







客户端开发
一般的生产逻辑所需步骤:
- 配置生产者客户端参数及创建相应的生产者实例。
- 构建需要发送的消息。
- 发送消息。
- 关闭生产者实例。
Java代码实现:
public class KafkaProducerDemo1 {
public static final Logger logger = LoggerFactory.getLogger(KafkaProducerDemo1.class);
public static final String BOOTSTRAP_SERVER = "localhost:9094";
public static final String TOPIC = "my-replicated-topic";
public static Properties initConfig(){
Properties properties = new Properties();
properties.put("bootstrap.servers", BOOTSTRAP_SERVER);
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.CLIENT_ID_CONFIG, "producer_demo1");
logger.info("initConfig result is {}", properties.toString());
return properties;
}
public static void main(String[] args) {
Properties properties = initConfig();
try (KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties)) {
ProducerRecord<String, String> objectStringProducerRecord = new ProducerRecord<>(TOPIC, "hello kafka!");
// 发后即忘(fire-and-forget)
// kafkaProducer.send(objectStringProducerRecord);
// 同步发送方式.get()
Future<RecordMetadata> send = kafkaProducer.send(objectStringProducerRecord);
// recordMetadata存在元数据
RecordMetadata recordMetadata = send.get(10, TimeUnit.SECONDS);
System.out.println(recordMetadata.offset());
} catch (Exception e) {
e.printStackTrace();
}
}
}
配置参数
在Kafka生产者客户端KafkaProducer中有3个参数是必填的:
- bootstrap.servers:该参数用来指定生产者客户端连接Kafka集群所需的broker地址清单。
- key.serializer&value.serializer:broker 端接收的消息必须以字节数组(byte[])的形式存在,来指定key和value序列化操作的序列化器,这两个参数无默认值。
client.id,这个参数用来设定KafkaProducer对应的客户端id,默认值为“”。如果客户端不设置,则KafkaProducer会自动生成一个非空字符串,内容形式如“producer-1”“producer-2”,即字符串“producer-”与数字的拼接。
可配置的参数远不止这些,需要的时候再补充。
构建与发送消息
消息的构建即创建ProducerRecord对象。
发送消息主要有三种模式:发后即忘(fire-and-forget)、同步(sync)及异步(async)。
// 发后即忘(fire-and-forget)
// kafkaProducer.send(objectStringProducerRecord);
不在意消息是否是否成功。性能最高可靠性最差。
// 同步发送方式.get()
Future<RecordMetadata> send = kafkaProducer.send(objectStringProducerRecord);
// recordMetadata存在元数据
RecordMetadata recordMetadata = send.get(10, TimeUnit.SECONDS);
同步方法来阻塞等待Kafka的响应,直到消息发送成功,或者发生异常。获得RecordMetadata对象,在RecordMetadata对象里包含了消息的一些元数据信息,比如当前消息的主题、分区号、分区中的偏移量(offset)、时间戳等。Future中的 get(longtimeout,TimeUnit unit)方法实现可超时的阻塞。
Kafka拥有重试机制,但是异常分为可重试和不可重试两种;比如网络异常,leder副本不可用等可以重试来解决。消息体过大等不可以重试。
properties.put(ProducerConfig.RETRIES_CONFIG, 3);
可以通过如上配置实现重试,默认是0。
// 异步发送
kafkaProducer.send(objectStringProducerRecord, (recordMetadata, e) -> {
if (e != null) {
logger.error("发送失败");
} else {
logger.info("recordMetadata offset is {}", recordMetadata.offset());
}
});
onCompletion()方法的两个参数是互斥的,消息发送成功时,metadata 不为 null而exception为null;消息发送异常时,metadata为null而exception不为null。
整体架构
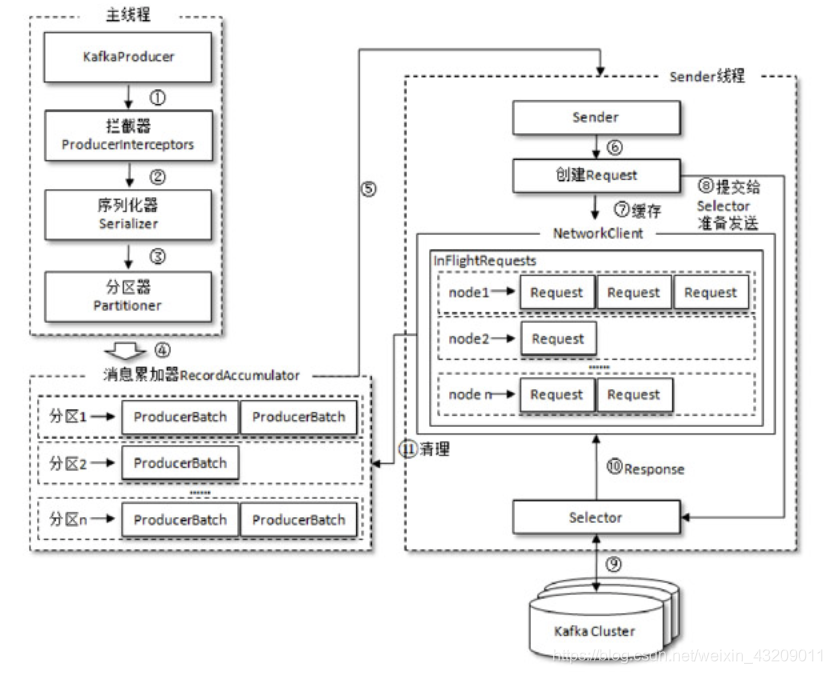
整个生产者客户端由两个线程协调运行,这两个线程分别为主线程和Sender线程(发送线程)。在主线程中由KafkaProducer创建消息,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息累加器(RecordAccumulator,也称为消息收集器)中。Sender 线程负责从RecordAccumulator中获取消息并将其发送到Kafka中。
RecordAccumulator 主要用来缓存消息以便 Sender 线程可以批量发送,进而减少网络传输的资源消耗以提升性能














 3232
3232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









