这个模块
from scary_test.items import ScaryTestItem
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class DangdangSpider(scrapy.Spider):
name = "dangdang"
allowed_domains = ["category.dangdang.com"]
start_urls = ["http://category.dangdang.com/cp01.01.02.00.00.00.html"]
base_url = 'http://category.dangdang.com/pg'
page = 1
rules = (
Rule(
LinkExtractor(allow=r'/pg\d+-cp01.01.02.00.00.00.html'),
callback="parse",
follow=True
)
)
def parse(self, response):
content = response.text
li_list = response.xpath("//ul[@id='component_59']/li")
print("*****************风吹草地现牛羊**********************")
for li in li_list:
describe = li.xpath(".//a[@name='itemlist-title']/text()").extract_first()
author = li.xpath(".//a[@name='itemlist-author']/text()").extract_first()
url = li.xpath(".//img/@data-original").extract_first()
if not url:
url = li.xpath(".//img/@src").extract_first()
price = li.xpath(".//span[@class='search_now_price']/text()").extract_first()
print("描述:" + describe)
print("作者:" + author)
print("图片:" + url)
print("价格:" + price)
book = ScaryTestItem(url=url,describe=describe, price=price, author=author)
yield book
if self.page < 10:
self.page = self.page + 1
url = self.base_url + str(self.page) + '-cp01.01.02.00.00.00.html'
yield scrapy.Request(url=url, callback=self.parse)
2、定义item
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
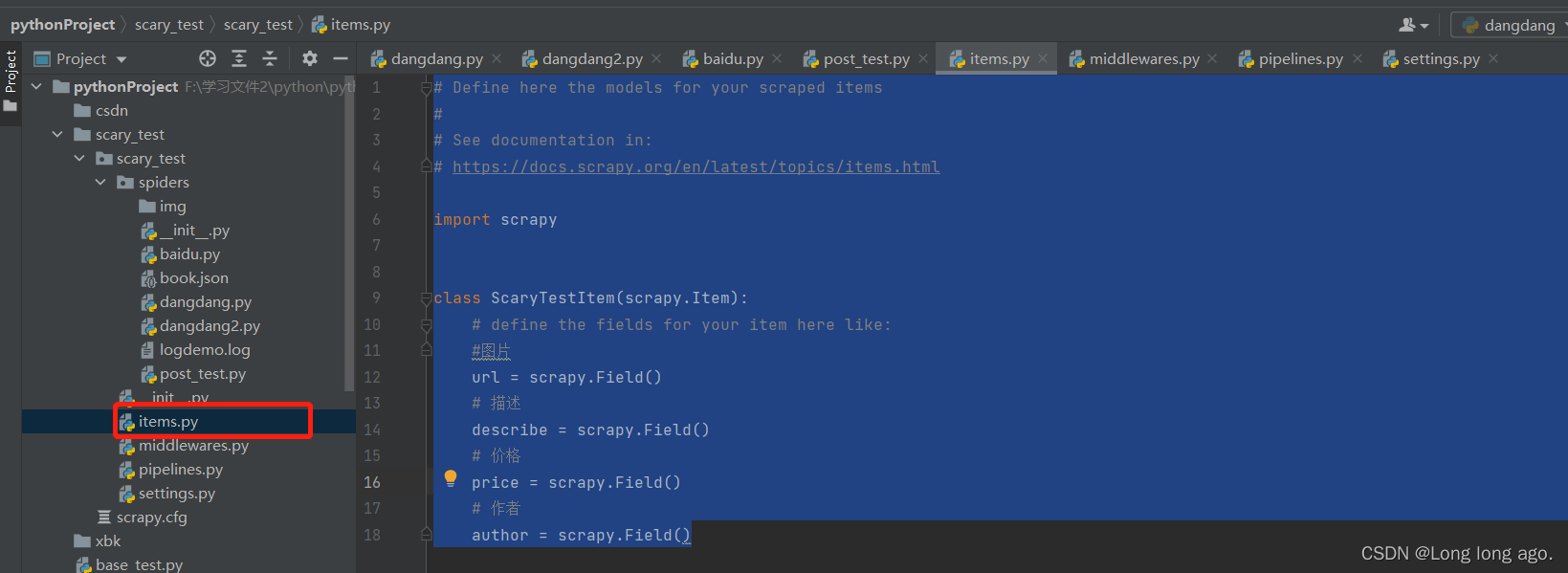
class ScaryTestItem(scrapy.Item):
# define the fields for your item here like:
#图片
url = scrapy.Field()
# 描述
describe = scrapy.Field()
# 价格
price = scrapy.Field()
# 作者
author = scrapy.Field()
3、定义通道
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import urllib.request
import pymysql
from itemadapter import ItemAdapter
from scrapy.utils.project import get_project_settings
class ScaryTestPipeline:
def open_spider(self, spider):
self.fp = open("book.json", "w", encoding="utf-8")
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self, spider):
self.fp.close()
class downloadimg:
def process_item(self, item, spider):
url="http:"+item["url"]
sp_list=url.split("/")
name="./img/"+sp_list[len(sp_list)-1]
urllib.request.urlretrieve(url=url,filename=name)
return item

配置通道
管道可以有很多个 那么管道是有优先级的 优先级的范围是1到1000 值越小优先级越高
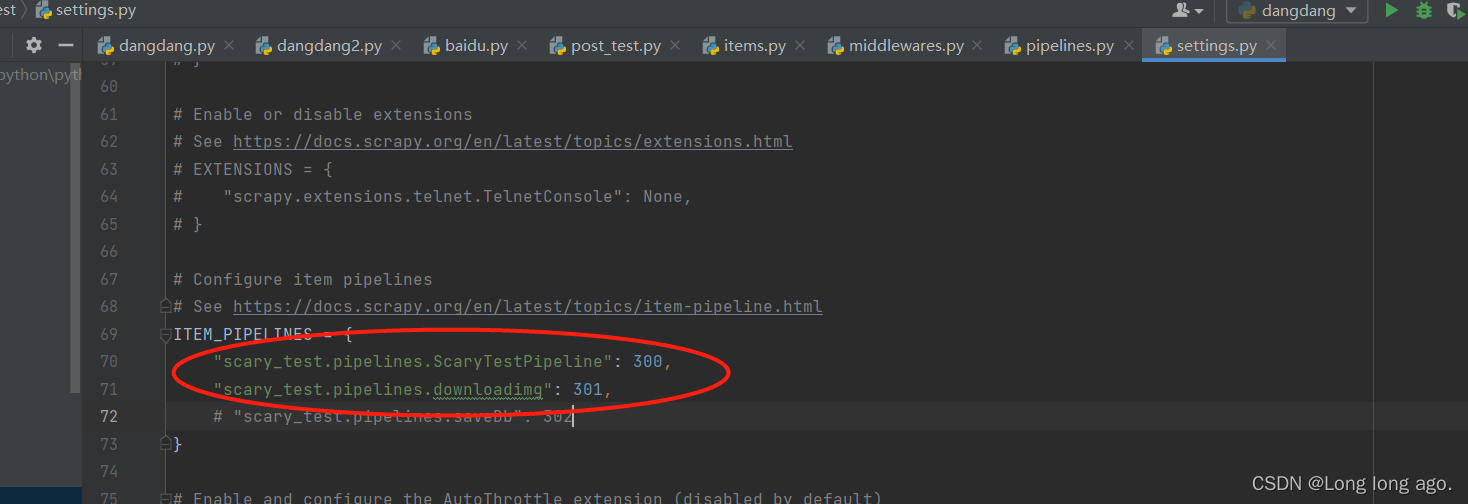
运行项目后就能发现已经爬取图片和json到本地
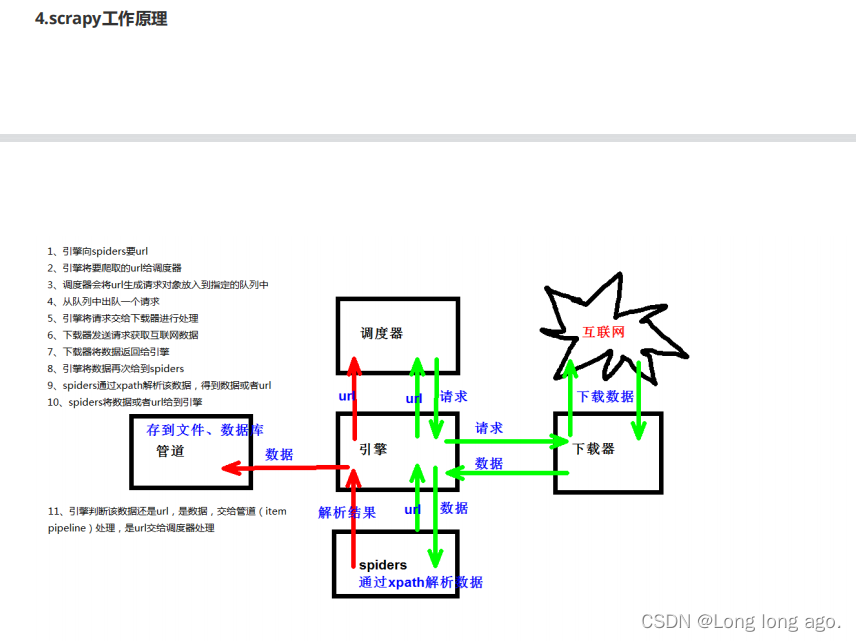
工作原理














 736
736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









