






offset的默认维护位置
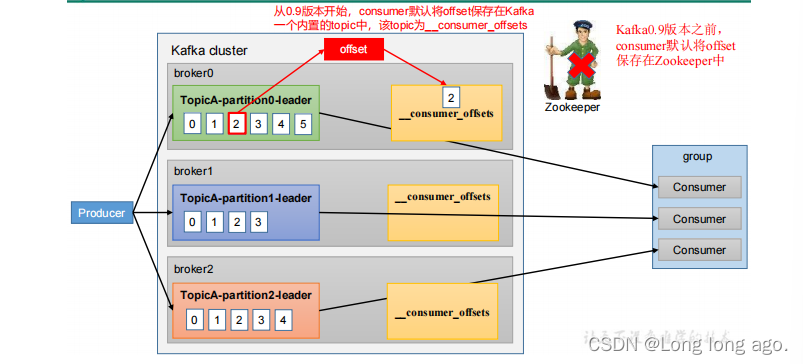
0.9版本之前:consumer默认将offset保持在zookeeper中
从0.9版本开始,consumer默认将offset保存在kafka一个内置的topic中,该topic为__consumer_offsets
__consumer_offsets 主题里面采用key和value方式存储数据,key是group.id+topic+分区号,value就是当前offset的值。每隔一段时间,kafka内部会对这个topic进行compact,也就是每隔group.id+topic+分区号就保留最新的数据
$KAFKA_HOME/bin/kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server hadoop100:9092 --consumer.config $KAFKA_HOME/config/consumer.properties --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --from-beginning

如果看不到
在配置文件 config/consumer.properties 中添加配置 exclude.internal.topics=false,
默认是 true,表示不能消费系统主题。为了查看该系统主题数据,所以该参数修改为 false。
自动提交offset
















 1774
1774











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









